Тендеры и лиды
Информация
Ленремонт
Услуги
Россия, Санкт-Петербург
Октябрь 2025
Ленремонт — компания с 58-летней историей, которую знают большинство жителей Санкт-Петербурга и Ленинградской области.
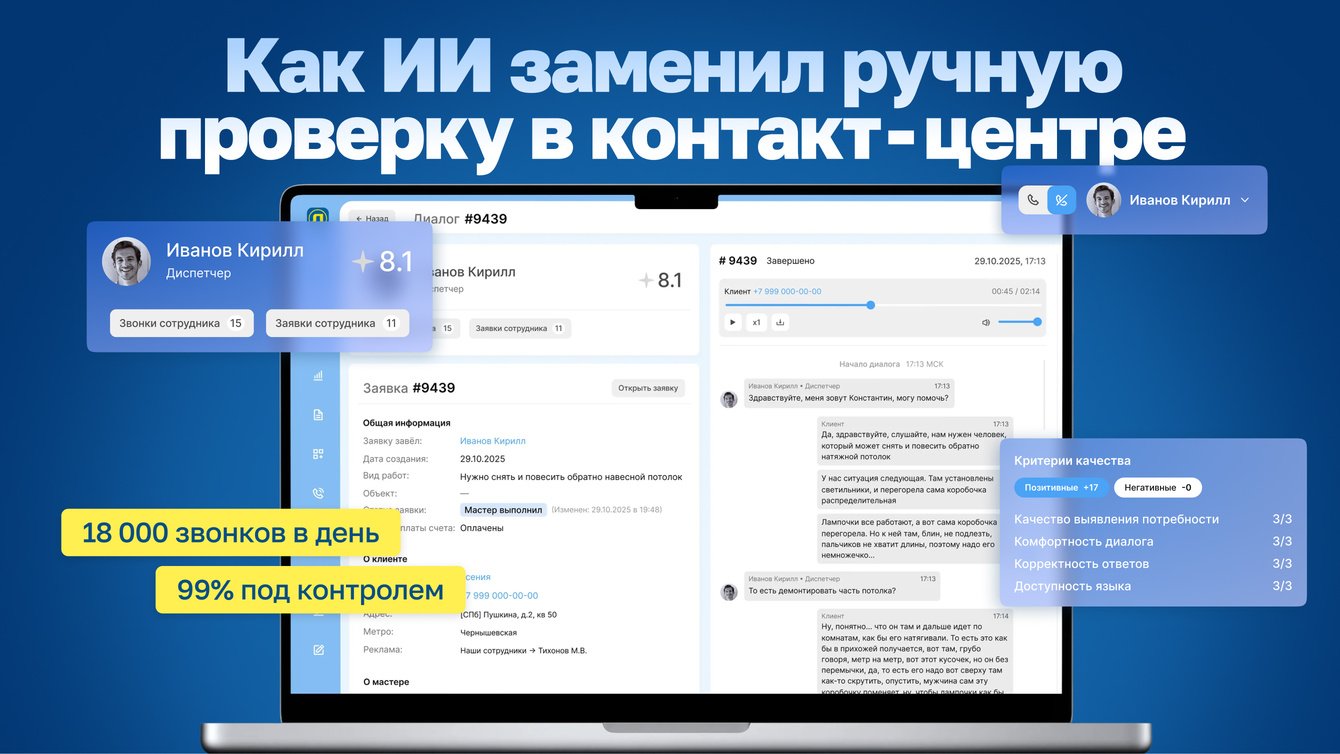
Ежедневно в контакт-центр поступает более 18 000 звонков с заявками на ремонт и другими вопросами. Для компании это основной канал привлечения клиентов и точка, где формируется первое впечатление о сервисе.
Каждый из 18 000 звонков в идеале необходимо отслеживать, контролировать качество и успешность, но в отделе контроля качества всего 10 человек, которые физически не справлялись с этой задачей, успевая обработать всего 5% звонков.
Компания понимала, что может упускать огромное количество важных данных и терять клиентов на этом самом первом этапе — была нужна точная аналитика по каждому звонку с пониманием того, где есть нарушения стандартов. Всё, чтобы продолжать привлекать новых клиентов и удерживать уровень сервиса.
Масштабировать контроль качества за счёт дополнительного найма и стандартных систем автоматизации было невозможно: они не давали ни нужного охвата, ни объективной оценки, ни контроля работы с заявкой.
Поэтому мы решили разработать систему речевой аналитики, в ядре которой — искусственный интеллект, который способен обрабатывать большие объёмы данных, оценивать диспетчеров без субъективности и сразу выявлять проблемы в коммуникации с клиентом.
Решение собирает записи звонков из телефонии, преобразует речь в текст, анализирует диалоги и формирует отчётность в интерактивных дашбордах для руководителей. А ещё — фиксирует нарушения и сопоставляет их с правилами работы по заявке.
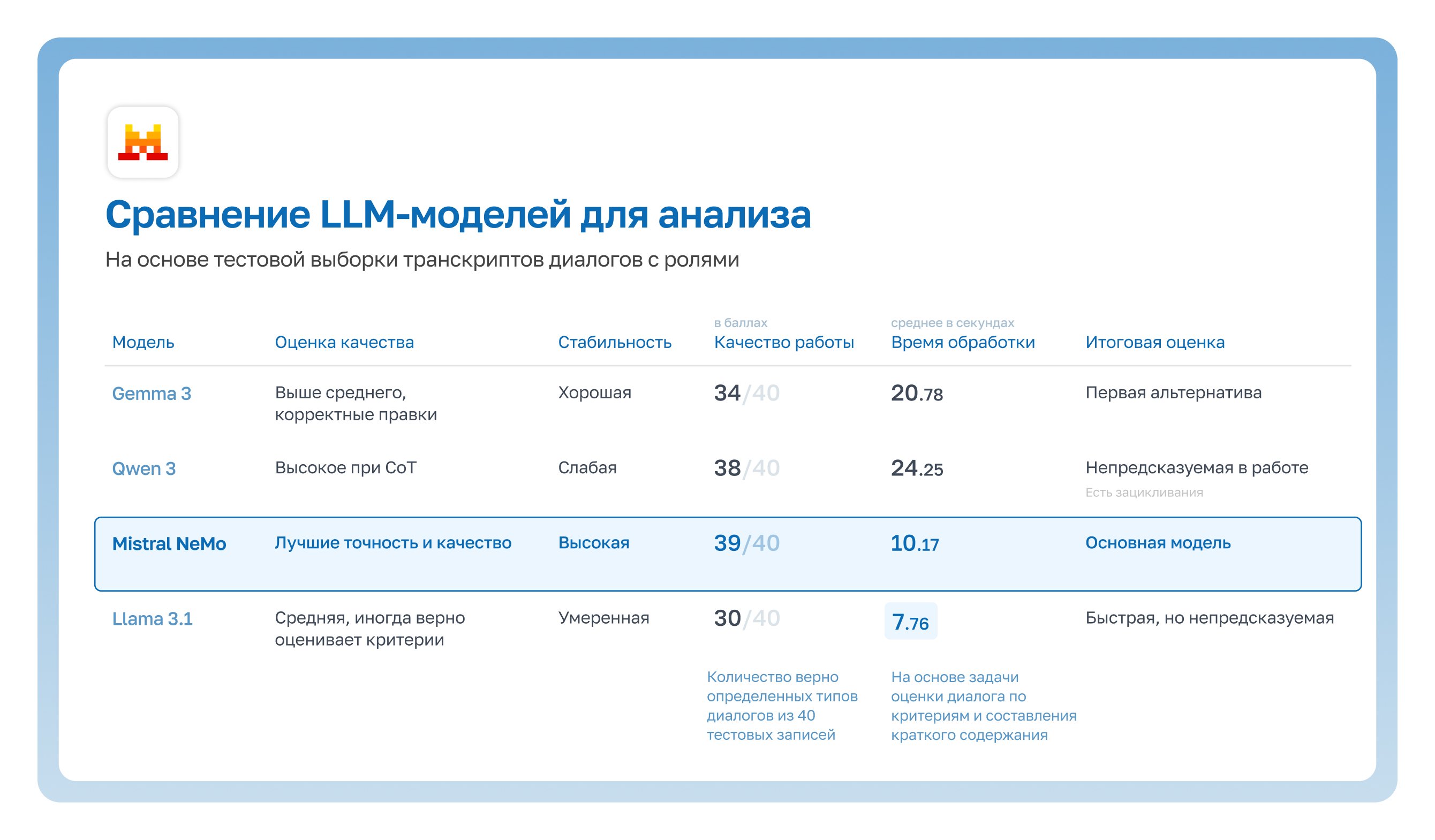
В основе системы — связка из трёх моделей, каждая из которых отвечает за свой этап анализа звонка.

К такому набору мы пришли не сразу: на старте было неочевидно, какие модели использовать. Например, одни модели хорошо справлялись с распознаванием речи, но «плыли» на длинных звонках. Другие корректно интерпретировали смысл диалога, но были нестабильны по структуре вывода.
Поэтому мы бросили попытки решить всё одной моделью и провели собственное исследование, чтобы собрать идеальный пайплайн для стабильного результата на реальных диалогах колл-центра.
Когда стало очевидно, что звонок нельзя обрабатывать одним этапом, мы придумали многоступенчатую модель процесса.
Итак, звонит клиент — отвечает диспетчер.
Телефония Asterisk записывает разговор и передаёт аудиофайл через API в систему. Приёмный сервис на Django получает запись звонка, сохраняет её и ставит задачу в очередь на обработку. Запрос на новые записи — каждые 5 минут.
Дальше в дело вступают нейросети:
1. Сначала звонок транскрибируется, то есть речь переводится в текст.
2. После этого система определяет, кто и в какой момент говорит.
Сначала мы хотели объединить транскрибацию и диаризацию в один этап — с помощью дополнительного «ремонтного» шага, где модель должна была сама исправлять ошибки и определять роли спикеров. В реальности результаты были нестабильными, поэтому от него отказались в пользу отдельных этапов обработки.
3. Включается модуль LLM. Он анализирует диалог: определяет тип разговора, проверяет выполнение обязательных этапов общения, фиксирует ошибки и формирует итоговую оценку по звонку, оператору и заявке.
Если в ходе анализа выявляются негативные метки, система автоматически формирует нарушения и передаёт их в управленческий слой. Дополнительно результаты анализа сопоставляются с историей заявки — временем реакции, сменой статусов и действиями мастеров.
Вся эта цепочка работает асинхронно: результаты шагов возвращаются через вебхуки, а система последовательно двигает звонок по пайплайну.

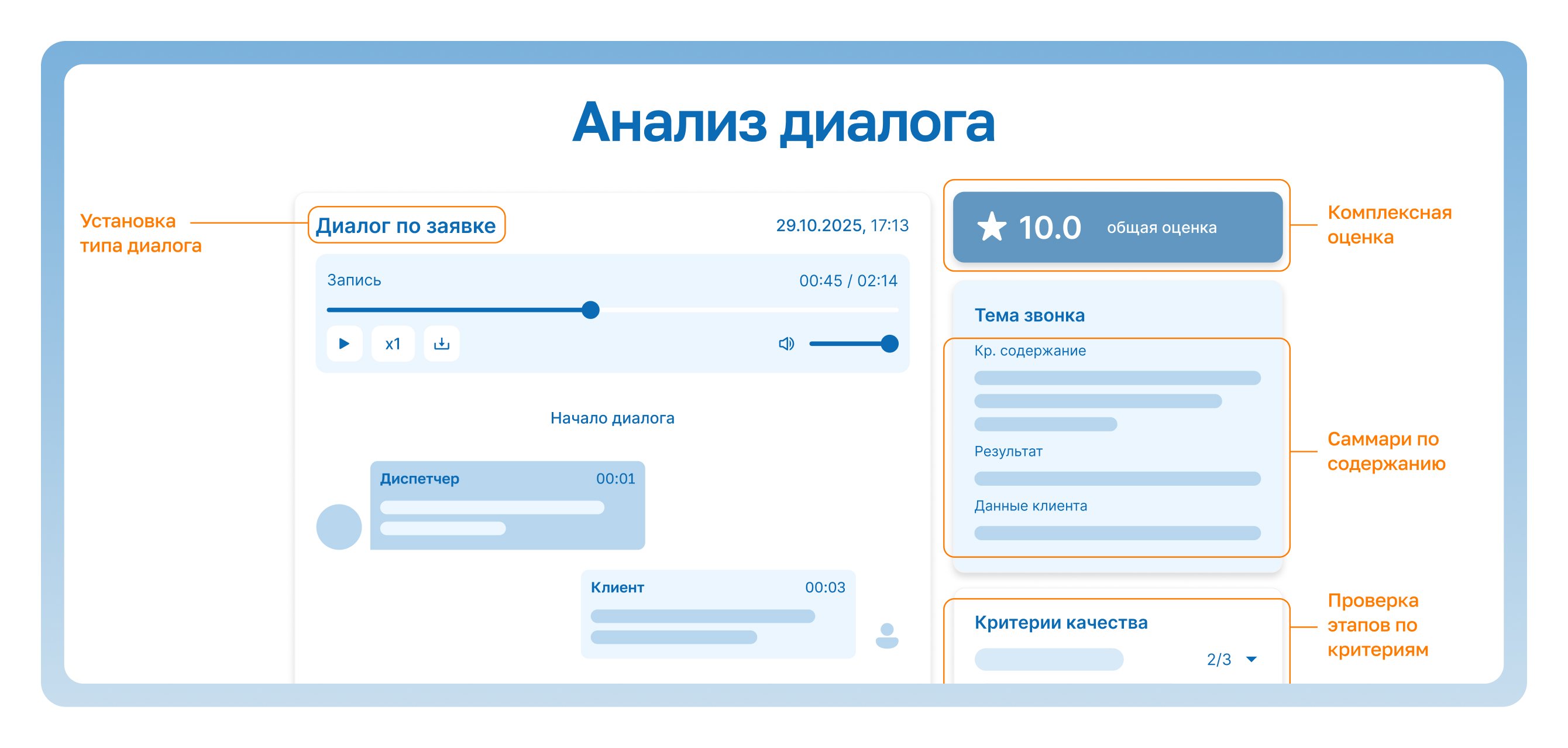
А чтобы конечный пользователь увидел результаты, система собирает данные всех этапов и отображает их в интерфейсе аналитики.
Самым сложным было то, что никто не понимал, что считать хорошим звонком.
Из интервью мы узнали, что каждый специалист трактует критерии оценки звонка по-своему. В рабочих документах этих критериев вообще насчитывались сотни, хотя в реальной работе использовались несколько.
Мы решили переизобрести подход и для этого:
1. Выделили типы звонков. Проанализировали большую выборку звонков и поняли, что звонки отличаются своими типами: это и обзвоны по оценке сервиса, и приём и оформление заявок, и исходящие продажи, и консультации мастера. Всего вышло 4.
2. Разработали критерии оценки для каждого типа.

Собрали группы, а для каждой группы и типу разговора — свой набор критериев. Определили, что нужно фиксировать:
• как говорит диспетчер (коммуникативные навыки),
• насколько последовательно выстроен диалог (структура разговора),
• соблюдаются ли скрипты и регламенты,
• как обрабатываются сложные (конфликтные) ситуации.
Часть этих критериев в дальнейшем стала основой для автоматической фиксации нарушений.
3. Придумали методику оценки. Каждому критерию задали простую шкалу: либо «да/нет», либо от 0 до 3. Чтобы модель не фантазировала, ввели жёсткое правило: если в тексте разговора нет подтверждения — значит, 0 баллов.

Финальный результат учитывает и то, что сотрудник сделал правильно, и то, каких ошибок избежал, и даёт честную оценку по шкале от 0 до 10 — руководителю сразу понятно, где проблемы в коммуникации с клиентом, а где зафиксированы конкретные отклонения от стандартов работы.
Система встроена в информационную систему компании, поэтому при проектировании интерфейсов мы опирались на текущий фирменный стиль и привычные сценарии работы сотрудников.
Всего в системе 3 раздела: «ОКК», «Заявки с нарушениями», «Звонки с нарушениями».
За три месяца мы разработали и внедрили систему речевой аналитики, которая закрыла ключевые задачи контакт-центра: масштабирование процесса без найма, данные для аналитики и работа с клиентами.
Теперь аналитика звонка доступна меньше, чем за 1 минуту. Руководитель может открыть конкретный диалог, увидеть, что диспетчер пропустил этап уточнения проблемы, и сразу дать точечную обратную связь.
Раньше такой звонок или отклонение по заявке просто потерялся бы среди тысяч других.

