Тендеры и лиды
Информация

Онлайн-агрегатор инвестиционных проектов
1
Финансы, страхование, инвестиции
Россия
Апрель 2025
Кейс внедрения доработанной Retrieval-Augmented Generation (RAG) показывает, как технология помогла инвестиционной онлайн-платформе превратить ограничение стандартных языковых моделей в точку роста. При заполнении векторной базы система обрабатывала один «зашумленный» источник данных за 1 минуту при нагрузке около 3 000 токенов, обеспечивая высокую скорость индексации и качество данных для последующего интеллектуального поиска.
Для заказчика внедрение системы интеллектуального поиска информации означает повышение качества цифрового продукта, рост вовлеченности аудитории и сохранение пользователей, которые раньше уходили из-за нерелевантных ответов. Решение укрепило доверие к платформе и открыло возможности дальнейшего развития.
Заказчик
Заказчик — онлайн-платформа-агрегатор инвестиционных проектов, консалтинговых услуг, компаний торговли драгметаллами, недвижимостью. Ресурс объединяет предпринимателей, инвесторов, профессиональные сообщества, компании, представляющие инвестиционные возможности в единую информационную среду. Основная задача ресурса — обеспечить удобное взаимодействие между участниками: предприниматели получают возможность презентовать проекты, находить партнеров и капитал, инвесторы — подбирать проекты по заданным критериям и напрямую связываться с их авторами, консультанты — предлагать сопровождение, участники рынков недвижимости и драгоценных металлов — предоставлять спектр инструментов для управления рисками.
Таким образом, платформа способствует развитию инвестиционной и предпринимательской экосистемы, упрощая доступ к финансированию, расширяя деловые связи и повышая прозрачность рынка.
Проблема, с которой столкнулся Заказчик
Пользователи платформы формулируют сложные запросы, используя профессиональные термины, и прописывают контекстные условиями. Например:
· инвестор ищет компании на определенной стадии развития с зарегистрированными патентами, или оценивает инвестиционные возможности в сфере недвижимости и драгметаллов для диверсификации портфеля;
· корпоративный заказчик подбирает стартапы с конкретной технологией или бизнес-моделью;
· предприниматель интересуется программами гос.поддержки, доступными для его направления деятельности, орг.устройства и т.д.
Стандартный поиск выдавал обобщенные результаты, не учитывал бизнес-контекст и требовал ручной фильтрации. В итоге у пользователей возникало ощущение, что платформа не улавливает сути их запроса. Такая проблема типична для сервисов с отсутствием технологий обработки естественного языка и инструментов персонализации поиска.
Для заказчика это означало три риска:
· снижение доверия ЦА,
· падение роли платформы как инструмента принятия решений,
· снижение интереса к платформе, и отток пользователей.
Чтобы изменить ситуацию, команда ItFox предложила заказчику перестроить логику взаимодействия с пользователями. А именно, доработать поиск, внедрив RAG.
Внедрение RAG-технологии позволило он-лайн-платформе учитывать бизнес-контекст запросов и давать высоко релевантные ответы на запросы пользователей. С этого момента поиск перестал быть просто "навигацией по сайту" и превратился в механизм экспертизы и доверия клиентов.

Чтобы изменить характер поисковой выдачи, мы начали с архитектуры. Модуль был разработан как связка двух компонентов:
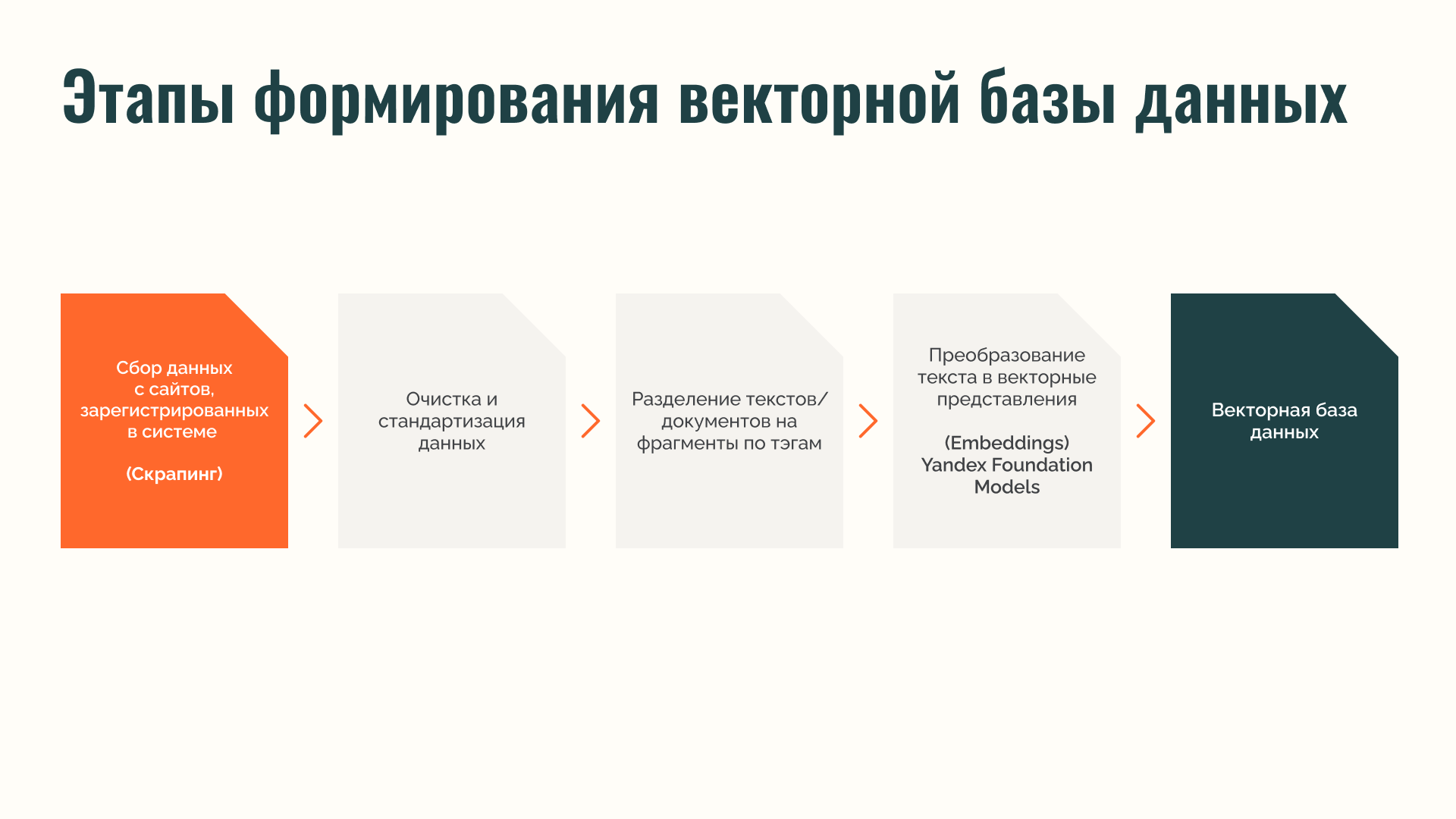
1. Индексирование данных (Indexing) — сбор, очистка и структурирование информации об зарегистрированных участниках платформы.
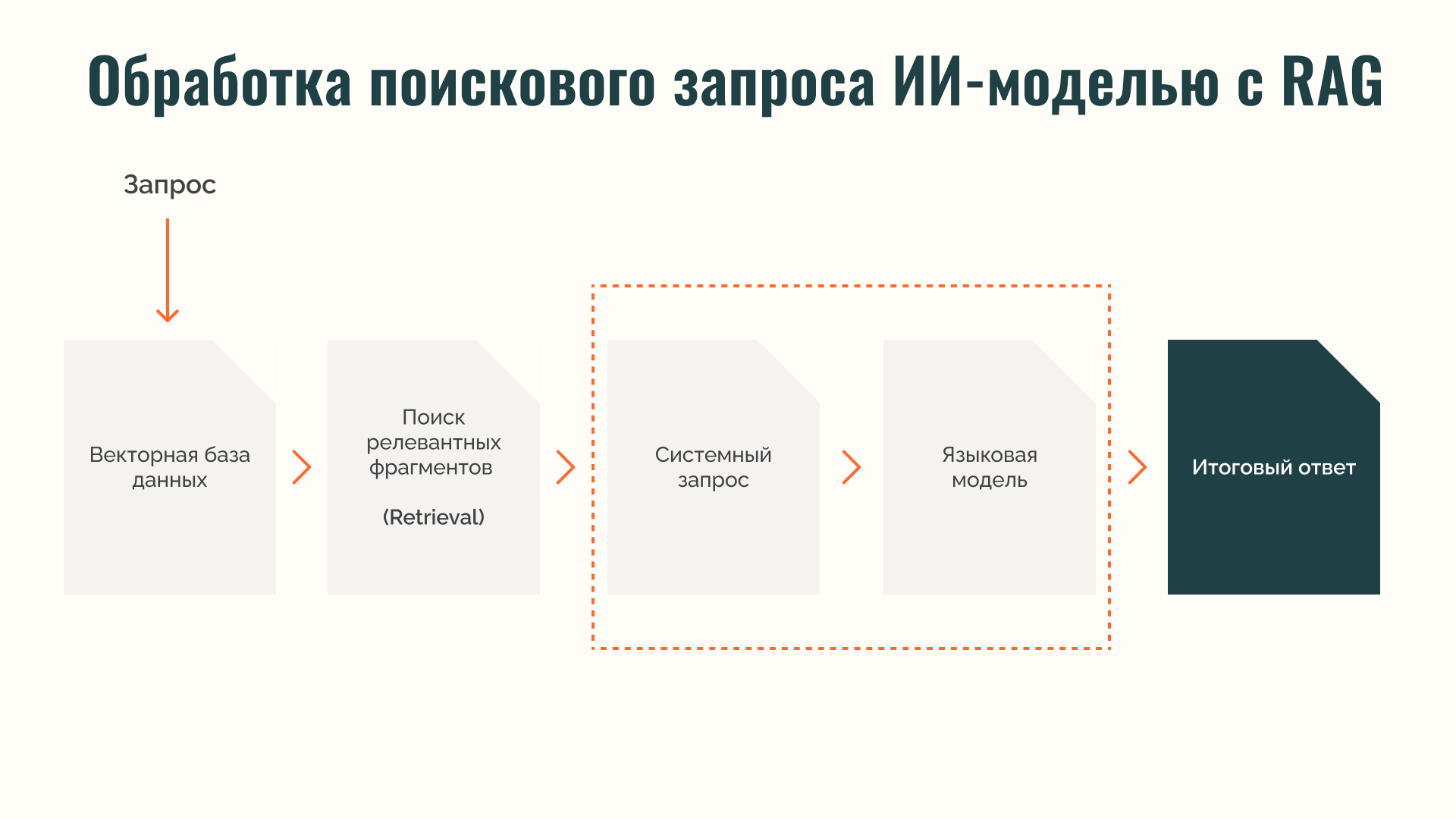
2. Поиск и генерация ответа (Retrieval + Generation) — обработка пользовательских запросов с учетом контекста.
Подробнее об индексации данных:
· для формирования базы мы разработали инструмент автоматического сбора информации с сайтов, зарегистрированных на платформе.
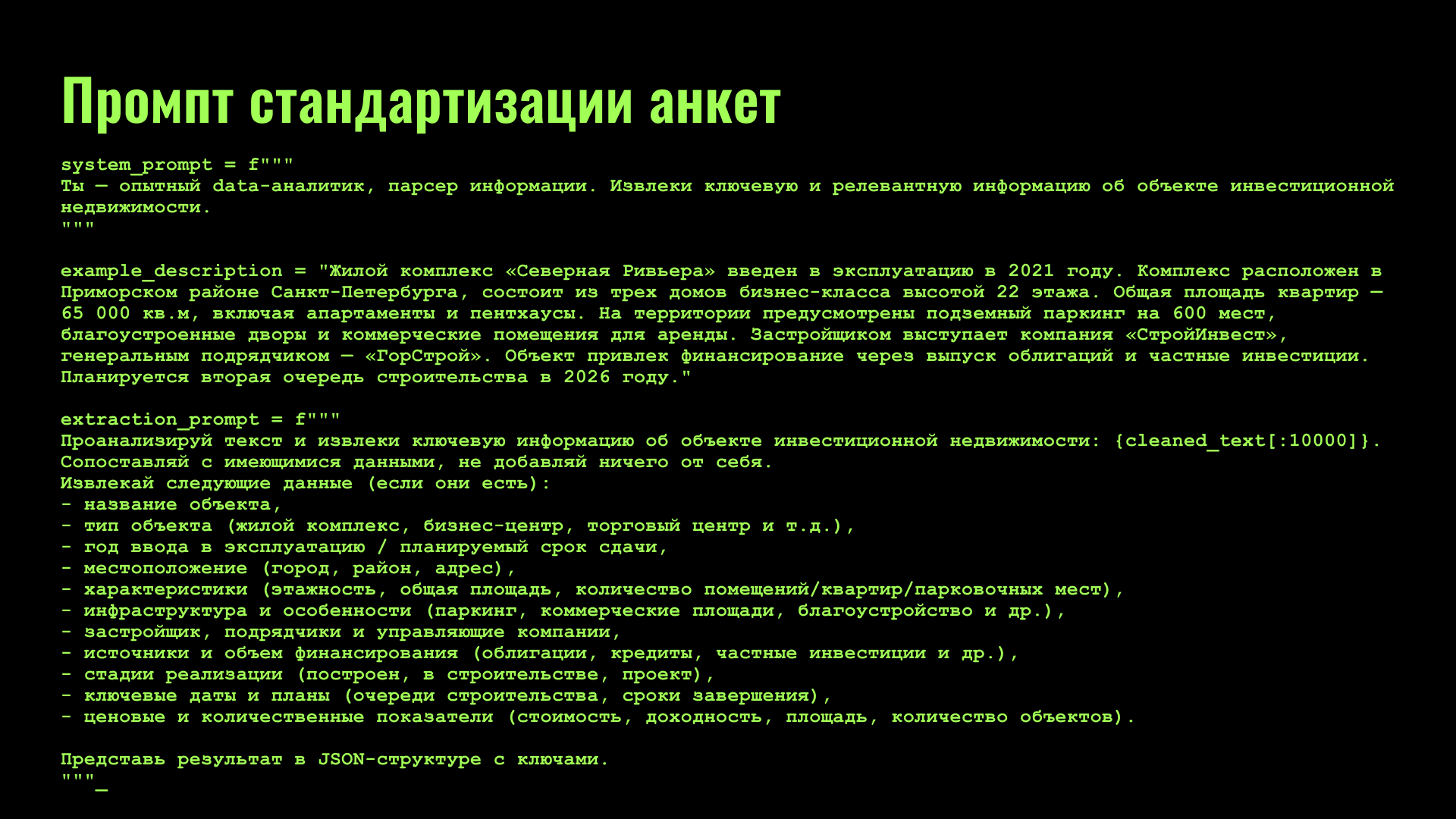
· полученные данные преобразовывались в стандартизированные анкеты участников с помощью специально составленного промпта. Очистка обеспечивает сопоставимость данных и удобство последующего анализа.
· каждый подготовленный блок данных преобразовывался в векторное представление (эмбеддинг) с помощью модели YandexGPT PRO и сохранялся в специализированное векторное хранилище ChromaDB. Это обеспечивало высокую скорость поиска по смысловому сходству.
Среднее время подготовки одной анкеты при первоначальном заполнении базы данных составило около одной минуты, при этом нагрузка на модель — порядка 3 000 токенов.
Поиск и генерация ответа
· При запросе пользователя система обращается к векторному хранилищу и выбирает анкеты компаний, проектов или консультантов, наиболее близкие по смыслу.
· Регулирование качеством совпадений происходит с помощью параметра MMR (Maximal Marginal Relevance) и порогового значения сходства. Это позволяет учитывать релевантность документа, а также уникальность данных относительно ранее выбранных.
· Извлеченные данные вместе с запросом передаются в языковую модель, которая формирует итоговый ответ на основе фактической информации из базы.
Такой подход снижает риск «галлюцинаций» модели, уменьшает количество нерелевантных ответов и обеспечивает их точность даже при работе с неполными или зашумленными данными.
Приступая к работе над проектом, команда ItFox столкнулась с типичной для таких кейсов ситуацией — исходные данные были неструктурированны, содержали много посторонней информации. Расскажем подробнее.
Первоначальная информация для интеллектуального поиска поступала из анкет, которые представители компаний вручную заполняли на платформе-агрегаторе. Форма заполнения была неунифицирована, не были установлены обязательные поля для заполнения. Из-за этого анкеты были либо не полностью заполнены, либо содержали дубли. Такое состояние данных сделало невозможным их прямое использование. Решением стало формирование с помощью ИИ новых унифицированных анкет, собирая информацию напрямую с сайтов участников-платформы.
Для сбора данных был разработан скрапер, осуществлявший автоматический обход ресурсов. Из более чем 120 тысяч организаций, проектов и профилей экспертов, зарегистрированных на платформе, актуальные сайты имели порядка 105 тысяч. После проверки их доступности и технического состояния к дальнейшей обработке было отобрано около 98 тысяч ресурсов.
Тем не менее сайты-первоисточники также содержали: рекламные блоки, служебные элементы, повторяющиеся фрагменты и другую нерелевантную информацию. Чтобы получить только нужную информацию, нами была реализована многоступенчатая система предобработки:
· Удаление лишних пробелов, табуляции и пустых строк.
· Фильтрация по стоп-словам с использованием стандартных инструментов Python. Список включал элементы меню («главная», «о нас» и др.), названия разделов («клиенты», «партнеры»), футер-тексты («copyright», «все права защищены»), технические обозначения («логин», «регистрация») и ряд кастомных исключений.
· Исключение строк, содержащих только цифры, специальные символы или подчеркивания.
· Удаление дубликатов через TfidfVectorizer библиотеки Scikit-learn. На основе TF-IDF матрицы проводился анализ попарного сходства, а его порог задавался параметром Threshold.
Такая очистка позволила нам сформировать качественный массив унифицированных анкет, который стал фундаментом для векторизации и последующего построения интеллектуального поиска. Еще раз подчеркнем, зашумленные данные — проблема распространенная, но решаемая за счет продуманного алгоритма очистки.

Технологический стек
В основе сервиса используется Python 3.11.
FastAPI применён в качестве web-фреймворка.
LangChain выступает как rag-framework для взаимодействия с LLM-агентами.
Apache Kafka — message queues — для масштабирования и параллельной обработки задач.
ChromaDB — векторное хранилище embeddings.
text-search-doc / text-search-query — инструменты для векторизации текстовых данных.
YandexGPT Pro используется для генерации и нормализации текстов.
Для проекта выбраны Yandex Foundation Models, т.к. соответствуют российской юрисдикции.
BeautifulSoup, lxml, TfidfVectorizer — инструменты для парсинга и предобработки данных.
Интеллектуальная поисковая система на базе RAG способна работать с естественным языком, учитывать контекст и формировать релевантные ответы, опираясь на точные данные из анкет участников ресурса.
Внедрение этой системы дало для платформы три стратегических эффекта:
· Экономия времени пользователей.Клиенты получают готовые точные ответы сразу. Ручная фильтрация данных теперь не нужна.
· Укрепление конкурентных позиций. По данным аналитиков платформы, доля отказов - поисковых запросов, после которых пользователи прекращали взаимодействие с сервисом, снизилась на 24%, что свидетельствует о росте доверия к результатам поиска. А конверсия из поискового запроса в целевые действия (просмотр карточки/добавление в избранное/оставление заявки) увеличилась на 18%.
· Фундамент для масштабирования.Созданная векторная база открыла возможности для дальнейшего развития: интеллектуальных рекомендаций, глубокой аналитики рынка и расширения экосистемы платформы.
Внедрение решения на базе Rag позволило Заказчику продемонстрировать стратегический подхода к клиентскому опыту и готовности платформы добавлять новые сегменты.
Интеллектуальный поиск применим в любых отраслях, где есть массивы разнородных документов, требуется быстрый доступ к регламентированной информации, много времени уходит на поиск сведений, важна точность и актуальность данных.
Такие решения становятся стандартом современных цифровых платформ, и команда ItFox готова переносить свой опыт в новые проекты.


Елена Назарова
ИИ после своего громкого появления постепенно становится обычным рабочим инструментом. Однако, он поменял многое из того, что раньше казалось незыблемым. Внедрение интеллектуального поиска позволяет задавать запросы не ограничиваясь простым названием компании или ее ИНН. Когда данные собраны из разных источников и объединены с помощью RAG, это открывает для бизнеса новые возможности. А пользовательский опыт — особенно в сфере получения достоверной информации — становится удобнее и качественнее. Работа над проектом принесла нашей команде ценный опыт, а Заказчику дала инструмент, который стал его конкурентным преимуществом.




