Тендеры и лиды
Информация

Агросервис «Стратегия»
Промышленность и оборудование
Россия, Екатеринбург
Февраль 2026
По этому проекту мы ранее опубликовали кейс «Интеграция со СБИС по CommerceML с массовыми преобразованиями на лету». В нем мы частично уже описали процесс, точнее, попытку получения части информации через обращение к СБИС (который теперь Saby) по API. Но тогда мы не получили нужного эффекта и повернули в сторону классического обмена по протоколу CommerceML. Все работало около года, пока номенклатура не достигла 28000 SKU. Тут мы столкнулись с рядом недостатков:
— ограничение на выгрузку товаров в 10000 позиций, о чем, конечно же, нигде не сказано;
— постоянные ошибки СБИС, ведь процесс обмена нами никак не контролируется, в результате результат непредсказуем: почти каждый раз что-то не то;
— полный обмен занимает около 16 часов, что стало просто мукой: пока обмен закончится, остатки уже не актуальны.
Единственным верным выходом казалось — вернуться к формату получения данных, обращаясь к СБИС напрямую по API. Но из прошлого мы помнили, что у СБИС каждый запрос специфичен и возвращает информацию частично: в первом случае при выгрузке в формате YML мы получим товары, но с 1 картинкой, в другом — можем получить остальные картинки, остатки получим вообще третьим запросом и так далее. Очевидное решение: сделать свой миксер, чтобы смешать все разрозненные результаты, полученные разными запросами, и объединить их в нормальный понятный и, самое главное, полный файл формата XML (YML).
В начале, как и в прошлый раз, мы приступили к получению списка товаров в формате YML. Нам показалось это хорошим решением, ибо можно указать конкретный раздел в СБИС, который необходимо выгружать, и в ответ получить уже структурированный файл со всеми (ну, так описано в документации СБИС) полями. Сделали приложение, запросили, получили данные в таком виде:
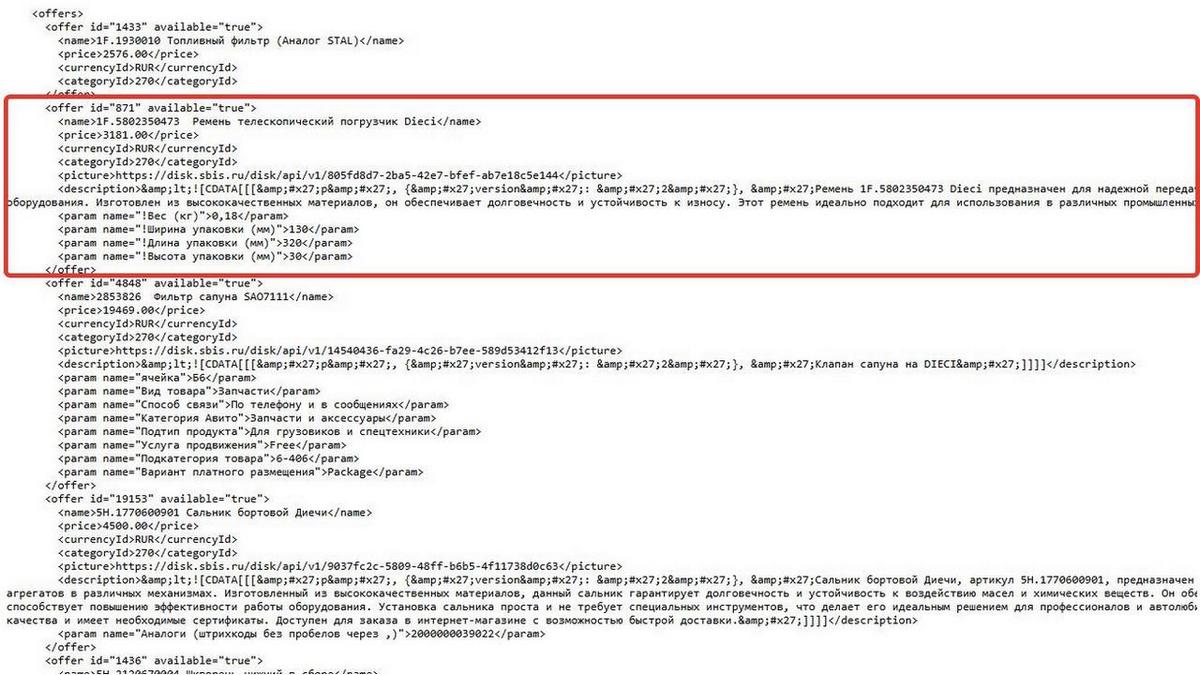
На первый взгляд прекрасный файл, но при детальном анализе видим, что в нем нет следующих данных:
— дополнительные изображения;— изображение раздела;— штрихкод;— артикул;— остаток на складе;— единицы измерения.
Но структура уже есть и это хорошо. Начало положено, с этим можно работать!
Не знаем, почему так устроено, но получить товары по API можно только из определенного прайс-листа, зная его id, id организации. Поэтому мы добавили нашу категорию с товарами «Интернет-магазин» целиком массово в прайс-лист. Далее по инструкции получили id прайс-листа, отфильтровали для тестов около 500 товаров из пары категорий, чтобы быстро произвести отладку, и получили все данные в массиве по каждому товару.
Здесь уже были штрихкоды, артикул и другие недостающие данные, но вместе с ними и куча хлама. СБИС выгружает готовые интеграции с «Озон» с его кучей полей и так далее. Поэтому мы описали условия, по которым отбираем, что необходимо, а что нет, и скорректировали полученный ответ.
Естественно, и тут не прошло без неожиданностей. Согласно приведенной в документации инструкции:
Чтобы получить изображение товара: метод: GET. запрос: https://api."sbis.ru/retail/{img?param="...}
, где {img?param=...} — значение параметра «images» из вернувшихся данных товара.
СБИС отдает ссылки на картинки в виде:
С пмощью AI-друзей мы выяснили, что часть после params – это кодировка base64 и если декодировать ее, то получим {"ObjectType": "nomenclature_for_ref", "ObjectId": 25956, "PhotoURL": "https://disk."sbis.ru/disk/api/v1/5aa3bff3-4cf1-48cf-8bcd-9b8dbc0ab61b", "PhotoId": null, "Size": null, "AdditionalParams": null} — отлично! Поэтому декодируем каждую картинку и забираем только ссылку, которая необходима, в данном случае: «https://disk.sbis.ru/disk/api/v1/5aa3bff3-4cf1-48cf-8bcd-9b8dbc0ab61b» – фух.
Немного правок понадобилось еще, чтобы скорректировать вывод картинок и параметров.
Параметры приходят в виде отдельных тэгов, каждый с новой строки. Картинки аналогично:

Нам такой формат не подошел, удобнее обрабатывать такие данные, объединенные в массив, например, и . Поэтому написали преобразование, объединяющее параметры и картинки в массивы.
Соединив все вышеописанное, мы написали скрипт для создания файла в формате yml. Но и тут сложности: файл получаем по внешней ссылке, его нужно скачать и потом уже преобразовывать. Решением стало скачивать файл, сохранять локально на сервер, далее производить с ним необходимые преобразования и объединенный кастомный YMLкласть в ту же папку на локальный сервер. Целая череда запросов к API СБИС, и в итоге получаем наш файл import.yml.
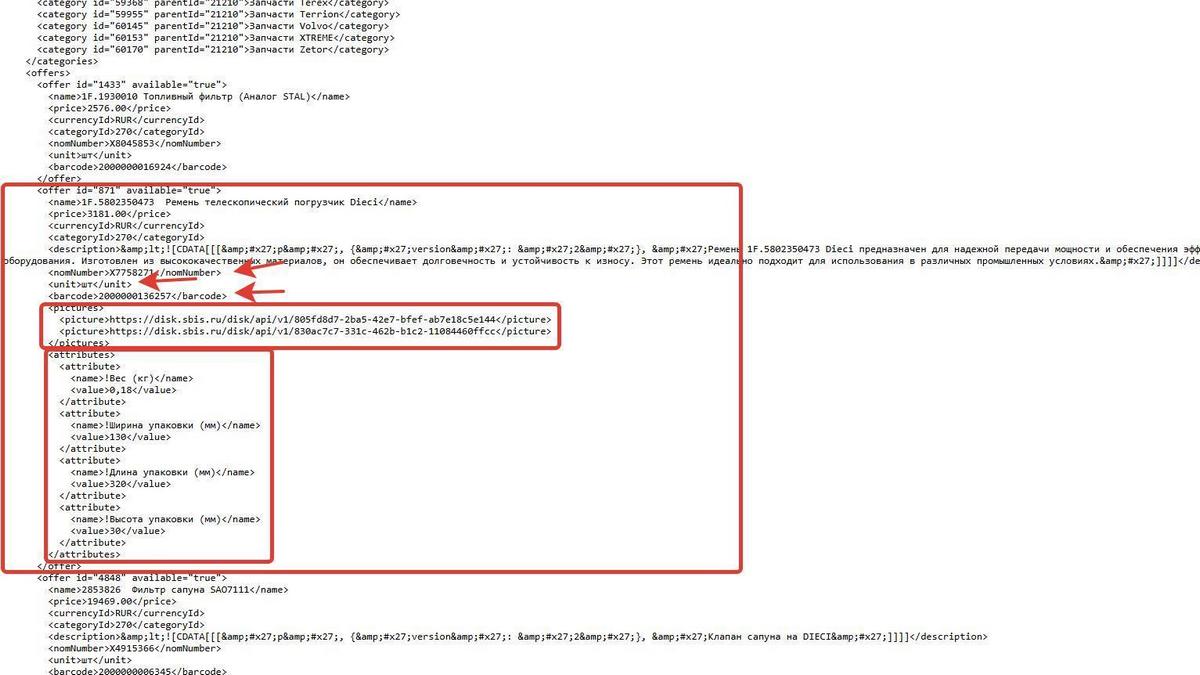
Добавили 2000 товаров в прайс-лист и стали тестировать генерацию нашего сборного файла импорта. Запускаем — результат 0 товаров.

Не то, чтобы мы совсем ничего не получаем — мы получаем первый уровень категорий и их id. Никто не может нам это объяснить, но работает оно вот так, и с этим ничего не поделать: если товаров до 1000 штук — приходит их полный список, если больше 1000 — только перечень родительских id. При этом параметры ни page, ни page_size не отрабатывают должным образом: в любом случае мы получаем список групп, а не товары. Логика подсказывает, что в таком случае помогло бы копнуть внутрь категории, указав ее id но в документации по API ни слова не говорится об этом. Мы 2 дня переставляли разные комбинации, на выходе — 0.
Потом последовали еще 2 дня переговоров и мучений техподдержки, перевод на старшего специалиста, еще 7 дней ожидания, и мы наконец-то понимаем, что, оказывается, были на верном пути. Только нужно в качестве параметра в запросе для выбора конкретной папки указывать folder. Конечно же, об этом знает только сам главный разработчик).
Отлично, теперь процесс стал более или менее понятен, и его можно представить так:
1. Собираем категории. Если у них parent=true, значит, углубляемся и собираем еще категории пока не получим false.
2. Собираем в массив индексы всех категорий и дальше запросами в цикле поштучно получаем товары каждой конечной папки, проверяя в конце каждого ответа "outcome": {"hasMore": true}} — значит есть пагинация — ставим page=2 и так далее, пока не будет false.
3. ???
4. PROFIT.
Все необходимые преобразования данных мы настроили еще при выгрузке по формату CommerceML, поэтому теперь просто скопировали их в новый импорт. В результате 28 000 товаров импортируются по API на сайт с нашими преобразованиями, описанными детально тут. Причем занимает это примерно 1 час вместо 16 часов при прямой интеграции.
Остатки важно обновлять часто, и тут уже «всего час» превращается в «целый час», что нас не устраивает. Поэтому выгрузку количества остатков отделяем в дополнительный файл, который должен импортироваться на порядки быстрее, чем весь каталог.
Конечно же, для выгрузки остатков есть своя документация, и в ней сказано, что получить остатки можно из текущего прайс-листа, зная id прайс-листа, id компании и id склада. Супер, все есть, отправляем запрос. Получаем первые 10 000 позиций и всё. Да: опять уперлись в лимит. Мало того, еще и столкнулись с проблемой выгрузки только опубликованных товаров. В результате в файле импорта каталога у нас, например, 10 000 товаров, а в файле остатков — 8 000. Почему? Никто так и не понял, да и разбираться не охота уже было: все равно упираемся в лимит.
Решением стало получать остатки по каждому товару через тот же обход прайс-листа, описанный выше. Включили параметр balance=true и уже понимая, как обходить все категории в цикле, получили отдельный файл stocks.yml. Связь между файлами идет через id товара. Сопоставляем их и получаем связь:

Выгрузка файла с остатками занимает всего 2 секунды, что дает нам возможность обновлять их на сайте хоть через каждые 5 минут, поставив соответствующую задачу в cron.
На выходе мы получили автоматизированную систему импорта данных из СБИС (Saby) в нужном нам формате, в программируемом нами временном интервале, с заданными нами условиями, которая создает 2 файла:— import.yml, формируемый путем преобразования стандартного файла import_sbis.yml с применением нашего миксера, добавляющего информацию, собранную при разных запросах;— stocks.yml — остатки.Обработка запроса со стороны СБИС длится не более 5 минут, общее время импорта примерно 1 час, итоговый файл весит около 15 Мб, а обработка остатков занимает 2 секунды.

Дмитрий Павлович Травин
Проектный менеджер
Чтобы выгружать 28 000 SKU из СБИС так, как это нужно заказчику, мы наладили импорт напрямую по API, написали свой миксер (чтобы объединять ответы по разным API-запросам в 1 файл XML), настроили преобразования значений на лету и поставили все это на cron. И теперь на сайте Агросервиса «Стратегия» есть автоматически заполняемый каталог с постоянно актуальными остатками. Например, вот: https://new.strat96.ru/catalog/z_ch_manitou_mlt_735/
