Тендеры и лиды
Информация

Услуги
Апрель 2026
Протестировать гипотезу о том, что переписывание контента под требования нейросетей повышает количество цитирования материалов в них.
Причина
Корпоративный блог Kokoc.com — крупная контент-площадка с информационным трафиком и обширной библиотекой публикаций, которые годами удерживают позиции в топ-5 и топ-10 традиционного поиска.
При этом в генеративных выдачах эти публикации практически не фигурируют. Частота включения даже самых рейтинговых материалов в ответы ИИ колеблется в пределах 1–2 упоминаний, что близко к статистической погрешности. Выявленный разрыв обозначил серьезный вызов: прежние методы продвижения больше не гарантируют заметность в ИИ-ландшафте, где контент оценивается по иным критериям.
Именно это противоречие вдохновило руководителя SEO-департамента Kokoc Performance Сергея Шабурова на разработку стратегии адаптации под нейросети.
В качестве тестовых образцов отобрали три статьи блога с прочными позициями в органике, но минимальной представленностью в ИИ-выдачах. Руководитель группы экспериментальных клиентов Павел Талакин и SEO-специалист Дарья Сербина провели адаптацию этих текстов под нейросети.
Современные пользователи все чаще получают исчерпывающую информацию прямо на странице поисковой выдачи, минуя клики по сторонним ресурсам. Интеграция в ИИ-ответы превращается в обязательное условие продвижения. В изменившихся условиях конкуренция смещается: борьба идет не просто за место в топе выдачи, а за право стать авторитетным первоисточником для обучения искусственного интеллекта.
Возникает любопытное противоречие. Если оценивать эффективность по канонам классического SEO, сайт может демонстрировать идеальные результаты: страницы занимают лидирующие строчки и получают стабильный трафик. Однако эти же страницы оказываются для ИИ-алгоритмов невидимыми, они их не цитируют.
Специалисты отдела экспертизы Kokoc Performance (входит в Kokoc Group) решили проверить, какие факторы влияют на частоту цитирования контента в ответах нейросетей.
Сложности проекта:
1. Отсутствие устоявшихся методик. Проблема интеграции контента в генеративные модели и ИИ-выдачи стоит на сегодняшнем digital-рынке особенно остро. Однако из-за новизны этого направления применять классические SEO-инструменты здесь бесполезно — требуются принципиально иные подходы. Четких алгоритмов действий и наработанной базы пока не существует: отрасль только нащупывает почву. Единственный возможный путь — формулировать гипотезы и проверять их на практике, чем мы и занялись.
2. Эксклюзивность эксперимента. Возможно, аналогичные исследования и проводились кем-то из участников рынка, однако публичных данных об этом нет. Для нашей команды этот опыт стал дебютом.
3. Исходный уровень контента. Улучшать то, что и так хорошо, всегда сложнее всего. Материалы блога Kokoc.com, задействованные в эксперименте, изначально были глубокими, экспертными и качественными — над ними трудились профессиональные авторы. Главная задача состояла в том, чтобы деликатно адаптировать их под новые требования нейросетей, не нарушив оригинальную структуру и не потеряв уникальный стиль изложения.
Подготовительный этап стартовал в августе–сентябре 2025 года. Мы выбрали 3 публикации блога, которые занимают устойчивые позиции в органическом поиске, но при этом практически не видны в ИИ-ответах: лонгрид о хакатонах, технический материал об ошибке 502 Bad Gateway и практическое руководство по построению диаграммы Исикавы.
На первом этапе мы задокументировали текущий уровень присутствия этих страниц в ответах нейросетей, чтобы сформировать точку опоры и впоследствии объективно оценить динамику после внесенных правок.

Отправной точкой стал аудит того, как нейросети «воспринимают» имеющиеся материалы. Проверка вскрыла типичную проблему: в некоторых статьях прямой ответ на поисковый запрос был «закопан» глубоко в тексте — после лирических отступлений, метафор или развернутого введения. Если для живого читателя такой стиль повествования вполне комфортен, для генеративных алгоритмов подобная архитектура текста резко снижает шансы на его использование в ИИ-выдаче.
На этом этапе мы:
- зафиксировали отсутствие принципа «ответ в приоритете»;
- убедились, что вступительные фрагменты зачастую непригодны для прямого цитирования в качестве готового решения.
После анализа тексты подверглись реорганизации: мы разбили их на самодостаточные смысловые модули (чанки), каждый из которых дает исчерпывающий ответ на конкретный запрос пользователя. Это было сделано для того, чтобы нейросети могли легко извлечь отдельный фрагмент и показать его пользователю в нейроответах.
В материале, посвященном ошибке 502, прямо в первом абзаце приводится четкое определение сбоя с указанием его первопричины.

Сразу под определением размещено оглавление, где четко выделены разделы: суть ошибки 502, внешние проявления, инструменты диагностики, инструкции по устранению для вебмастеров и обычных пользователей, а также блок частых вопросов.

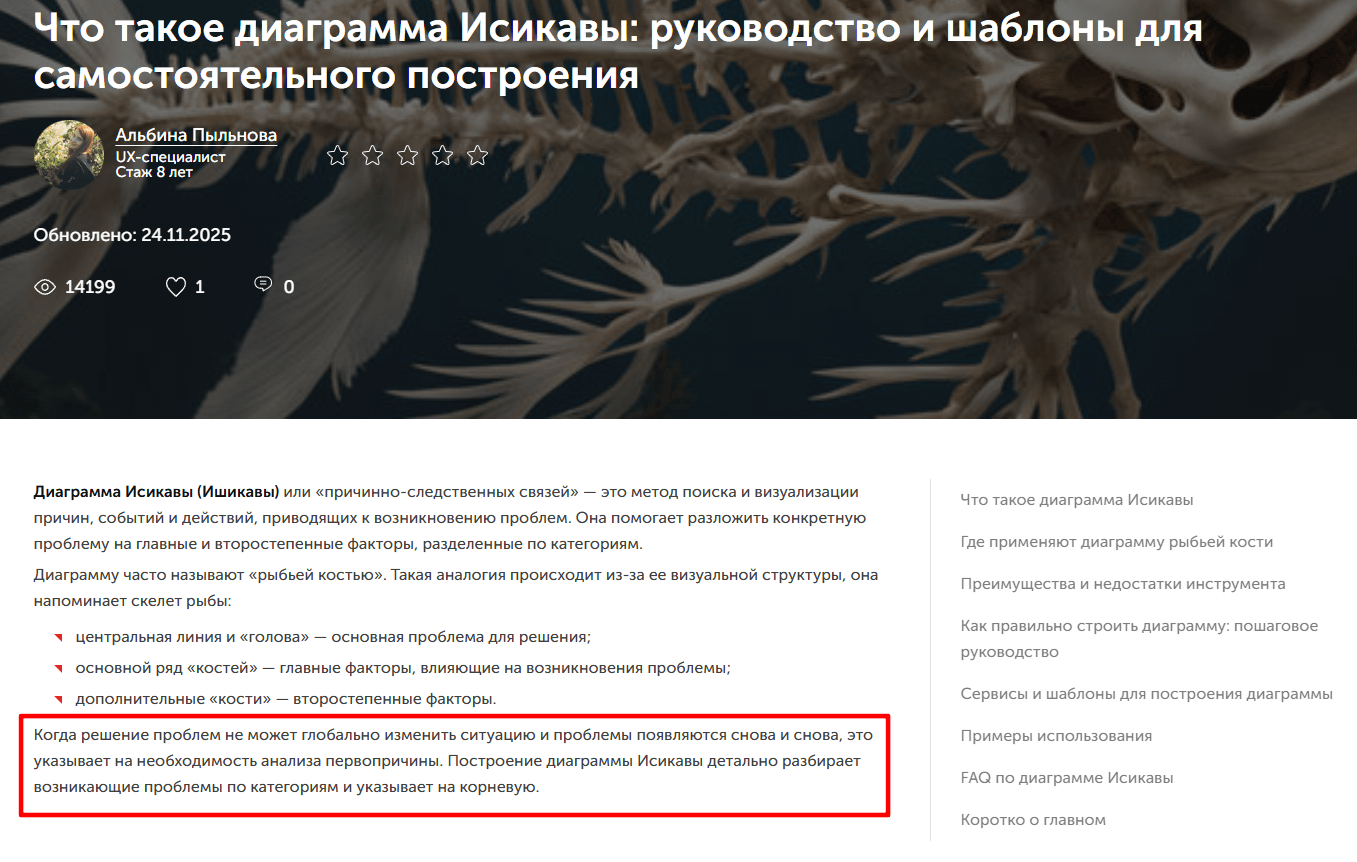
В статье о диаграмме Исикавы в оригинальной версии определению предшествовал авторский вступительный текст.

Мы провели ротацию блоков, переместив определение в начало статьи.
Второй этап доработок затронул систему рубрикации и последовательность смысловых блоков. Анализ показал, что в практических разделах нередко нарушалась причинно-следственная связь: например, инструкции по устранению неполадки опережали этап диагностики, а разбор серверных логов размещался после описания конфигураций или используемых ресурсов.
Для генеративных моделей подобная алогичность неприемлема, поскольку LLM оценивают не только фактическую базу, но и стройность, последовательность рассуждений.
Нами был реализован следующий комплекс мер:
- скорректированы заголовки — исключены размытые, метафоричные формулировки;
- оставлены лишь те наименования, которые максимально точно передают суть раздела и соответствуют пользовательскому интенту;
- упорядочена последовательность действий по схеме «установление причины диагностика устранение»;
- структура адаптирована под алгоритмическое восприятие искусственным интеллектом.
Так, в руководстве по диаграмме Исикавы изначально перечислялись способы построения, и лишь затем давалась пошаговая инструкция.
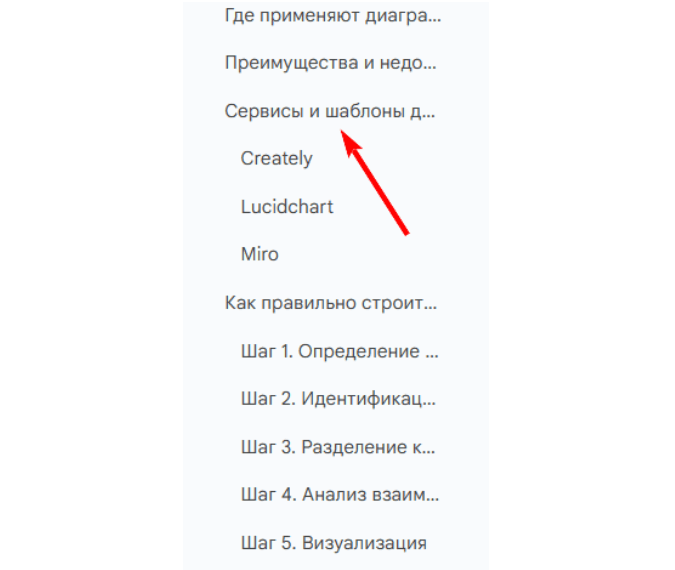
Мы произвели ротацию этих фрагментов, приведя повествование в логически верный порядок. Ниже представлен финальный вариант структуры:

В материале об ошибке 502 заголовки выстроены по четкому алгоритму: открывает раздел блок диагностических инструментов («Средства оперативной диагностики ошибки 502»), затем следуют инструкции для вебмастера — анализ логов и мониторинг серверных ресурсов. И лишь после этого представлены рекомендации для конечных пользователей с детализированными шагами: верификация доступности ресурса, уведомление администратора, ожидание стабилизации нагрузки, деактивация расширений и пр.
Представленный скриншот подтверждает: советы по исправлению ошибки не опережают диагностические процедуры, соблюдена корректная технологическая последовательность.

В исходных вариантах статей некоторые разделы совмещали несколько чанков — например, причины и симптомы, теорию и практику, рекомендации для разных категорий пользователей. Это затрудняло извлечение нейросетями точечной информации.
В рамках доработки мы:
- разделили избыточно насыщенные абзацы на самостоятельные логические элементы;
- упростили синтаксис и сократили громоздкие предложения;
- внедрили маркированные списки и табличные формы там, где это усиливало структурированность;
- сохранили при этом связность текста и его удобочитаемость.
Теперь каждый отдельный блок дает четкий ответ на один конкретный вопрос и легче идентифицируется нейросетями как самодостаточный информационный фрагмент.
Так, в публикации о хакатонах задачи мероприятия представлены в виде маркированного перечня. Такой формат идеален для цитирования, поскольку напрямую отвечает на потенциальные запросы:

После приведения структуры в порядок мы сфокусировались на содержательной части. Анализ выявил, что даже добротные материалы теряют привлекательность для ИИ из-за элементов устаревания: конкретных временных привязок, упоминаний устаревших форматов без пояснений об их актуальности.
Что было сделано:
- актуализированы термины;
- формулировки приведены к единому стандарту с опорой на современные источники;
- интегрирована свежая статистика и описания действующих практик.
Даты обновления видны в карточках материалов:



Несмотря на изначальную полезность контента, уровень компетентности автора не всегда явно считывался алгоритмами явно.
Мы провели усиление этого направления:
- указали сведения о практическом опыте команды Kokoc;
- добавили авторитетные комментарии с указанием должностей и ролей специалистов;
- детализировали технические нюансы, подчеркивающие реальную практическую вовлеченность.
Так, в материале об ошибке 502 появился экспертный блок с комментарием руководителя SEO-департамента Сергея Шабурова, его фотографией и указанием должности.

Также мы дополнили материалы реальными кейсами из практики команды Kokoc:

Подобный подход существенно усилил экспертную составляющую публикаций, повысил ценность контента и дополнительно акцентировал сигналы доверия и профессиональной компетенции, критически важные для ранжирования в генеративной выдаче.
Завершающий этап работ был посвящен технической оптимизации. Проверка показала, что значительная часть информации была структурирована с ориентацией на человека, а не LLM: многоуровневые списки вместо табличных форм, команды, встроенные в текст, выводы, оформленные сплошными абзацами.
Вот что было выполнено:
- реализована перестройка HTML-кода с заменой универсальных div и span на семантические элементы (h2, h3, p, ul);
- выверена иерархия заголовочных уровней;
- команды и технические параметры вынесены в обособленные код-блоки;
- заключения трансформированы в форматы чек-листов;
- внедрена микроразметка Schema.org (BreadcrumbList, Article, headline, image, dateModified, author);
- проведены множественные циклы валидации кода до полного устранения ошибок.
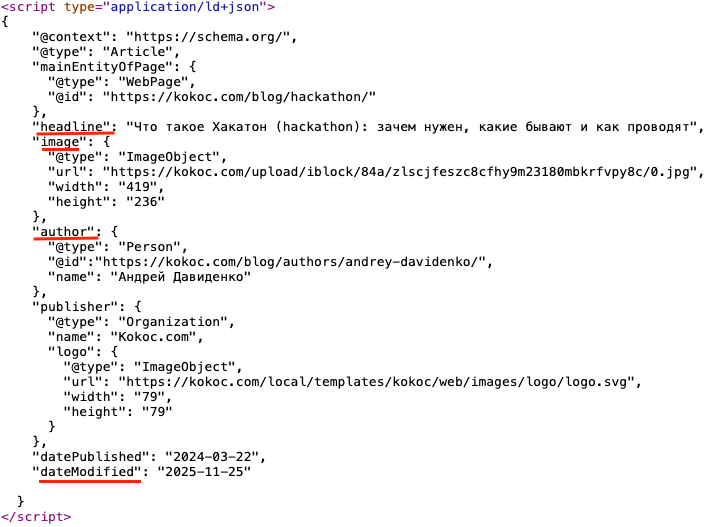
Визуально для посетителя эти изменения незаметны, однако именно они обеспечивают корректную интерпретацию материалов поисковыми системами и генеративными алгоритмами.
Проведенный эксперимент наглядно продемонстрировал: высокие позиции в классической выдаче больше не являются гарантией присутствия в ИИ-поиске. Решающее значение приобретает степень адаптации контента под логику генеративных систем — способность оперативно предоставлять ответ, выстраивать прозрачный алгоритм действий и наглядно транслировать экспертность.
Ключевой вывод: оптимизация под генеративную выдачу не отменяет классическое SEO, а формирует следующий уровень работы с контентом — через продуманную архитектуру, своевременность данных, дробление на смысловые блоки и усиление сигналов E-E-A-T.
Работа над кейсом стартовала 7 октября 2025 года. В ходе нескольких итераций нам удалось трансформировать стандартные SEO-материалы в структурированный, экспертный и адаптированный для нейросетей контент. Теперь наши материалы появляются в ИИ‑ответах (Алиса от Яндекса и Google AI Overview):
По состоянию на 7 октября статья о хакатонах фиксировала лишь 2 упоминания в ответах нейросетей. После реструктуризации и обновления смыслового наполнения показатель шестикратно вырос — до 12 цитирований к декабрю. Это свидетельствует об устойчивом положительном эффекте и значительном прогрессе в видимости генеративной выдачи.
Материал про диаграмму Исикавы первоначально находился в полной «тени» для ИИ — было зафиксировано лишь разовое цитирование. После изменения архитектуры текста и актуализации данных частота упоминаний выросла до стабильных 3–4.
Аналогичная ситуация наблюдалась и с публикацией об ошибке 502: на старте эксперимента присутствовало единственное упоминание. После упрощения навигационных элементов и обновления описательной части число цитирований достигло 5.
Особого внимания заслуживает факт достижения устойчивой видимости в нейроответах. Речь идет не о случайных попаданиях, а о системном результате. Материалы стали стабильно востребованы нейросетями, окончательно преодолев «слепую зону» генеративного поиска.
Kokoc Performance с удовольствием обсудит вашу задачу