

Тендеры и лиды
Информация
Ручная загрузка товаров на Яндекс Бизнес занимает слишком много времени, ведь приходится долго и муторно добавлять каждый товар и услугу. Когда их десять - это терпимо, но если больше трёхсот? Остаётся либо делегировать задачу, либо покупать рекламную подписку от Яндекс Бизнеса, чтобы получить возможность загружать YML-фид.
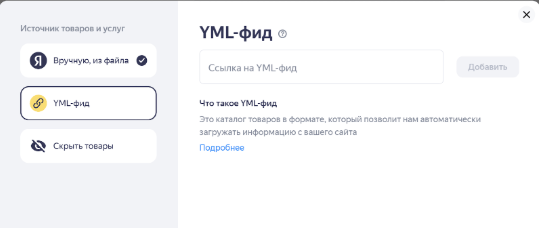
Однако есть автоматизированный способ, который позволит добавить все товары всего за 20 минут. В этой статье вы получите пошаговую инструкцию, как это сделать. Понадобится лишь Screaming Frog или любой другой краулер с поддержкой XPath.
Для загрузки товаров и услуг в Яндекс Бизнес нужно заполнить следующие основные поля:
Все эти данные мы автоматически достанем с сайта. Для начала откройте Screaming Frog (SF) → Configuration → Custom → Custom Extraction (далее мы будем вставлять туда нужные XPath-запросы).
Не спешите сразу парсить весь сайт, так как у вас могут быть ошибки. Возьмите для начала 2-3 страницы и проверьте их с помощью режима “List”, чтобы убедиться, все ли данные вам удалось достать. Если для 3-х страниц данные успешно подгрузились, то можно переходить к остальным страницам.
Название категории проще всего взять из предпоследней хлебной крошки, так как именно она чаще всего указывает на раздел товара или услуги.
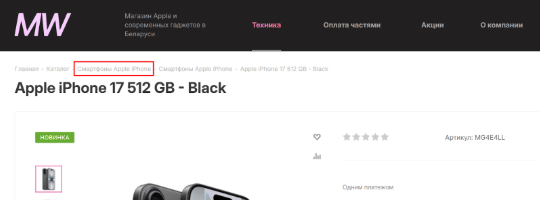
Чтобы найти предпоследнюю хлебную крошку в поле выбора данных для извлечения выберите “Extract Text”.
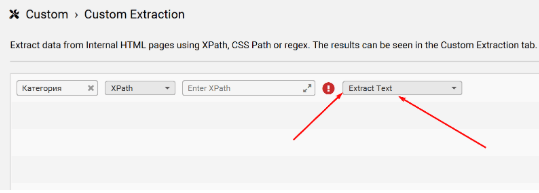
Используйте следующие шаблоны Xpath, которые помогут найти нужное 👇
Ищет последнюю «нессылочную» крошку и берёт предыдущего соседа (li или span):
((//nav[contains(@class,'bread') or contains(@aria-label,'bread')]
| //div[contains(@class,'bread')]
| //ul[contains(@class,'bread')]
| //ol[contains(@class,'bread')])[1]
//*[self::li or self::span][not(.//a)][last()]
/preceding-sibling::*[self::li or self::span][1])
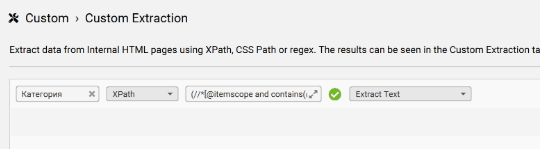
(//*[@itemscope and contains(@itemtype,'schema.org/BreadcrumbList')]
//*[@itemprop='itemListElement']//*[@itemprop='name'])[last()-1]/text()
Применяется в том случае, если хлебные крошки на вашем сайте размечены микроразметкой BreadcrumbList - сервис для проверки
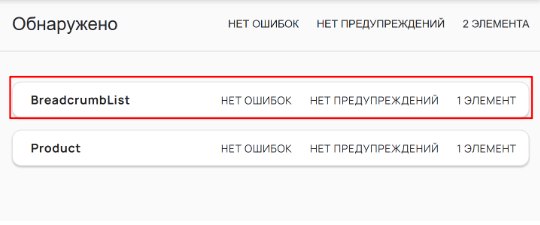
Вернитесь в SF и вставьте нужный XPath в поле “Enter XPath”.
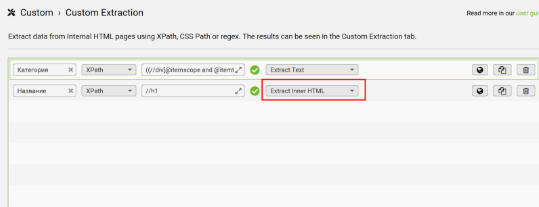
Название берём из заголовка H1 на странице. Универсальный XPath:
👉 //h1
В поле выбора данных укажите “Extract Inner HTML” - и далее используйте это значение для всех остальных полей, если не указано иное.
Для описания выберите часть текста, которая лучше всего характеризует страницу. Если сайт был SEO-оптимизирован, на нём, скорее всего, есть подходящий текстовый блок. Не берите весь SEO-текст - достаточно 150–250 символов, передающих суть.
Наша система сама подберет вам исполнителей на услуги, связанные с разработкой сайта или приложения, поисковой оптимизацией, контекстной рекламой, маркетингом, SMM и PR.
Заполнить заявку
13303 тендера
проведено за восемь лет работы нашего сайта.
Чтобы автоматически подтянуть этот блок, воспользуйтесь XPath.
Откройте страницу → Ctrl + Shift + C → наведите курсор на нужную часть текста → ПКМ → Copy → Copy XPath.
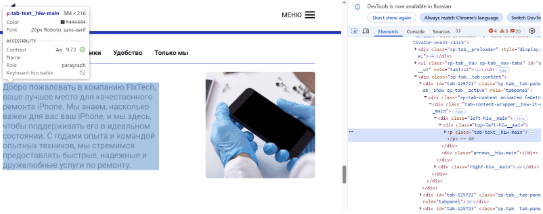
Например у меня данный Xpath выглядит вот так - //div[contains(@id, "tab-")]/div/div/div[1]/div[1]/p
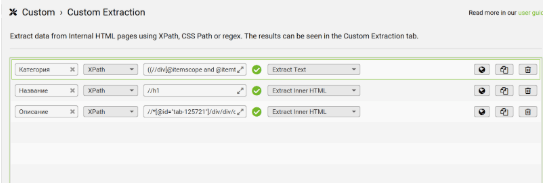
Если на сайте реализована микроразметка “Product” с помощью microdata, то извлечь описание можно из поля “description” с помощью данного XPath, обязательно выставив “Extract Text” поле выбора данных для извлечения.
👉 (//*[@itemscope and contains(@itemtype,'schema.org/Product')]//*[@itemprop='description'][@content])[1]/@content
Для интернет-магазинов - всё просто. Просто ищем Xpath цен на товарах, вставляем в программу и готово. Для этого ищем XPath данного элемента, как мы делали при поиске “Описания” и вставляем его в Screaming Frog.
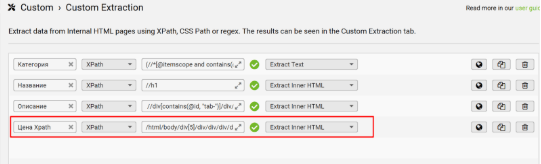
Если на сайте реализована микроразметка “Product” с помощью microdata, то извлечь данные о цене можно из поля “price” с помощью данного XPath, обязательно выставив “Extract Text” поле выбора данных для извлечения.
👉 (//*[@itemscope and contains(@itemtype,'schema.org/Offer')]//*[@itemprop='price'][@content])[1]/@content
Как решать проблему с каталогами я так и не решил, так как у каждой компании свои особенности. А вот с сайтами услуг либо подтягивать цену из блока с стоимостью услуги
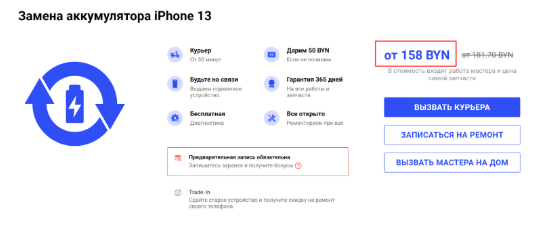
Либо если это общая страница, где нельзя назвать точную стоимость, то берите цену из первой строки в общей таблице с ценами.
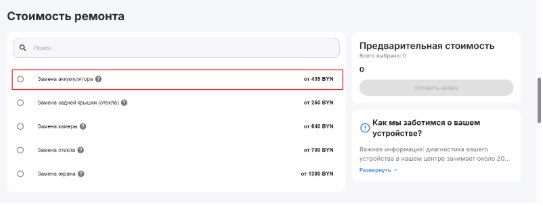
Для этого в поле выбора режима извлечения данных выберите “Regex” и вставьте шаблон ниже
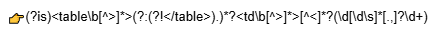
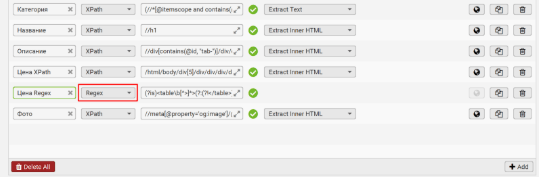
Данный шаблон берет первое число именно из td внутри конкретной table, не беря в учет числа, которые находятся внутри стилей.
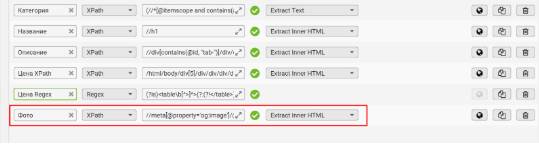
5. Фото
Самый простой способ найти картинку, которая будет характеризовать страницу, найти её в разметке для социальных сетей, которые находятся в теге head вида:

XPath для извлечения изображения:
👉 //meta[@property='og:image']/@content | //meta[@name='twitter:image']/@content
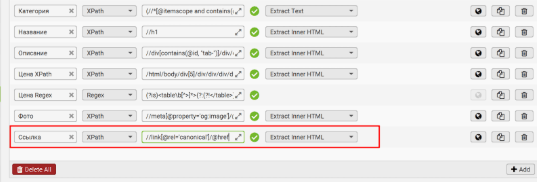
Для получения ссылки страницы используйте тег canonical - это лучший вариант, так как он указывает на основную страницу и предотвращает дублирование в индексе.
XPath для извлечения canonical:
👉 //link[@rel='canonical']/@href
Автоматизация загрузки товаров и услуг в Яндекс Бизнес экономит часы рутинной работы и снижает риск ошибок. Благодаря простым XPath-шаблонам и инструменту Screaming Frog вы можете собрать все нужные данные - название, цену, описание, фото и ссылку - прямо с вашего сайта.
Дальше остаётся лишь сформировать CSV или YML-файл и загрузить его в Яндекс Бизнес. Это решение особенно полезно для сайтов с большим ассортиментом: обновления становятся быстрее, а данные — всегда актуальными.


