




Тендеры и лиды
Информация
Современные решения, построенные на микросервисной архитектуре, напоминают сложный организм: сотни взаимосвязанных компонентов, распределенные базы данных, облачные сервисы. Без продуманного наблюдения даже мелкая ошибка в одном узле может спровоцировать цепную реакцию — например, падение конверсии из-за «зависшего» платежного шлюза или потерю данных из-за перегруженной очереди сообщений.
Мы внедряем DevOps-практики так, чтобы ваша инфраструктура не просто «работала», а давала вам конкурентное преимущество. И делаем это без лишнего шума: наши решения интегрируются в ваши процессы, а не ломают их.
Современные системы — это уже не монолиты, а сложные экосистемы из микросервисов, облачных сервисов и распределенных баз данных. Классический мониторинг, который фокусируется только на инфраструктурных метриках (CPU, RAM, дисковое пространство), не успевает за этими изменениями. Вот основные проблемы:
Решение — переход к observability (наблюдаемости). Это подход, где метрики, логи и трейсы анализируются вместе, чтобы система «рассказывала» о своем состоянии сама.
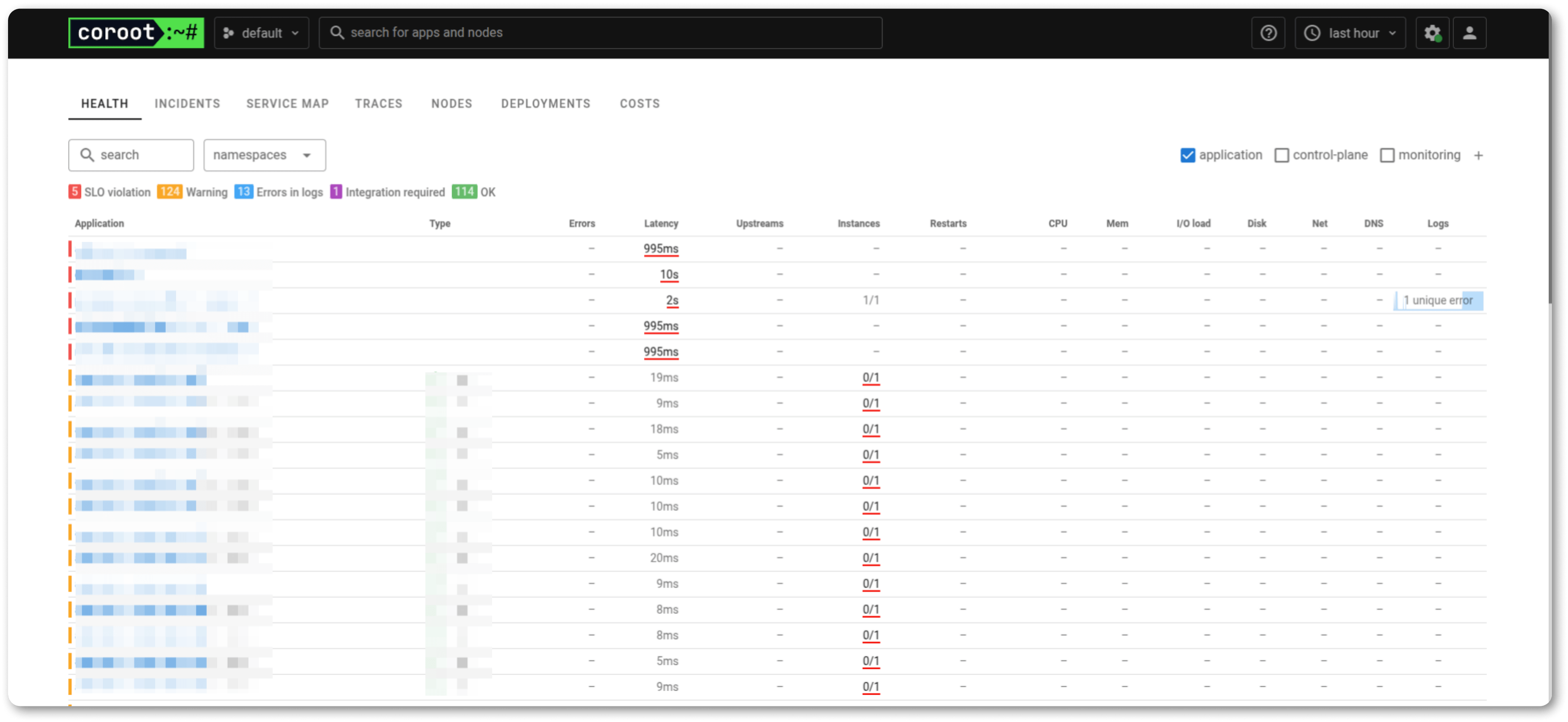
Чтобы показать, как это работает на практике, добавим мониторинг ключевого параметра — количества запросов к API.
Вот несколько решений для этого:
На первый взгляд кажется, что мониторинг API — сложная задача. Но отслеживание корректных показателей — это важная часть работы для всех, кто занимается разработкой программных интерфейсов.
Мы используем гибридный подход:
Эффективный мониторинг — это всегда баланс между инфраструктурой, бизнес-логикой и пользовательским опытом. Разберем ключевые категории метрик, которые нельзя игнорировать.
Базовые показатели: CPU, память, дисковое пространство, сетевой траффик.
Особенности для микросервисов:
Для Kubernetes используйте метрику kube_pod_status_ready в Prometheus — это помогает быстро находить «битые» поды без ручного проверки логов.
Финансовые показатели:
Производительность процессов:
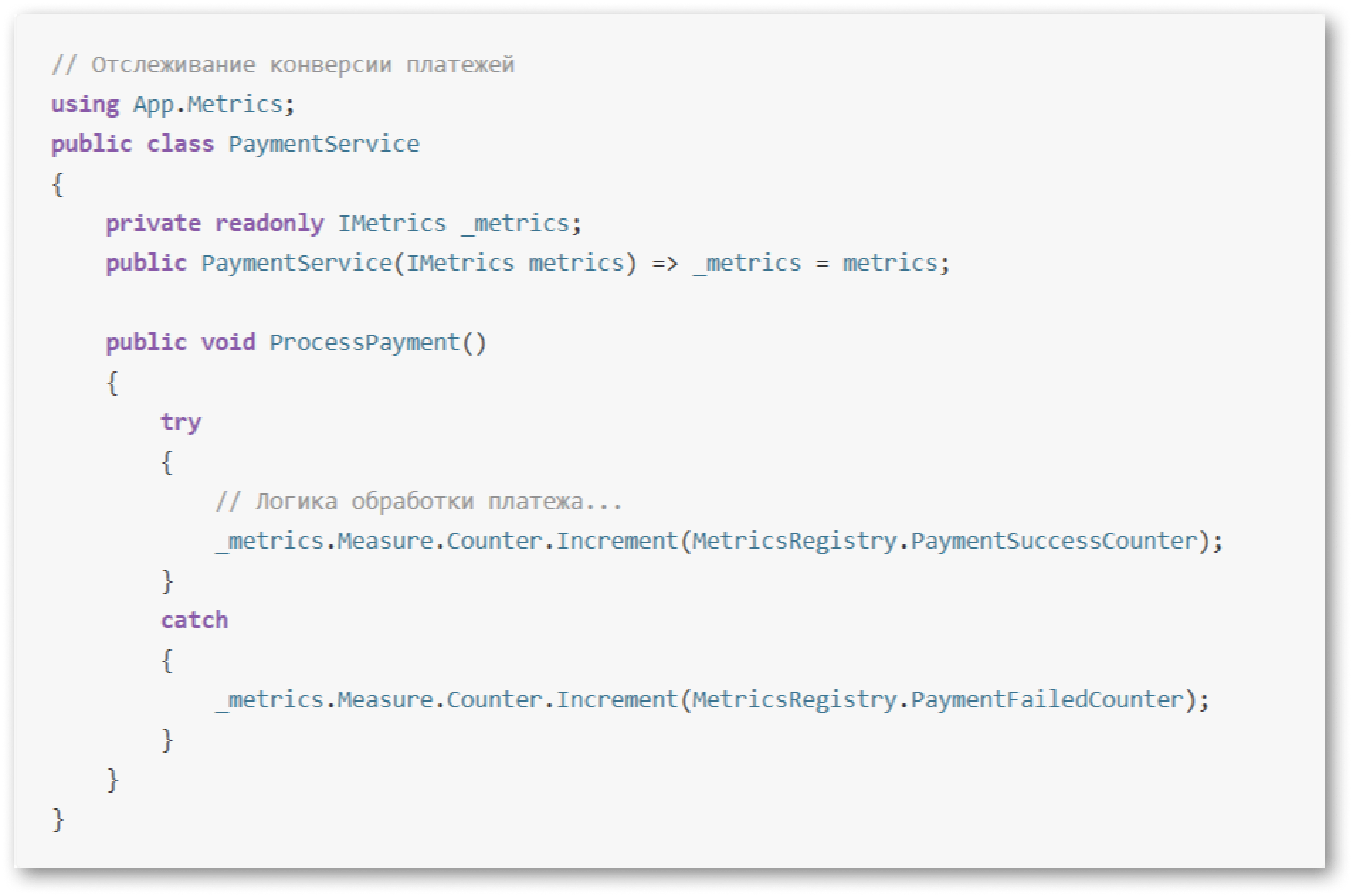
Инструменты: Рекомендуем App.Metrics для .NET-проектов — библиотека гибко интегрируется с мониторингом на базе Grafana.
Скорость работы:
Надежность:
Интеграции:
Для анализа пользовательского опыта недостаточно отслеживать только ошибки 5xx. Важно структурировать логи в JSON с контекстом позволяющим упростить поиск ошибки:
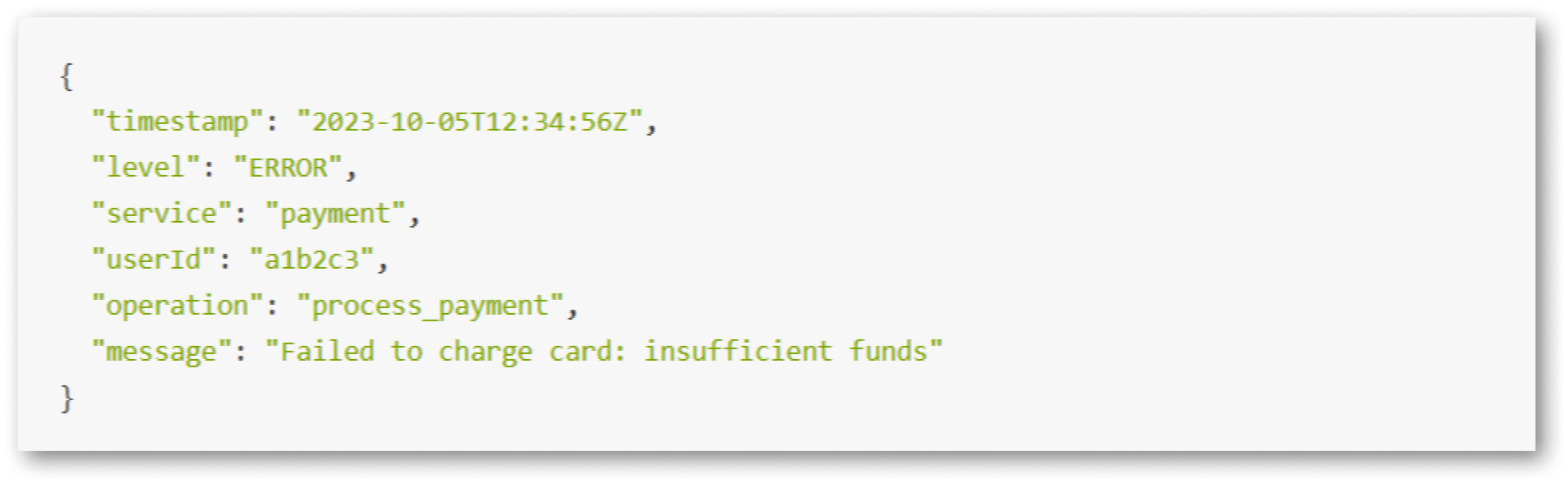
Теги вроде userId или operation позволяют быстро найти все логи, связанные с конкретным пользователем или транзакцией.
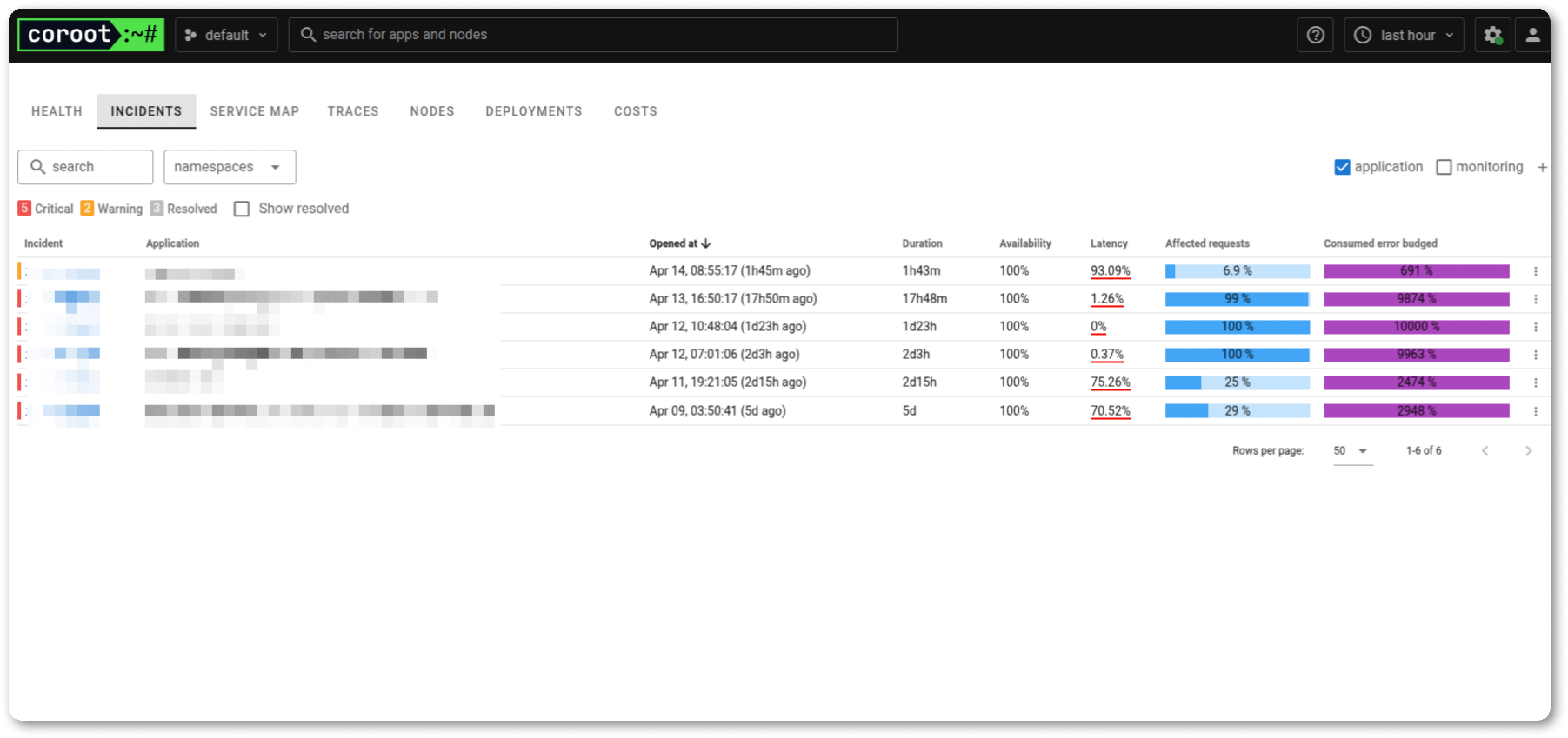
Грамотный мониторинг — это не просто сбор данных, а продуманная система быстрого реагирования. Мы выстраиваем процессы так, чтобы клиенты спали спокойно даже в пиковые нагрузки.
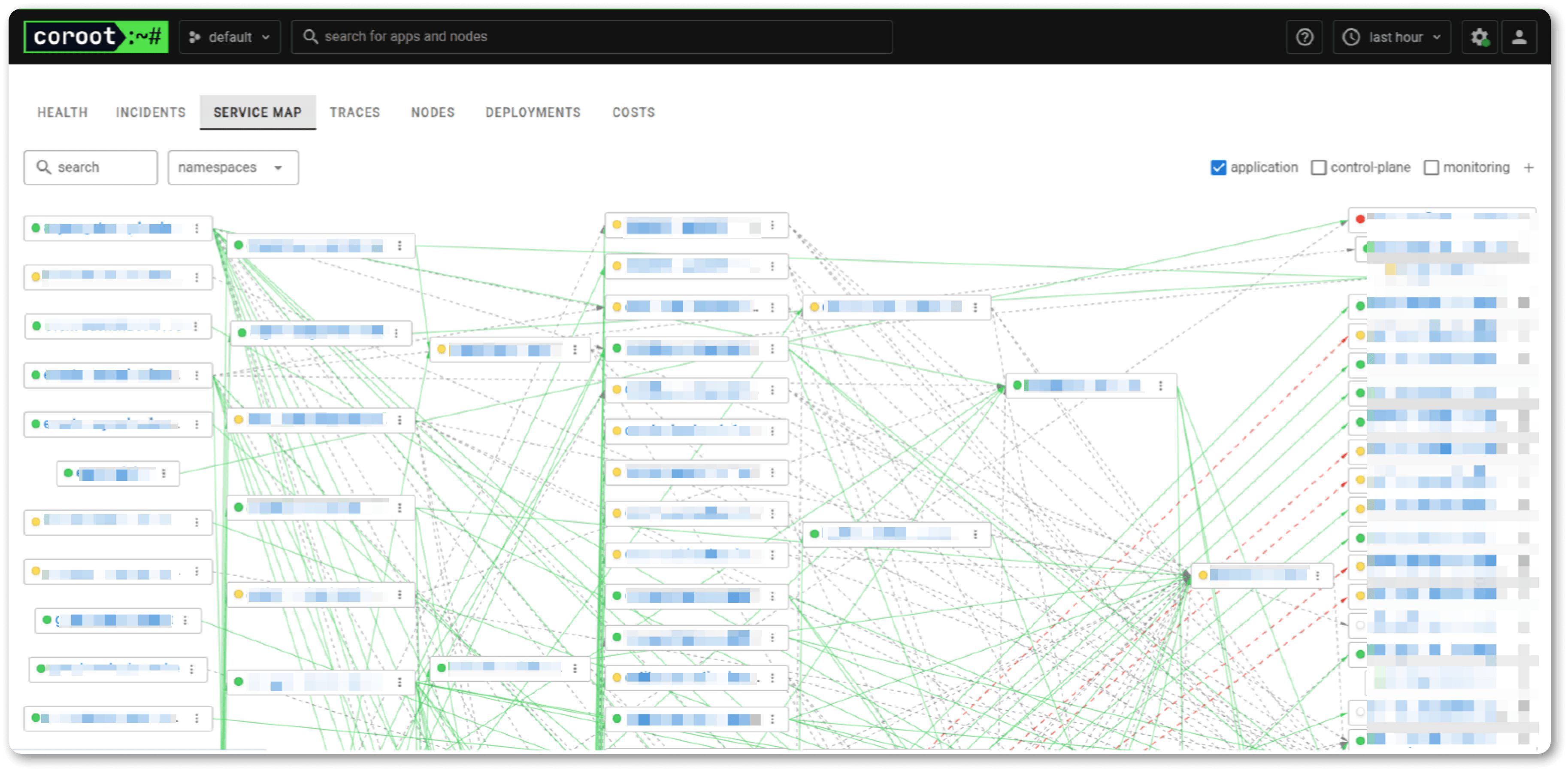
Шаг 1: Составьте карту сервисов.
Включите в нее все компоненты: ваши микросервисы, базы данных, очереди (Kafka, RabbitMQ), сторонние API (платежки, SMS-шлюзы).
Шаг 2: Определите зависимости.
Какие сервисы влияют на работу друг друга? Например, падение Redis может «уронить» кэширование и увеличить нагрузку на БД.
Для каждого узла из шага 1 определите срочные симптомы и те, которые требуют анализа.
Первые, которые требуют реакции сейчас. Например:
Наша система сама подберет вам исполнителей на услуги, связанные с разработкой сайта или приложения, поисковой оптимизацией, контекстной рекламой, маркетингом, SMM и PR.
Заполнить заявку
13233 тендера
проведено за восемь лет работы нашего сайта.
Решить их можно через настройку алертов в Grafana OnCall или PagerDuty. Для этого в сообщении нужно указать что случилось, где искать логи и краткий гайд по решению.
Примеры вторых, которые требуют анализа:
Их можно решить через отправку таких алертов в Slack/Email — они не требуют мгновенной реакции, но помогают предотвратить кризис.
Сбор логов: Используйте стек EFK (Elastic + Fluentd + Kibana) для агрегации и анализа логов.
Настройка Kubernetes
Liveness/Readiness пробы:
Работа с Redis: настройте политики очистки кэша в конфигурации Redis.
Инструменты для ленивых: если времени на интеграцию Prometheus/Jaeger нет, начните с Coroot. Он автоматически обнаружит сервисы, построит карту зависимостей и предложит базовые алерты.
Chaos Engineering: Раз в месяц устраивайте «стресс-тесты»:
Мониторинг должен не только сообщать о проблемах, но и подсказывать, что делать. Мы настраиваем его так, чтобы ваша команда тратила время на развитие, а не на тушение пожаров.
Observability — это не просто «продвинутый мониторинг», а способность системы отвечать на вопросы, которые вы даже не успели задать. Если мониторинг говорит: «Сервер упал», то observability объясняет: «Сервер упал из-за исчерпания памяти в поде Kubernetes, который обрабатывал очередь сообщений с задержкой в 5 секунд из-за проблем с сетью в облаке».
Представьте, что ваш микросервисный API внезапно начинает тормозить. Мониторинг покажет высокую загрузку CPU, но только observability раскроет полную картину: например, что проблема вызвана каскадными таймаутами из-за медленного ответа геолокационного сервиса, который, в свою очередь, упирается в неоптимальные запросы к PostgreSQL. Такой уровень детализации достигается за счет трех ключевых компонентов: метрик, собираемых Prometheus, логов из Loki/ELK/EFK, и трейсов, которые настраивают через Jaeger и OpenTelemetry.
Вот как это работает на практике. Допустим, вы видите в Grafana рост времени ответа API. Вместо ручного поиска причин, observability-стек позволяет мгновенно перейти к связанным трейсам в Jaeger и обнаружить, что 70% задержки возникают в сервисе кэширования. Анализ логов покажет, что ошибки «Connection timeout» начались после обновления версии Redis.
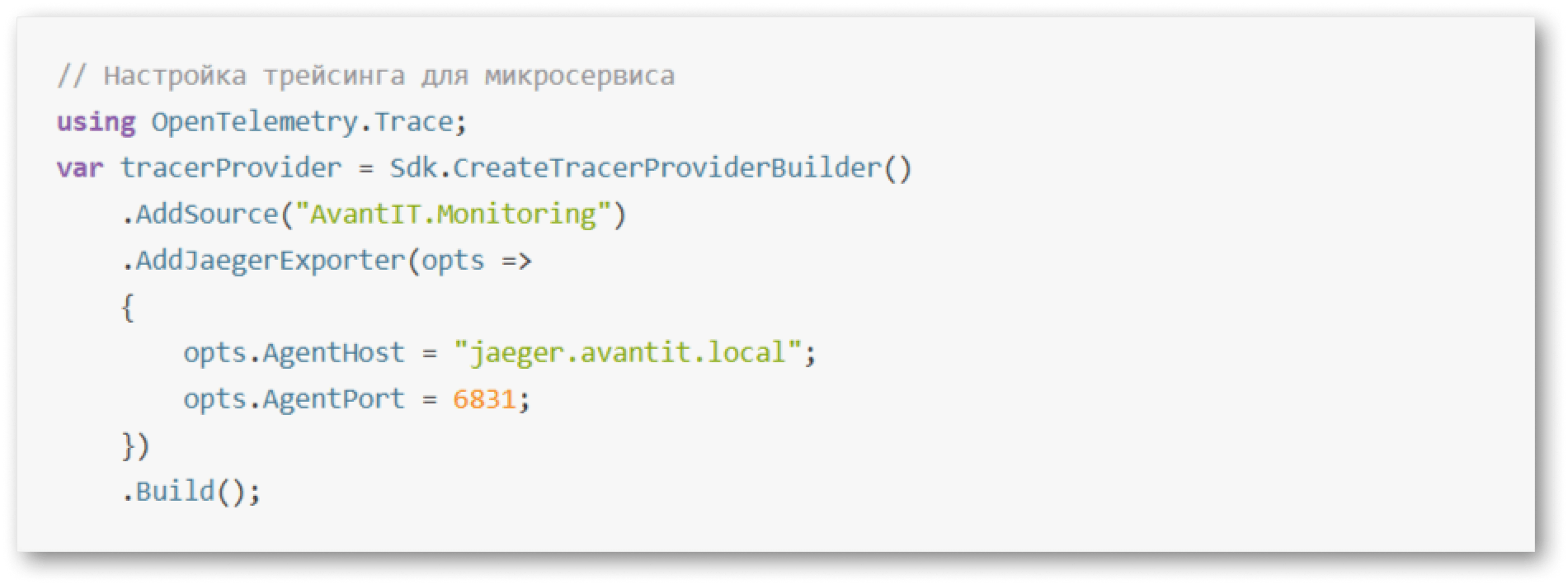
Для настройки трейсинга можно использовать OpenTelemetry — это универсальный стандарт, который применяется даже в сложных .NET-средах. Например, следующий код интегрирует Jaeger в микросервис, чтобы каждый запрос оставлял «след» для анализа:
Но observability — это не только инструменты, а культура работы с данными.
Главный секрет в том, чтобы превратить данные в действия. Когда вы видите, что p95 времени ответа API растет на 3% ежедневно, то необходимо оптимизировать код или добавить ресурсы.
Observability не устраняет проблемы — она делает их предсказуемыми. И это именно то, что превращает вашу инфраструктуру из расходов в конкурентное преимущество.
Мониторинг перестает быть задачей только для DevOps-инженеров, когда становится частью DNA вашей команды.Мы строим процессы так, чтобы метрики и трейсы влияли на каждое решение — от написания кода до управления релизами.
Observability-метрики (время ответа API, ошибки) встраиваются в код с первого дня. Например, если новая фича увеличивает задержку на 20%, это видно еще до код-ревью. Для админов связь метрик Prometheus с трейсами Jagger упрощает поиск «узких горлышек»: не нужно копать логи вручную, когда система сама показывает, где тормозит геолокационный сервис или блокируются запросы к PostgreSQL.
Хороший пайплайн не просто деплоит код, а прогнозирует риски. Вот как это работает:
Блокировка из-за загрузки CPU часто приводит к ложным срабатываниям. Гораздо эффективнее анализировать метрики, которые напрямую влияют на пользователей: ошибки, время ответа, бизнес-показатели.
Прогнозирование сроков: Рост метрики deployment failure rate сигнализирует, что команде нужен рефакторинг или дополнительные ресурсы.
Оценка рисков: Трейсы Jaeger показывают сервисы с низкой отказоустойчивостью — их можно доработать до перехода в прод.
Современные IT-системы больше не позволяют себе роскоши работать вслепую. Сбои, ошибки и простои — это не просто технические неполадки, а прямые угрозы бизнесу, особенно в эпоху микросервисов и распределенных облачных сред. Но хорошая новость в том, что сегодня у нас есть все инструменты, чтобы не просто реагировать на проблемы, а предупреждать их.





