


Тендеры и лиды
Информация
Реальный кейс 100% восстановления индексации от digital-агентства Webit.
Автор: SEO-специалист Webit Ирина Сергеенко
Индексация — это процесс, при котором поисковая система заносит страницы сайта в свою базу. Только после этого страницы могут появляться в поисковой выдаче. Если страница не проиндексирована — для Google ее как будто не существует. А теперь представьте, что из индекса выпадают ВСЕ страницы сайта. Именно с такой критической ситуацией мы столкнулись, работая над поисковым продвижением сайта образовательной платформы одного из крупнейших производителей алюминия. Разбираемся, почему это произошло, как восстановили видимость сайта и какие выводы сделали.

С середины марта 2025 года Google начал исключать из индекса страницы сайта, реализованного с помощью JS-фреймворка React.
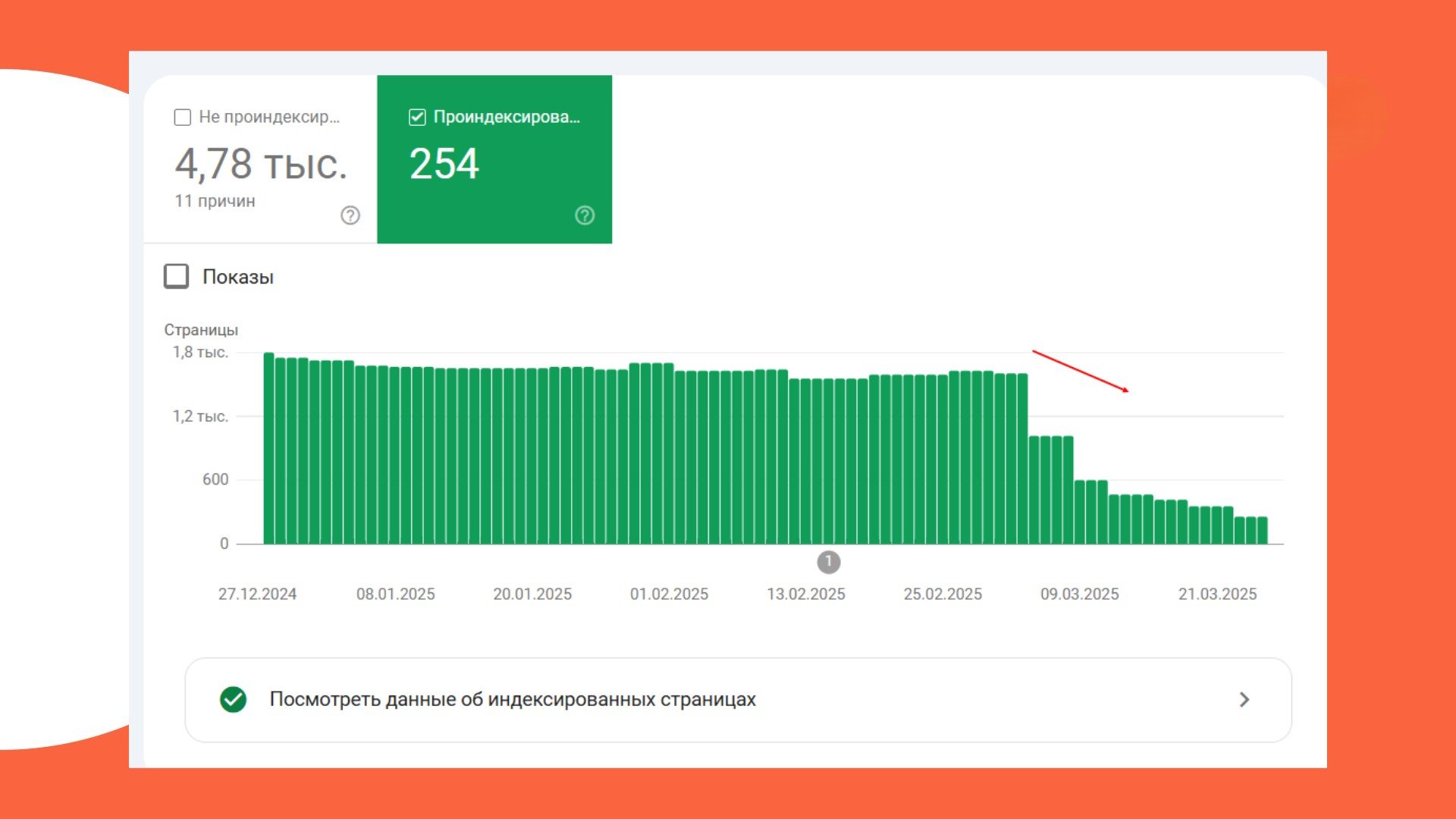
Уже к началу апреля ни одна страница сайта, включая главную, не индексировалась в Google.
Отметим, что проблема затронула только Google, индексация в Яндексе осуществлялась без нареканий. Вот что показал технический аудит:
То есть все страницы были технически доступны, но при этом Google их не индексировал.
Мы решили провести детальную проверку и выдвинули несколько предположений, почему сайт не индексируется в Google.
Основную причину выпадения страниц из индекса мы обнаружили спустя пару недель. Кто же был «виновником» торжества?
Источником проблемы была конфигурация файла robots.txt и особенности реализации сайта на React.
Хотя сайт был настроен на серверный рендеринг (SSR), Googlebot по какой-то причине не использовал готовую HTML-версию страниц для индексации. Вместо этого он пытался загружать и обрабатывать контент через клиентский рендеринг — то есть «собирать» страницу прямо в браузере. Для этого Googlebot обращался к URL с query-параметрами, главным из которых был «?rsc=» — именно через него подгружался основной контент. Но эти параметры были запрещены в файле robots.txt, поэтому бот не мог получить доступ к нужным данным.
Наша система сама подберет вам исполнителей на услуги, связанные с разработкой сайта или приложения, поисковой оптимизацией, контекстной рекламой, маркетингом, SMM и PR.
Заполнить заявку
13334 тендера
проведено за восемь лет работы нашего сайта.
Хотя Google и трактует robots.txt как рекомендацию, в этом случае он воспринял запрет буквально (как прямое указание к действию!) и полностью исключил такие страницы из индексации.
Более того, Googlebot также обращался к поддомену с API (api.site.ru), который отдает данные в формате JSON для клиентского рендеринга. Но и там файл robots.txt копировал правила с основного сайта, включая запреты на параметры — в итоге бот не мог получить даже исходные данные.
При этом все страницы при проверке в Search Console были полностью доступны боту и имели весь необходимый контент.
Дополнительно были заблокированы параметры «?url=» и «?search=», которые Googlebot тоже использует для загрузки контента. Все вместе это делало ключевую информацию недоступной для индексации.
Чтобы вернуть страницы в индекс, мы пересмотрели правила в файле robots.txt на основном домене — убрали запреты на ключевые query-параметры (rsc, url и другие), через которые подгружается важный контент.
Такие же правки внесли и в robots.txt поддомена api.site.ru, поскольку Googlebot обращался к нему за данными при попытке собрать страницу через клиентский рендеринг.
После этих изменений Google наконец получил доступ ко всем необходимым ресурсам — страницы начали возвращаться в индекс, а видимость и трафик — расти.
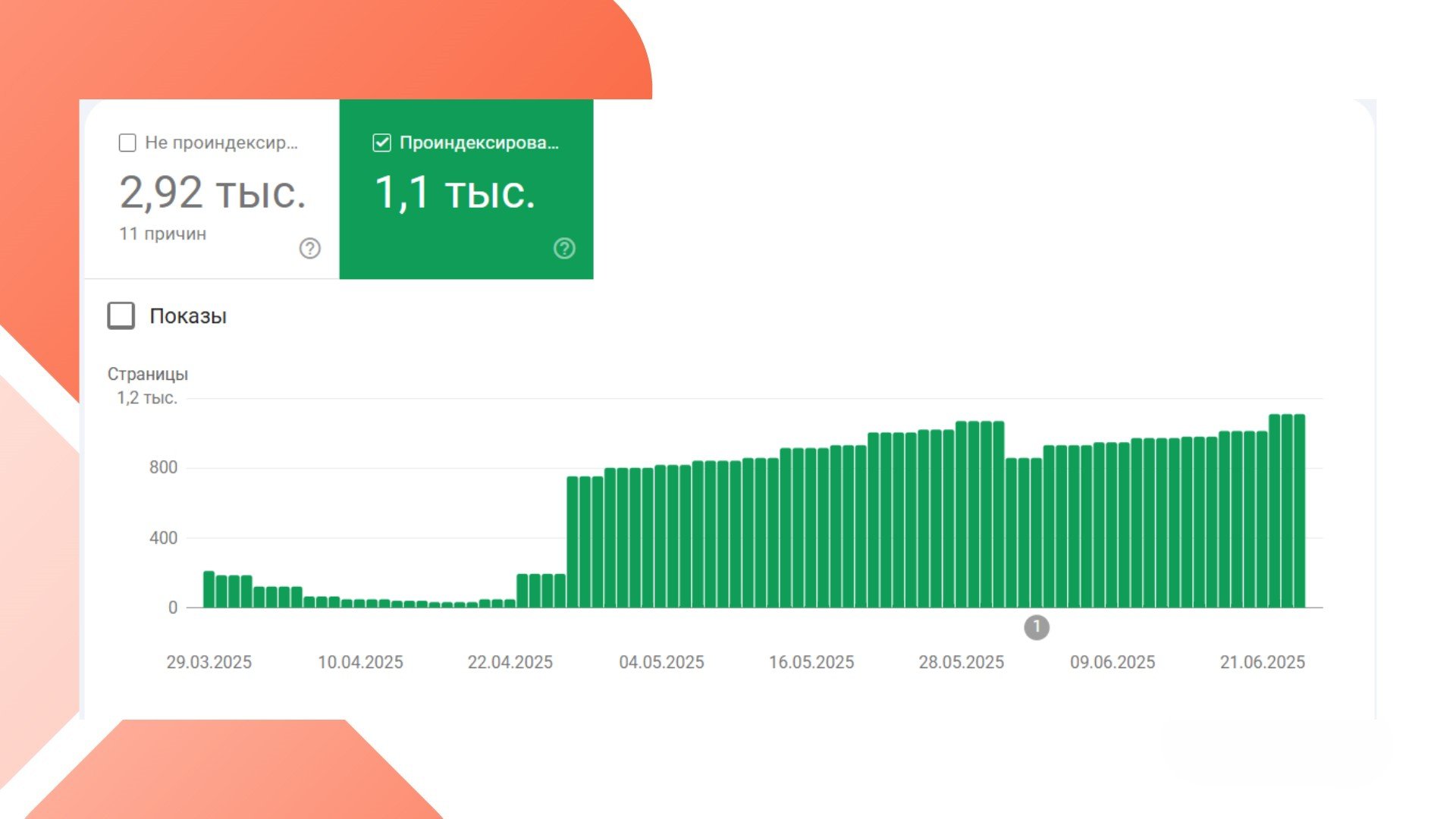
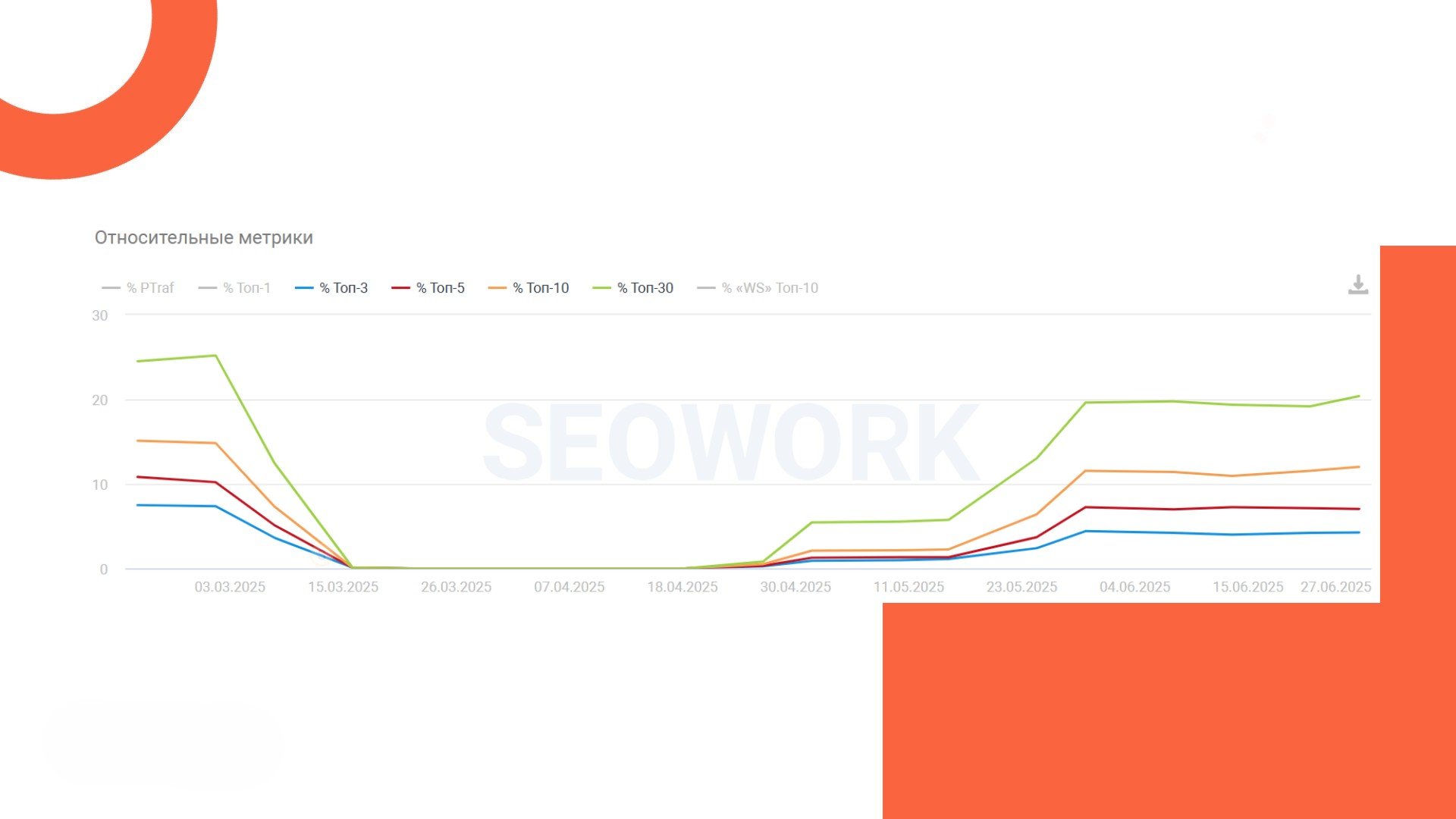
Если Google внезапно исключает страницы из индекса при видимой технической доступности (особенно на сайтах, реализованных на фреймворке):
Чем сложнее сайт, тем внимательнее нужно подходить к деталям. В нашем случае грамотная диагностика и точечные правки вернули сайт в индекс и восстановили трафик. Шаг за шагом и без паники.



