Тендеры и лиды
Информация


Сеть отелей по РФ
Туризм и отдых
Россия
Сентябрь 2025
Компания ежемесячно выгружает из helpdesk-системы отчеты о задачах сотрудников для последующего анализа. Объем данных составляет в среднем 4000 строк и 10 столбцов. Перед формированием итогового отчета таблицу необходимо нормализовать: скорректировать названия задач, удалить названия контрагентов и отелей, служебные пометки, унифицировать формулировки, а также исключить нерелевантные задачи (отпуска, командировки, собеседования).
Ручная обработка такого массива данных занимала у специалиста целую рабочую неделю, что создавало несколько проблем: длительное время подготовки отчетности, высокая вероятность ошибок из-за монотонной работы и нерациональное использование рабочего времени квалифицированного сотрудника.
Клиент обратился к нам с запросами:
1. Автоматизировать процесс нормализации данных в таблицах с задачами.
2. Сократить время подготовки ежемесячных отчетов.
3. Минимизировать человеческий фактор и повысить точность обработки данных.
4. Освободить специалиста от рутинной работы для решения более важных задач.
Нами было предложено:
1. Создать специализированного AI-агента на базе нейросети Gemini
2. Разработать четырехэтапный бизнес-процесс нормализации: подготовка таблицы с добавлением новых столбцов, переписывание названий задач по заданным правилам, простановка признаков удаления и формирование итоговой таблицы.
3. Оптимизировать обработку данных путем разделения исходной таблицы на части для корректной работы в рамках контекстного окна нейросети.
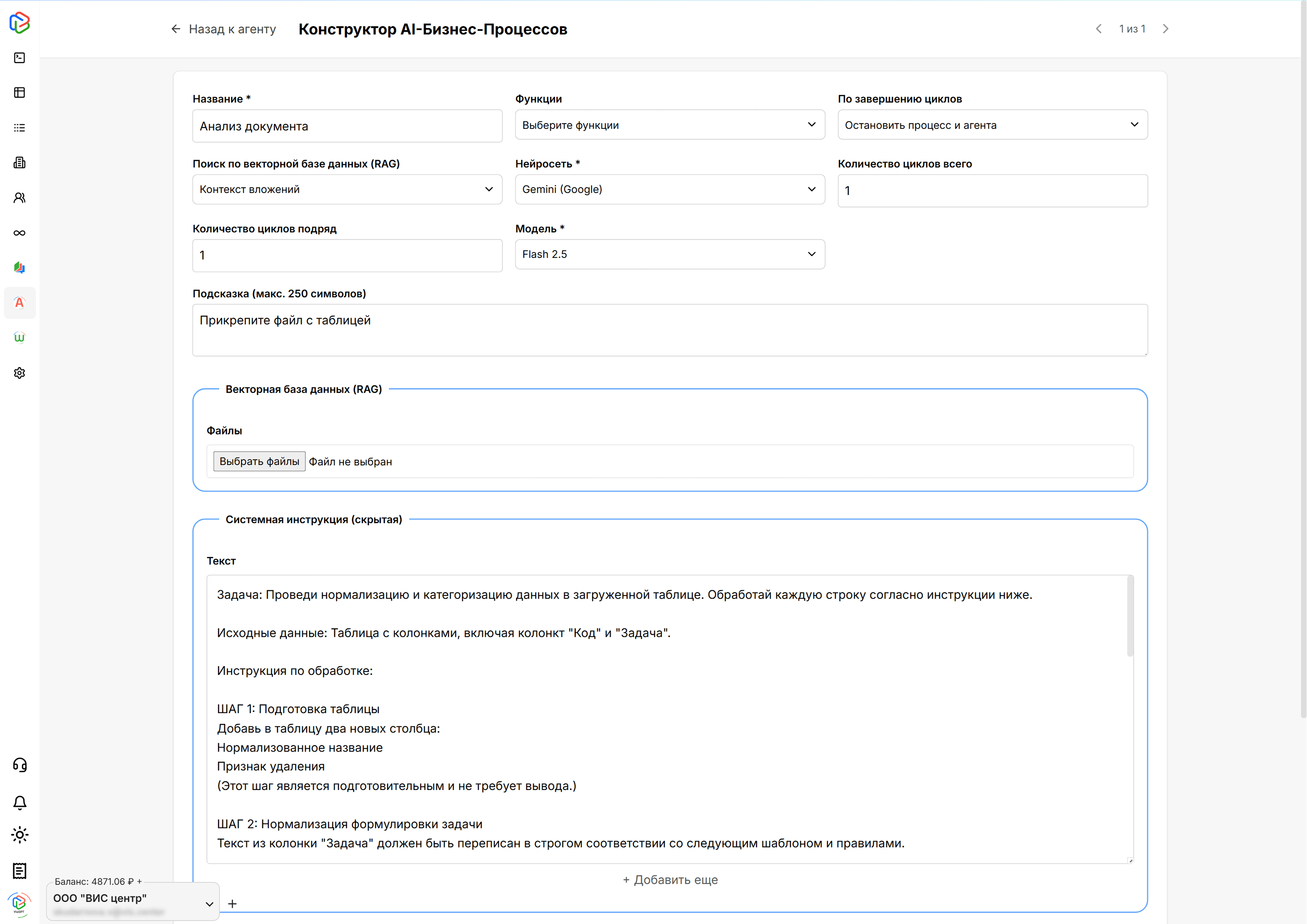
В сервисе VisGPT https://gpt.vis.center доступен конструктор для создания ИИ-агентов, которые состоят из AI бизнес-процессов и выполняют задачи поэтапно. Для каждого этапа можно задать отдельные инструкции и выбрать оптимальную нейросеть.
Нейросеть Gemini Flash была выбрана благодаря увеличенному контекстному окну в 1 млн токенов, что позволяет обрабатывать большие таблицы, и высокой скорости работы с данными. Агент получил четкие инструкции по нормализации: как менять названия задач, как унифицировать формулировки (например, «не работает» → «анализ ошибок»), и по каким критериям помечать задачи для удаления.
Нормализация таблицы происходит за 4 шага:
ШАГ 1: Подготовка таблицы
В загруженную исходную таблицу нейросеть добавляет два новых столбца — “нормализованное название” и “признак удаления”.
ШАГ 2: Нормализация формулировки задачи
Нейросеть переписывает исходные названия задач в едином виде по заданным правилам. Корректирует названия, убирает служебные отметки, меняет формулировки, например «не работает», «ошибка» → анализ ошибок, «не проводится» → анализ алгоритма проведения. Новые названия добавляются в соответствующий столбец новой таблицы.
ШАГ 3: Простановка признака удаления
Если в исходном тексте колонки "Задача" встречается слово "отпуск", "командировка", "собеседование", нейросеть добавляет значение “удалить” в новый столбец.
ФИНАЛЬНЫЙ ШАГ 4: Вывод результата
После обработки всей таблицы, ИИ-агент генерирует итоговую новую таблицу с дополнительными столбцами и правильными формулировками.
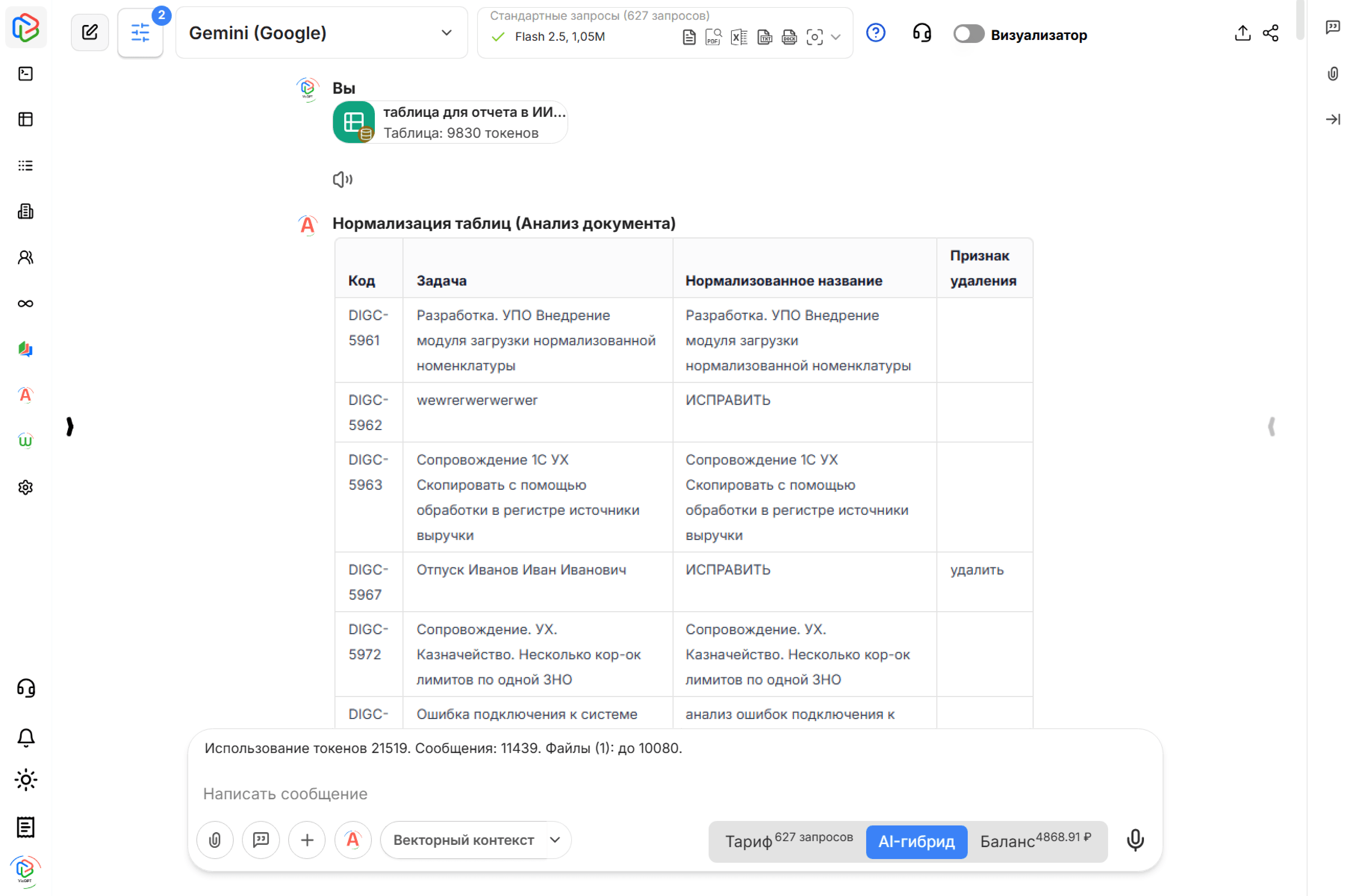
Даже с контекстным окном в миллион токенов, обработать такую большую таблицу у нейросети нет возможности. Когда количество сообщений превышает лимит контекстного окна, самые ранние сообщения начинают "забываться" моделью. ИИ-агент распознает только часть таблицы и обрабатывает неполные данные.
Контекстное окно — это объем информации, который нейросеть может проанализировать за один запрос. Измеряется в токенах – это базовые единицы обработки текста для нейросетей, представляющие части слов, целые слова или знаки пунктуации. В русском языке один токен соответствует примерно 0,7-0,8 слова (или ~4-6 символам). Так, текст из 1000 слов может содержать около 1300-1400 токенов
Опытным путем мы определили оптимальный объем таблицы, который нейросеть “видит” полностью. Исходную таблицу необходимо разделить на несколько частей и оставить столбцы, по которым нужно провести нормализацию. После обработки каждой части нейросетью, их можно объединить в единую новую таблицу вручную и предоставить для отчета.
Нейросеть не заменила специалиста. Сейчас работа человека по-прежнему нужна, но она заключается в подготовке данных для нейросети, управлении процессами ИИ-агента и проверкой полученного результата.
Ранее ручная обработка такой таблицы требовала недели работы специалиста. Теперь весь процесс занимает один рабочий день.

Тимур Космодемьянов
Обработка больших объемов данных для составления отчетности - один из многочисленных способов применения AI-агентов и нейросетей VisGPT. Наш опыт и экспертиза позволят найти решение для любых нестандартных и объемных бизнес-задач https://ai.vis.center


