

Тендеры и лиды
Информация
XPath (XML Path Language)– это язык запросов, используемый для навигации и поиска информации в XML-документах. Он позволяет точно указать путь к элементам, атрибутам и текстовым данным, которые нужно найти в структуре XML файлов и получить данные при необходимости.
Из всего этого разнообразия возможностей, разберем “Поиск элементов” и “Извлечение данных” с помощью Screaming Frog (SF).
1. С помощью инструментов разработчика (клавиша F12) анализируем HTML-элемент (тег), в котором располагается ссылка на картинку на каждой товарной карточке. Для этого используем инструмент “Выбор элемента” или сочетание клавиш CTRL+SHIFT+C и наводим курсор на нужную область:
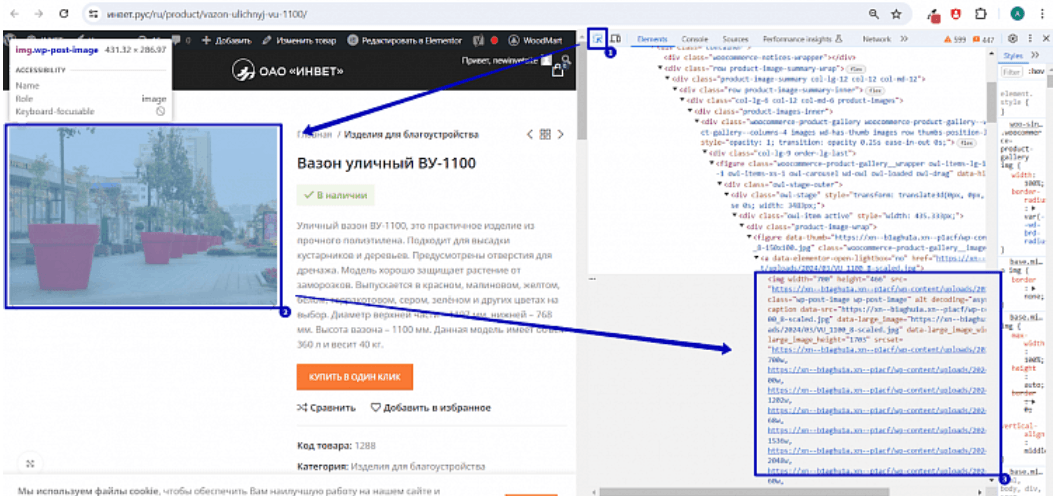
Все картинки располагаются в теге figure, который имеет одинаковое значение атрибута class=”woocommerce-product-gallery__image”:
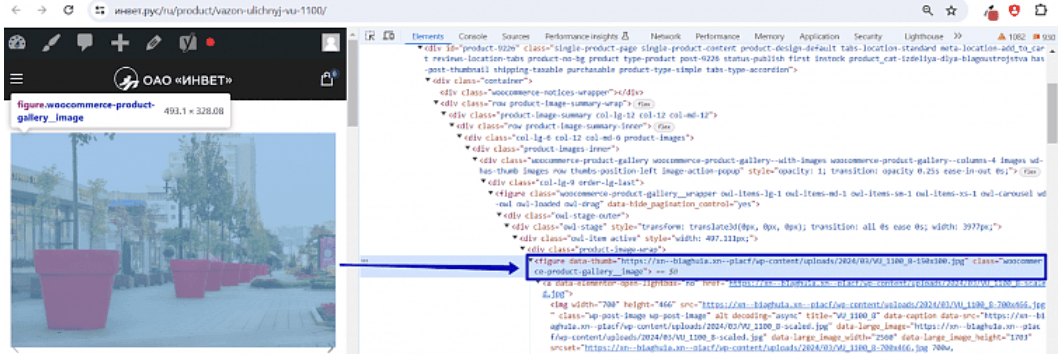
2. На основе общих тегов и атрибутов формируем запрос XPath:
//figure[@class="woocommerce-product-gallery__image"]/@data-thumb
Таким выражением мы запрашиваем вот это значение

3. Запускаем Screaming Frog. Переходим в “Configuration” – “Custom” – “Extraction”.
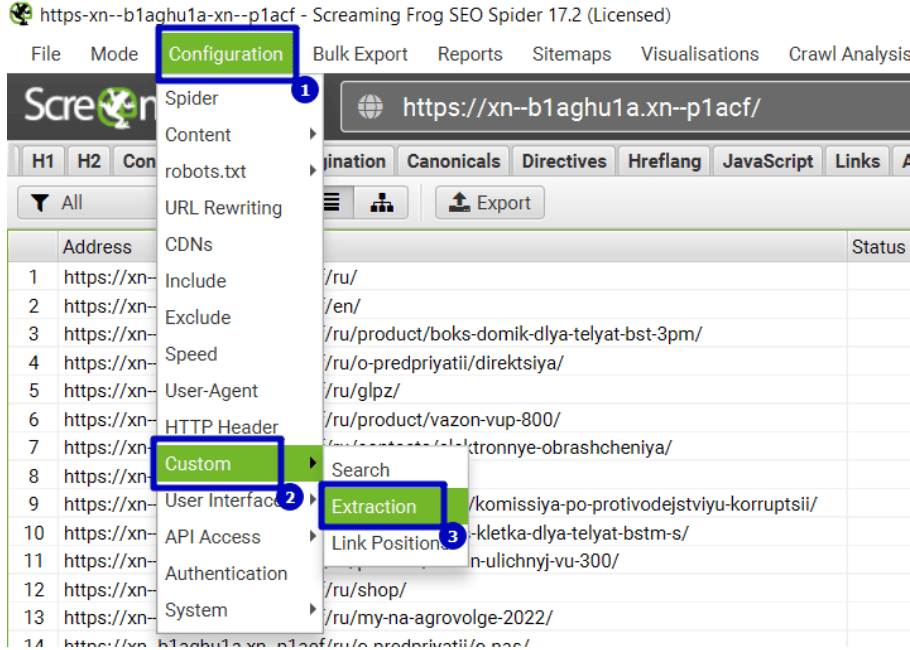
4. Добавляем наш запрос XPath.
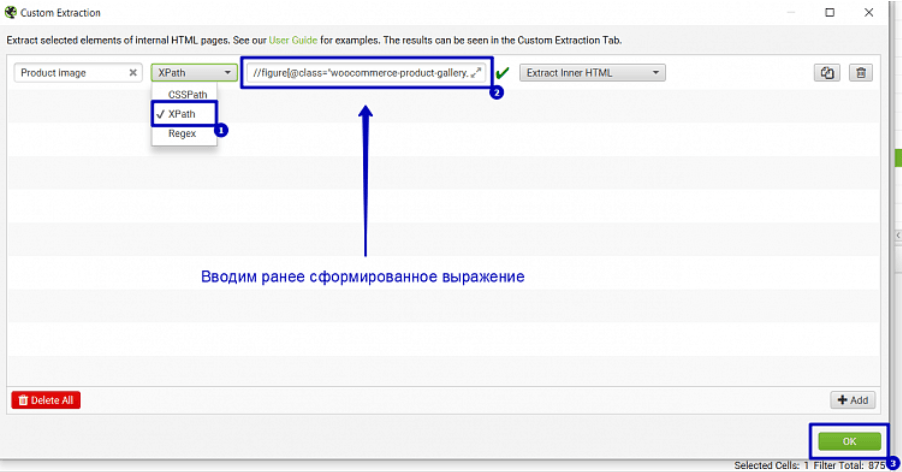
5. Вводим сайт для поиска и запускаем парсинг SF:

6. После того, как парсинг завершен, ищем в правом окошке интерфейса “Custom Extraction” и выбираем искомый параметр.

Наша система сама подберет вам исполнителей на услуги, связанные с разработкой сайта или приложения, поисковой оптимизацией, контекстной рекламой, маркетингом, SMM и PR.
Заполнить заявку
13203 тендера
проведено за восемь лет работы нашего сайта.
7. Экспортируем данные в отчет:
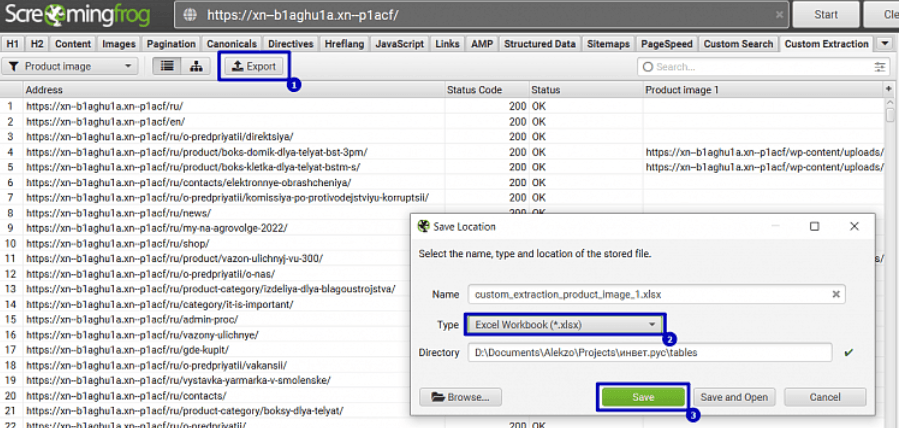
8. Открываем полученный документ. Удаляем столбцы “Status Code”, “Status”.
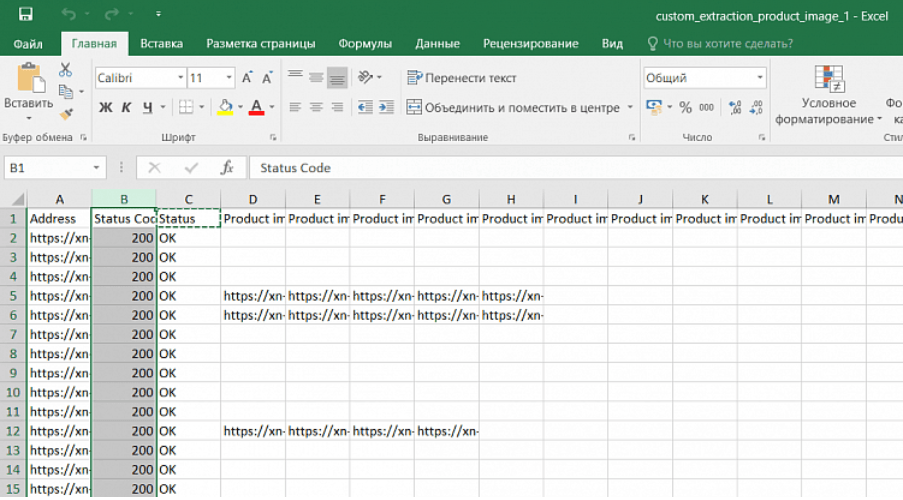
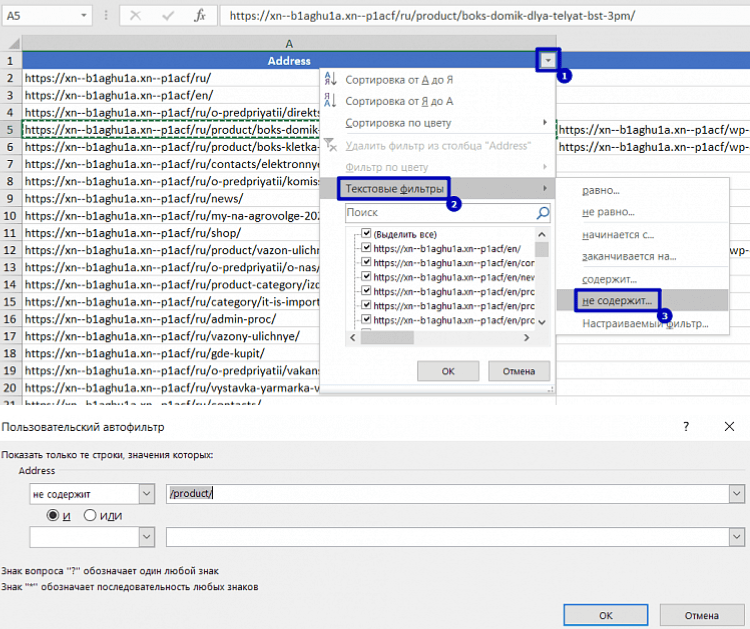
9. Дополнительно добавляем к оставшимся столбцам фильтр.
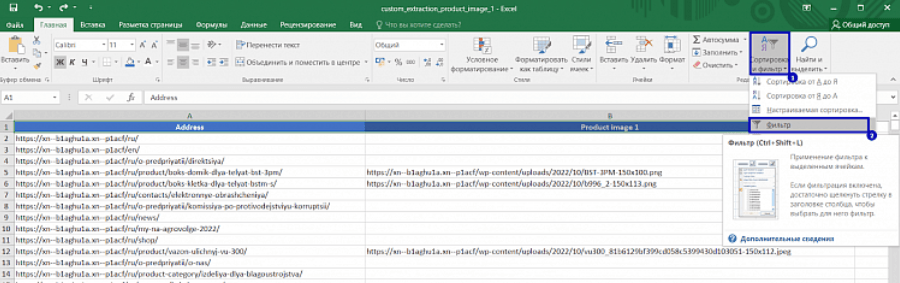
10. С помощью фильтра удаляем лишние страницы.
В моем примере у всех товаров есть составная часть /product/.
Таким образом удаляем все URL, что не содержит ее.
11. Удаляем сортировку. В столбце “Product image 1” выбираем сортировку “Сортировка от А до Я”:
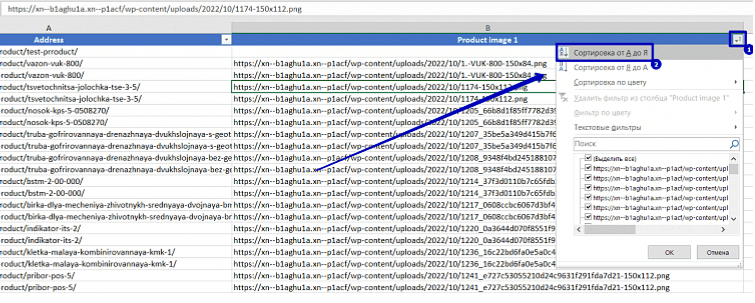
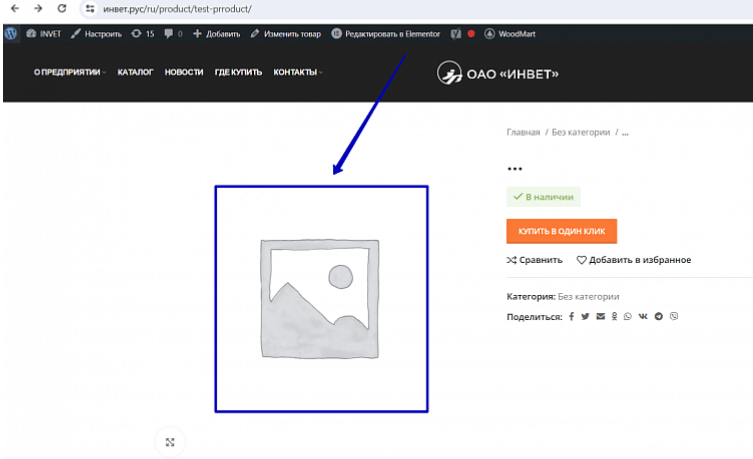
12. Результат получен! Пустое поле в столбце “Product image 1” означает, что на данной странице товара нет уникальной картинки:
Информация взята с сайта https://seo-personal.ru/blog/screaming-frog/straniczy-bez-kartinok/




