


Тендеры и лиды
Информация
Привет! Меня зовут Рома Игнатович, я лид фронтенд-разработки в диджитал-продакшене Далее. В работе я часто сталкивался с ситуациями, когда тормозящие сайты оптимизируют вслепую. Менеджер ставит слишком общую задачу — вроде «нужно ускорить загрузку», — а разработчики начинают перебирать версии, почему сайт тормозит, и проверять всё подряд. Для бизнеса такой подход обычно означает затянутый процесс исправлений и лишние часы разработки.
В этой статье расскажу про эффективный подход при такой задаче — это аудит фронтенда. Он помогает командам не тратить время на гадания, а делать только то, что прямо влияет на метрики и реально оптимизирует сайт. Итак, приступим👇
PageSpeed и похожие инструменты для анализа производительности полезны, но есть нюанс: они показывают симптомы, а не причины. Низкая скорость загрузки контента, нестабильная верстка и клики с задержкой не отражают подкапотную картину. Без дополнительного анализа это просто цифры, за которыми могут скрываться десятки разных проблем.
Иногда лаги на фронтенде появляются из-за тяжелых картинок, иногда причина — медленный бэкенд или неоптимальная загрузка на фронте. А иногда всё сразу. В итоге без системного подхода команда тратит время на случайные улучшения, но не попадает в реальную причину.
У полноценного фронтенд-аудита есть три преимущества:
Занимает в среднем 6–8 часов для среднего проекта.
Покрывает самые частые пользовательские сценарии.
Дает не догадки, а обоснованные гипотезы.
При стандартном анализе разработчики проверяют сайт кусками, но это мешает увидеть самые важные проблемы. Например, главная страница работает быстро, каталог и карточка товара — тоже. Но при переходе между ними возникает задержка и именно она ломает весь пользовательский опыт.
Аудит фронтенда выявляет проблемы в пользовательских сценариях: задержки между шагами, отказы, сложности при взаимодействии. Эти технические параметры прямо связаны с бизнес-метриками — например, с потерей пользователей на этапе оформления заказа
Важно отметить, что фронтенд можно анализировать без доступа к коду. Нужно зайти в браузер и открыть вкладку Performance в DevTools. Важнее знать методику исследования, о ней я расскажу чуть ниже.
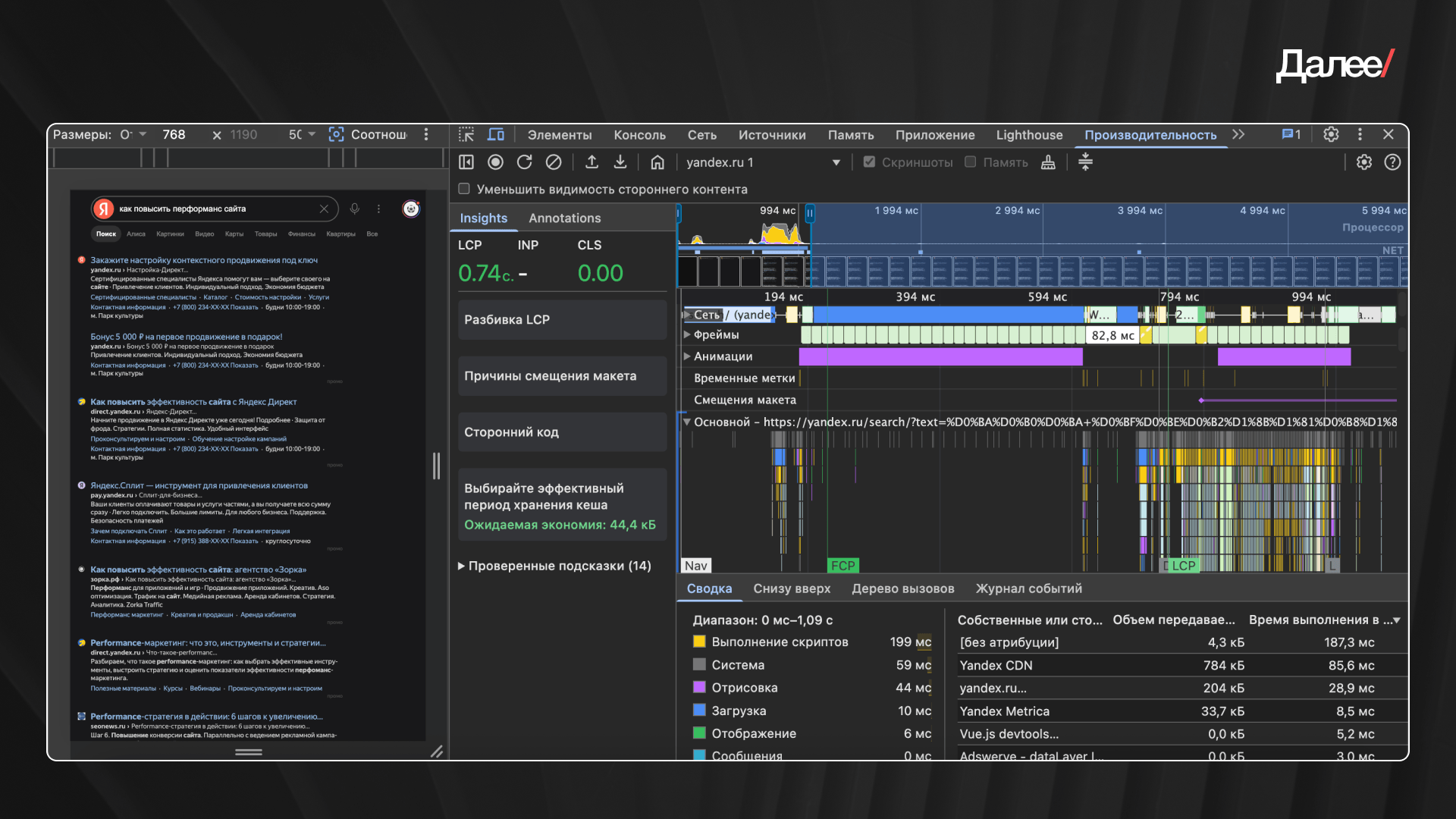
В двух словах задача разработчика — прогнать сценарии и зафиксировать все подозрительные места.
1. Замер производительности и анализ performance trace.
Обычно первым берется ключевой сценарий — например, тот же флоу покупки. Затем включается запись производительности в браузере, и этот сценарий полностью воспроизводится: скролл, клики, переходы, ввод данных. По итогам этих замеров браузер автоматически формирует performance trace — подробную техническую запись пользовательского сценария, которую можно использовать для дальнейшего анализа.
2. Анализ причины.
В Performance trace надо найти долгие сценарии, блокировки потока, проседание анимаций, задержки между действиями. Всё это как раз и провоцирует лаги.
3. Параллельно — проверяем сеть, рантайм и метрики Web Vitals.
1. Network waterfall показывает, какие запросы выполняются, сколько времени они занимают, не блокируют ли они загрузку других ресурсов.
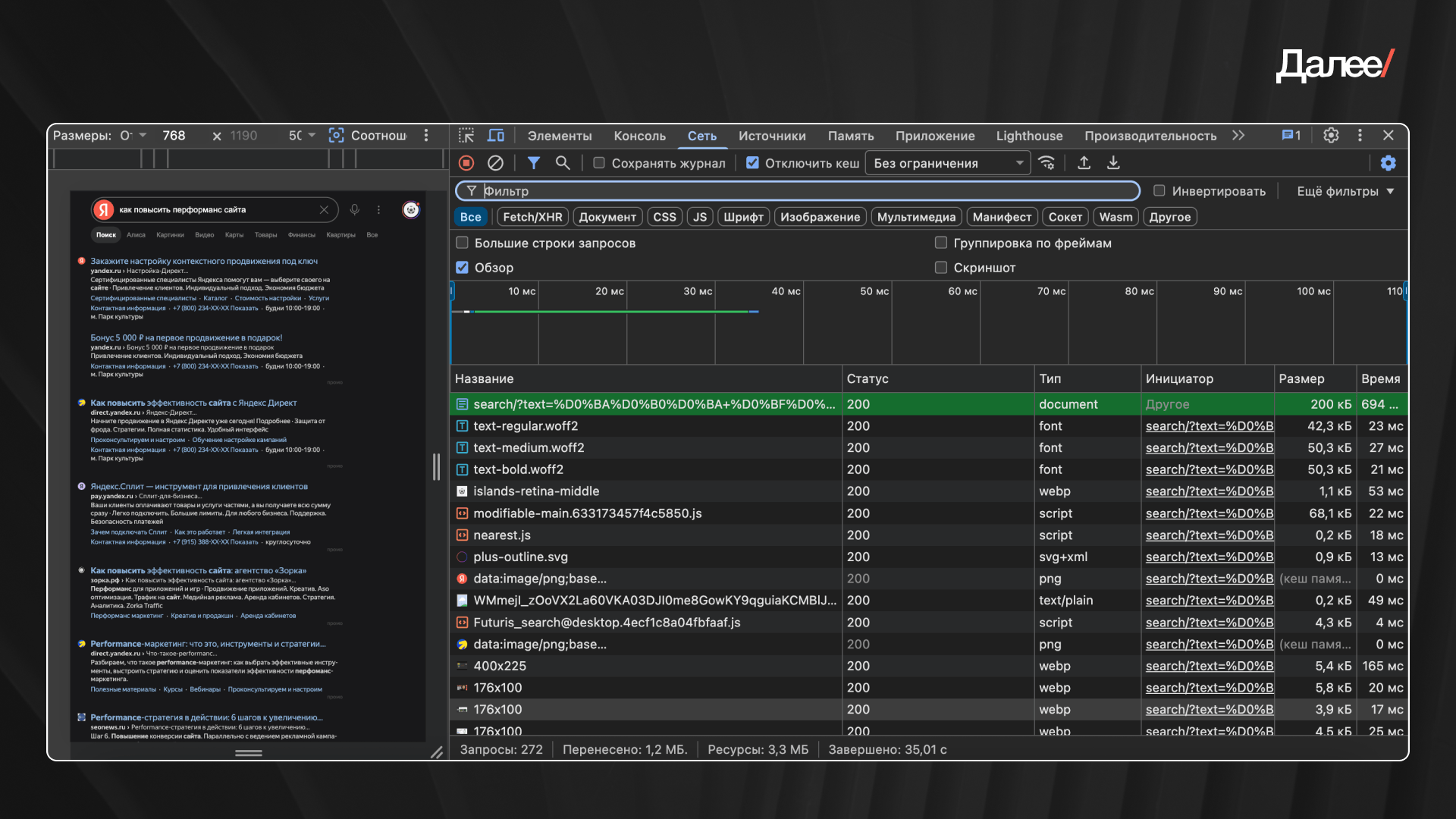
2. Рантайм позволяет анализировать фактическое поведение сайта: реакцию и задержки.
3. Из метрик мы берем за ориентир всего три: LCP — скорость появления основного контента, TTFB — скорость ответа сервера и CLS — стабильность интерфейса.
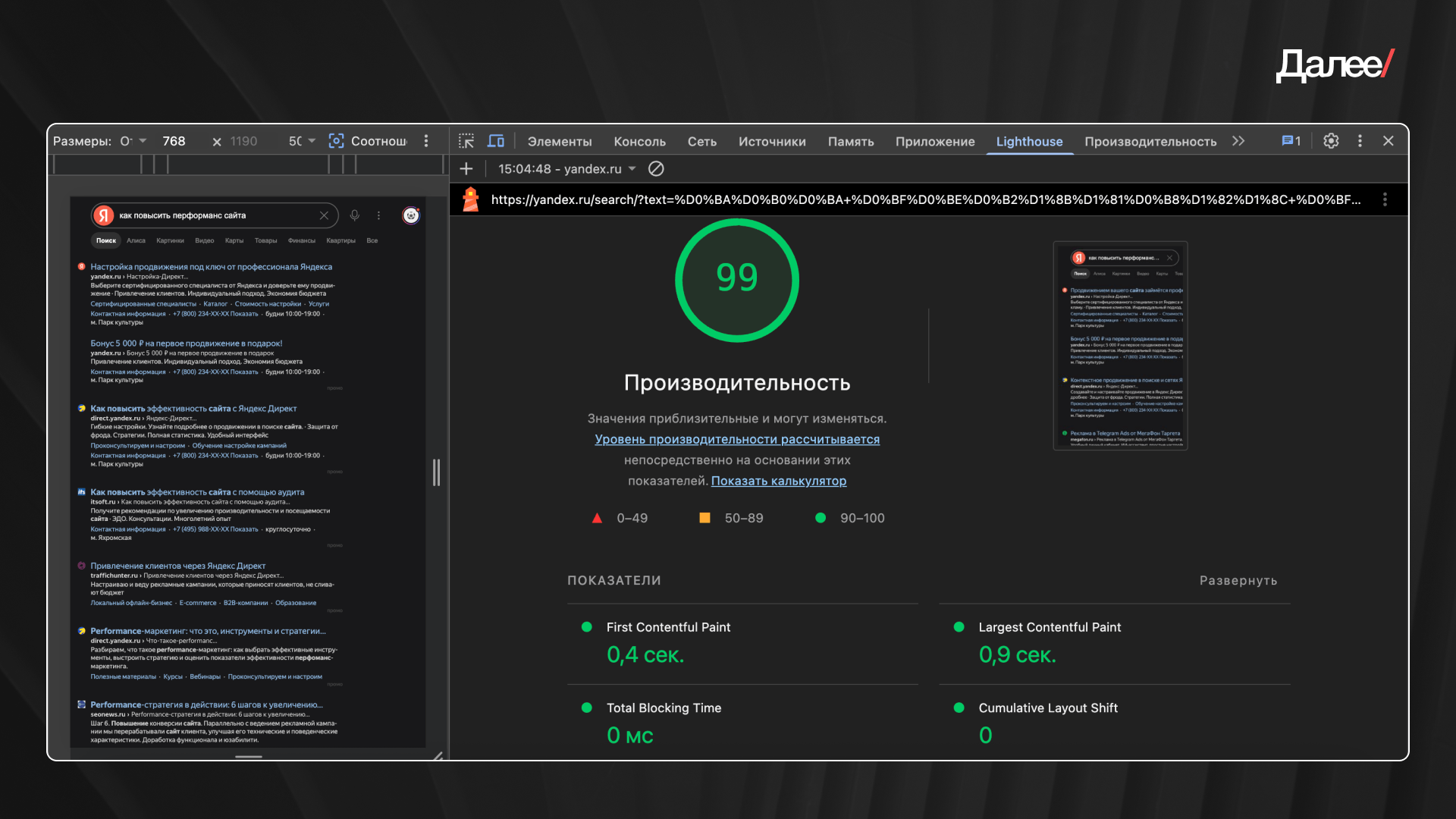
Если продукт работает сразу в нескольких регионах — например, .ru, .kz и .uz, — полезно дополнительно использовать WebPageTest. Он проверяет, как сайт ведет себя из разных географических точек и на разном качестве соединения. Это помогает выявить проблемы, которые не всегда заметны при локальной проверке.
После прохождения всех этапов вы получаете список проблем и можете строить гипотезы о причинах их появления. Обычно этот перечень довольно типовой, независимо от того, исследуете ли вы интернет-магазин или корпоративный сайт.
Наша система сама подберет вам исполнителей на услуги, связанные с разработкой сайта или приложения, поисковой оптимизацией, контекстной рекламой, маркетингом, SMM и PR.
Заполнить заявку
13590 тендеров
проведено за восемь лет работы нашего сайта.
Одна из задач аудита — не просто найти лаг, а быстро определить, в какой зоне он лежит: в загрузке, в интерфейсе или в логике работы приложения. Это позволяет не перебирать все подряд, а сразу сузить область поиска и эффективно все решить.
Почти любая проблема на сайте имеет несколько возможных причин. Поэтому аудит — это всегда работа с гипотезами, а не с «единственно правильным ответом». Ниже — две основные группы проблем и то, какие проблемы и решения за ними чаще всего стоят.
Именно эти проблемы чаще всего стараются лечить по PageSpeed. Симптомы очевидны: страница долго открывается, контент появляется с задержкой, метрики вроде LCP находятся в красной зоне.
Визуально все такие проблемы выглядят одинаково — «сайт медленный». Но под капотом все не так очевидно и причины могут быть разными: от сборки фронтенда до работы бэкенда или просто тяжелого контента.

Вторая группа — это проблемы, которые напрямую влияют на восприятие интерфейса. Сайт может загружаться достаточно быстро, но при этом выглядеть «сломанным» с точки зрения UX: что-то дергается, анимации лагают, элементы скачут, клики срабатывают с задержкой, ввод тормозит.
Такие вещи особенно критичны, потому что пользователь замечает их мгновенно и часто — уже когда совершает целевое действие. Здесь сложно диагностировать «на глаз», потому что лаги появляются случайно, зависят от особенностей рендеринга и иногда от устройства пользователя. Без детального анализа это превращается в выпуск «Необъяснимо, но факт», то есть баг где-то есть, но почему — никто не знает.

Одна из частых ошибок при аудите — проверять сайт на мощной рабочей машине с быстрым интернетом. В таких условиях многие проблемы просто не проявляются, хотя реальные пользователи сталкиваются с ними постоянно.
В DevTools есть два инструмента, которые это исправляют:
CPU throttling — замедляет процессор в 4–6 раз, имитируя среднебюджетный Android-смартфон. Именно здесь вылезают лаги анимаций и подвисания интерфейса, которые на десктопе незаметны.
Network throttling — позволяет симулировать мобильный интернет: 3G, медленный 4G и просто нестабильное соединение. Это сразу показывает, , насколько критичны тяжелые изображения, большие бандлы и неправильный порядок загрузки ресурсов.
Практически все проблемы из раздела выше — лаги анимаций, перегруженный main thread, тяжелые изображения — на мобильных устройствах проявляются в разы острее. Поэтому при аудите стоит прогонять ключевые сценарии минимум дважды: в обычных условиях и с включенным throttling. Если с throttling сайт деградирует критично — это уже не технический долг, а прямые потери пользователей и конверсии.
Знать проблему ≠ знать ее причину. Так и аудит — сильно сужает область поиска и выявляет гипотезы, которые дальше нужно проверять. Посмотреть performance trace, найти ошибки и блокеры недостаточно для системной работы. Все результаты аудита нужно перевести на язык задач, чтобы получился готовый план по исправлениям.
Сформулируйте каждую проблему из аудита как цепочку: проблема → гипотеза → действие
Примеры таких цепочек:
Проблема: интерфейс подвисает при открытии карточки → Гипотеза: длинные JS-задачи → Действие: разбить и оптимизировать выполнение.
Проблема: анимация лагает → Гипотеза: расчеты на CPU → Действие: перевести на GPU через transform.
Проблема: страница долго грузится → Гипотеза: тяжелые изображения → Действие: оптимизировать формат и размер.
Важно: у любой оптимизации должна быть измеримая цель. Например:LCP < 2.5 секунды, CLS < 0.1, снижение веса страницы на 30–40%. Так после изменений можно повторно прогнать сценарии и проверить, улучшились ли метрики.
Из действий нужно сделать план — чтобы понять приоритетность задач и их влияние на бизнес. Задачи ранжируются в зависимости от эффекта, который даст исправление, и затраченных ресурсов. В приоритете — то, что напрямую влияет на ключевые пользовательские сценарии и при этом относительно быстро исправляется. Именно такие изменения дают быстрый и заметный результат.
В любом аудите всегда находится больше проблем, чем имеет смысл исправлять. Если проблема не влияет на конверсию, не мешает пользователю пройти ключевой путь и не создает реальных потерь — ее можно отложить.
Результат аудита фронтенда — не просто список проблем, а обоснованные гипотезы и приоритезированный список задач. Команда не тратит время на слепые попытки, сразу переходит к делу и выдает результат для клиента. Вин-вин по всем фронтам.
После внедрения изменений задачи все равно проходят дополнительную валидацию: через тестирование, проверку бизнес-командой или повторный технический анализ. Это нужно, чтобы убедиться, действительно ли интерфейс стал работать быстрее, а пользовательские сценарии — стабильнее.
Кроме того, через несколько недель после внедрения можно повторно прогнать сайт через Google PageSpeed Insights и сравнить показатели. Метрики обновляются не мгновенно, а постепенно — обычно в течение нескольких недель или месяца. Это позволяет оценить, дали ли изменения реальный прирост в цифрах.
В итоге аудит помогает собрать не просто список задач, а измеримый план оптимизации с понятным эффектом для бизнеса.


