

Тендеры и лиды
Информация
Компьютерное зрение (Computer Vision, CV) — это набор алгоритмов, которые превращают обычную картинку в структурированные данные. Для человека это фото, а для компьютера — матрица пикселей. Задача CV — найти в этих числах закономерности и ответить на вопросы: «Это человек?», «Где номерной знак?», «Сколько машин в кадре?».
Изображение для компьютера — не «снимок», а таблица значений яркости и цвета. Алгоритмы ищут в этих данных паттерны: края, текстуры, формы — и сопоставляют их с тем, чему модель обучалась (кошки, люди, дорожные знаки и т.д.).
📥 Сбор: камера/сканер передают кадр как массив пикселей.
🔧 Предобработка: нормализация цвета, ресайз, шумоподавление — для единообразия входа.
🔍 Признаки: классика (HOG, Хаара) или CNN (нейросеть учится сама: края → формы → объекты).
🎯 Распознавание: классификация («какой это предмет») или детекция (рамки + класс + уверенность; Есть различные модели: YOLO, R-CNN, SSD.
🧠 Интерпретация: логические связи поверх рамок («пешеходы переходят перед машиной») + ИИ-логика.
- Сбор и разметка данных.
Нужны тысячи изображений, где специалисты вручную обводят объекты рамками/масками и подписывают классы.
- Обучение. Нейросети многократно показывают примеры с правильными ответами. Алгоритм постепенно корректирует внутренние веса, минимизируя разницу между предсказанием и реальностью.
- Валидация и тестирование.
Отдельный набор данных проверяет, научилась ли модель обобщать знания или просто «выучила наизусть» учебные примеры.✅ После обучения система способна распознавать объекты, которых раньше не видела, но относящихся к известным классам (например, новую модель автомобиля как «машину»).
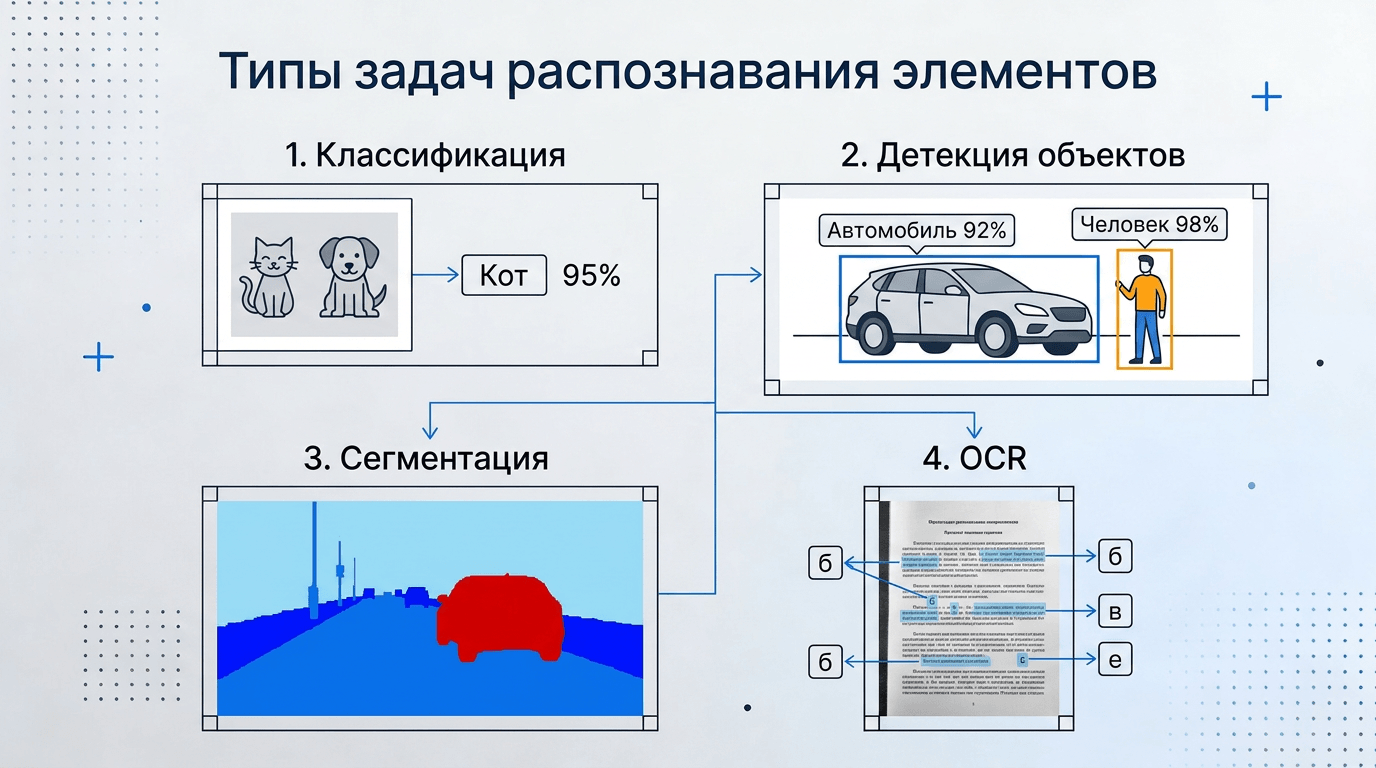
🔹 Классификация — определение общего класса изображения (документ, рентген с патологией, порода собаки).
Наша система сама подберет вам исполнителей на услуги, связанные с разработкой сайта или приложения, поисковой оптимизацией, контекстной рекламой, маркетингом, SMM и PR.
Заполнить заявку
13507 тендеров
проведено за восемь лет работы нашего сайта.
🔹 Детекция объектов — поиск объектов с отрисовкой рамок, указанием класса и вероятности.
🔹 Семантическая сегментация — разметка каждого пикселя: дорога, разметка, пешеход, небо. Критично для беспилотников и медицинской диагностики.
🔹 OCR (распознавание текста) — выделение текстовых блоков и преобразование их в машинный текст.
🔹 Биометрия и распознавание лиц — детекция лица, нормализация ракурса, извлечение уникальных признаков и сравнение с базой данных.
Представьте многослойный фильтр:
1️⃣ Первый слой замечает только контуры.
2️⃣ Следующие комбинируют их в простые формы (круги, линии, углы).
3️⃣ Глубокие слои собирают формы в знакомые объекты: «голова», «колесо», «буква».
4️⃣ Финальный слой решает, к какому классу относится увиденное и где именно оно находится.📌
Подписывайтесь — в следующих постах разберём конкретные архитектуры моделей и их особенности.
💬 Есть продукт, куда хотите внедрить компьютерное зрение? Пишите в комментариях — разберём ваш кейс на реальных примерах! 👇



