




Тендеры и лиды
Информация
В последние годы большие языковые модели (LLM) доказали: они генерируют классные тексты, отлично справляются с отработкой типовых запросов в поддержке клиентов и помогают автоматизировать целые бизнес-процессы.
Есть проблема: решения «из коробки» редко готовы к применению на реальных задачах. Они могут не учитывать гайды бренда, специфику отрасли или предпочтения пользователей. Чтобы адаптировать языковую модель под конкретные задачи, повысить качество и предсказуемость ответов, её дообучают.
Если вы не сталкивались с задачей дообучения моделей, то, возможно, думаете, что это дорого и долго — и вообще то же, что сделать свою собственную Llama, GPT-5 или Mistral. Это не так.
Дообучение — не настолько масштабная задача, а главное, существуют десятки методов и техник, доступных в том числе малому бизнесу. В материале — о малоресурсных методах дообучения языковых моделей под узкие задачи.
Готовые большие языковые модели (LLM) представляют собой универсальный фундамент, но редко отвечают «из коробки» всем требованиям бизнеса. Дообучение необходимо, чтобы:
Спектр подходов к адаптации LLM широк.
На одном полюсе — RLHF (Reinforcement Learning from Human Feedback) и его производные (DPO, DRPO), требующие кластеров GPU (графических процессоров), разработки отдельной модели вознаграждения и долгих итераций обучения. Такие методы оправданы в крупных корпорациях с серьёзными бюджетами и задачами критической важности.
На другом полюсе — Parameter-Efficient Fine-Tuning (LoRA, prefix-tuning, adapter-tuning) и prompt-based техники (few-shot, zero-shot), позволяющие конфигурировать лишь малую часть параметров или вовсе обходиться без донастройки, полагаясь на промпты. Эти лёгкие приёмы делают дообучение LLM доступным стартапам, малому бизнесу и вообще любому энтузиасту.
Между этими полюсами есть промежуточные варианты: SimPO и ORPO оптимизируют предпочтения без разработки отдельной модели-судьи и минимизируют нагрузку на память. Комбо DPO + LoRA помогает быстро и малозатратно научить модель выбирать те ответы, что больше нравятся людям — дорабатывая не всю модель, а лишь компактные надстройки поверх неё.
В контексте этой статьи под «малой ресурсностью» методов мы будем подразумевать те, что не требуют тяжёлой инфраструктуры по сравнению с полным дообучением или RLHF. Мы будем опираться на следующие показатели:
Базовые модели могут отвечают слишком формально, не знают важных нюансов вашего продукта. Дообучение позволяет сделать из бота полноценного сотрудника компании, владеющего корпоративным стилем общения, знающего всё о компании и умеющего правильно эскалировать запросы клиентов в техподдержку.
Модель должна создавать контент, соответствующий tone of voice бренда — от дружелюбного и неформального до строгого B2B-стиля. Дообучение на корпусе текстов компании помогает сохранить узнаваемость и консистентность.
Стандартные LLM плохо справляются с внутренней терминологией и процедурами. Дообучение на корпоративных данных повышает точность извлечения информации, категоризации заявок и генерации отчётов.
Модель учится адаптировать сообщения под сегменты аудитории на основе предыдущих откликов и истории активности клиентов. Дообучение помогает персонализировать коммуникации и не выжигать аудиторию чрезмерным объёмом посланий.
В регулируемых отраслях критична точность терминологии и соблюдение комплаенс-требований. Дообучение нужно, чтобы учитывать отраслевые знания и снижать риски некорректных рекомендаций или нарушений.
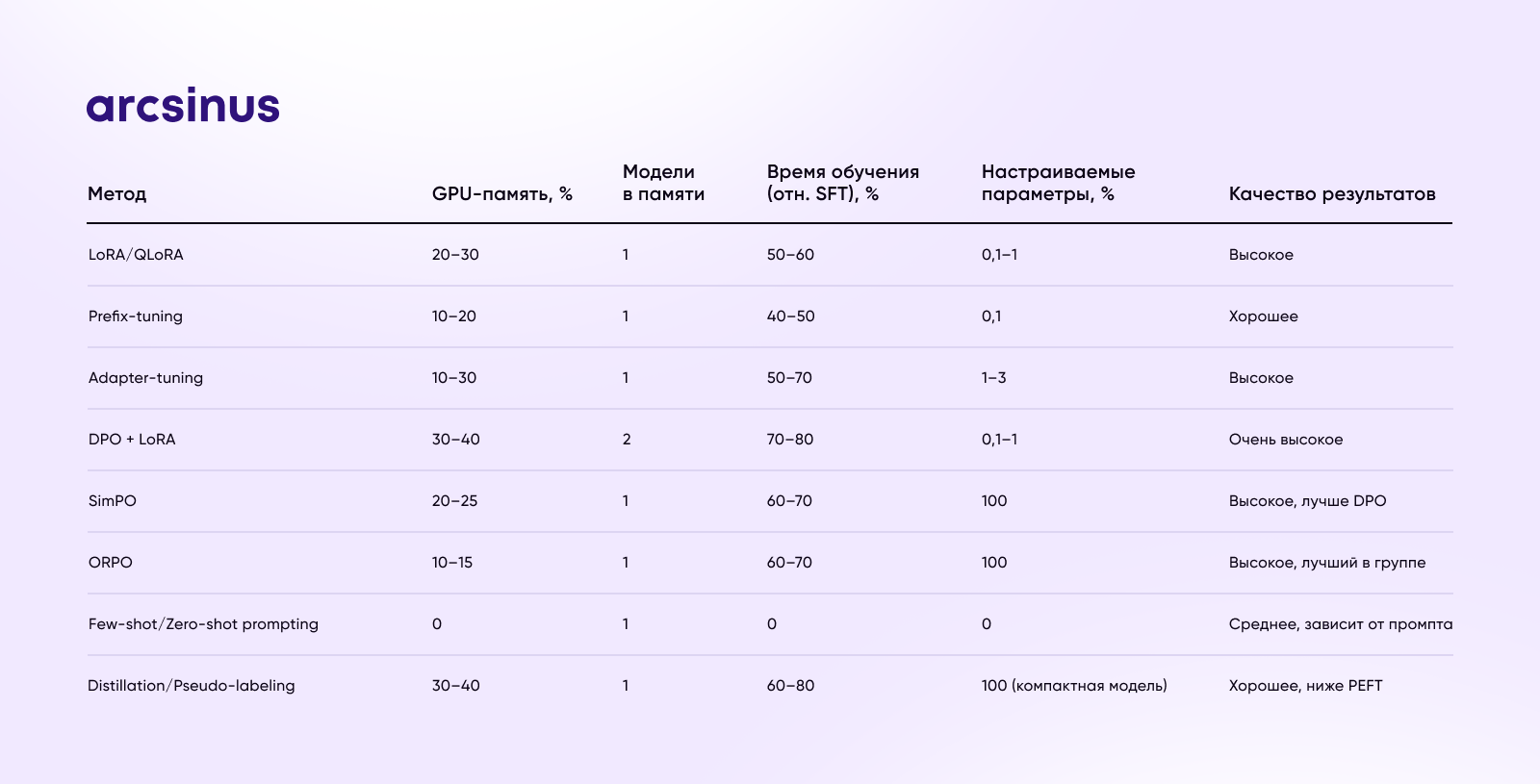
LoRA/QLoRA
Встраивает низкоранговые адаптеры в весовые матрицы модели. Обновляется 0,1–1% параметров, обучение на одном GPU занимает часы. Используется для быстрой донастройки модели, например, под новые разделы FAQ или региональные особенности.
Prefix-tuning
Модель учится лишь набору «префиксных» векторов, добавляемых к каждому запросу. Модель учится небольшому набору префиксных векторов — это специальный набор параметров, которые автоматически подставляются к любому новому запросу. Благодаря этому модель учится учитывать ваши требования, но при этом её основные «знания» не затронуты. Префиксы весят доли процента от модели и переключаются мгновенно.
Adapter-tuning
В модель вставляют небольшие адаптерные блоки между слоями трансформера. Параметры адаптеров составляют 1–3 % от модели, легко комбинируются для разных задач типа маркетинговых или создания техдокументации.
DPO + LoRA
Наша система сама подберет вам исполнителей на услуги, связанные с разработкой сайта или приложения, поисковой оптимизацией, контекстной рекламой, маркетингом, SMM и PR.
Заполнить заявку
13260 тендеров
проведено за восемь лет работы нашего сайта.
Комбинация прямо оптимизирует модель под пары ответов — предпочитаемый А vs не предпочитаемый Б — без участия модели вознаграждения и PPO. Комбо с LoRA снижает нагрузку на память и ускоряет цикл донастройки ответов чат-бота под оценки людей.
SimPO
Ещё проще, чем DPO: не требует справочной модели, обновляет политику напрямую с учётом предпочтений. Экономит ~20 % времени и памяти по сравнению с DPO, подходит для доработки рекомендаций.
ORPO
Использует отношение шансов (odds ratio) для preference learning без эталонной модели. Обновляет 100 % параметров модели через специальную функцию потери, но требует лишь одной копии модели в памяти.
Few-shot/Zero-shot prompting
Вообще не требует дообучения модели: достаточно продуманных примеров в промпте. Быстро внедряется для разовых задач, например, создания заголовков или классификации отзывов без инфраструктуры.
Lightweight distillation и pseudo-labeling
Генерируют разметку «машинным» учителем на больших неразмеченных датасетах, затем дообучают компактную модель. Подходит для построения узкоспециализированных чат-ботов при ограниченном бюджете и данных.
Стартапам и малому бизнесу с ограниченным бюджетом стоит начать с LoRA, prefix-tuning или ORPO: быстрая настройка на одном—двух GPU и результаты за часы, максимум — дни.
Средним командам с доступом к нескольким GPU подходят SimPO и DPO+LoRA: оптимальный баланс качества и ресурсов.
Крупные проекты могут сочетать PEFT со сложными алгоритмами оптимизации предпочтений (DPO, DRPO) для задач, где важна максимальная точность и устойчивость.
Облако (AWS, Azure, GCP) — быстрое масштабирование и доступ к топовым GPU, удобно для экспериментальных циклов.
On-premise подходит для высоких требований к безопасности и контролю данных, но требует вложений в железо и команду DevOps.
Гибридные решения — основная работа в облаке, чувствительные данные держать локально, а готовые решения переносить в прод.
Внедрите автоматический сбор метрик — точность ответов, доля отказов, пользовательские оценки.
Используйте A/B-тестирование разных версий адаптации (LoRA vs prefix-tuning) для выбора оптимального метода.
Регулярные оценивайте работу моделей — после изменения данных, процессов или целевой аудитории быстро дообучайте или переключайте префиксы.
Тимофей Кузнецов, ML-инженер arcsinus



