Тендеры и лиды
Информация

13 000 000
Финансы, страхование, инвестиции
Апрель 2026
Мы — АЙТИФОКС. Делаем сложные штуки: финтех, ИИ, высоконагруженные системы. Шесть лет на рынке, в штате больше шестидесяти человек, в портфолио — проекты, которыми реально гордимся.
Но этот кейс два года лежал под NDA. И вот наконец можно рассказать.
Заказчик — онлайн-платформа-агрегатор: инвестиционные проекты, консалтинг, драгметаллы, недвижимость. Ключевой актив — реестр, который собирает данные из множества внешних систем. К нам пришли с запросом «возьмите на поддержку и развитие». Звучало как плановая работа.
А по факту — реанимация. До нас над реестром работали две команды подряд. Обе не справились. Проект перешёл к нам в состоянии, близком к полной остановке. И через полтора месяца — ключевое отраслевое мероприятие, где продукт обязан работать и презентовать новую аналитику.
Представьте картину. Мы проектируем архитектуру под сотни запросов в секунду, запускаем сложные интеграции, копаемся в чужом коде без документации. А клиент открывает реестр и видит… белый экран на минуту. Или данные, которые непонятно откуда взялись. Или интеграцию, которая молча потеряла заявку.
Разрыв между тем, что должно быть, и тем, что есть, был не просто стыдным — он был критичным для бизнеса. В B2B с высокими регуляторными требованиями это либо работает, либо хоронит репутацию.

В каком состоянии мы получили проект

Картина вскрылась за первые две недели ресёрча. Тяжёлая.
Первая команда построила все роуты по единому «сверхжадному» шаблону на самописном фреймворке. Чтобы показать карточку компании, запрос тянул вообще всё: команду, аккаунты, историю сделок, контракты. Гигантский объём нерелевантных данных. Плюс внешний поисковый движок Elasticsearch был настроен неоптимально и добавлял к загрузке ещё 5+ секунд. Ключевые страницы грузились по 20–60 секунд. Не миллисекунд — секунд.
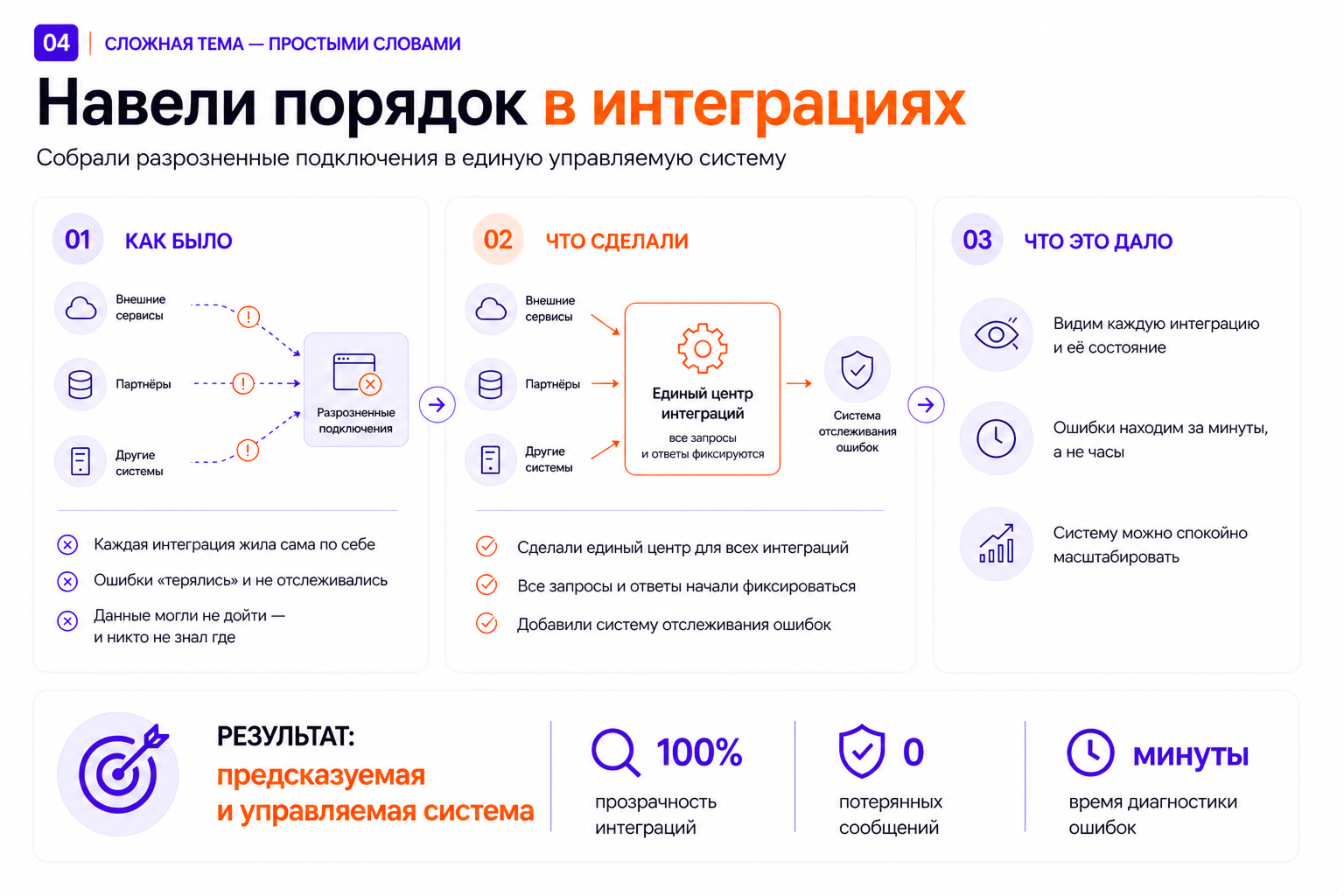
Интеграции с внешними системами работали фрагментарно. Часть данных не передавалась, заявки терялись. Фоновые задачи вроде отправки экспертных заключений просто не выполнялись. Таймаутов и обработчиков ошибок не было — любой сбой молча вешал задачу без уведомлений.
Инфраструктуры как класса не существовало. Тестового контура нет. Деплой ручной. Sentry не подключён. Логи не собираются. Линтеры и чекеры кода не используются.
Ключевой сотрудник предыдущей команды то «болел», то «ничего не знал». Нам не передали ни знаний об архитектуре, ни логики принятых решений. Документация отсутствовала полностью.
И на всё это накладывалась организационная специфика: B2B-сегмент, строгая двухнедельная отчётность по шаблонам, протоколы испытаний с тест-кейсами, согласование на уровне высшего руководства. Каждый отчёт могли завернуть до пяти раз.
Как мы дважды могли провалиться, но не провалились
Первый риск был очевиден: классический подход «сначала долгий ресёрч, потом разработка» просто не влезал в полтора месяца до отраслевого интенсива. Если бы мы пошли этим путём — пришли бы на мероприятие с сырым продуктом.
Второй риск был более коварным: начать латать старый код. Симптомы были видны — медленные запросы, падающие интеграции. Исправить «по верхам» и сдать как «поддержку»? Но мы понимали: проблема не в багах, а в архитектуре. Латание означало бы отсрочку на пару месяцев, после которой всё посыпалось бы снова.
Мы выбрали третий путь: тактическая стабилизация параллельно с ресёрчем, а затем системное переписывание фундамента.

Разбили работу на три этапа.
Этап 1. Тактическая стабилизация и проектно-образовательный интенсив. Первые две недели — полный ресёрч параллельно с разработкой. Внедрили кэширование страниц — не архитектурное решение, а тактический «костыль», чтобы «заморозить» проблему медленной загрузки. Параллельно форсировали новую аналитику для мероприятия. Команда работала на пределе, но это была разовая история. Продукт прошёл интенсив.
Этап 2. Пересборка архитектуры (около года). Править старые запросы было бессмысленно — логика связей слишком глубоко зашита в самописном фреймворке. Мы переписали все критические роуты в новую версию API (v2) с нуля, используя паттерн «сервис-репозиторий». Каждый роут теперь запрашивал только те данные, которые реально нужны фронту. Результат: загрузка сократилась с 20–60 секунд до 200–500 миллисекунд. В 50 и более раз.
Отказались от Elasticsearch для пользовательского поиска. Внедрили полнотекстовый поиск на базе самого PostgreSQL — убрали 5-секундную задержку и упростили архитектуру. Elasticsearch оставили только в админке, где его использование оправдано.
Для нормализации хаоса с внешними сервисами внедрили собственную шину данных на Kafka. Любое взаимодействие с внешними системами — отправка данных, запрос статусов, получение описаний — теперь проходит через контролируемый контур. Шина записывает все сообщения в БД, фиксирует статусы и ошибки. Впервые интеграции стали прозрачными.
Полностью переписали обмен с ключевыми внешними системами: SOAP и REST API, CRM, внешние шины проектов. Настроили полные циклы обмена, валидацию по справочникам, обработку коллизий — например, когда сервер возвращает 500 ошибку, но данные при этом записывает.
Подняли тестовый контур и связали его с тестовыми средами внешних систем. Внедрили Sentry и логирование. Настроили автоматический деплой и alembic для миграций БД.
Отдельная история — отчётность. После многократных переделок (до пяти раз на один документ) мы изучили все нормативные требования заказчика и создали собственные шаблоны, которые утвердили раз и навсегда. Проблема «придирок к запятым» исчезла.
Этап 3. От стабильности к интеллектуальному поиску. Когда архитектура перестала быть узким горлышком, перешли к развитию. На основной платформе заказчика требовался поиск, понимающий сложные профессиональные запросы: от стартапов по технологиям до анализа недвижимости по доходности
.
Проблема: данные на платформе были «шумными» — анкеты заполнялись вручную, содержали дубли, пропуски, разную структуру. Просто подключить нейросеть означало бы получить галлюцинации.
Мы написали скрапер, который обошёл сайты компаний и собрал актуальные данные по 98 000 профилей. Выстроили многоуровневую очистку: TF-IDF для удаления дублей, фильтрация технического мусора, унификация структуры. Очищенные данные перевели в векторное представление через YandexGPT PRO и сохранили в ChromaDB. Внедрили поиск на базе RAG (Retrieval-Augmented Generation) — модель ищет ответ не в своей «памяти», а в актуальных данных платформы.
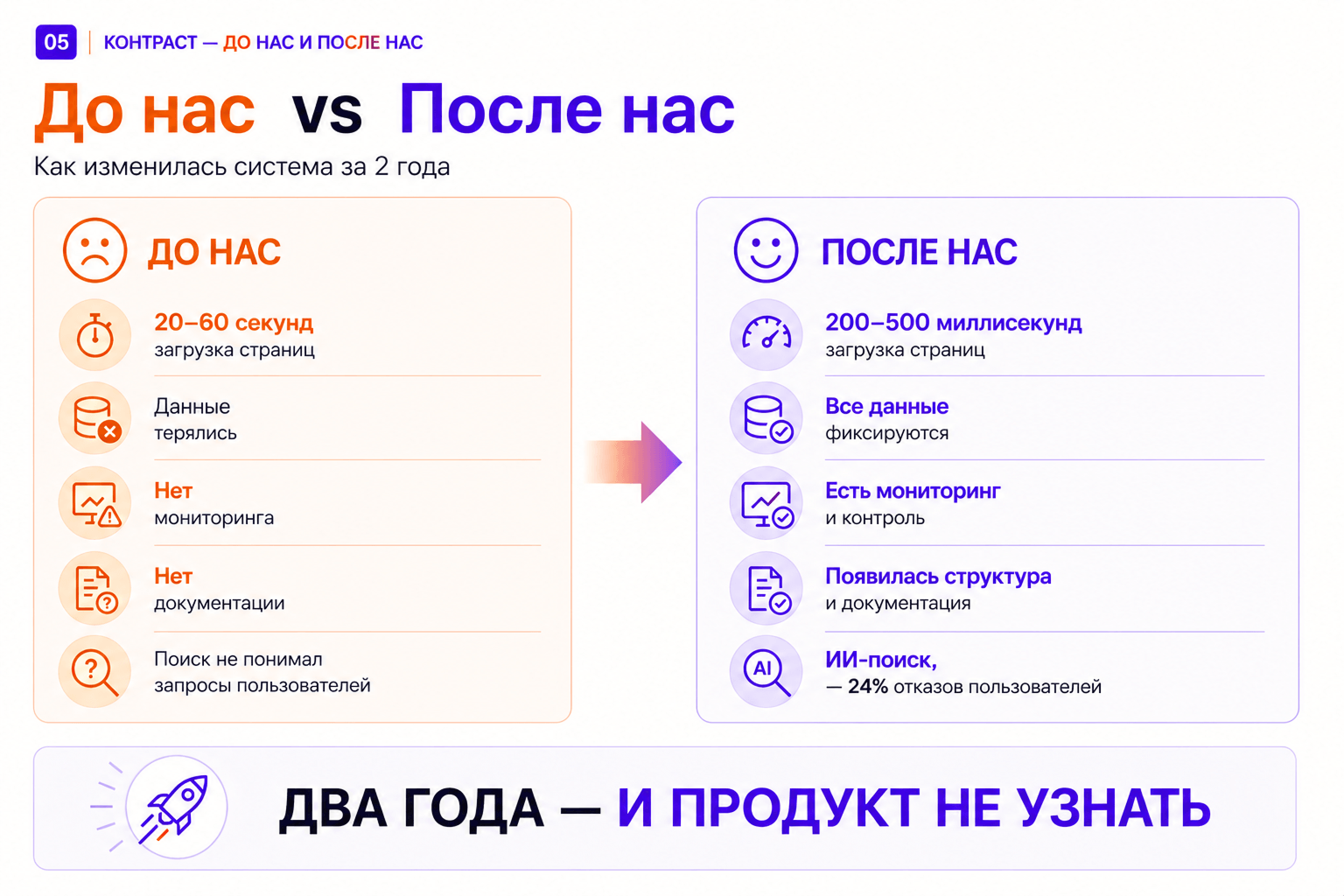
Два года назад нам передали проект, который не грузился, не интегрировался и не имел документации. Сегодня:
✅ Загрузка страниц — 200–500 миллисекунд вместо 20–60 секунд. В 50 и более раз быстрее.
✅ Интеграции работают и логируются через шину данных. Ошибки не теряются, статусы отслеживаются.
✅ Отчётность сдаётся по утверждённым шаблонам без переделок.
✅ ИИ-поиск понимает инвестиционные запросы: доля отказов снизилась на 24%, конверсия выросла на 18%.
✅ Заказчик, дважды обжигавшийся на других командах, работает с нами до сих пор.
И самое кайфовое — мы больше ни от кого не зависим. Ни от чужого самописного фреймворка, ни от потерянной документации, ни от решений, которые закладывались без понимания роста. Мы пересобрали фундамент — и теперь платформа масштабируется.
Проект перестал быть слабым звеном. Теперь это аргумент в переговорах заказчика, а не повод оправдываться.

Елена Назарова
Главное — не относитесь к legacy как к приговору. Две команды до вас провалились? Архитектура заложена с ошибками? Документации нет, а дедлайн вчера? Это не повод опускать руки. Это повод включить мозги и действовать системно: сначала стабилизировать, потом пересобрать фундамент, потом развивать.
Иногда надо просто взять и сделать. Выделить команду, защитить её от дёрганий, поставить жёсткий срок — и довести до ума. Даже если проект выглядит безнадёжным.
Проект тормозит и теряет данные? Перепишем архитектуру, наладим интеграции и внедрим ИИ-поиск — как для платформы, где мы ускорили загрузку в 50 раз.

