
Тендеры и лиды
Информация


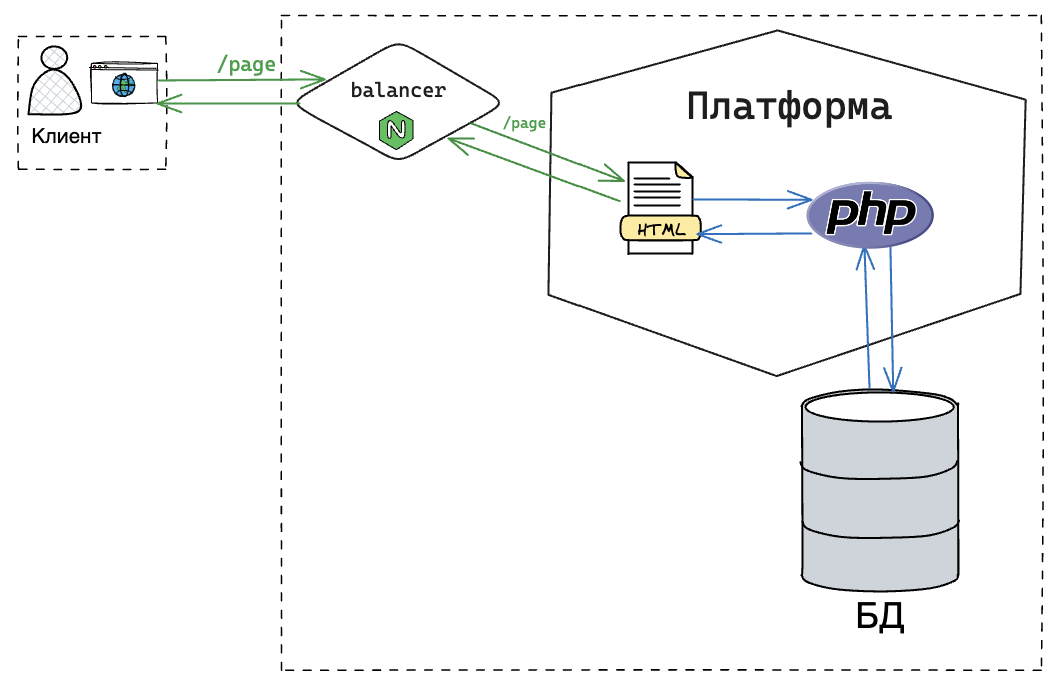
Несколько лет назад процесс передачи веб-страниц происходил следующим образом: сервер получал запрос от клиента, обрабатывал его и возвращал полностью готовую HTML-страницу. Например, на платформах PHP типа Magento или Bitrix запросы обрабатывались сервером, который извлекал данные из СБД, формировал HTML-страницу и отправлял его на клиентскую сторону. Это был стандартный подход, но со временем фронтенд стал усложняться, и всё больше данных переносилось на клиентскую сторону.
С ростом уровня фронтенд-разработки стали появляться одностраничные приложения (SPA). У такого подхода есть множество преимуществ. Прежде всего, это использование современных фреймворков, которые ускоряют разработку и делают ее более удобной.
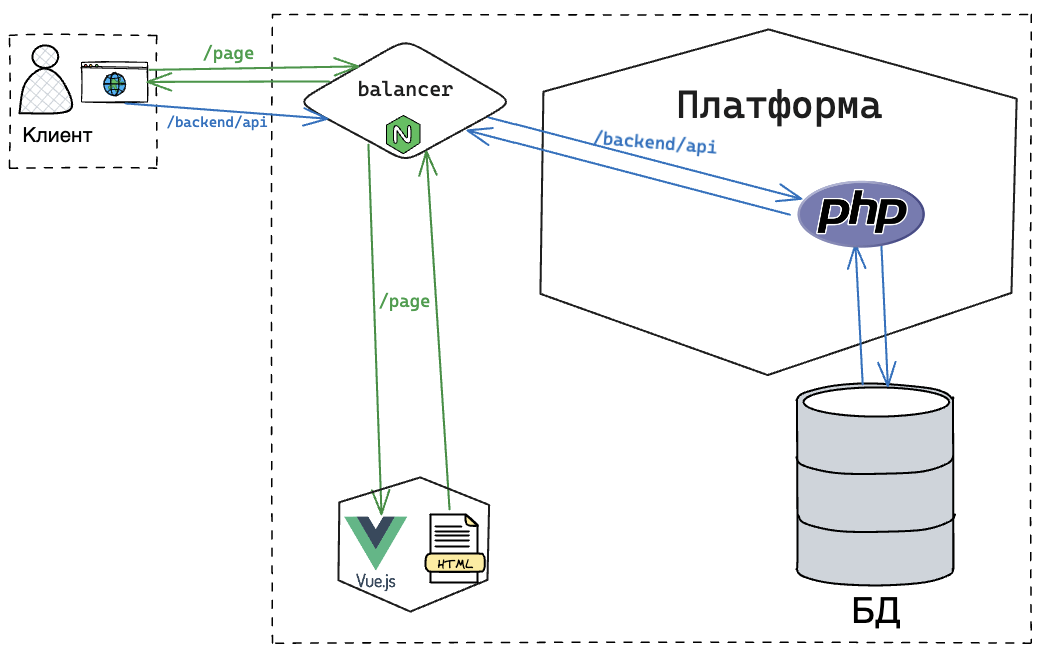
Взаимодействие фронтенда и бэкенда стало происходить через API, что позволило разделить их на независимые части. Это упростило процесс разработки и обновлений. Однако у SPA есть и недостатки.
Главный минус SPA-приложений заключается в том, что на начальном этапе клиент получает «голый» HTML. Дальнейшая обработка страницы происходит фреймворком, который загружает данные и отображает контент. Это приводит к тому, что пользователи видят прелоадер на экране в первые несколько секунд загрузки. Но ещё более серьёзная проблема заключается в SEO — поисковым ботам нужен уже готовый контент, и отсутствие его может негативно сказаться на индексации страницы. Ещё одна сложность — это достижение высоких показателей PageSpeed (выведение в зеленую зону), так как оптимизировать SPA-приложение для скорости загрузки значительно сложнее.
На помощь приходит серверный рендеринг (SSR). Этот подход позволяет генерировать HTML на сервере, как это было раньше, но теперь данные берутся не из баз данных напрямую, а из API. Здесь появляется дополнительный бэкенд на JavaScript, который взаимодействует с фреймворком, запрашивает данные, формирует страницу и отправляет её клиенту.
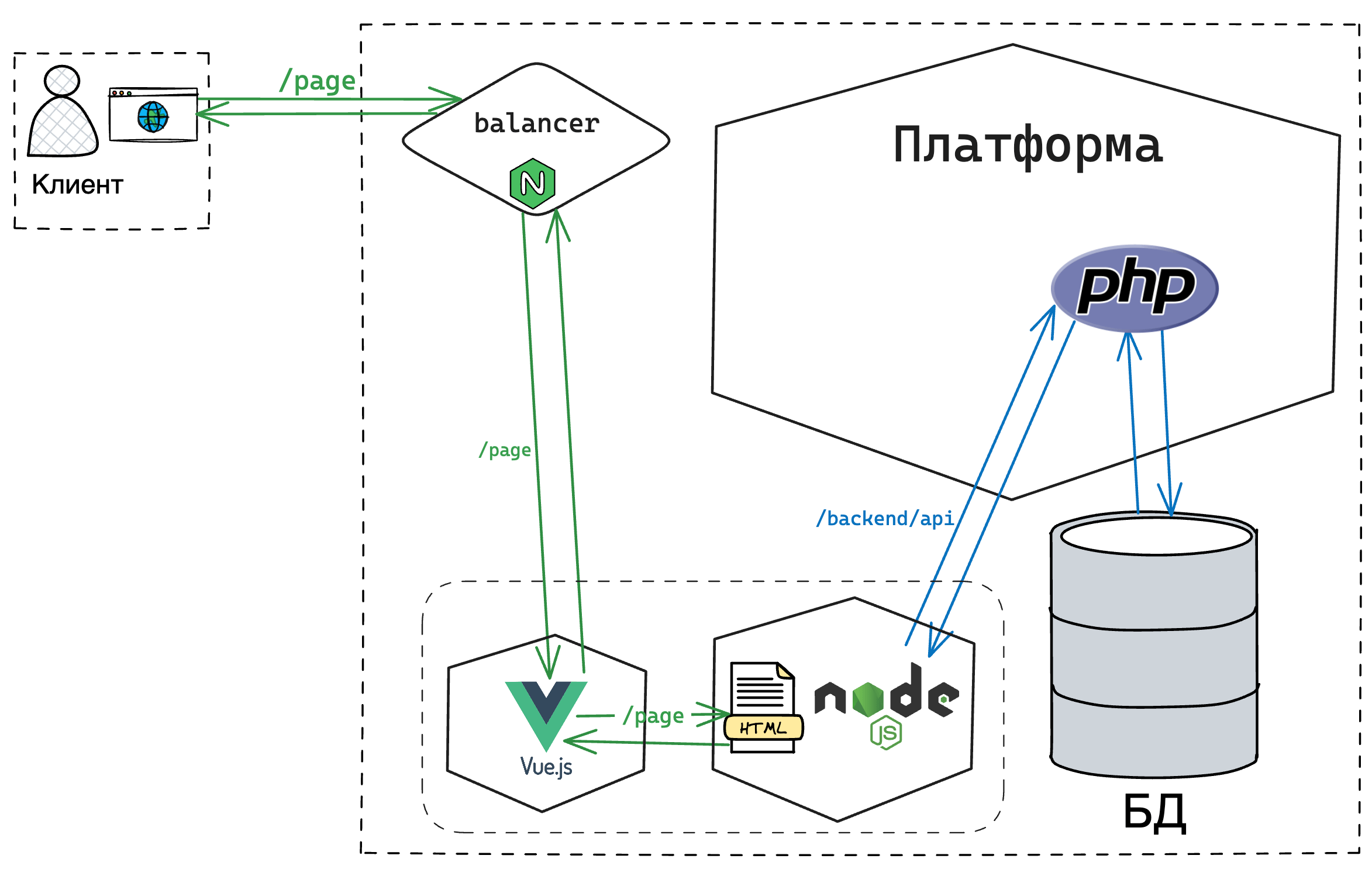
Хотя на первый взгляд SSR решает проблему, ситуация усложняется. Появляется ещё один бэкенд, увеличивается количество сетевых запросов, пусть даже и внутренних. Это повышает нагрузку на сервер. Кроме того, время, которое раньше тратилось на прелоадер на клиенте, теперь переносится на сервер, что иногда приводит к тому, что даже поисковые боты сталкиваются с задержками в загрузке контента. И здесь появляется необходимость в дополнительных оптимизациях.
О проекте
Проект, о котором я расскажу, реализован на платформе Magento с кастомным интерфейсом (VueJS) и рядом микросервисов, которые используются для оптимизации. В системе представлено около 130 000 товаров, доступных в более чем 50 регионах. Из-за специфики проекта в Google Search Console отображается около 6 миллионов страниц, которые должны быть проиндексированы роботами поисковых систем. Такое большое количество страниц объясняется различными ценообразованиями и товарными предложениями для разных регионов — фактически, каждая комбинация этих факторов создаёт уникальную страницу.
Нагрузка на серверы стабильно поддерживается на уровне 300 запросов в секунду (RPS) на бэкенд при постоянных 1 000 пользователях онлайн. Это обусловлено тем, что товары представлены в разных регионах, и сайт должен поддерживать быструю отдачу страниц и стабильную производительность. Кроме того, в период пиковых нагрузок, например, во время «чёрной пятницы», необходимо также поддерживать стабильную работу.
Есть еще один важный момент: возможности вертикального и горизонтального масштабирования проекта ограничены из-за ресурсов серверов. Это требует более тонких решений для оптимизации работы системы.
На начальном этапе проекта использовался серверный рендеринг (SSR) только для поисковых ботов. Когда попытались включить SSR для клиентов, время загрузки страниц увеличилось до 2-5 секунд, что совершенно неприемлемо для пользователей. Для ботов время рендеринга составляло 1-2 секунды, но даже этого оказалось недостаточно, потому что при такой скорости индексирование 6 миллионов страниц могло занять до двух месяцев, что, очевидно, не является рабочим сценарием. Как результат, значительная часть страниц не попадала в SEO и органический поиск, что негативно сказывалось на бизнесе.
Забегая вперед, можно отметить, что разработанная инфраструктура микросервисов применима не только на платформе Magento и кастомном Vue, но и в других системах.
Выделю три ключевых параметра кэширования, которые играют важную роль в оптимизации производительности:
В данном проекте был применен полностраничный кэш (Full Page Cache, FPC). Это решение работает достаточно просто: на первом этапе серверный рендеринг (SSR) обрабатывает запрос и формирует страницу, при этом создаётся уникальный ключ для кэша. Полностраничный кэш был выбран потому, что основной задачей было сократить время загрузки страницы до 100 мс в 95-м процентиле, что требовало максимальной оптимизации производительности.
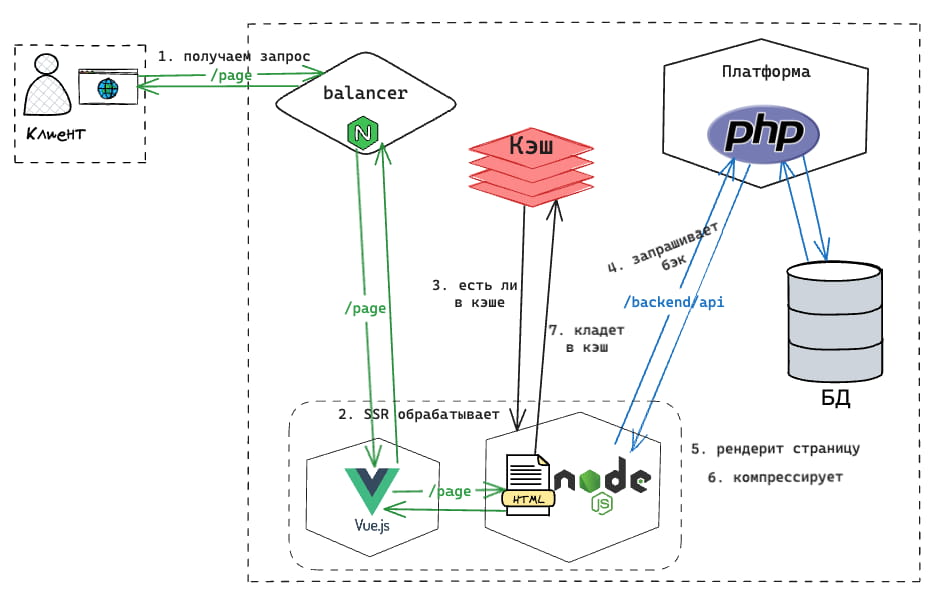
В первый раз кэш, конечно, ещё пуст, поэтому система обрабатывает и сжимает страницу с помощью алгоритма Brotli, который считается одним из самых эффективных для сжатия данных. Затем сжатая страница сохраняется в кэше. При последующих запросах она уже быстро отдается клиенту напрямую из кэша, что значительно сокращает время загрузки страницы.
Важно отметить, что сжатие с использованием Brotli требует осторожности: слишком высокая степень сжатия может сильно нагрузить сервер, поэтому нужно найти баланс.
Судя по данным из метрик и профилирования, нам была необходима внешняя простая система, которая могла бы быстро обращаться к кэшу, извлекать данные и отдавать их обратно клиенту. Важно было, чтобы эта система работала максимально эффективно, без задержек.
На момент начала работы у нас уже были настроены различные уровни кэширования: кэш запросов, кэш конфигураций и другие. Они функционировали независимо друг от друга, не создавая конфликтов. В итоге, общая картина системы выглядела так: каждый тип кэша выполнял свою задачу, что позволяло сократить нагрузку на сервер и существенно улучшить скорость обработки запросов.
При выборе key-value хранилища мы рассматривали несколько популярных решений. В наш топ вошли четыре варианта: Redis, KeyDB, Memcached и NATS.
Каждое из этих решений имеет свои сильные и слабые стороны, и окончательный выбор будет зависит от конкретных задач проекта: от необходимости в сложных структурах данных и репликации до простоты и скорости работы.
Актуальность данных достигается с помощью механизма тегов, привязанных к каждой сущности, например, к продуктам, категориям или баннерам. При сохранении записи в кэш к ней прикрепляются теги всех сущностей, которые входят в эту запись. Когда одна из сущностей обновляется или удаляется, например, баннер, кэш по его тегу удаляется.
Это допустимо также для таких элементов, как баннер на главной странице. Однако, когда дело доходит до более сложных и часто используемых элементов, таких как навигационное меню, которое отображается на большинстве страниц сайта, ситуация усложняется. Удаление одной сущности может привести к необходимости одновременного удаления миллионов записей из кэша.
У большинства key-value хранилищ нет встроенного решения для работы с тегами. Чтобы реализовать такой механизм, для каждого тега создается отдельный ключ, который хранит ключи на другие записи кэша. При необходимости все эти записи удаляются массово с помощью операций типа multi-delete. Мы использовали эту схему на Redis и KeyDB. Несмотря на все попытки распараллеливания и оптимизации, система со временем начала испытывать трудности.
На помощь пришли документоориентированные хранилища, которые позволили более гибко управлять данными и значительно упростили процесс поддержания актуальности кэша.Массив тегов сохраняется вместе с записью в кэше, что позволяет эффективно управлять данными. Это значит, что по идентификатору мы можем быстро выбирать и удалять записи, что происходит за миллисекунды. Мы выбрали Couchbase как основное хранилище, хотя параллельно тестируем и MongoDB, и результаты с ним также отличные.
Наша система сама подберет вам исполнителей на услуги, связанные с разработкой сайта или приложения, поисковой оптимизацией, контекстной рекламой, маркетингом, SMM и PR.
Заполнить заявку
13359 тендеров
проведено за восемь лет работы нашего сайта.
Однако, несмотря на внедрение этого решения в серверный рендеринг (SSR), ожидаемого прироста производительности мы не получили. Поставленной цели в 100 мс на 95-м процентиле достичь не удалось. Более того, даже закэшированная страница могла выдаваться за 400-500 мс. Причина кроется в том, что наша среда исполнения (Node.js) однопоточная. Хотя у нас были микрозадачи и псевдопараллельность, если предыдущий запрос из кэша не был завершен, новый запрос задерживался, пока система рендерила текущий.
Возникла идея запараллелить Node.js, создать множество подов для распараллеливания запросов. Но здесь мы столкнулись с ограничениями ресурсов: развернуть 50 подов, из которых половина будет простаивать, мы не могли себе позволить.
Кроме того, стало очевидным, что кэш нужно прогревать заранее, а не на реальных пользователях, чтобы минимизировать задержки.
В итоге мы решили перейти на слоистую систему кэширования. Мы внедрили кэш L1 для быстрого доступа и L2 — более медленный, но полный кэш, который обеспечивает хранение всех данных. Этот подход помог улучшить производительность и достичь более стабильной работы системы.
У нас проект был на PHP, и при выборе фреймворков мы остановились на двух самых быстрых в своих категориях. В категории классических FPM-подходов мы выбрали Phalcon, написанный как C-расширение. Благодаря этому он самый быстрый, не считая неблокирующих/асинхронных.
В категории event-driven решений мы остановились на Swoole как самый быстрый неблокирующий PHP-фреймворк (по данным бенчмарка от https://web-frameworks-benchmark.netlify.app/result).
По бенчмаркам и нашему собственному опыту, связка этих инструментов показала наилучшие результаты в плане производительности.
Для оптимизации работы с кэшем мы внедрили механизм его репликации. Когда происходит деплой или обновляется важная часть сайта, например, навигационное меню, миллионы записей кэша удаляются одновременно. Это вызывало проблемы — сайт хоть и не полностью «ложился», но начинал сильно замедляться, что было заметно по резкому скачку в мониторинге.
Чтобы устранить эту проблему, мы реализовали реплицированный кэш. Это не стандартная схема «мастер-реплика», но суть в том, что данные сохраняются в отдельное хранилище, которое живет чуть дольше основного (мастер-кэша). Когда мастер-кэш очищается, реплика еще некоторое время хранит данные, и это позволяет постепенно прогревать новый кэш.
Такой подход обеспечил нам плавный и бесшовный деплой, без заметных просадок в скорости отдачи страниц, что значительно улучшило производительность сайта.
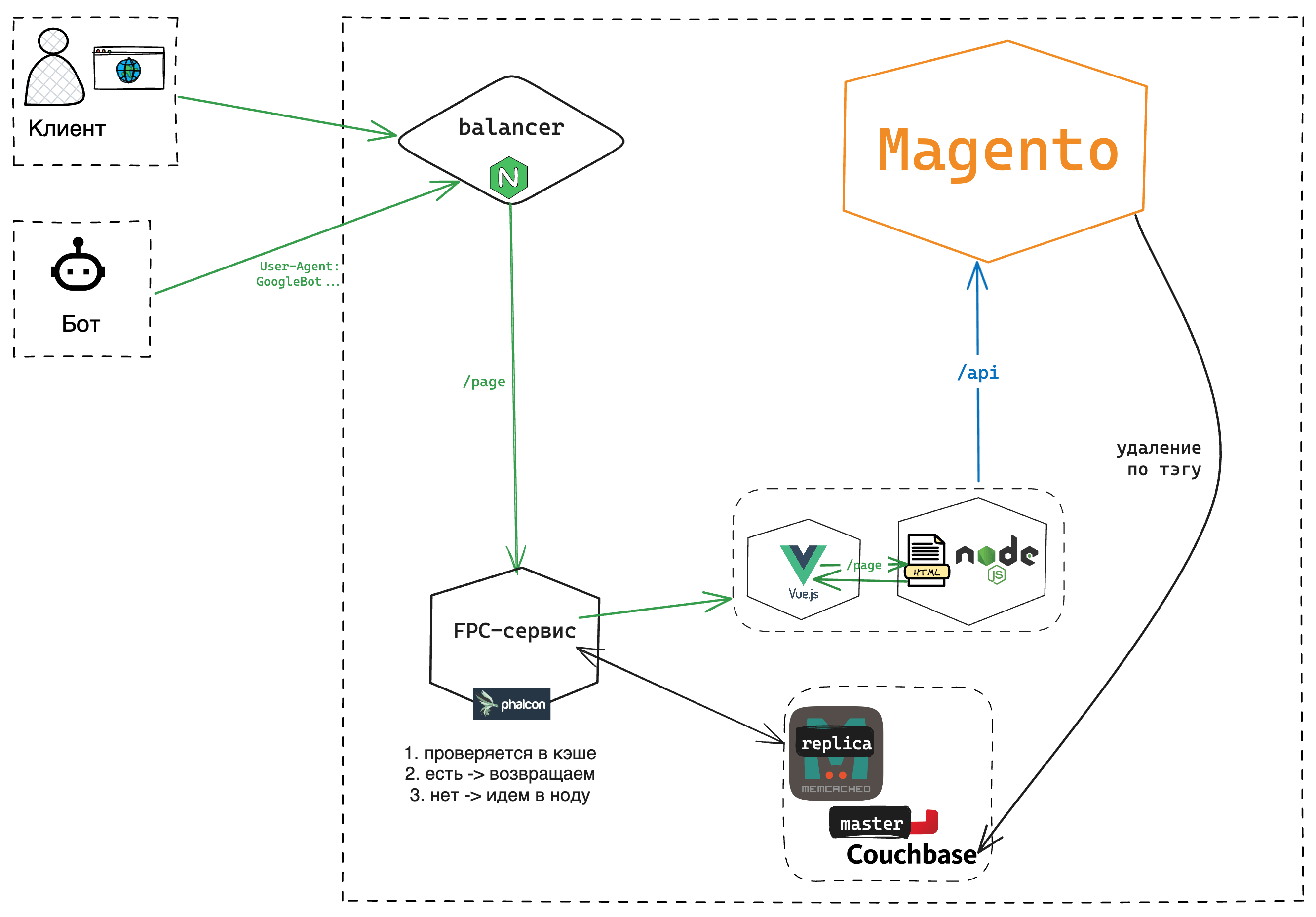
Мы разделили кэши на основе трех ключевых критериев: скорость выдачи, актуальность данных и частота попадания в кэш.
Для роботов:
Для клиентов:
Такое разделение кэшей позволяет оптимально управлять данными в зависимости от потребностей разных типов запросов, обеспечивая и актуальность информации, и скорость ее выдачи.
Также для оптимизации работы сайта мы реализовали микросервис для прогрева кэша, который позволяет заранее загружать данные в кэш и минимизировать задержки при доступе пользователей к страницам. Микросервис выполняет несколько ключевых задач:
2. Прогрев всех страниц по расписанию. Это помогает обеспечить наличие кэша для любых запросов, даже на редко посещаемые страницы.
3. Интеграция с FPC-сервисом. Если Full Page Cache-сервис обнаруживает, что страницы отсутствуют в основном (мастер) кэше, но есть в реплике, он сигнализирует микросервису для их прогрева. Это помогает избежать ситуации, когда данные внезапно теряются и не могут быть быстро возвращены.
Нагрузочное тестирование было ключевым этапом перед каждым деплоем новой версии в продакшн. Это необходимо для того, чтобы убедиться, что система выдерживает ожидаемую нагрузку и функционирует стабильно после обновлений.
Для тестирования мы используем k6js, заменив ранее использовавшийся JMeter. k6js предоставляет удобные возможности для написания сценариев тестирования и интеграции с системами мониторинга.
Наш инструмент для мониторинга и анализа результатов тестирования — это сервис от Grafana, который интегрируется с InfluxDB и отображает данные в виде графиков, предоставляя наглядную информацию о производительности системы.
В процессе тестирования мы используем наборы данных, полученные из нашего сервиса прогрева кэша, что позволяет нам моделировать реальную нагрузку. Мы также программно обрабатываем случаи, когда данные не попадают в кэш, чтобы выявить и устранить возможные проблемы.
Наши усилия принесли отличные результаты: в начале тестирования мы ставили цель обеспечить время ответа в 100 мс, но в итоге достигли 41 мс на 95-м процентиле, что значительно превышает наши ожидания и демонстрирует высокую эффективность и стабильность системы.



