Тендеры и лиды
Информация
NDA
3 000 000
Государство и общество
Швейцария, Zürich
Февраль 2026
Создать и внедрить AI-ассистента как единую интеллектуальную точку входа в поддержку для сайта и личного кабинета, чтобы ускорить получение информации и повысить качество сервиса при высокой нагрузке.
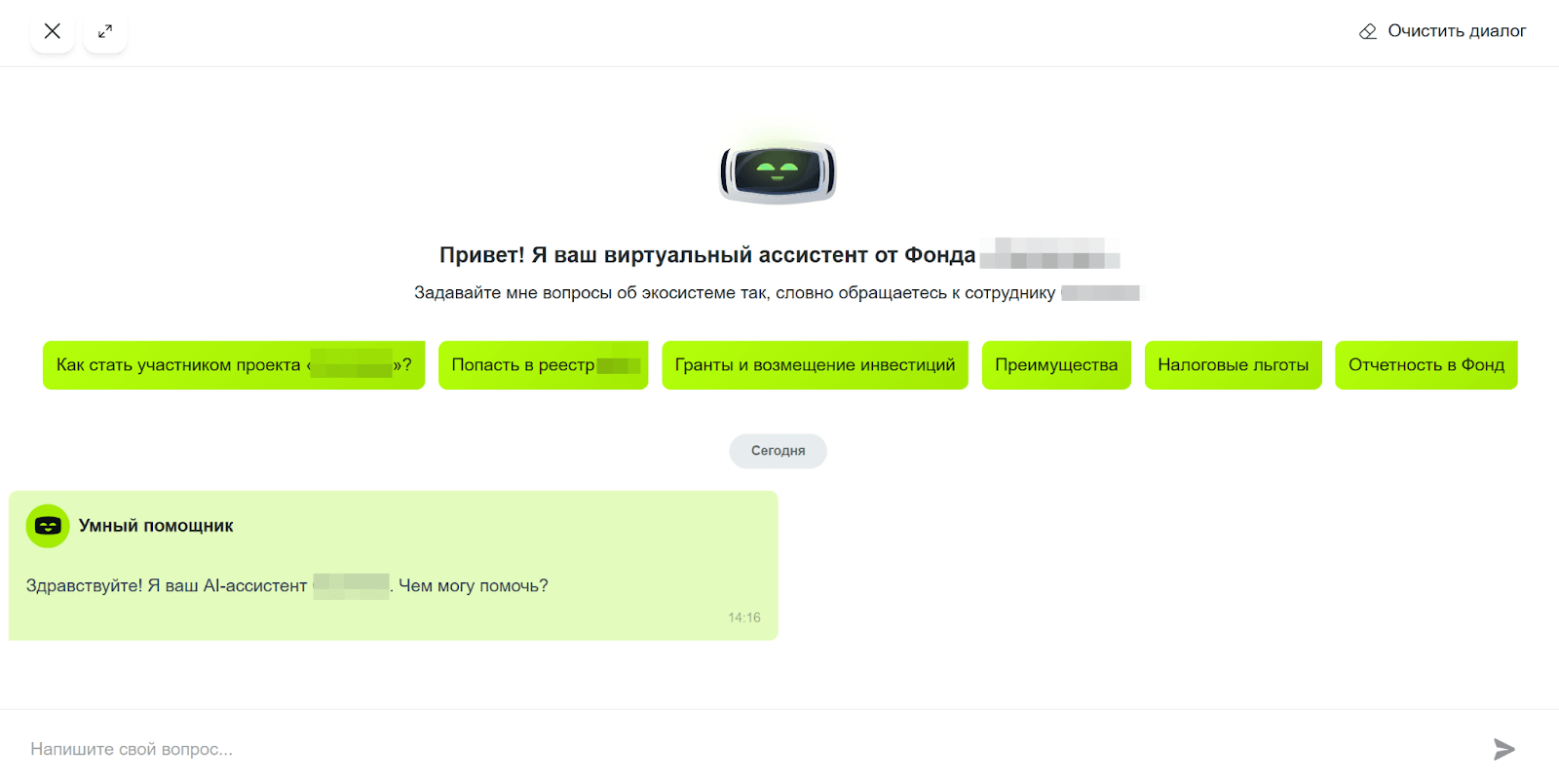
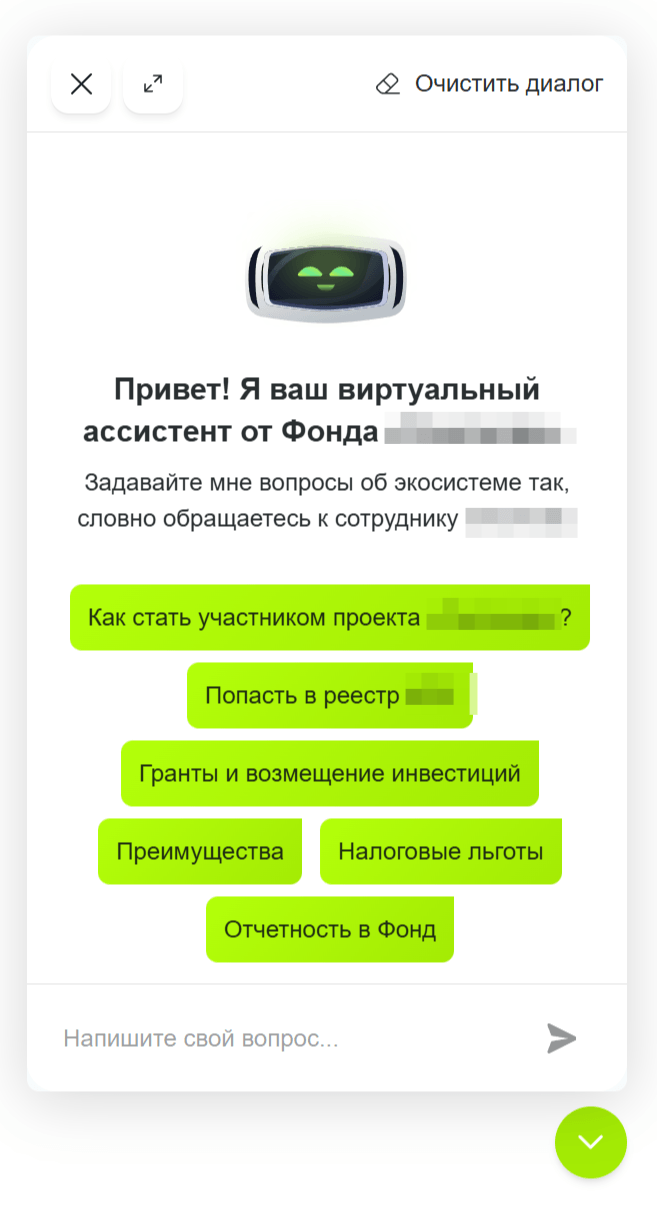
Мы создали AI-ассистента для публичного сайта и личного кабинета — единую интеллектуальную точку входа для разных аудиторий экосистемы: стартапов и инновационных команд, компаний-участников, жителей и гостей территории, а также экспертов и менторов. Ассистент 24/7 отвечает на типовые вопросы по статусу участника, доступным мерам поддержки и льготам, административным процессам и услугам, инфраструктуре и событиям, работе с заявками и выплатами.
Он ищет ответы в большом массиве разрозненных официальных документов и регламентов, собранных из разных источников, учитывает базу знаний AutoFAQ, что позволяет структурировать информацию, снизить нагрузку на поддержку и ускорить получение ответов для пользователей.
AI-ассистент работает на базе LLM с RAG-архитектурой. Он способен:
● вести контекстный диалог с пользователем;
● искать ответы в официальных источниках;
● учитывать приоритет базы знаний AutoFAQ.
Определили ключевые пользовательские сегменты и интенты для сайта и личного кабинета, зафиксировали типовые запросы и правила, по которым обращения должны эскалироваться к операторам (Human-in-the-Loop).
Подключили приоритетный источник — базу знаний AutoFAQ, дополнительно собрали и структурировали официальные документы Фонда, контент сайта sk.ru и его поддоменов, а также новости и события для обеспечения достоверных ответов.
Реализовали AI-ассистента на базе LLM с RAG-архитектурой: он ведёт контекстный диалог, ищет ответы в официальных источниках, учитывает приоритет AutoFAQ и при необходимости перенаправляет запрос оператору.
Спроектировали и внедрили асинхронную микросервисную архитектуру с очередями задач и масштабируемыми воркерами, развернули компоненты LLM Platform, RAG-пайплайн, Qdrant (векторная база), PostgreSQL (диалоги и аналитика), Redis + BullMQ (асинхронная обработка) и интеграцию с AutoFAQ.
Создали административную панель для просмотра истории диалогов, управления базой знаний, мониторинга качества, аналитики активности и вовлечённости, а также настройки ассистента без участия разработчиков; настроили логирование всех обращений для постоянного улучшения.
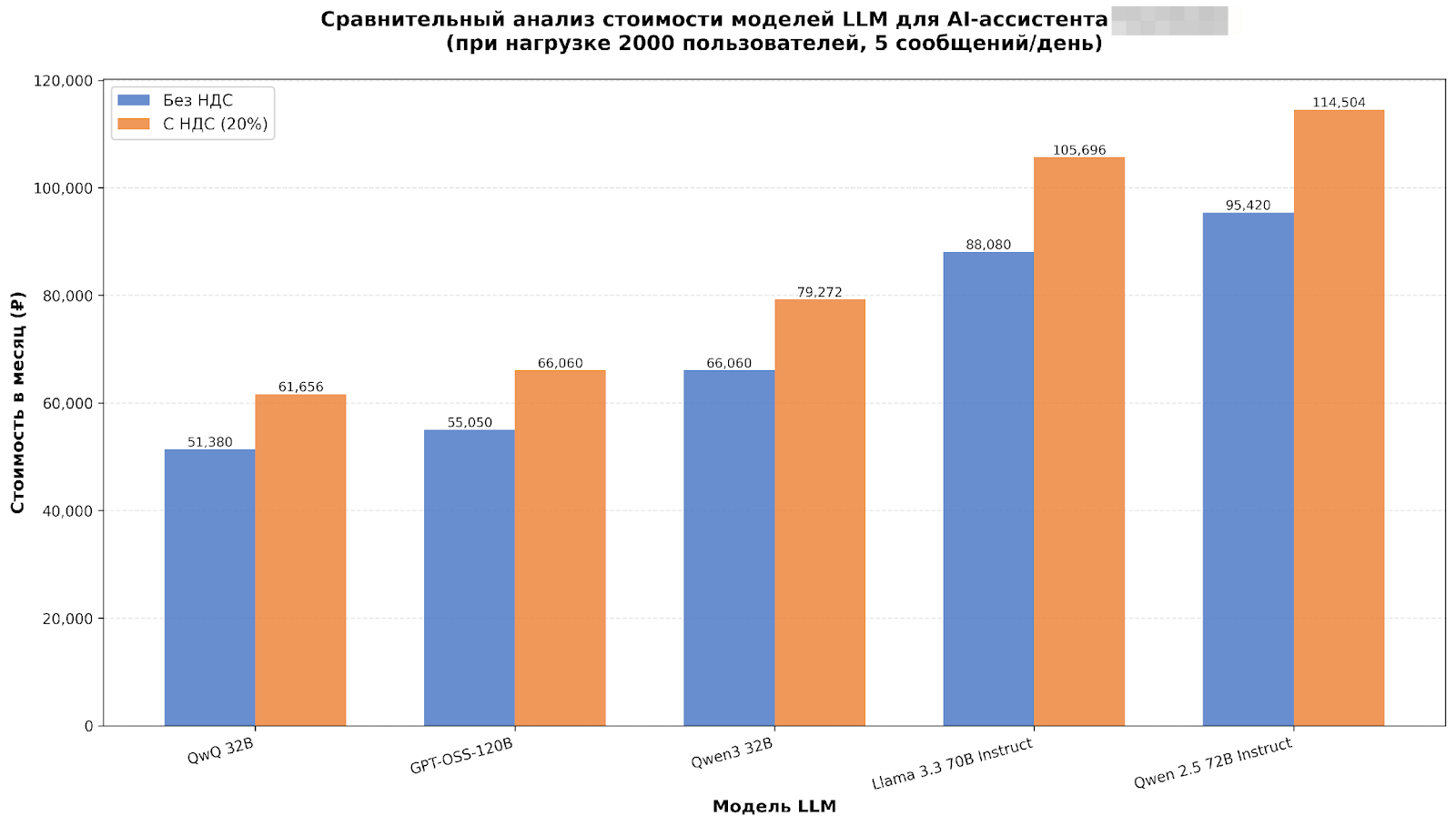
Мы провели сравнительное тестирование LLM для AI-ассистента, чтобы выбрать оптимальную модель при требовании не ниже 70% точности на типовых пользовательских запросах.
Для этого мы протестировали 5 больших языковых моделей на 20 тестовых кейсах, покрывающих ключевые сегменты целевой аудитории. Система тестирования была построена на базе встроенного функционала LLM-платформы и включала Datasets (наборы входных запросов и эталонных ответов), Evaluators (автоматизированные критерии оценки: RAGAS + LLM-as-a-Judge на GPT-4.1) и Analytics Dashboard для мониторинга результатов и визуализации метрик.
Дополнительно мы рассчитали ежемесячную стоимость эксплуатации каждой модели и подтвердили, что использование GPT-OSS-120B обеспечивает экономически обоснованные операционные расходы.
По итогам оценки качества, стабильности и стоимости владения для промышленной эксплуатации была выбрана модель Cotype 2 Pro от MTS AI. Модель продемонстрировала 87,8% Accuracy, что на 17,8 п.п. превышает целевой порог, и показала наилучший баланс между точностью, предсказуемостью ответов и операционными расходами.
Cotype 2 Pro особенно уверенно работает с ключевыми типами обращений — информационными (93,8%) и процедурными (83,3%) запросами, которые формируют около 70% всего пользовательского потока, обеспечивая стабильные и достоверные ответы в режиме 24/7 при высокой нагрузке.
Стабильная работа под высокой нагрузкой
Существенно снижена нагрузка на службу поддержки
Повышена доступность и прозрачность информации для пользователей
Повышена доступность и прозрачность информации для пользователей
Точность ответов 87,8%
Частота ошибок 15%
Время ответа до 10 секунд

