




Тендеры и лиды
Информация
Мы занимаемся не только созданием цифровых решений для клиентов, но и активно развиваем собственные IT-продукты и стартапы. Опыт в разработке и продвижении собственных проектов напрямую помогает нам в в понимании задач бизнеса клиента в аутсорсинговой разработке. Один из наших стартапов — онлайн-ассистент «Я здоров», в основе которого лежат технологии AI/ML.
В основе идеи продукта лежит мысль о том, что людям важно не периодически лечиться от болезней, а поддерживать здоровье постоянно и превентивно. Мы верим, что будущее — за профилактикой и регулярным мониторингом состояния здоровья, а не за решением проблем со здоровьем по мере их поступления.— Основатель ASAP, Даниил Васильев
Сегодня ожидания людей часто не совпадают с тем, как устроена система здравоохранения:
Большинство стремится поддерживать здоровье, а медицина в основном лечит уже возникшие болезни. Обычно происходит так: человек живет привычно, заболевает, попадает к врачу, лечится и возвращается к повседневности — до следующего обращения. Это разрозненный подход.
Современные тенденции в медицине указывают на перемены:
Прогресс технологий, в частности ИИ и машинного обучения, дает возможность анализировать большие объемы медицинских данных и выявлять проблемы на ранних стадиях.
Главная цель продукта — сформировать экосистему, которая объединяет всю доступную информацию о здоровье человека, проводит анализ и выдает индивидуальные рекомендации по питанию, образу жизни, обследованиям и выбору специалистов.
Задача — обеспечить постоянный контроль состояния здоровья, а не только разовое устранение недугов.
Ассистент здоровья — это комплексное решение для работы с медицинской информацией, общения с врачами и хранения документации в одном месте. Фактически — «семейный доктор» в смартфоне. Уже доступны следующие функции:
Медицинская карта. Сохранение всех результатов обследований, анализов и врачебных назначений с удобной сортировкой по папкам.
Загрузка и распознавание бланков. Прием фото- и pdf-файлов с автоматическим распознаванием данных и возможностью их корректировки перед сохранением.
Семейный профиль. Ведение карт здоровья для членов семьи и быстрое переключение между ними.
Работа с медицинскими специалистами. Настройка прав доступа врачей к карте и участие в опросах.
Текстово-голосовой ассистент. Управление функциями приложения и получение медицинских ответов в текстовом и голосовом формате.
Одним из первых реализованных модулей приложения стала универсальная медицинская карта. Она позволяет в одном месте хранить все результаты анализов, обследований и назначения специалистов, с возможностью быстрого доступа в любое время.
При этом важно, чтобы данные загружались корректно и были правильно интерпретированы. На этом этапе мы выделяем два ключевых аспекта:
Вносить результаты анализов вручную не только долго, но и неудобно.
Поэтому одной из ключевых функций стало предоставление возможности загрузить в приложение документ или фото бланка анализа, чтобы система автоматически распознала данные, упорядочила их и показала в наглядном виде. Сервис должен сохранять историю изменений, строить графики и фиксировать отклонения от нормы. При этом критически важно избежать ошибок, ведь от точности интерпретации напрямую зависит здоровье пользователя.
В этой публикации мы расскажем, как подошли к решению этой задачи, с какими барьерами столкнулись, какие промежуточные результаты получили и что продолжаем улучшать.
Нужно было реализовать обработку бланков анализов из разных лабораторий — как в виде файлов, так и фотографий — с сохранением данных со следующими полями:
Формы бланков значительно разнятся.
Для извлечения текста из изображения применяется OCR-модель — технология, переводящая печатный документ в цифровой текст.
Но для нас было важно не просто получить распознанный текст, а структурировать его так, чтобы каждая строка содержала название биомаркера, его значение, единицу измерения и референсы. Отсутствие единого стандарта оформления бланков заметно усложняет задачу.
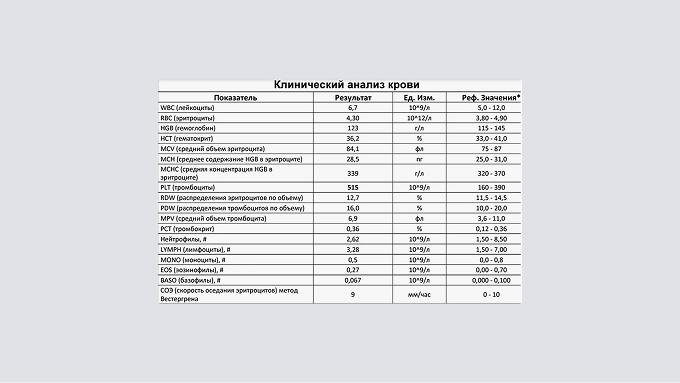
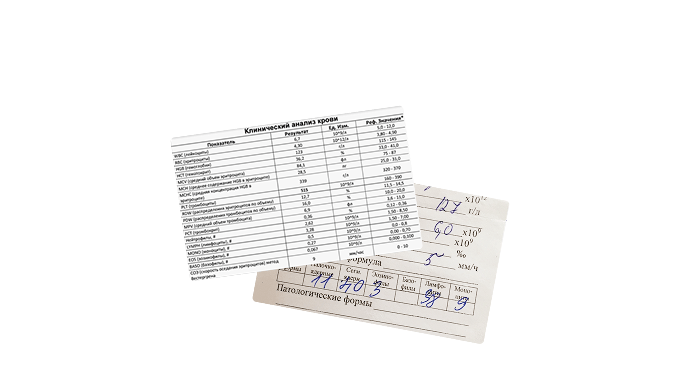
Так выглядит нормальная структура бланков
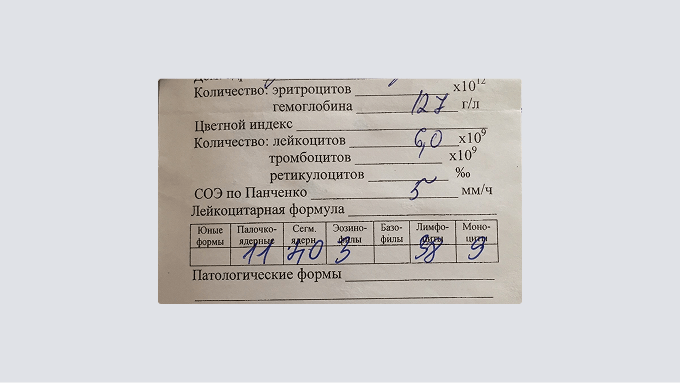
Но бывают и такие
Кроме того, встречаются изображения с низким качеством, плохим контрастом или другими дефектами.
В итоге OCR может пропустить часть данных, ошибиться в распознавании или выдать результат в том виде, который невозможно корректно структурировать.
Синонимы и сокращения
Многие биомаркеры имеют десятки и даже сотни синонимов. Лаборатории нередко используют собственные сокращённые варианты названий. При этом один и тот же показатель может быть представлен как абсолютным, так и процентным значением.
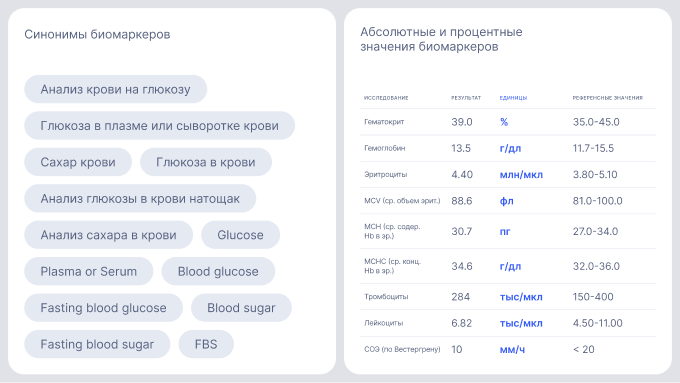
Чтобы избежать ошибок, система должна определять биомаркеры вне зависимости от того, как именно они записаны. Если этого не сделать, один и тот же маркер будет отображаться в истории и графиках как разные показатели, что приведёт к искажению данных и снижению точности прогнозных моделей.
Для минимизации ошибок требуется собрать обширную базу синонимов, вариантов написания и единиц измерения. Тем не менее, всегда существует риск встретить уникальное сокращение, которое не совпадает ни с одним из известных системе.
Верхнеуровневый пайплайн решения мы построили следующим образом:
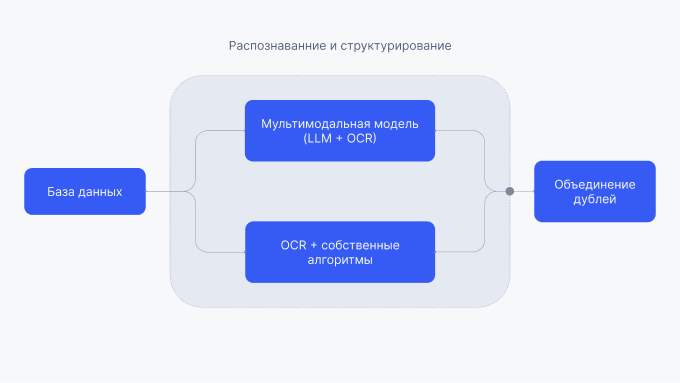
Сначала формируем базу данных. Далее выполняем распознавание и структурирование информации с помощью мультимодальной модели, а также OCR в сочетании с собственными алгоритмами. Затем проводится определение биомаркеров и объединение повторяющихся записей.
Сбор базы данных биомаркеров, единиц измерения и референсных значений
Для корректной работы алгоритмов распознавания и бесперебойного функционирования приложения была необходима полная структурированная база, в которую входят:
Референсные значения зависят от категории пациентов
Это очевидный момент: показатели одного и того же биомаркера могут меняться в зависимости от пола, возраста и других характеристик пациента. Поэтому для каждого биомаркера мы сохраняем несколько наборов референсных значений — по различным группам пациентов.
Индивидуальные коэффициенты пересчета для одинаковых единиц
Менее заметный, но важный аспект: коэффициенты пересчета между единицами зависят от конкретного биомаркера.
Пример:
Наша система сама подберет вам исполнителей на услуги, связанные с разработкой сайта или приложения, поисковой оптимизацией, контекстной рекламой, маркетингом, SMM и PR.
Заполнить заявку
13334 тендера
проведено за восемь лет работы нашего сайта.
Представьте, что при измерении длины дивана в одном случае 1 метр равен 100 см, а в другом — 90 см. Хотя звучит странно, в лабораторной практике встречается похожее.
Например:
• глюкоза: мг/дл × 0,0555 → ммоль/л
• молочная кислота: мг/дл × 0,111 → ммоль/л
Это показывает, что для каждого биомаркера нужен свой коэффициент пересчета, который обязательно учитывается и хранится в базе данных.
Сбор такой базы — сложная задача. На сегодняшний день у нас более 2000 уникальных биомаркеров, и для каждого необходимо:
Для наполнения базы мы используем два основных источника:
Далее вся информация агрегируется, структурируется и проверяется на точность. Таким образом, база биомаркеров формируется как результат последовательного сбора, сопоставления и нормализации большого объема медицинских данных с учетом единиц измерения и особенностей пациентов.
Следующий этап — извлечение текста с изображений бланков. Для этого мы используем OCR (оптическое распознавание символов) и собственные алгоритмы анализа и структурирования данных. Мы тестировали несколько OCR-систем, включая Yandex OCR и другие решения. В текущей версии проекта остановились на Tesseract OCR.
Предобработка изображений перед распознаванием включает:
На первый взгляд может показаться, что достаточно распознавать текст по строкам. Однако на практике это неэффективно: некоторые строки — заголовки, подкатегории или техническая информация, не содержащие биомаркеров. Поэтому мы анализируем отдельные блоки, где каждый участок изображения интерпретируется в контексте: где биомаркер, где его значение, а где — нерелевантные данные.
После OCR мы получаем текст и координаты каждого элемента на изображении. Далее мы выполняем:
На этом этапе мы сталкиваемся с проблемой: из-за множества синонимов и сокращений текстовое совпадение не всегда точное, и система может принять уже существующий биомаркер за новый, что приводит к дубликатам.
Для решения этой задачи мы использовали векторный поиск. Он сравнивает слова не по буквальному совпадению, а по смысловой близости. Но и здесь возникла трудность: стандартные векторизаторы настроены на естественные тексты на русском и английском языках. Биомаркеры и их синонимы формируют «неестественный язык» с особыми правилами смысловой близости и различий.
Этот подход рассматривается как альтернативный вариант при разработке системы распознавания медицинских документов с применением мультимодальной модели (OCR + LLM).
Идея подхода
Первоначально мы создали собственный OCR-алгоритм с надстройками для структурирования данных. Метод работал, но требовал сложной логики и постоянной поддержки. Во втором подходе мы решили упростить процесс: полностью передать задачу распознавания и структурирования мультимодальной модели.
Проще говоря, файл вместе с промтом, описывающим структуру данных, отправляется модели, а она извлекает информацию и возвращает её в нужной форме.
При выборе моделей мы столкнулись с рядом сложностей
После серии тестов мы выбрали модель Qwen 7B. Параллельно продолжаем тестировать оба подхода — классический OCR и мультимодальную модель. Точность распознавания примерно одинаковая, но вариант с LLM требует меньше кода и логики для работы. Собственный алгоритм тоже имеет плюсы: требует меньше ресурсов и более прозрачен.
Сейчас мы выбираем финальное решение. Нам важно сохранить бесплатный доступ к функциям работы с медкартой, включая распознавание документов, поэтому критичны не только точность, но и экономичность алгоритма.
Точность распознавания: полноценное тестирование на больших массивах данных ещё не проведено, но текущие результаты обнадеживают. Точность распознавания биомаркеров превышает 90%.
Как мы это измеряли
Методика оценки прозрачная: тестовая выборка — около 100 бланков медицинских анализов, в каждом — в среднем 20 биомаркеров. Качество бланков разное: от четких PDF с таблицами до менее удачных вариантов.
Бланки проходили через систему распознавания, данные по биомаркерам извлекались и сверялись с оригиналом. Более 90% данных совпали с исходными, что позволяет использовать систему в реальных сценариях.
Проблема обработки дублей биомаркеров: вызов для векторного поиска
Ключевая сложность на этом этапе — работа с дубликатами биомаркеров. Основная задача — сопоставить распознанные значения с уже существующими записями базы, включая синонимы. Это необходимо для правильного ведения истории изменений показателей и предотвращения создания лишних биомаркеров.
Ранее мы пробовали использовать стандартный текстовый поиск, но он не справился с задачей. Обычные методы векторного поиска также не показали удовлетворительных результатов. Как уже упоминалось выше, базовые векторизаторы распознают русский и английский языки, однако биомаркеры и их синонимы воспринимаются как «неестественный язык».
В связи с этим рассматривается подход дообучения эмбеддинговой модели для векторного поиска. Планируется использовать корпус уже собранных названий биомаркеров и их синонимов для создания троек: исходный биомаркер, близкое по смыслу значение и далёкое по смыслу значение. Также предусмотрено дальнейшее обучение векторизатора с помощью метода Contrastive Learning.
Цель — адаптировать модель под конкретную предметную область, чтобы она могла корректно различать и интерпретировать медицинские термины, связанные с биомаркерами. Такой подход позволит существенно повысить точность сопоставления и снизить риск дублирования данных.
Когда этот процесс будет завершён, мы обязательно опубликуем отдельную техническую статью.
Мы не собираемся останавливаться на достигнутом. Медицинская карта приложения «Я здоров» должна быть больше, чем просто место для хранения данных — её функционал будет шире. В будущем планируется с помощью ML-моделей на основе полученных данных формировать рекомендации для пользователей: по дополнительным анализам, обследованиям у профильных врачей и другим действиям.
Работа над приложением не ограничивается этим: мы планируем развивать и другие функции, чтобы сделать «Я здоров» комплексным помощником по здоровью, который всегда будет под рукой.
В планах разработки:
Проект «Я здоров» создаёт условия для формирования новой парадигмы здравоохранения, где поддержка здоровья осуществляется непрерывно с помощью технологий, сбора данных и персонализированного подхода. Это вдохновляет нашу команду продолжать работу.
Спасибо всем, кто дочитал до конца. Мы запустили сайт сервиса «Я здоров» — yazapp.ru, и готовимся к релизу продукта. Оставьте заявку по ссылке, чтобы получить доступ к регистрации одними из первых.
•

