


 Сумма технологий
Сумма технологий 
Тендеры и лиды
Информация
SEO — это не «магия попадания в топ», а длинная история попыток поисковых оптимизаторов договориться с поисковыми системами о главном: показать человеку лучший ответ на его вопрос — и при этом честно заслужить органический трафик. Поисковики усиливали качество и антиспам, оптимизаторы искали рычаги, бизнес учился считать экономику. В итоге из ремесла «подкрутим метатеги» SEO выросло в дисциплину на стыке продукта, контента, аналитики и технологий.
Сам термин search engine optimization закрепился в индустрии примерно к концу 1990-х. Часто называют 1997 год — именно тогда выражение стало активно употребляться.
Вот история появления SEO со слов Боба Хаймана (приведена в книге “Net Results”, 1997; публикация Search Engine Land, 2 октября 2008):
«Лето 1995-го, понедельник, около трёх ночи. У Боба Хеймана — тогда старший вице-президент по развитию аудитории в компании Cybernautics, — звонит телефон. На линии менеджер рок-группы Jefferson Starship (клиент Cybernautics), для которого они делали сайт.
— Почему, б***ь, мы не появляемся на этой проклятой странице? Почему страница номер четыре, вы, б***ь, идиоты! — кричит голос на другом конце провода. Наутро Хейман собирает команду и ставит задачу: научиться управлять поисковой выдачей.
Выясняется забавная деталь эпохи: тогда органика во многом «слушала» частоту ключевой фразы на странице. Дизайнеры Cybernautics сделали сайт аккуратным — и слов «Jefferson Starship» на нём было меньше, чем на фан-страницах. Решение тоже из тех времён: добавить фразу «Jefferson Starship» ещё много раз — даже крошечным чёрным текстом на чёрном фоне. Результат — страница взлетает на первое место, клиент доволен. А Боб Хейман и его партнёр Лиланд Харден дают этому занятию имя: Search Engine Optimization — и вскоре нанимают первого Search Engine Optimization Manager. Так (по их версии) и родилось SEO».
История поисковой оптимизация неотделима от истории развития поисковых машин: изменялись алгоритмы ранжирования — поисковая оптимизация подстраивалась под изменения, а влияние оптимизаторов на поисковую выдачу заставляло поисковые машины менять алгоритмы.
Сегодня, когда сформированный поиском железный паттерн поведения «проблема — вопрос — ссылка — ответ» меняется на «проблема — вопрос — ответ — ссылка» и скоро превратится в «анализ — ответ — решение», сложно представить, что это — результат большого пути развития поиска.
Краткий таймлайн рождения веб-поиска (как мы вообще сюда пришли)
С этого момента (1997–1998 годы) началось движение от ранжирования по плотности вхождения ключевого слова к пониманию смысла запроса и определению полезности ответа и, затем, к самостоятельному ответу на вопрос пользователя.
Для России поисковая оптимизации стала историей развития Яндекса и Google в силу их популярности на этой территории. На момент создания этой статьи (февраль-март 2026) поисковый спрос делят Яндекс и Google.
По данным Яндекс Радара, 70% визитов на сайты с Яндекс Метрикой совершается из поиска Яндекса, а 30% — из поиска Google. Причём Яндекс лидирует уже больше 10 лет.

Динамика визитов в поисковые системы Яндекс и Google (Яндекс Радар)
По данным счетчика Liveinternet, который установлен на 80 000 сайтов с заметным перекосом в информационные ресурсы, ситуация с популярностью противоположная: Яндекс — 45%, Google — 55%.
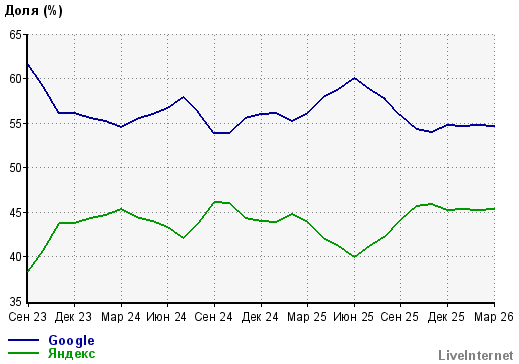
Динамика популярности поисковых систем Яндекс и Google (Live Internet)
Данные сервиса Statcounter таковы: Яндекс — 72%, Google — 26%. Но это не точно: Statcounter собирает данные только с сайтов, где установлен их счётчик (около 1,5–2 млн ресурсов по всему миру). Причём в российском сегменте этот счётчик встречается реже, чем Яндекс Метрика. Кроме того, исторически сложилось, что зарубежные счётчики чаще ставят на сайты, ориентированные на международный трафик или IT-сообщество: это может приводить к завышению доли Google в обычное время и её занижению в период снижения трафика на такие ресурсы.
Но, как ни посмотри, Яндекс в России не одинок, а доля Google велика. И лидерами большую часть огромного периода протяжённостью в 30 лет в России были именно Яндекс и Google. Хотя до 2010 года бывали периоды, когда Google бился за второе место с Рамблером, а какой-то процент спроса оттягивал на себя Апорт.
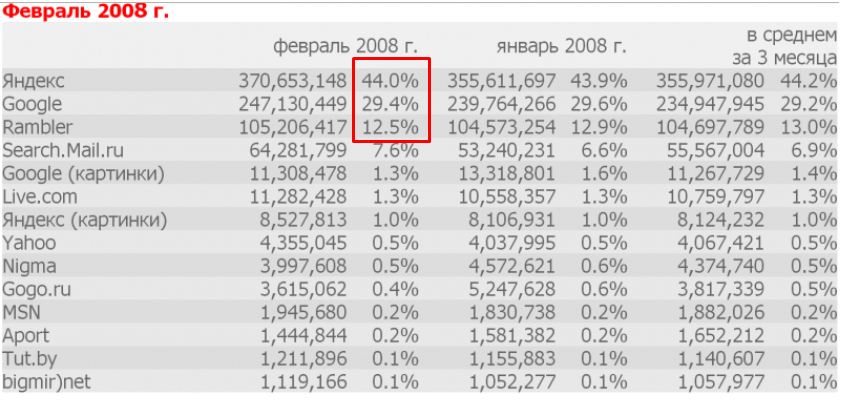
Популярность поисковых систем в январе-феврале 2008
Нужно понимать, что то, что нам известно сейчас, не было известно нам тогдашним. Поисковые машины скрывали свои алгоритмы и никогда прямо не рассказывали, как устроен поиск. Они и сейчас темнят)
1998–1999 — PageRank
Идея PageRank была заложена в Google с самого начала как один из базовых отличительных принципов проекта.В самом первом подробном публичном описании Google как прототипа поисковой системы в 1998 году — в статье «Анатомия крупномасштабной гипертекстовой поисковой системы в Интернете» («The anatomy of a large-scale hypertextual Web search engine»), основатели Google Сергей Брин и Ларри Пейдж пишут, что построенные ими карты ссылок позволяют быстро вычислять PageRank страницы, и что это «отличный способ» приоритизировать результаты обычного keyword-поиска. Так началась эпоха ссылок в поисковой оптимизации, породившая рынок покупки и аренды ссылок и сформировавшая ландшафт интернета на следующие 15 лет.

Основатели Google Ларри Пэйдж (слева) и Сергей Брин (справа)
1998–2003 — принцип «чем больше, тем лучше»
В этот период SEO было «Диким Западом» — золотой порой для манипуляций, когда поисковик был доверчивым, а алгоритмы — линейными. Создавались тысячи пустых сайтов, так называемые фермы, только для того, чтобы сослаться на основной ресурс. Появился массовый спам в гостевых книгах и форумах. Позже появились и расцвели ссылочные биржи.Алгоритм искал точное совпадение фразы, и, если пользователь искал «купить кроссовки недорого», на странице эта фраза должна была встретиться десятки раз. Тексты превращались в нечитаемый набор слов: «Мы предлагаем купить кроссовки недорого, потому что наши кроссовки недорого — это лучшие кроссовки недорого в Москве». Оптимизаторам был известен «идеальный» процент вхождений, например, 3–7% от всего текста. Теперь это звучит смешно, но тогда работало. Чтобы не снизить тошноту от таких текстов, портянки ключевых слов писали белым шрифтом на белом фоне или размещали в блоках размером 1 × 1 пиксель: робот индексировал ключи, а человек их не видел. Сервер настраивали так, чтобы он показывал роботу Google оптимизированную страницу с текстом, а обычному пользователю — красивую картинку или Flash-анимацию без текста, так называемый клоакинг.Выдача была практически одинаковой для всех: не важно, находитесь вы в Екатеринбурге, Москве или Владивостоке — по запросу «Экскаватор» вы видели одни и те же сайты. Достаточно было оптимизировать одну страницу под весь мир.Google обновлял свой индекс примерно раз в месяц. Это событие называли Google Dance («Танцы Google»). Оптимизаторы вносили правки и неделями ждали, когда робот придёт, проиндексирует новые страницы, пересчитает ссылки — и позиции изменятся. Если сайт попадал под фильтр, он исчезал из выдачи минимум на месяц.
Чтобы попасть в топ, не нужно было быть экспертом или писать полезные статьи. Нужно было просто «переспамить» конкурентов ключами и закупить больше ссылок.Всё изменилось в ноябре 2003 года с обновлением Florida, которое разом обнулило эффективность этих методов и положило начало череде обновлений, направленных на борьбу с поисковым спамом.
2003 — Florida
Это было первое по-настоящему масштабное обновление, которое шокировало SEO-сообщество. В России, в силу того, что SEO пребывало здесь в зачаточном состоянии, большого шока не было, но имевшие трафик его потеряли.Google начал активно бороться с методами «чёрного» SEO 90-х годов. Под удар попали:
Многие коммерческие сайты потеряли до 90% трафика за одну ночь. Отрасль поняла, что правила игры поменялись и безнаказанно кошмарить Google спамными текстами уже нельзя.Многие считают, что именно тогда SEO перестало быть игрой в быстрые трюки и перешло к долгосрочному, стратегическому подходу.
2005 — Bourbon
Это обновление было сфокусировано на качестве контента и том, как Google понимает структуру сайта.Google начал пессимизировать сайты, которые копировали чужие тексты или плодили одинаковые страницы внутри себя.Появилось разделение между версиями сайта с www и без него. Google стал определять канонические адреса страниц. Теперь стало важным настраивать 301-е редиректы и следить за уникальностью каждой страницы.
2005 — Personalized Search
В 2005 году Google запустил Personalized Search — и это стало моментом, когда единая для всех выдача начала рассыпаться: если раньше два человека в разных городах по одному и тому же запросу видели идентичный топ-10, то с 2005 года всё изменилось.
Google начал учитывать историю поиска пользователя: если вы часто заходили на определённые сайты или искали специфические темы, поисковик начинал подмешивать эти ресурсы выше в вашей персональной выдаче.Сначала это работало только для тех, кто вошел в аккаунт Google и включил историю.Затем для всех: к 2009 году персонализация стала стандартом (даже без входа в аккаунт, через файлы cookie)
Для SEO-специалистов ситуация обратилась настоящим кошмаром. Понятие «первое место в Google» стало размытым. На компьютере владельца сайта его ресурс мог быть на 1-м месте (потому что он часто на него заходит), а для нового клиента — на 15-м.Появилась острая нужда в инструментах, которые проверяют позиции через «чистые» прокси-серверы без истории поиска.
Стало важным не просто привлечь клик, а сделать так, чтобы пользователь вернулся на сайт. Потому что повторные заходы «закрепляли» сайт в персональном топе конкретного юзера.Personalized Search оказался предвестником эры поведенческих факторов. Google начал анализировать:
Если сайт нравился пользователю, Google «запоминал» его и продвигал именно для этого человека.
Персонализация шла рука об руку с Local Search. Поисковик начал учитывать IP-адрес, чтобы выдавать релевантные результаты — например, пиццерию в вашем городе, а не в соседней области.Запуск персонализации заставил SEO-специалистов слегка сместить фокус с манипуляций с алгоритмом на удержание аудитории. Стало понятно: если контент бесполезен и пользователь сразу уходит, никакие ссылки не удержат сайт в топе его персональной выдачи надолго.
Декабрь 2005 – март 2006 — Big Daddy
В отличие от предыдущих изменений, это было, скорее, обновлением инфраструктуры (баз данных и центров обработки), чем просто сменой формулы ранжирования. Изменилось качество индексации: Google сменил алгоритмы обхода сайтов (краулинга) и стал лучше распознавать технические ошибки.Впервые серьёзно заговорили о «трасте» — доверии к сайту в целом, а не к отдельной странице.Улучшилась обработка перенаправлений (301 и 302), что позволило корректно передавать ссылочный вес при переездах страниц.
В этот период случилось рождение технического SEO как отдельной дисциплины. Сайты с плохой архитектурой и бесконечными URL-параметрами начали выпадать из индекса.
В 2003–2006 SEO из набора «хаков» превратилось в серьёзную работу над качеством контента и техническим здоровьем ресурса.
2007 — Universal Search
Май 2007— это момент, когда Google перестал быть просто списком из 10 синих ссылок и превратился в мультимедийную витрину.
В начале результаты поиска по умолчанию содержали на первой странице 10 ссылок на страницы найденных сайтов. Со времён первого массового браузера Mosaic (1993 год) заголовки ссылок традиционно синие. Поэтому, когда говорят о старом, традиционном, поиске и его «простой» сути, упоминают именно 10 синих ссылок. Это, примерно, как сказать, что раньше солнце было ярче и трава зеленее.
До этого поиск был разделён: приходилось отдельно искать тексты, отдельно картинки и отдельно новости. Universal Search объединил всё это в одну выдачу.
Для SEO это стало рождением вертикального поиска. Раньше все бились за 1-е место в текстовой выдаче. Теперь над первой ссылкой мог оказаться огромный блок с картинками или видео, который забирал на себя 50–70% кликов.
Формула успеха после 2007 года: если по вашему запросу Google показывает видео — делайте видео. Если показывает картинки — делайте качественный визуал. YouTube стал чит-кодом для SEO. Оптимизированное видео могло попасть в топ-3 по высокочастотному запросу гораздо быстрее, чем текстовая статья. Появилось понятие SERP Dominance — стремление занять как можно больше места в выдаче разными типами контента (ссылка + видео + картинка).
Александр Свириденко Руководитель отдела SEO. Руководитель отдела продвижения компании «Сумма Технологий» с 2012 по 2016:
Когда в 2008 году я, ещё студент, начал заниматься SEO-продвижением, Google уже был мировым лидером среди поисковых систем и занимал около 60% мирового рынка поиска. Поисковик отлично работал в англоязычном сегменте, однако в России его популярность была не столь велика. Им пользовались в основном студенты, гуманитарии, «компьютерщики и гики». Пока Google ещё не очень хорошо искал по-русски, многие пользователи придерживались простой логики: русскоязычные сайты искали в Яндексе, а всё остальное — в Google. Но когда Google начал глубже индексировать Рунет, эта необходимость постепенно отпала.огда в 2008 году я, ещё студент, начал заниматься SEO-продвижением, Google уже был мировым лидером ср
SEO-продвижение в Google тогда было достаточно простым и понятным. В первую очередь это наличие на сайте текстовых страниц, грамотная перелинковка между ними в меню и в текстах, а также наращивание PageRank (цитируемости) путем размещения ссылок на нужные страницы с других ресурсов. Интересно, что поисковик вполне неплохо справлялся даже с геозависимыми запросами: добавив город, можно было спокойно найти «такси в Екатеринбурге» или «купить пластиковые окна в Челябинске».
2010 — Caffeine
До этого обновления индекс Google состоял из нескольких уровней, и главный уровень обновлялся каждые 30 дней. Это означало, что свежий контент мог ждать индексации неделями. «Кофеин» добавил бодрости и поисковику, и оптимизаторам: Google перешёл на инкрементальную индексацию. Вместо того, чтобы пересчитывать весь интернет целиком, система начала обновлять индекс маленькими порциями в реальном времени. Как только робот находил новую страницу, она почти мгновенно могла появиться в поиске.Для новостных и событийных запросов свежий контент стал ранжироваться выше авторитетного, но старого.Google прямо заявил, что скорость загрузки сайта теперь является официальным фактором ранжирования. Медленные сайты начали проигрывать, так как роботам было сложнее их быстро индексировать.
В SEO появилась стратегия регулярного обновления старых статей. Если вы обновили дату и добавили пару абзацев в старый гайд, поисковик видел это сразу и мог поднять страницу в выдаче. Благодаря скорости индексации ссылки из Twitter и других соцсетей стали влиять на поиск почти мгновенно, помогая новому контенту «взлетать». Caffeine убил «эпоху ожидания». От SEO-специалистов потребовалось работать в режиме 24/7. Стало важно не просто оптимизировать сайт один раз, а постоянно генерировать контент и следить за техническим совершенством (скоростью), чтобы поисковый робот хотел заходить на сайт как можно чаще.
2011 — Panda
Panda — это «ядерный взрыв» в мире SEO, который навсегда изменил отношение к текстам. Если до этого Google можно было обмануть количеством ключевых слов, то Panda начала оценивать не только оригинальность, но и качество и полезность контента. Это был сложный фильтр, который накладывался на основной алгоритм. Его целью стали сайты с «мусорным» контентом. Пострадали сайты, которые плодили тысячи коротких, низкокачественных статей обо всём на свете ради рекламы и сайты, которые просто пересказывали чужие статьи без добавления ценности. Кроме того, стал учитываться высокий показатель отказов: если пользователи массово уходили с сайта через секунду, Panda считала такой сайт бесполезным.
Обновление вызвало панику, так как под удар попали даже крупные игроки. SEO-специалисты перестали заказывать дешевые тексты по 50 рублей за 1000 знаков. Стало важно писать для людей. Появилась практика удаления страниц: оптимизаторы начали массово удалять или закрывать от индексации «мусорные» страницы, чтобы спасти авторитет всего домена. Google начал отслеживать, читают ли люди статью или закрывают её сразу: удержание внимания стало негласным фактором ранжирования.И почти сразу после обновления Google выпустил отдельное руководство о том, как понимает высокое качество сайта, в виде списка вопросов к сайту — то есть перевёл разговор из «угадай сигнал» в «сделай так, чтобы тебе доверяли как источнику».
Panda превратила SEO из технической настройки в контент-маркетинг. Именно после 2011 года родилась знаменитая фраза «Content is King» («Контент — это король»). Оптимизаторы стали больше походить на редакторов и издателей, чем на программистов.Качество стало важнее количества — и интернет стал лучше для всех.
2012 — Penguin
Penguin (апрель 2012) — это второй удар после Panda, который окончательно разрушил старые методы продвижения. Если Panda боролась с плохими текстами, то Penguin (Пингвин) пришел за теми, кто манипулировал ссылками.До 2012 года покупка ссылок на «биржах» (в СНГ это была эра Sape) была самым простым и эффективным способом попасть в топ. Вы просто покупали 1000 дешёвых ссылок с любым текстом — и сайт взлетал. «Рулили» ссылочные бюджеты, многократно превышающие расходы на контекст. Ну разве это могло понравиться поисковым машинам? И Google запустил алгоритм для борьбы со ссылочным спамом. Он начал наказывать сайты за «неестественный» ссылочный профиль. И дал определение ссылочного спама: «Ссылочный спам – это создание ссылок на сайт или с сайта, главным образом, с целью манипулирования системами ранжирования».
Под удар попали:
Началась «великая ссылочная депрессия», и эпоха ссылок стала клониться к закату. Penguin сделал манипуляцию ссылками опасной. А аудит ссылочного профиля стал обязательной гигиенической процедурой.Главным правило теперь звучало следующим образом: «Ссылка должна выглядеть так, будто её поставили добровольно за хороший контент».С 2016 года (Penguin 4.0) алгоритм стал частью основного ядра Google и начал работать в реальном времени, не просто наказывая сайты, а игнорируя плохие ссылки.
2013 — Hummingbird
Запущенный в сентябре 2013 года к 15-летию Google Hummingbird (Колибри) стал самым радикальным обновлением поискового движка со времен Caffeine. Если «Панда» и «Пингвин» были фильтрами-надстройками, то «Колибри» — это полная замена «мозга» поиска.До 2013 года Google разбивал запрос на отдельные слова, и чтобы получить адекватный ответ, нужно было писать «ремонт стиральная машина цена». «Колибри» научился понимать контекст и стало можно писать «сколько стоит починить стиралку».Поисковик стал выдавать страницы, где даже может не быть точного вхождения ваших слов, но есть ответ на ваш вопрос.Обновление подготовило почву для Siri и Google Assistant, так как люди говорят предложениями, а не набором тегов.
Для SEO это был очередной важный культурный перелом: случилось рождение семантического поиска. Исчезла необходимость писать фразы вроде «ремонт холодильник недорого москва». Стало можно и нужно писать нормальным человеческим языком: «мы качественно чиним холодильники в Москве по доступным ценам».Родился LSI-копирайтинг (Latent Semantic Indexing). Стало важным использовать тематические слова (LSI), которые окружают основную тему.Если вы пишете о кофе, Google ожидает увидеть слова «зёрна», «обжарка», «арабика», «бариста». Это подтверждает экспертность статьи.SEO-специалисты начали задаваться вопросом: «Что на самом деле хочет найти человек?» Контент стал создаваться под интент: запрос «как выбрать ноутбук» предполагает статью-гайд, запрос «купить ноутбук» — страницу каталога. Если тип страницы не совпадает с интентом, в топ попасть невозможно.Раньше под каждый ключ делали отдельную страницу. После «Колибри» стало эффективнее создавать одну глубокую, экспертную статью, которая отвечает сразу на 50–100 смежных микро-запросов.В целом для SEO «Колибри» обозначил начало перехода от манипуляции словами к работе со смыслами. Главным правилом стало: «Оптимизируйте не под запросы, а под ответы на вопросы пользователей».
2014 — HTTPS as a ranking signal
Google официально объявил HTTPS фактором ранжирования. Сайты, использующие безопасный протокол (SSL-сертификат), получили небольшое преимущество в позициях по сравнению с незащищёнными HTTP-версиями.
Для SEO переход на HTTPS стал обязательным техническим пунктом чек-листа. Сначала это был слабый сигнал (влиял менее чем на 1% запросов), но со временем он стал базовым гигиеническим требованием.Позже, в 2017–2018 годах, браузер Chrome начал помечать все HTTP-сайты как «Незащищенные» в адресной строке, что ударило по поведенческим факторам даже сильнее, чем прямой алгоритм ранжирования.
2015 — Mobile-friendly update
Этот апдейт, запущенный 21 апреля 2015 года, вошел в историю SEO под устрашающим названием «Mobilegeddon» (Мобайлгеддон). Google официально объявил: если ваш сайт плохо отображается на смартфонах, он будет падать в мобильной выдаче.В 2015 году количество поисковых запросов с мобильных устройств впервые превысило объём запросов с десктопов. Google отреагировал радикально:
Обновление Mobile-friendly update разделило мир SEO на «до» и «после»:
Mobilegeddon не уничтожил интернет, как предсказывали заголовки. Но он сделал адаптивность обязательным стандартом.
2015 — RankBrain
RankBrain— это третья по значимости составляющая алгоритма Google (после контента и ссылок) и первый по-настоящему масштабный шаг в сторону искусственного интеллекта. Если Hummingbird (Колибри) научил Google понимать связи между словами, то RankBrain научил его догадываться о смысле запросов, которые он раньше никогда не видел, а таковых на момент запуска алгоритма было ежедневно 15% от всех.RankBrain превращает слова в математические векторы, и если видит незнакомое слово или фразу, то ищет векторы похожих слов и выдает результат, который, скорее всего, подойдет.Кроме того, алгоритм анализирует, на какие результаты кликают пользователи по сложным запросам. Если люди массово переходят на второй результат и остаются там, RankBrain понимает: «Ага, этот сайт лучше отвечает на этот странный вопрос», и поднимает его выше.
Что это значило для SEO:
SEO-специалистам пришлось признать: лучший способ понравиться Google — это дать ему понять, под какую потребность пользователя вы пишете текст.
2018 — Medic Update
Это переломный момент, когда Google официально заявил: «Мы не просто ищем информацию, мы фильтруем её на предмет безопасности».Хотя обновление затронуло все ниши, основной удар пришёлся на сайты медицинской, фармацевтической и оздоровительной тематик (отсюда и название «Medic»).Google ввёл и жёстко применил классификацию сайтов YMYL (Your Money or Your Life) — «Ваши деньги или ваша жизнь». Это ресурсы, контент которых может напрямую повлиять на здоровье, финансовое благополучие, безопасность или счастье человека.
К YMYL относятся:
Чтобы ранжироваться в этих нишах, сайт должен соответствовать трём критериям, которые позже стали «золотым стандартом» SEO:
Позже, в 2022 году, к формуле E-A-T добавили еще одну букву E (Experience — личный опыт), превратив её в E-E-A-T.
Для SEO это стало началом конца анонимного контента. SEO-специалисты массово бросились создавать страницы экспертов с биографиями, ссылками на дипломы, соцсети и публикации в СМИ. Статьи «Как лечить простуду подорожником», написанные копирайтером-фрилансером без медицинского образования, мгновенно вылетели из топа.Стали важны ссылки не просто с «жирных» сайтов, а с профильных ресурсов (.edu, .gov, авторитетные клиники и институты). Google начал анализировать отзывы о компаниях на сторонних площадках (Trustpilot, Google Maps, для России 2ГИС).Medic Update убил возможность продвигать «чувствительные» темы простыми SEO-текстами. Для бизнеса это означало, что теперь недостаточно просто сделать сайт — нужно доказать, что вы эксперт.
2019 — BERT
Google объявил внедрение в ранжирование методики предварительного обучения NLP под названием Bidirectional Encoder Representations from Transformers (BERT) для понимания смысла запроса. Если RankBrain научил Google сопоставлять концепции, то BERT научил его читать предложения так же, как это делает человек. До этого алгоритмы читали текст слева направо (или справа налево), анализируя слова по очереди. BERT стал двунаправленным: он анализирует всё предложение целиком, учитывая слова до и после каждого конкретного слова.
Интересно, что в описание продукта BERT сравнивается с Open AI. Ниже представлена визуализация архитектуры нейронной сети BERT в сравнении с предыдущими передовыми методами контекстного предварительного обучения.
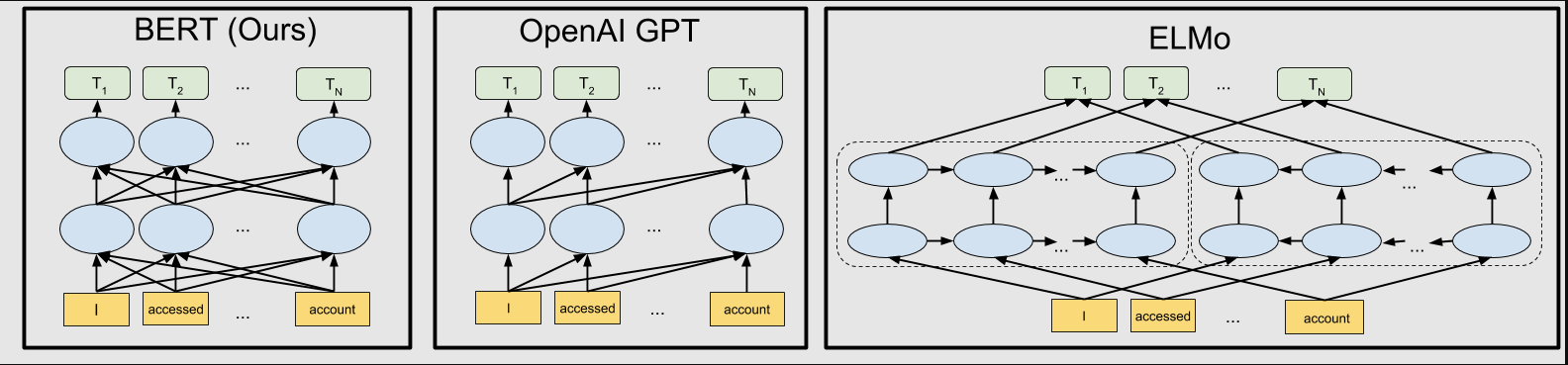
BERT обладает глубокой двунаправленностью, OpenAI GPT — однонаправленностью, а ELMo — поверхностной двунаправленностью.
С этого момента оптимизация ещё сильнее сместилась к смыслу фраз, контексту и точности формулировок, а не к механике ключей. Google наконец-то понял разницу в предлогах «для», «в», «из», «к». Раньше он часто их игнорировал как «стоп-слова». Алгоритм научился понимать значение слова, исходя из его окружения (например, слово «кран» в контексте стройки или кухни).
BERT лучше всего работает на сложных, длинных, разговорных запросах (Long-tail). Сайты, которые давали четкие ответы на конкретные вопросы (FAQ, инструкции), получили резкий приток трафика. Если статья глубоко раскрывает тему со всеми нюансами, BERT это «считает» через семантические связи. Поверхностный рерайт стал ранжироваться заметно хуже.
Для SEO-специалиста это означало, что нужно перестать думать о плотности ключевых слов и начать думать о логике и структуре повествования. По сути, BERT — это предвестник эры ИИ, который оценивает не слова, а качество передачи информации.
2021 — MUM
MUM (Multitask Unified Model) был представлен как «старший брат» BERT, который в 1000 раз мощнее его. Если BERT научился понимать структуру предложения, то MUM научился сопоставлять знания из разных форматов и языков, чтобы отвечать на сложные вопросы. MUM подан как следующий AI-шаг к поиску, который лучше справляется со сложными задачами и многошаговыми вопросами.
В чём это проявилось для пользователя:
Для SEO-специалистов MUM стал сигналом, что контент должен быть не просто «оптимизированным», а структурированным и мультимедийным, чтобы ИИ мог легко «вытащить» из него факты для своих ответов.
2023 — ссылки всё: официальное окончание эпохи ссылок
Представитель Google Гэри Иллиес публично сказал, что люди переоценивают важность ссылок, поскольку они уже давно не входят в тройку главных факторов ранжирования. Для SEO это не означает, что ссылки больше не работают, но означает, что они перестали быть тем самым главным рычагом, каким были во времена ссылочных бирж.
2024 — AI Overviews (обзоры ИИ)
Это крупнейшее обновление интерфейса Google, запущенное в мае 2024 года. Оно окончательно закрепило переход Google от модели «поисковой системы» (список ссылок) к модели «ответного движка» (прямые ответы ИИ).Суть AI Overviews: Google использует генеративный ИИ для создания краткого резюме в верхней части выдачи, которое синтезирует информацию из нескольких источников.В 99% случаев ИИ берет данные из сайтов, входящих в топ-10 органической выдачи.
Для SEO это начало эпохи «Zero-Click». Появление ИИ-ответов создало серьёзные вызовы для SEO-специалистов, так как пользователи получают информацию, не переходя на ресурс:
Наиболее пострадали информационные ниши (здоровье, наука, лайфхаки, рецепты), где ИИ может дать исчерпывающий ответ. Транзакционные и брендовые запросы затронуты меньше, так как для покупки пользователю всё равно нужно перейти на сайт.
В SEO-практике это начало борьбы за попадание в ответы. SEO-специалисты переходят к концепции GEO (Generative Engine Optimization) — оптимизации для генеративных движков:
Это было начало GEO.
2025 — AI Mode
В новости Google AI Mode описан как следующий уровень поверх Overviews. Но на самом деле это переломный момент, когда Google перестал быть поисковиком с ИИ-вставками и превратился в полноценного ИИ-агента.
В 2025 году компания начала массовое внедрение режима, который кардинально меняет интерфейс и логику работы с информацией. Ссылки в результатах поиска пока есть, но появился режим диалога, в котором поиск перестаёт выдавать список сайтов. Вместо этого он ведёт себя как чат:
Для SEO-специалистов 2025 год стал годом окончательного ухода от ключевых слов к работе над «цитируемостью» в нейросетях.В мае 2025 Google публикует инструкцию «Как оптимизировать контент для функций Google Поиска, использующих технологии искусственного интеллекта».
Коротко путь эволюции Google от поисковой системы к генерации ответов выглядит так:
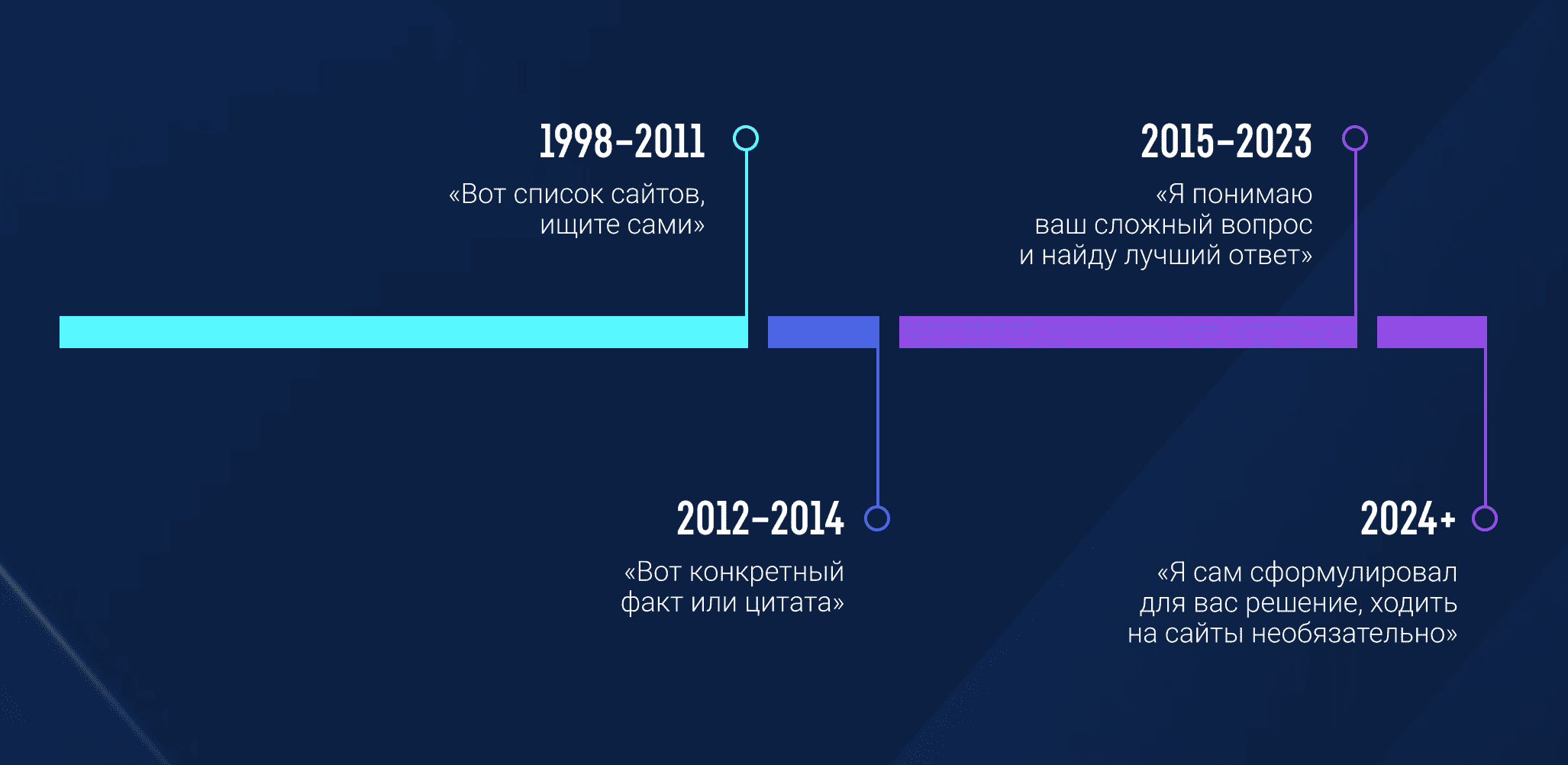
Google больше не ищет сайты, он даёт ответы. Чтобы дальше продвигаться с помощью Google, нужно перестать оптимизировать тексты для роботов и начать строить бренд, который люди и искусственный интеллект будут узнавать и рекомендовать по умолчанию.

Наша система сама подберет вам исполнителей на услуги, связанные с разработкой сайта или приложения, поисковой оптимизацией, контекстной рекламой, маркетингом, SMM и PR.
Заполнить заявку
13590 тендеров
проведено за восемь лет работы нашего сайта.
Создатели Яндекса Илья Сегалович (слева) и Аркадий Волож (справа). «Ведомости»
1997 — Яndex-Web
Яндекс выходит в публичный интернет как поиск, который с самого начала «заточен» под русский язык. В отличие от раннего Google, который долгое время искал слова по точному совпадению символов, Яндекс с момента своего основания строился на базе морфологического анализатора Mystem (разработка Ильи Сегаловича и Виталия Титова). Это позволяло системе понимать, что разные формы одного слова — это одно и то же понятие. Если пользователь вводил запрос в именительном падеже, Яндекс находил страницы, где это же слово стояло в любом другом падеже или числе.Например.
Запрос: «окно». Результаты: страницы со словами «окна», «окном», «окон», «окнами».Запрос: «идти». Результаты: «шёл», «шла», «шли».
Ранние алгоритмы Яндекса пытались различать слова, которые пишутся одинаково, но имеют разное значение в зависимости от части речи. Например, слово «стали». Яндекс анализировал соседние слова, чтобы понять, идет речь о существительном (виды стали) или о глаголе (они стали делать).
Mystem умел строить гипотезы для слов, которых не было в его словаре (например, неологизмов или сленга), анализируя их флексии (окончания). Если поисковик видел новое слово «глюкавить», он понимал, что это глагол, и мог найти формы «глюкавил» или «глюкавят», даже если само слово «глюкавить» не было занесено в базу. Для тех случаев, когда автоматика мешала, Яндекс ввел операторы, которые позволяют «отключить» морфологию: если поставить перед словом восклицательный знак, например, «!салона», Яндекс будет искать именно эту форму, игнорируя «салон», «салону» и т.д., а если заключить слово или фразу в кавычки, будет искаться точное вхождение слова или фразы — без словоформ. Операторы поддерживаются и сейчас — вот свежая статья Яндекса про операторы.
1999 — тИЦ
Яндекс вводит тематический индекс цитирования как публичный показатель «ссылочного авторитета». В отличие от PageRank у Google, тИЦ рассчитывался не для каждой страницы в интернете, а для каждого сайта. Это был тот самый понятный рынку сигнал, который удобно показывать клиенту на графике и страшно удобно пытаться накрутить, поэтому со временем тИЦ стал жить собственной жизнью рядом с реальным ранжированием.
2000 — компания «Yandex» и портал yandex.ru
Яндекс оформляется как отдельная компания и параллельно строит портал-экосистему вокруг поиска, добавляя сервисы и так называемый параллельный поиск по специализированным источникам (Новости, Товары, Каталог, Открытки)Для SEO это был ранний намёк на то, что поиск в Яндексе — не просто «10 ссылок», а смесь вертикалей и сервисов, где часть ответа может приходить не с сайтов, а из собственных баз.
2001 — Яндекс Директ
Рождается контекстная реклама, и у бизнеса впервые появляется массовый способ покупать спрос «здесь и сейчас», не дожидаясь, пока органика созреет.Для SEO это важная развилка: органика начинает конкурировать за внимание и бюджет с платным блоком прямо на странице результатов. С ностальгией вспоминаются всего три объявления перед органикой в блоке «Спецразмещение»: на момент написания статьи их, вроде бы, пять. «Вроде бы» — потому что их сложно посчитать: они не выделены как реклама.
2009 — «Арзамас». Геозависимость
До «Арзамаса» выдача была практически одинаковой для всех пользователей. С апреля 2009 поисковик начал делить запросы на геозависимые (например, «заказ такси», «доставка пиццы») и геонезависимые («рецепт борща», «как выбрать ноутбук»): для пользователей из разных городов по одним и тем же коммерческим запросам стали показываться разные сайты — приоритет получили местные ресурсы.
Алгоритм радикально изменил правила продвижения, породив направление «региональное SEO». Московские сайты перестали занимать топ в регионах по коммерческим запросам, что открыло дорогу местному бизнесу. Для оптимизаторов критически важным стало указание региона в Яндекс Вебмастере и наличие физического адреса и местного телефона на странице «Контакты».
Тем предприятиям, чей бизнес распространялся на множество регионов, Яндекс советовал доказывать наличие филиалов в городах, и присваивал регионы по наличию филиалов.Большой след «региональность» оставила в структуре сайтов. Крупным компаниям пришлось создавать поддомены или отдельные папки для каждого города (например, spb.site.ru, ekb.site.ru), чтобы ранжироваться по всей стране. Стало важно получать ссылки с ресурсов того же региона, что и продвигаемый сайт.
«Арзамас» фактически разделил интернет-маркетинг на локальный и глобальный, заставив владельцев сайтов подтверждать свою географическую принадлежность для работы с целевой аудиторией.
2009 — MatrixNet
В 2009 году Яндекс внедрил MatrixNet (Матрикснет) — прорывную технологию машинного обучения, основанную на методе градиентного бустинга. Это событие фундаментально изменило принципы работы поиска и подходы к SEO.До MatrixNet формула ранжирования была единой и сравнительно простой. MatrixNet позволила строить крайне сложные формулы, учитывающие тысячи факторов и их комбинаций. Матрикснет обучался на оценках живых людей (асессоров), которые помечали сайты как «релевантные» или «нерелевантные» запросу. Машина находила закономерности в их выборе и применяла их ко всему интернету.
С точки зрения оптимизации, это начало конца эпохи простых манипуляций. Стало невозможно продвинуть сайт, просто «накачав» его ключевыми словами или купив ссылки. Система видела сотни других сигналов, которые противоречили искусственной накрутке.Яндекс начал оценивать «экосистему» домена, а не только конкретную страницу. Появились понятия «авторитетность» и «доверие».SEO-специалистам стало труднее предсказывать результат, так как «золотого правила» (например, «нужно 5 вхождений ключа») больше не существовало: требования менялись от запроса к запросу.
MatrixNet оставался базой поиска Яндекса до 2017 года, когда его сменил более совершенный алгоритм CatBoost.
2010 — «Краснодар» и технология «Спектр»
Суть этой технологии заключалась в решении проблемы неоднозначных запросов, которые составляли на тот момент около 20% всех обращений пользователей.Когда пользователь вводит запрос, смысл которого может быть разным (например, «марс», «Наполеон», «кран», «ключ»), система не пытается угадать одно значение, а подмешивает в выдачу результаты для разных потребностей («спектр» ответов).
Для SEO это момент, когда появились понятия «интент запроса» и LSI-копирайтинг. Стало важно окружать ключевое слово тематическими словами. Если пишешь про «отель», должны быть слова «бронирование», «номер», «завтрак», чтобы робот верно определил категорию. SEO-специалисты начали создавать на коммерческих сайтах разделы с обзорами, видео и FAQ, чтобы попасть в выдачу по «информационным» запросам.«Спектр» сделал выдачу «разношёрстной». SEO-шникам пришлось признать: теперь они соревнуются не только с прямыми конкурентами, но и с Википедией, YouTube и агрегаторами отзывов в рамках одной страницы выдачи. Если раньше по запросу «пластиковые окна» можно было забить весь топ коммерческими сайтами, то после «Спектра» Яндекс начал отдавать 2–3 места информационным статьям, отзывам или картам. Конкуренция за оставшиеся «коммерческие» строчки резко выросла.
2011 — «Рейкьявик»
Это был первый серьёзный шаг Яндекса к персонализации поиска. Главная идея: разным людям нужны разные ответы на один и тот же запрос. Учитывались языковые предпочтения, история поиска и поведение на поиске.
«Рейкьявик» принёс в мир SEO понятие «персональная выдача», которое сильно усложнило жизнь аналитикам. Стало невозможно увидеть «объективный» ТОП: у владельца сайта он был один, у SEO-специалиста — другой, а у потенциального клиента — третий. Появилась необходимость использовать инструменты проверки позиций через «инкогнито» или специальные XML-сервисы без учёта персонализации. Алгоритм анализировал историю поисковых запросов и кликов. Кликабельность сниппета стала критичной. Если пользователь раз за разом кликал на ваш сайт в выдаче, для него этот сайт закреплялся на верхних позициях, даже если общие алгоритмы ставили его ниже. Стало важно, чтобы пользователь не просто зашёл на сайт, но и перестал искать дальше: если после вашего сайта юзер возвращался в поиск, это был сигнал системе, что ответ не найден.«Рейкьявик» начал разрушение представления о первой странице Яндекса как единой страницы для всех, а окончательную точку поставил «Калининград» в 2012 году.
Декабрь 2012 — «Калининград»
В блоге для вебмастеров Яндекс фиксирует запуск платформы «Калининград», которая учитывает личные интересы и предпочтения в подсказках и ответах.Для специалистов по продвижению «Калининград» стал «точкой невозврата», окончательно лишив их возможности видеть стабильный, одинаковый для всех топ-10.
2013 — «Острова»
Основная идея заключалась в создании интерактивных сниппетов («островов»). Вместо того чтобы просто кликать на ссылку и переходить на сайт, пользователь мог взаимодействовать с функционалом сайта прямо в поиске. Владельцы ресурсов должны были передавать Яндексу структурированные данные через специальные XML-фиды, чтобы сформировать такой «остров».Проект «Острова» в его первоначальном виде (с массовыми формами сторонних сайтов) не взлетел на 100% и позже трансформировался в современные обогащённые ответы.Однако именно он заложил фундамент текущей экосистемы Яндекса, где поисковик старается дать ответ, не отпуская пользователя на другие ресурсы.
Для SEO это был не всеми понятый ранний предвестник будущей концепции «источник внутри ответа», когда сайт нужен, но поисковик старается дать ответ без перехода на сайт.
Александр Свириденко
Илья Сегалович тогда представлял это как будущее поиска: интерактивные блоки прямо в выдаче, где можно записаться к врачу, забронировать билет или купить товар, не заходя на сайт. Проект, увы, закрыли, но идея расширенных сниппетов и микровзаимодействий с пользователем проросла в том, что мы имеем сейчас (представления на поиске): карточки товаров, недвижимость, вакансии, врачи и другие услуги прямо в поиске.
2013 — АГС-40
6 ноября 2013 года Яндекс выпустил алгоритм АГС-40 — масштабное обновление своего главного антиспам-фильтра. АГС-40 был карательным инструментом, направленным на очистку выдачи от «мусорных» ресурсов. Основная цель — сайты, созданные не для людей, а исключительно для заработка на продаже ссылок. Это обновление привело к исключению из индекса сотен тысяч страниц.
Алгоритм нанес мощный удар по бизнесу вебмастеров, которые делали сайты-фермы для автоматической продажи ссылок (через Sape и аналоги). Ссылки с сайтов под АГС перестали передавать вес.Запуск АГС-40 фактически уничтожил рынок низкокачественного ссылочного спама и заставил оптимизаторов фокусироваться на создании ресурсов, представляющих реальную ценность для пользователей. Сайты, которые продвигались не тупой покупкой ссылок, не пострадали. Ну, почти.
2013 — «Об учёте ссылок в ранжировании»
6 декабря на конференции IBC Russia Александр Садовский (тогдашний руководитель поисковых сервисов Яндекса) сделал сенсационное заявление: Яндекс перестаёт учитывать ссылки в ранжировании по коммерческим запросам.
2014 — «Смерть» ссылок для коммерческих запросов
Событие 12 марта 2014 года стало практическим воплощением декабрьского анонса, сделанного Александром Садовским. В этот день Яндекс официально отключил ссылочное ранжирование для коммерческих запросов в Москве и Московской области. Ссылки с других ресурсов перестали передавать «авторитетность» сайту-акцептору. Позиции в выдаче стали пересчитываться на основе других групп факторов.
Александр Свириденко
В 2014 году мы увидели создание опасной асимметрии: атаковать чужой сайт становится дешево и анонимно, а защищаться — дорого и долго. Конкурент может завалить вас спам-ссылками, заказать массу негативных отзывов или имитировать ботный трафик, чтобы спровоцировать фильтр. А добросовестный владелец бизнеса оказывается заложником ситуации: ему нужно доказывать свою честность, тратить ресурсы на «разбор полётов» в техподдержке, в то время как агрессор остаётся в тени.Поисковая система не может быть только карательным органом. Если вы внедряете механизмы санкций, вы обязаны предоставить и эффективные инструменты защиты. Были нужны (нужны и сейчас) прозрачная система верификации жалоб, защита от накрутки отзывов и быстрые каналы связи для жертв негативного SEO.
Для SEO эпоха ссылок в Яндексе закончилась и начался бум коммерческих факторов. Именно весна 2014 года закрепила в SEO обязательный чек-лист: цены, кнопка «Купить», условия доставки, онлайн-консультант, корректные контакты. Без этих элементов сайт мгновенно вылетал из ТОПа, так как ссылочная «броня» больше не работала.Многие оптимизаторы заметили, что выдача стала менее динамичной. Без ссылок сайтам стало сложнее быстро ворваться в ТОП, а старым лидерам — проще удерживать позиции за счёт накопленных поведенческих данных.Стратегия «купи 100 ссылок и жди» окончательно сменилась стратегией комплексного развития интернет-маркетинга.
2015 — «Минусинск»
Эксперимент 2014 года показал, что поиск может работать без ссылок, но оптимизаторы продолжали их покупать «по привычке». Это привело Яндекс к решению не просто игнорировать ссылки, а начать за них наказывать. Сайт, уличённый в массовой закупке ссылок, не просто терял «ссылочный вес», а принудительно понижался в поисковой выдаче на 20 или более позиций (в среднем — за пределы топ-20).
Теперь «дошло» уже до всех, и в мае-июне 2015 года оптимизаторы начали массово вычищать ссылочные профили. Это привело к временному хаосу в выдаче и падению доходов ссылочных бирж. Выход из-под «Минусинска» занимал от нескольких месяцев до полугода после полного снятия платных ссылок, что делало фильтр одним из самых страшных кошмаров для бизнеса.«Минусинск» стал финальным аккордом в многолетней борьбе Яндекса со ссылочным спамом. С этого момента ссылки перестали быть главным инструментом продвижения, уступив место поведенческим факторам и качеству продукта.
2016 — «Палех»
«Палех» (запущен 2 ноября 2016 года) — это исторический момент, когда в поиск Яндекса впервые официально пришли нейронные сети. До «Палеха» поиск работал со словами. Если вы искали «фильм про человека, который выращивал картошку на другой планете», а в тексте страницы не было именно этих слов (но было слово «марсианин»), Яндекс мог его не найти. Теперь нейросеть научилась переводить поисковый запрос и заголовок страницы в числа (векторы) и сравнивать их по смыслу, а не по написанию.Алгоритм был нацелен на редкие, уникальные запросы — тот самый «длинный хвост», который пользователи формулируют своими словами, а не стандартными терминами.
Для SEO это начало LSI-копирайтинга: стало важным использовать синонимы и тематически связанные слова (LSI), так как поиск стал понимать контекст страницы. Тексты, перенасыщенные ключевыми словами в ущерб смыслу, стали ранжироваться хуже, так как алгоритм ищет наиболее точный ответ, а не наибольшее количество совпадений слов.На этапе «Палеха» нейросеть анализировала преимущественно заголовки, поэтому их релевантность смыслу страницы стала критической.
2017 — «Королёв»
«Королёв» продолжает линию «Палеха», но делает это «взрослее»: нейросеть сопоставляет смысл запроса и веб-страницы, и поиск лучше понимает, что именно нужно пользователю.
Для SEO это означает, что «правильные» слова перестают быть гарантией: важнее становятся целостная тема и реальная полезность страницы. Начался закат эпохи текстов для роботов. Прямые вхождения ключевиков в стиле «купить пластиковые окна недорого Екатеринбург» стали не просто бесполезны, но и вредны. «Королёв» заставил оптимизаторов писать статьи для людей, а не для поисковых алгоритмов. В 2020 году эту логику развил алгоритм YATI, который начал понимать контекст еще глубже.
2017 — «Баден-Баден»
Параллельно Яндекс усиливает борьбу с имитацией полезности и вводит алгоритм, который находит переоптимизированные, неестественные тексты. Если «Палех» и «Королёв» помогали поиску лучше понимать смысл, то «Баден-Баден» был создан, чтобы наказывать за плохие тексты.Применялось два уровня санкций: запросный (хостовый) давал снижение позиций конкретных страниц, где найден переспам, а общий (фатальный) понижал в выдаче на 20 и более позиций весь сайт, если переоптимизация носила массовый характер.Как и в случае со ссылками, избыточные точные вхождения сначала перестали влиять положительно, а затем стали влиять отрицательно: если «Королёв» дал возможность ранжироваться без точных ключей, то «Баден-Баден» сделал наличие точных и частых ключей опасным для сайта.
«Баден-Баден» совершил революцию в качестве контента, фактически убив классический SEO-копирайтинг. Стали исчезать огромные бессмысленные блоки текста внизу страниц категорий интернет-магазинов, которые писались только ради ключей. SEO-специалисты перешли от подсчета вхождений слов к работе над читаемостью. Теперь текст должен быть полезным, структурированным и написанным для людей.В 2017–2018 годах основной задачей SEO было удаление или полное переписывание старых заспамленных текстов, чтобы вывести сайты из-под фильтра. Главным фактором стала не плотность ключевых слов, а поведенческие метрики (как долго пользователь читает текст и находит ли он ответ).
2018 — ИКС
ИКС (индекс качества сайта) пришел на смену устаревшему тематическому индексу цитирования (тИЦ) в августе 2018 года. Если тИЦ считал только ссылки, то ИКС стал оценивать сайт комплексно.ИКС — это показатель того, насколько полезен ваш сайт для пользователей с точки зрения Яндекса. При расчете ИКС учитываются размер аудитории, уровень доверия к ресурсу, поведенческие факторы и данные из других сервисов Яндекса — карты, справочник и т.д. Значение ИКС открыто для всех — его можно проверить для любого сайта в Яндекс Вебмастере.
ИКС для SEO — это окончательная смена парадигмы: официальное заявление Яндекса о том, что ссылки больше не являются главным мерилом авторитетности. И новая «пузомерка» для продвиженцев. ИКС стал удобным инструментом для быстрого анализа «силы» конкурентов в нише: чем выше их индекс, тем качественнее (в глазах поиска) должны быть ваши сервис и контент, чтобы их обойти.ИКС окончательно превратил SEO из технической манипуляции алгоритмами в работу над качеством и востребованностью продукта.
2018 — «Андромеда»
«Андромеда» — это масштабное обновление поиска Яндекса, представленное в ноябре 2018 года. Если предыдущие алгоритмы — «Королёв», «Палех» — учили поиск понимать текст, то «Андромеда» сосредоточилась на том, чтобы давать ответ максимально быстро и в разных форматах. Прямо в выдаче появились расширенные блоки с информацией (рецепты, определения, курсы валют), чтобы пользователю не нужно было кликать на сайт.У сайтов в выдаче появились иконки: «Выбор пользователей» (высокий трафик и лояльность), «Популярный сайт» и «Официальный дилер/ресурс». Это повысило доверие к качественным площадкам. В выдачу стали агрессивно подмешиваться Яндекс Кью, Яндекс Услуги, Карты, Видео и Дзен.
«Андромеда» серьезно изменила стратегию работы с трафиком, превратила выдачу в «винегрет» из разных типов контента, заставив SEO-специалистов работать не только над позициями сайта, но и над его репутацией и присутствием во всей экосистеме Яндекса.И это было вторым звонком после «Островов», предупреждавшем о потерях трафика из-за ответов на выдаче.
2019 — «Вега»
«Вега» — масштабное обновление поиска Яндекса, представленное в декабре 2019 года. Оно объединило в себе более 1500 улучшений, направленных на гиперлокальность и экспертность ответов.Основная идея «Веги» — переход от простого поиска к интеллектуальному подбору экспертного контента с учетом контекста пользователя. Поиск научился понимать запросы на уровне микрорайонов и даже отдельных домов.К обучению алгоритмов привлекли специалистов в узких областях (врачей, юристов, учёных), чтобы поисковик лучше ранжировал именно профессиональный контент, а не просто популярный.Интеграция Яндекс Кью стала еще плотнее: ответы реальных людей начали появляться прямо в результатах поиска.
Обновление «Вега» заставило SEO-специалистов работать над локальным присутствием и авторитетностью. Регистрация в Яндекс Бизнесе и Картах стала обязательной. Теперь для ранжирования важно указывать точные адреса, зоны доставки и филиалы до уровня районов города.По аналогии с Google (E-A-T — Экспертность, Авторитетность, Доверие), Яндекс стал жёстче оценивать авторство: статьи от «анонимов» стали проигрывать текстам, подписанным реальными экспертами с подтверждённым профилем.
«Вега» сделала поиск ближе к дому и умнее в деталях, заставив оптимизаторов подтверждать экспертность продвигаемого бизнеса и бороться за локальный трафик. В 2020 году логика обучения на экспертных оценках легла в основу алгоритма YATI.
2020 — YATI
Как писал Яндекс, YATI — это самое масштабное обновление за последние 10 лет. Расшифровывается аббревиатура YATI как Yet Another Transformer with Improvements — «ещё один трансформер с улучшениями». Обновление основано на архитектуре нейросетей-трансформеров (аналог BERT от Google).Если раньше алгоритмы искали совпадения слов или векторов заголовков, то YATI научился читать и понимать текст как человек, учитывая контекст и порядок слов.Нейросеть анализирует не просто наличие слов, а связи между ними. Она понимает разницу в запросах «билет из Москвы в Екатеринбург» и «билет из Екатеринбурга в Москву».Алгоритм обучали асессоры-эксперты, которые помечали наиболее глубокие и качественные ответы. YATI перенял их логику оценки «полезности». Теперь документ может занять первое место, даже если в нём нет ни одного слова из поискового запроса, но его смысл идеально совпадает с интентом (намерением) пользователя.
YATI окончательно перевел SEO из технической плоскости в плоскость качества контента.Сервисы, считающие количество вхождений ключевых слов (LSI, плотность), потеряли смысл. Важнее стали полнота раскрытия темы и логика изложения. Статьи «ни о чём» от дешёвых копирайтеров перестали ранжироваться по сложным запросам. Яндекс начал отдавать приоритет текстам, написанным профессионалами, с чёткой структурой, таблицами, списками и уникальными данными. Привет, E-A-T! Использование разметки Schema.org стало еще важнее, так как она помогает «трансформеру» быстрее и точнее понять структуру и суть данных на странице. YATI сделал бессмысленными любые попытки обмануть алгоритм текстом. Гарантированный путь в ТОП в Яндексе после 2020 года — это создавать самый лучший и полный ответ на вопрос пользователя в своей нише. В 2021 году эту линию продолжил алгоритм Y1.
2021–2022 — Y1 и Y2
Инновации алгоритмов Y1 (2021) и Y2 (2022) окончательно перевели поиск из режима «база ссылок» в режим «умный помощник».
Для SEO Y1 и Y2 — это третий и последний звонок, предупреждающий о потерях трафика из-за сдвига синих ссылок вниз блоками обогащённых ответов, вставок видео, карт, товарных блоков. В товарной и событийной выдаче малым сайтам стало почти невозможно конкурировать с крупными площадками, которые Яндекс объединяет в объектные блоки. Y1 и Y2 превратили SEO из «оптимизации слов» в «оптимизацию представления данных». Трафик стали получать те, кто лучше всех размечен технически и чьи видео и товары Яндекс может легко встроить в свои интерактивные блоки.
2024 — Поиск с «Нейро»
«Нейро» — это масштабный апдейт апреля 2024 года, объединивший традиционный поиск и генеративные возможности нейросети YandexGPT 3. Это переход от модели «список ссылок» к модели «ответ на языке человека». Нейросеть сама обходит топ-10 выдачи, изучает содержимое сайтов и пишет один итоговый ответ. Больше не нужно кликать по пяти разным ссылкам, чтобы сравнить мнения.С поиском можно вести диалог. Он помнит контекст предыдущих фраз, что позволяет сужать запрос.
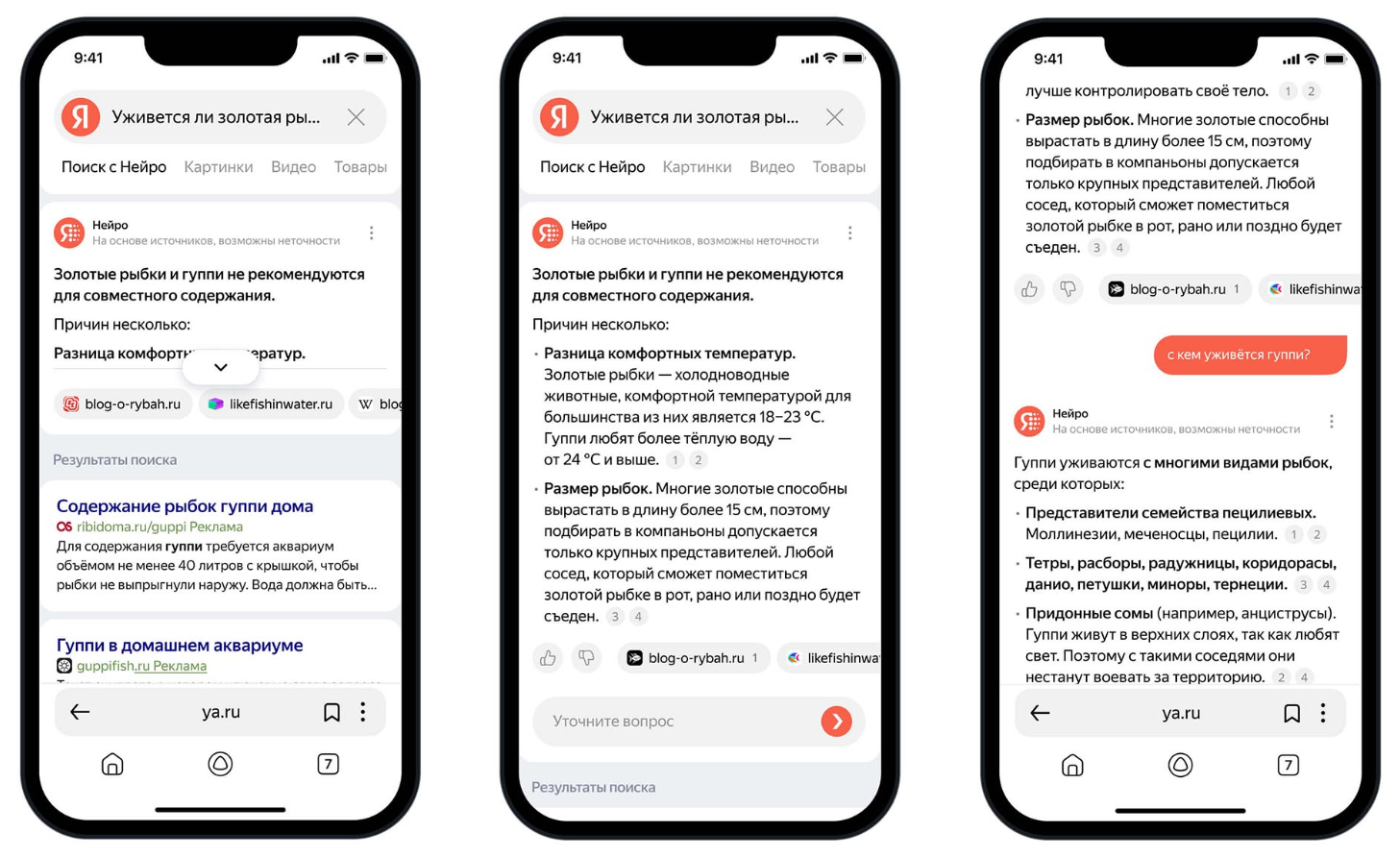
Поиск с «Нейро»
Звонки-предупреждения закончились. С приходом «Нейро» SEO в Яндексе становится другим. Начинается борьба не только за место в выдаче, но и за право стать источником внутри ответа. По простым запросам («как выбрать...», «в чем разница между...», «топ-10...») пользователи перестают переходить на сайты. Ответ нейросети занимает весь первый экран. Но под ответом «Нейро» есть ссылки на сайты, на основе которых он составлен. Задача SEO теперь — попасть в этот список ссылок-источников, чтобы получить «брендовый» клик.
В 2024 году SEO разделилось на две части: техническая разметка для «понимания» нейросетью и сильный бренд, за которым пользователь придёт целенаправленно, проигнорировав ответ ИИ.
2025 — Поиск с Алисой
Следующий шаг Яндекса — это интеграция технологий Алисы в поиск, где появляются режим рассуждений и генерация контента прямо в выдаче. В официальной формулировке это превращает поиск в помощника, который не просто находит, а объясняет и помогает выбрать, а сайтам всё чаще достаётся роль цитируемых источников. В отличии от «Нейро», Алиса — это уже полноценный чат. Она обладает памятью (помнит, что вы спрашивали вчера) и может вести глубокое «исследование» темы, задавая вам уточняющие вопросы, пока не решит вашу проблему «под ключ».Если с «Нейро» начал теряться трафик по информационным запросам, то с внедрением Алисы и пользователи по транзакционным запросам перестали доходить до сайтов и начали решать вопрос с выбором товара или услуги на поиске в интерфейсе Алисы.
В 2025 году SEO окончательно превратилось в работу над авторитетностью бренда и структурированием данных для того, чтобы продвигаемый сайт стал базой знаний для ИИ-агента Яндекса, а бренд рекомендовался в ответах модели по запросам типа «Лучшие поставщики…» или «Оптимальный тариф для…». И, конечно, в условиях, когда Алиса сама даёт ответы, единственным стабильным источником переходов стали запросы конкретных брендов, которым нейросеть не может найти замену
SEO всегда жило в простой человеческой дилемме. Развивать проект трудно: нужно писать, исследовать, улучшать продукт, чинить технику, выстраивать сервис и репутацию. Манипулировать ранжированием легче: достаточно найти один «рычаг» и нажать на него сильнее, чем конкуренты.
Проблема в том, что поисковик видит эту игру, и со временем превращает найденный рычаг в декоративную кнопку. В Google это описано прямо и однозначно: спам — это техники, которые пытаются обмануть или манипулировать системами поиска ради высоких позиций, и за такое страницы или сайты могут ранжироваться ниже или вообще исчезать из результатов, причём и автоматикой, и ручными проверками.
Ниже — понятное разделение на «белое», «серое» и «чёрное» с примерами и описанием того, как граница сдвигалась.
Белое SEO
Белое SEO — это когда вы делаете сайт лучше для людей и одновременно понятнее для поисковой машины. В нём нет фокуса на «взлом» алгоритма. Фокус на том, чтобы алгоритму было за что вас показывать.
В белых методах обычно сходятся три линии.
Первая линия — контент как продукт. Это не «написать текст под ключи», а закрыть задачу пользователя так, чтобы страницу хотелось сохранить, переслать, вернуться. Именно этот тип развития в долгую и выигрывает, потому что он устойчив к смене формул ранжирования.
Вторая линия — техническая ясность. Поиску должно быть легко обойти сайт, понять структуру, не запутаться в дублях и редиректах, не наткнуться на мусор. Это не ускоритель «в топ завтра», но это фундамент, который уменьшает потери и снижает зависимость от случайных апдейтов.
Третья линия — доверие и репутация. В современном поиске важно не только «про что страница», но и «насколько источнику можно верить». Именно поэтому в долгом периоде выигрывают те, кто вкладывается в экспертизу, прозрачность и качество, а не в одноразовые трюки.
Белое SEO почти всегда выглядит скучнее чёрного. Но есть компенсация: оно редко сгорает целиком одним апдейтом.
Серое SEO
Серое SEO начинается там, где вы формально можете не нарушать правила, но мотивация становится другой. Вы делаете не лучший продукт, а макет продукта, который выглядит убедительно для алгоритма. Это зона «на грани».
Типичные серые практики менялись вместе с поиском.
Здесь важно понимать механику. Поисковики не обязаны заранее перечислить все серые схемы. Google прямо пишет, что политики покрывают распространённые практики, но действия возможны против любых типов спама, которые система обнаружит. И если серое SEO начинает выглядеть как масштабная манипуляция, оно легко переезжает в чёрное и получает санкции.
Серое SEO часто выигрывает короткий спринт, потому что дешевле развития. Но оно почти всегда проигрывает марафон, потому что живёт на «дырах» в модели. А дыры закрываются.
Чёрное SEO
Чёрное SEO — это то, что поисковики прямо описывают как попытку обмануть систему. Здесь цель не «сделать полезнее», а «показаться полезнее». Классика чёрного SEO хорошо совпадает с тем, что поисковики называют спам-практиками.
И отдельный важный пласт истории рынка, особенно в 2000–2010-е, — это попытки манипулировать ссылками. Поисковики вначале отвечали изменением модели так, чтобы накрутка давала всё меньше эффекта. А затем стали наказывать за ссылочный спам понижением сайта или страниц в результатах поиска. Google начал борьбу 24 апреля 2012 алгоритмом «Пингвин» (Penguin).И стал понижать в выдаче сайты, которые закупали ссылки на биржах или использовали спамные тексты в ссылках (анкорах). До этого ссылки почти всегда шли в плюс, теперь они могли «утопить» сайт. В сентябре 2016 Пингвин стал частью основного поиска и начал работать в реальном времени. И с 2016 года за плохие ссылки не просто штрафуют весь сайт раз в полгода, а обесценивают конкретные спамные линки мгновенно.
Яндекс долго боролся со специфическим российским рынком «ссылочных агрегаторов» (Sape и другие). В марте 2014 в качестве эксперимента Яндекс полностью перестал учитывать ссылки в ранжировании по коммерческим запросам в Москве. Это был сигнал оптимизаторам, но его поняли не все.14 мая 2015 Яндекс перешел к карательным мерам. Сайты, которые продолжали массово закупать ссылки, стали принудительно понижать в ранжировании. Они теряли десятки позиций в выдаче (обычно падали на 20 и более пунктов) на срок от нескольких месяцев.
Где тут главная мораль
Манипуляции почти всегда дешевле, чем развитие, потому что манипуляция покупает вам видимость, а развитие строит ценность. Но поисковые системы годами показывают один и тот же паттерн реакции. Если техника масштабно используется, чтобы обманывать ранжирование, система либо начинает её ловить, либо перестаёт ей верить, либо и то и другое. Google прямо говорит, что нарушения могут привести к понижению или удалению из поиска, а для обнаружения нарушений используются автоматические системы и, при необходимости, ручная проверка. Яндекс в истории с «Баден-Баденом» формулирует это ещё жёстче и по-русски понятно: чтобы снять ограничения, нужно полностью избавиться от SEO-текстов, то есть от контента, который написан для «влияния», а не для пользы.
Поэтому в долгую выигрывали и выигрывают те, кто инвестировал в контент, функционал и качество сервиса. Их сложно «обнулить», потому что у поисковика нет мотивации прятать полезное. А вот «быстрые рычаги» почти обречены стать историей — обычно короткой, но очень поучительной.
Раньше поиск был витриной, а ответ жил внутри источника. Пользователь задавал запрос, получал список ссылок и дальше сам добывал смысл, сравнивал, перепроверял, собирал финальную картину из нескольких страниц. SEO в этой модели работало как искусство оказаться среди нужных страниц и убедить человека кликнуть именно на вас.Теперь всё чаще наоборот: поиск сам собирает связный ответ и показывает его сразу в выдаче, а источники превращаются в «ингредиенты» этого ответа, в цитаты и опорные ссылки внутри готового текста.
Практический смысл в изменениях простой и чуть ироничный. Раньше мы боролись за место на полке книжного магазина, теперь мы боремся за то, чтобы нашу книгу процитировали в школьном учебнике. Поэтому выигрывают не те, у кого страница «про всё», а те, у кого есть чёткие определения, проверяемые факты, аккуратная структура и репутация источника, чтобы поиску было безопасно вас цитировать.
Эволюция поисковой оптимизации:

Мы – «Сумма технологий», агентство полного цикла из Екатеринбурга. С 2002 года занимаемся системным интернет-маркетингом.
Подпишитесь на нас в соцсетях, чтобы не пропустить авторские статьи и кейсы, приглашения на мероприятия и выгодные предложения. Никакой бесполезной информации.


