Тендеры и лиды
Информация


ГК ФСК
Строительство и ремонт
Россия, Москва
Июль 2023
ГК ФСК ведет активное развитие девелоперских проектов, что влечет за собой потребность в привлечении большого количества подрядчиков. С ростом количества проектов и подрядчиков увеличиваются трудозатраты компании по рутинным операциям, что могло бы привести к увеличению штатной численности сотрудников.
Есть большой отдел специалистов-сметчиков, которые вручную обрабатывают описания видов строительных работ и сопоставляют с классификатором ГК ФСК. Это монотонный, длительный процесс, при котором возможны ошибки (человеческий фактор).
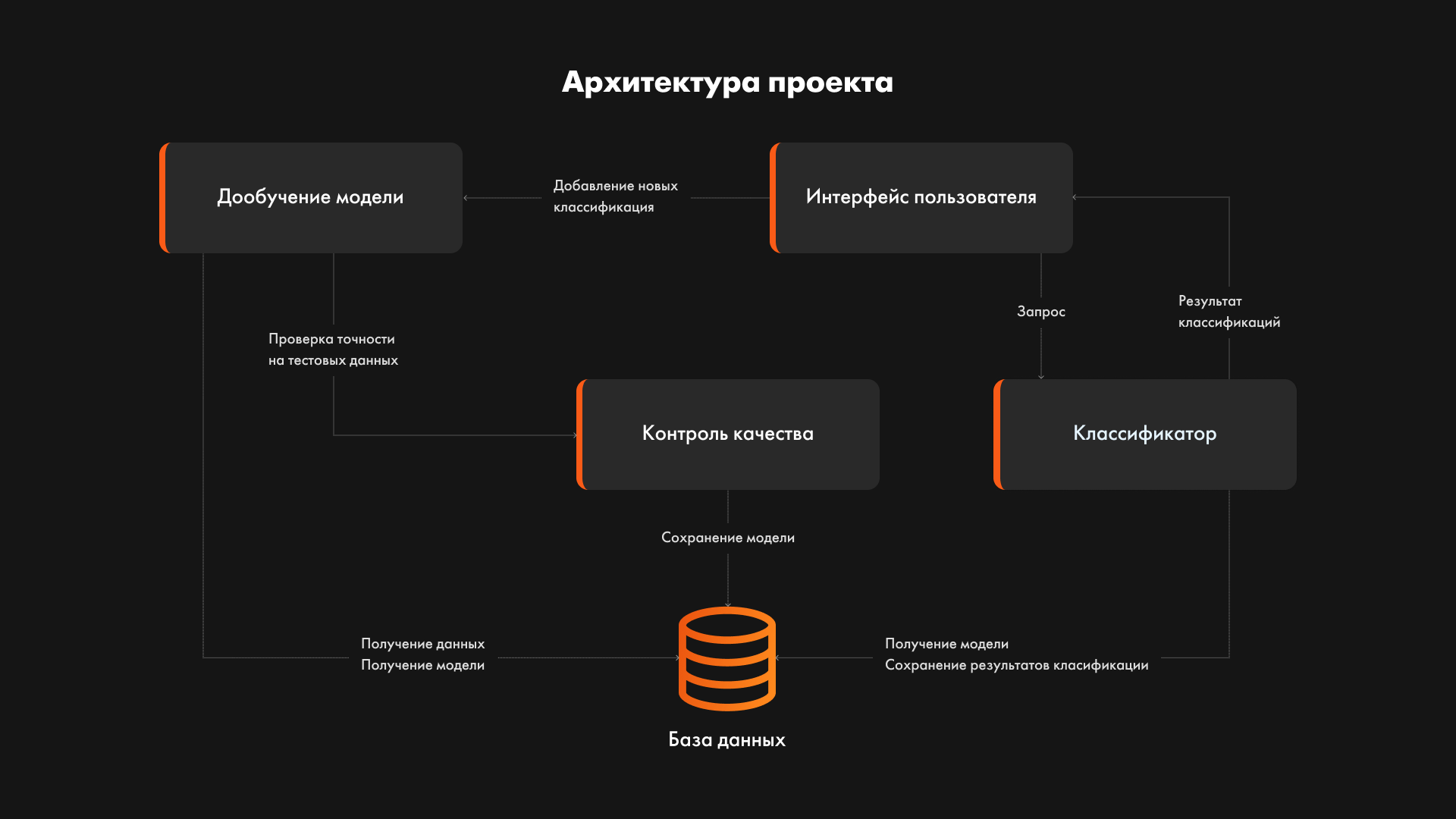
Разработка API-сервиса, интегрированного во внутренний контур ГК ФСК. В основе сервиса лежит нейросетевая модель, которая работает локально и работает офлайн, данные не покидают серверов компании.
Принцип работы сервиса следующий:
1. Сотрудник компании в интерфейсе системы передает текстовые описания видов работ, которые необходимо отнести к классам из перечня классификатора компании;
2. При помощи API эти данные в формате json передаются в модуль классификации. В нем данные предварительно обрабатываются, валидируются, переводятся в математический вид;
3. Подготовленные данные передаются на вход математической модели, и для каждого текстового описания она возвращает топ-5 возможных классов из списка классификатора, с процентами вероятности;
4. Предсказания по API возвращаются в интерфейс пользователя, где он может валидировать результаты предсказаний.
Кроме того, в модель заложен модуль переобучения математической модели. Если у клиента изменились данные (появились новые текстовые примеры, новые классы и т.д.), он может инициировать процесс переобучения модели. Если новая модель удовлетворяет метрикам качества, то она заменяет текущую модель сервиса.
— Проект реализован за 3 месяца
— Отмечено повышение точности классификации для малых классов в среднем на 15% за счет решения проблем дисбаланса классов
— Обучено 6 математических моделей: 4 нейросетевых модели типа трансформер и 2 комбинированных модели на основе текста и нейросетевых текстовых представлений
— Более 96 часов потрачено на обучение моделей
Разное количество примеров данных для каждого класса
Обычно сырые данные редко представлены в одинаковом объеме, какие-то работы проводятся реже (заливка фундамента), а какие-то в больших объемах (отделочные работы помещений). Чтобы модель могла эффективно отличать такие текстовые описания, необходимо достаточное количество примеров, а лучше - одинаковое для всех классов. В выборке были классы как с 1, 2, 3 примерами текста, так и с 5000, 12000 примеров. Необходимо было найти способ для улучшения качества классификации таких малых классов. Были созданы искусственные примеры текстовых описаний, которые позволили улучшить точность классификации для этих классов на десятки процентов.
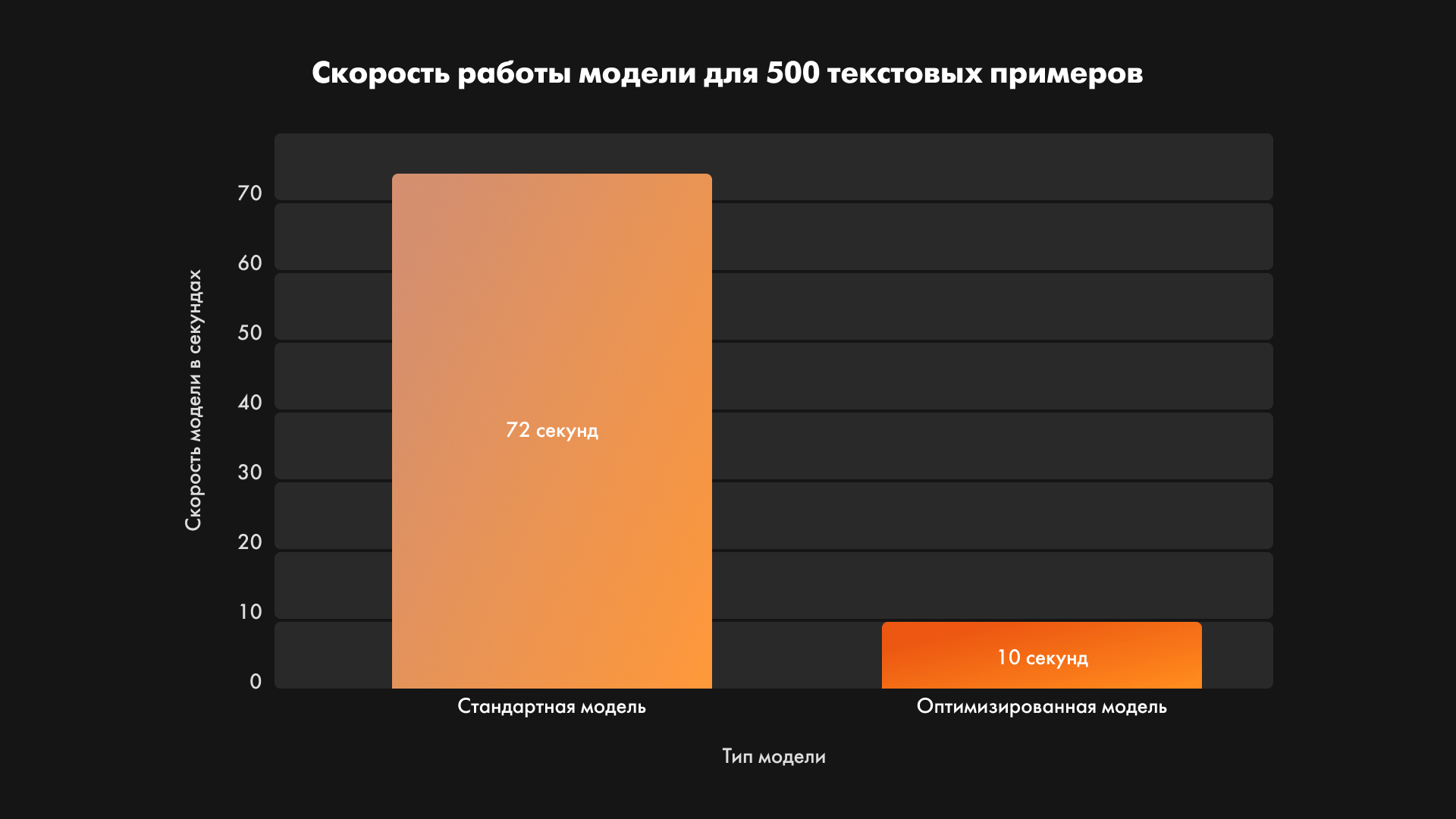
Ускорение работы модели на CPU
Современные нейросетевые модели хотя и являются мощными решениями задач естественной обработки языка, но они очень медлительны и объемны при работе на пользовательских ЦП. Наши аналитики нашли способ ускорения этого процесса, снизив время обработки 500 фраз в 256 символов до 1 секунды, включая весь процесс обработки.
— Автоматизировано рабочее место специалиста-сметчика (38 рабочих мест)
— Минимизация трудозатрат в 7 раз и отказ от привлечения дополнительных двух специалистов-сметчиков для определения статей затрат по каждому элементу сметы за счет использования ИИ
— Точность нейросетевой модели более 90%
— Скорость работы ИИ – 500 строк за 1 секунду на CPU
— Reliable ML-продукт, не требующий поддержки: модель автоматически переобучается, отслеживаются метрики качества
— Проект реализован за 3 месяца.

Александр Цай
Данный проект – отличный пример небольших ИИ-проектов с точки зрения сроков реализации и стоимости, которые дают эффективное и измеряемое экономическое value для заказчика.











