Тендеры и лиды
Информация

АО «Российская венчурная компания»
Информационные технологии и интернет
Россия
Ноябрь 2020
ПРО//ЧТЕНИЕ. Технологии понимания
Международный конкурс для разработчиков в области понимания естественного языка. Глобальная цель конкурса — преодолеть технологический барьер, научив искусственный интеллект понимать текст на естественных языках (NLU).
Задача
Разработать и запустить высокотехнологичную платформу для квалификационных, технических и финальных испытаний программных комплексов участников.
Общие требования к платформе — высокая отказоустойчивость и принцип open source ключевых сервисов (для обеспечения прозрачности испытаний).
Если сам конкурс ПРО//ЧТЕНИЕ — вызов для профессионалов в BigData и Machine Learning, то реализация его технической части — вызов для Вебпрактик.
Конкурс с подобным заданием проводится впервые в мире. Поэтому рабочей платформы, которую можно скопировать и адаптировать под задачи «ПРО//ЧТЕНИЕ», не существовало.
В техзадании заказчика был список задач, но без подробностей, как именно надо их решить. Таким образом, провести бизнес-анализ, разработать архитектуру платформы, отладить все процессы нам предстояло вместе с командой заказчика.
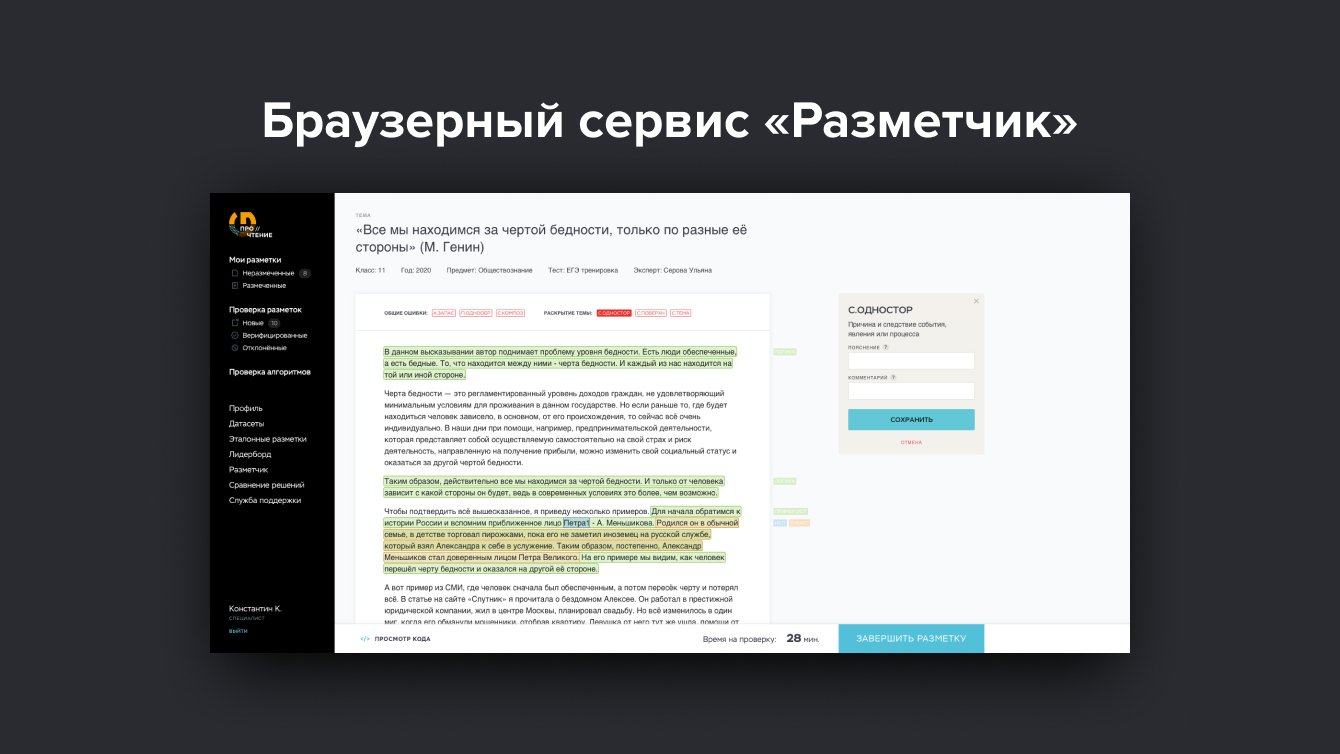
Техзадание мы получили в мае, а 1 октября конкурсанты должны были получить доступ к работающей платформе. Все дедлайны были привязаны к публичному графику конкурса и не было никакой возможности их сдвигать. Уже в июле мы запустили Разметчик для Специалистов. Он позволил начать подготовку датасетов конкурса на русском и английском языках. В сентябре запустили тестирование платформы с первыми Участниками.
Чтобы запустить платформу вовремя, нам предстояло^
1. Провести бизнес-анализ
2. Прототипировать интерфейсы и собрать обратную связь по ним от целевых групп (Преподаватель и Участники конкурса)
3. Разработать архитектуру платформы
4. Запустить в кратчайшие сроки MVP платформы
5. Отладить процессы в ходе обучения алгоритмов участников.
Платформа должна сравнить то, как тексты проанализировал программный комплекс, с анализом специалистов-учителей. Поэтому для старта испытаний на платформе нужны: тексты, учителя, инструменты для анализа текстов.

Как это происходит у людей, а не роботов? Учитель выделяет красным ошибки, «на полях» поясняет, в чем ошибка заключается. Но проверяющие, прежде всего, — люди. А значит, могут формулировать одни и те же мысли разными словами. Человек-читатель поймет смысл в любом случае, а вот искусственный интеллект — нет.
Учителей, тексты, технический регламент, который описывал математику, и классификатор ошибок нам предоставил заказчик.
Он помогает специалистам выделять смысловые блоки в тексте и оставлять единообразные комментарии с описанием ошибки, сверяясь с Классификатором.
Разметчик был запущен в июле. Разметки специалистов мы назвали Экспертными. Самих проверяющих объединили в группу пользователей Редакторы. Запустить сервисы для Участников было необходимо не позднее 29 сентября.
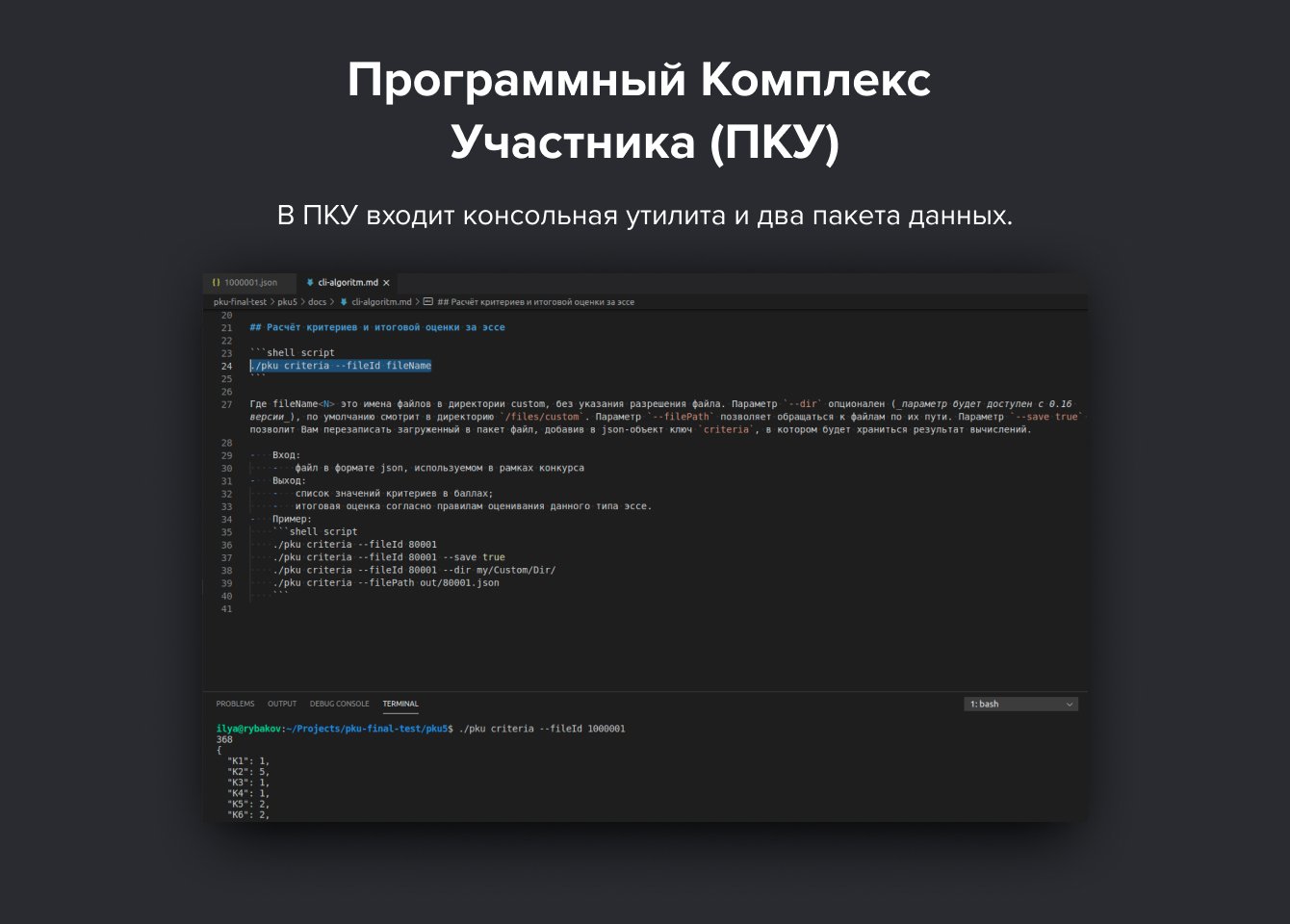
Сначала мы загрузили в систему разработанные совместно с партнерами конкурса тестовые и обучающие датасеты. Чтобы программные комплексы конкурсантов смогли в реальном времени передавать размеченные файлы на платформу для испытаний, был разработан модуль Программный Комплекс Участника (ПКУ).
В ПКУ входит консольная утилита и два пакета данных.
PSR — c метриками сравнения, Criteria — c критериями точности разметки (метрики и критерии даны в техническом регламенте от организаторов). Архивы для скачивания доступны в личном кабинете Участника и на GitHub.
Используя ПКУ, Участник может в любой момент через API установить сессию между своим локальным устройством и платформой. Последняя по запросу отдаёт файлы с неразмеченным эссе. Затем на локальном устройстве алгоритм участника размечает их и передает обратно. Пакет парсера собирает разметку и преобразует в машиночитаемую JSON-структуру.
Чтобы Участники были независимы от языка платформы (TypeScript), мы "завернули" приложение и пакеты в Docker-контейнер и предоставили к ним готовый консольный интерфейс. Его можно использовать из любого языка программирования.
Данные сессии и результаты проверки размеченных файлов отображаются в ЛК Участника.
Пользователь может скачать отчёт и логи, посмотреть в визуальном интерфейсе, чем отличается его вариант разметки от Экспертной.
Когда на платформу приходят размеченные файлы, включается автоматическая система проверки решений, которая анализирует присланные разметки, сравнивая с Экспертными. Это алгоритмическая квалификация.
Кроме того, система проверяет состояние подключенного ПКУ каждые 4 часа и оценивает его готовность к работе. Этот процесс — техническая квалификация, имитирующая финальные состязания.
Чтобы снизить нагрузку на Систему проверки решений, мы разработали вспомогательный инструмент — Валидатор. Он автоматически проверяет присланные файлы на наличие логических ошибок в разметке и высылает Участнику багрепорт.
Для проведения финальных испытаний мы разработали отдельный сервис — Программу Сравнения Решений (ПСР).
Он представляет собой worker, который считывает задачи из сервера очередей и сохраняет результаты в базу датасетов. Она хранится на отказоустойчивом облаке Yandex Object Storage. Логи сессий отправляются в ELK стек.
Сохраненные файлы с алгоритмической разметкой проверяют 20 лучших специалистов из числа тех, кто делал Экспертную разметку. За результатами проверки Участники могли следить на Лидерборде в личном кабинете.
Лидерборд динамически обновляется через сервис финала и квалификаций с websocket-интерфейсом для платформы и http-интерфейсом для скачивания и загрузки файлов датасетов с выданным токеном. В этом сервисе хранится информация по финалу и квалификациям, он отвечает за выдачу файлов датасетов с необходимыми таймаутами и сохранение данных (для статистики).
В день состязаний команды, успешно прошедшие квалификацию, одновременно установили сессии с платформой, используя ПКУ. В режиме реального времени их алгоритмы получали файлы от платформы, размечали в них тексты и возвращали обратно. Испытания длились более 8 часов, а точнее, 500 минут, из расчета по минуте на файл. Для финала были использованы датасеты с новыми текстами, которые не использовались для обучения на этапе квалификаций.
Итого, в ходе разработки платформы мы создали:
1. Сервис «Разметчик»,
2. Сервис «Валидатор»,
3. Систему проверки решений,
4. Модуль «Персональный Комплекс Участника»,
5. Программу Сравнения Решений.
А также пакеты данных, вспомогательные микросервисы, мануалы и техническую документацию. Как и хотел заказчик, наши решения имеют открытый код, ознакомиться с которым и дать фидбэк можно на GitHub.


Системы личных кабинетов на платформе получилось две, с разной архитектурой и функционалом. С визуальным интерфейсом, но без программного для Редакторов и с обоими для Участников.

Команда Up Great
Команда Up Great
Платформа для конкурса ПРО//ЧТЕНИЕ — сложная и многоуровневая система. На начальном этапе требовалась тщательная проработка архитектуры, а в течение самих испытаний — оперативная и качественная реакция на запросы в режиме non-stop. Всё это мы получили во время работы с командой «Вебпрактик». Такое глубокое погружение в проект редко встретишь со стороны подрядчика. Нам повезло работать с профессионалами в своем деле.

















