


Тендеры и лиды
Информация
Если Screaming Frog не начинает парсить сайт и забирает только одну страницу (как правило главную), показывающую код ответа 0, 403, 307 и парсинг останавливается, показывая 100%, то вы столкнулись проблемами, варианты решения которых находятся ниже ⏬
Я лично протестировал и использую все эти методы в работе. Метод №4 наиболее эффективен, но к нему стоит обращаться только после того, как были опробованы предыдущие способы.
Скриминг фрог подчиняется правилам robots.txt, поэтому если его User-agent заблокирован, то парсинг не начнется. Чтобы обойти данное правило переходим в разделConfiguration → User-Agent
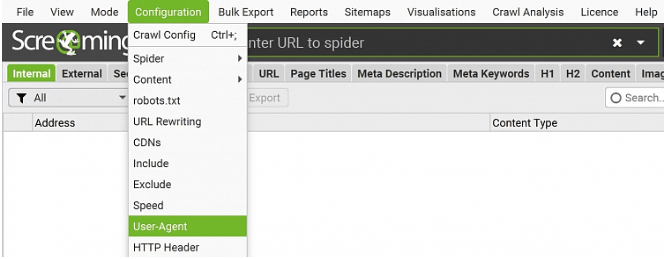
Напротив пункта Preset User-Agents выберите любого другого поискового робота, который точно не будет заблокирован.
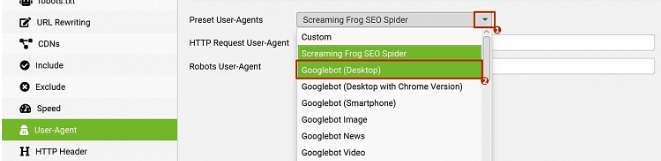
Я обычно выбираю Googlebot Desktop или Smartphone
Нажимаем OK, чтобы настройки применились и запускаем сканирование. Если проблема сохранилась, то переходим к следующему шагу ⏬
Одна из самых частых проблем сканирования является блокировка сканирования сайта в файле robots.txt или попытка просканировать закрытый от индексации сайт в результате чего вы видите ошибкуblocked by robots txt. Ранее я подробно рассказывал как решить эту проблему в одном из видео
Так как интерфейс программы на момент 2024 года немного поменялся, то я решил записать подробную инструкцию в текстовом формате с скриншотами.
Если сайт закрыт для сканирования/индексации, то наша задача заключается в том, чтобы разрешить краулеру заходить на такие страницы, для этого:
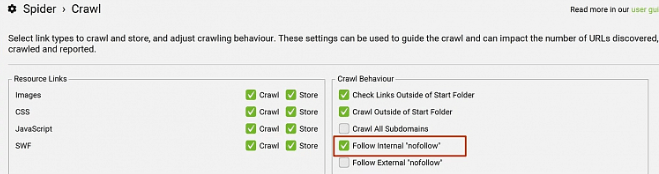
1. Переходим в настройки краулинга Configuration → Spider → Crawl

2. Ставим галочку в разделе Follow Internal "nofollow"
Данная функция разрешает программе сканировать все страницы, которые содержат атрибут nofollow
3. Молодец, осталось только открыть сайт в robots.txt. Напомню, что этот файл отвечает именно за сканирование, поэтому если не разрешить лягушке игнорировать данный файл, то парсинг может не начаться.
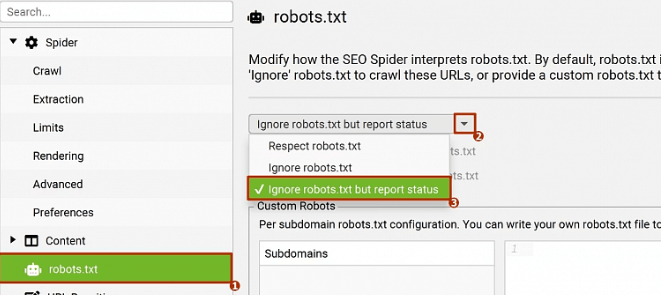
Оставаясь в настройках сканирования переходим в раздел Robots.txt → Выбираем пункт "Ignore robots.txt but report status"
Опция разрешает программе игнорировать правила в файле robots.txt и показывать вам какие именно страницы были закрыты в robots.
Наша система сама подберет вам исполнителей на услуги, связанные с разработкой сайта или приложения, поисковой оптимизацией, контекстной рекламой, маркетингом, SMM и PR.
Заполнить заявку
13488 тендеров
проведено за восемь лет работы нашего сайта.
Нажимаем OK, чтобы настройки применились и запускаем сканирование заново. Если проблема сохранилась, то переходим к следующему методу ⏬
В связи с массовой накруткой поведенческих факторов и увеличением числа ботного трафика многие сайты ставят защиту, которая мешает сканированию сайта. Существуют и другие защиты, которые требуют входа в систему с использованием файлов cookie. Такая защита также легко обходится.
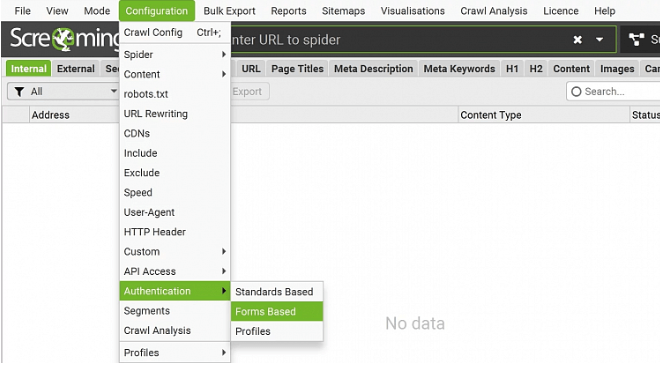
2. Нажимаем "+ Add" → вводим URL-адрес сайта, который хотим сканировать → Нажимаем OK
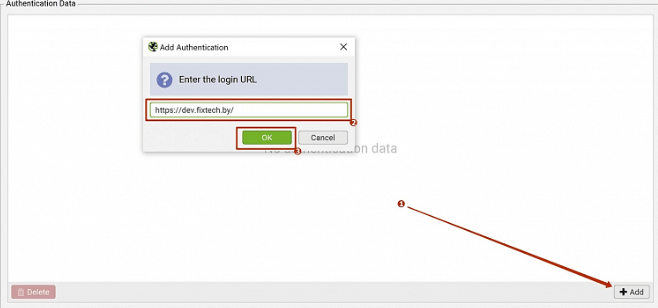
3. Откроется всплывающее окно, в котором отобразится сайт
Опция позволяет вам войти на сайт во встроенном браузере Chromium SEO Spider, получить файлы cookie, а затем сканировать его. Если открывшийся сайт защищен паролем, то изучите данную инструкцию.
Если всё прошло гладко, то нажимаем OK и пробуем запустить сканирование.
Если все вышеописанные методы были испробованы, но проблема сохраняется, скорее всего, ваш IP-адрес был заблокирован. В этом случае рекомендуется снизить скорость парсинга, изменить User-Agent и подключить отдельный прокси.
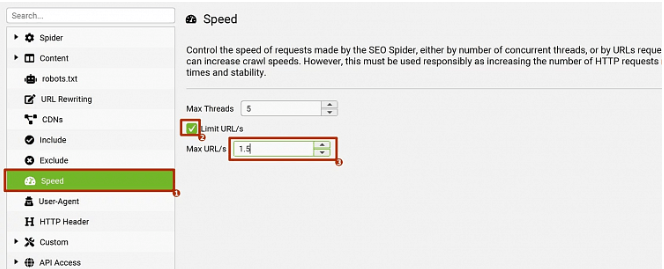
Вы можете как приобрести индивидуальный прокси, так и использовать бесплатные варианты, доступные в сети (хотя их стабильность и функциональность могут быть ограничены). Важно начать с уменьшения скорости парсинга, чтобы избежать блокировки нового IP-адреса. Как изменить User-Agent описано в пункте №1. Далее необходимо уменьшить скорость обхода: перейдите в Configuration → Speed → Установите флажок в разделе "Limit URL/s". В поле Max URL/s задайте значение от 1 до 1,5 и нажмите OK.
Для добавления прокси выполните следующие шаги: перейдите в Licence → Enter Licence, затем откройте Proxy и активируйте опцию Use Proxy Server. Укажите адрес прокси и порт, после чего нажмите OK and Restart и перезапустите программу, чтобы изменения вступили в силу и прокси корректно заработал.
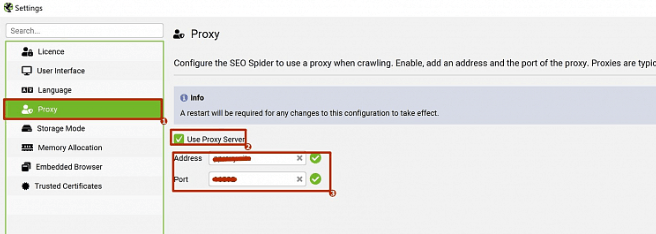
После добавления прокси он будет применяться и в последующих сканированиях. Если он больше не требуется, очистите поле настроек после использования.
Завершающим шагом будет повторное выполнение действия из метода 3, где в появившемся окне нужно будет ввести логин и пароль от прокси и убедиться в работоспособности сайта.
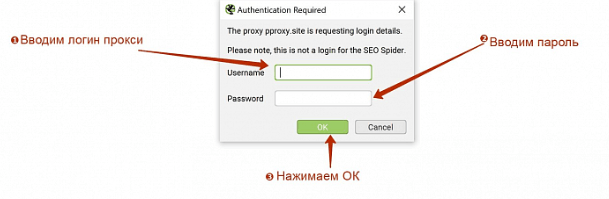
Если проблем не возникло, можно смело запускать парсинг сайта.
Информация взята с сайта https://seo-personal.ru/blog/screaming-frog/ne-parsit/

