

Тендеры и лиды
Информация
В процессе работы с данными нередко возникает задача определения функциональной зависимости yi=f(xi), установленной в результате эксперимента или анализа статистических данных. Иными словами, исходные данные представлены в виде набора точек (x1,y1), (x2,y2), …, (xn,yn), где n — количество измерений. Если аналитическое выражение функции f(x) неизвестно или слишком сложное, то становится актуальной задача поиска функции Y=F(x), которая максимально близко описывает экспериментальные данные при x=xi . Такой процесс приближения функции f(xi) более простой функцией F(x) называется аппроксимацией.
Аппроксимация позволяет анализировать числовые характеристики и качественные свойства объекта, переводя задачу в более удобное математическое представление. Обычно модель аппроксимации выбирают так, чтобы минимизировать ошибку на всем диапазоне исходных данных. Для достижения более точного результата часто применяют несколько видов аппроксимаций и выбирают ту, которая лучше описывает зависимость y=f(xi).
Надежность аппроксимации оценивается с помощью коэффициента детерминации R², в литературе он встречается как "R-квадрат". Этот показатель характеризует степень соответствия модели исходным данным. Далее мы подробнее разберем, что такое R² и как его применять.
Переход от экспериментальной зависимости f(x) к аналитической функции F(x) предоставляет возможность вычислять значения F(x) на всей области определения. Если x является временной переменной, это позволяет, в определенном смысле, предсказывать будущее. Иными словами, имея функцию F(x), можно подставлять в нее любые значения x и получать результаты даже для тех точек, где f(x) не была определена. Это делает аппроксимацию мощным инструментом для прогнозирования, позволяя предвидеть дальнейшее развитие процессов.
Важно понимать, что все измерения дают лишь приближенные значения. Абсолютная точность недостижима из-за множества факторов: ограниченных возможностей измерительных приборов, несовершенства человеческих органов чувств, неоднородности объектов измерения, а также влияния внутренних и внешних факторов. Ошибки измерений делятся на систематические и случайные. Систематические ошибки обусловлены конструкцией приборов и методологией измерений, и их невозможно устранить, работая с уже полученными данными. Однако случайные ошибки поддаются частичному контролю: они могут быть вызваны преобладанием маловероятных исходов при малом объеме экспериментов.
Для минимизации случайных ошибок необходимо увеличивать объем данных. Чем больше измерений проводится, тем выше достоверность получаемых результатов. При обработке больших массивов данных на первый план выходят базы данных, которые поддерживают масштабируемость, такие как GreenPlum/Postgres и Hive. Эти системы позволяют эффективно обрабатывать данные и выполнять сложные запросы. Предложенный подход универсален и может быть адаптирован для работы с другими базами данных.
Сегодня существует множество библиотек и программных продуктов, реализующих различные методы аппроксимации. Эти инструменты представлены как в популярных математических пакетах, так и в специализированных приложениях, предназначенных для решения подобных задач. Однако одной из сложностей при работе с большими объемами данных является их хранение в базах данных, специально созданных для обработки и управления числовыми массивами. Процесс передачи данных из таких хранилищ во внешние приложения зачастую оказывается трудоемким и сложным, а в некоторых случаях — вовсе невозможным.
В данной статье мы хотим показать, что для решения задач аппроксимации вовсе не требуется использование сторонних инструментов. Если ваши экспериментальные данные находятся в базе данных, и вы имеете возможность выполнять к ним SQL-запросы, то этого уже достаточно для реализации методов аппроксимации.
Метод наименьших квадратов (МНК) — это математический подход, который используется для решения задач путем минимизации суммы квадратов отклонений заданных функций от экспериментальных данных. Основная идея метода заключается в минимизации расхождений между исходной функцией f(x) и аппроксимирующей функцией F(x). Для этого применяется числовая мера: сумма квадратов разностей f(x) и F(x) должна быть минимальной [1].
Аппроксимирующая функция по МНК определяется из условия, при котором сумма квадратов отклонений между расчетной функцией F(x) и массивом экспериментальных данных достигает минимума. Этот критерий записывается следующим образом:
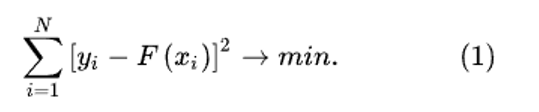
Здесь F(xi) представляет значения расчетной аппроксимирующей функции в узловых точках, а xi, yi — массив заданных экспериментальных данных в этих узловых точках.
Применение метода наименьших квадратов позволяет:
Ответ на первые два вопроса может быть получен с помощью расчета величины достоверности R², которая также известна как коэффициент детерминации. Этот показатель оценивает, насколько хорошо выбранная аналитическая модель F(x) описывает экспериментальные данные. Коэффициент детерминации R² может быть вычислен по следующей формуле [2]:
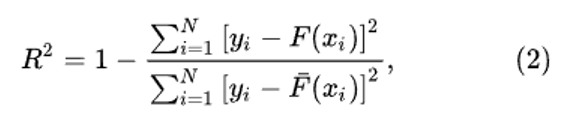
где:
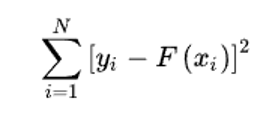
– сумма квадратов остатков регрессии; yi и F(xi) – фактическое и расчетное значение переменной y в данной точке x,
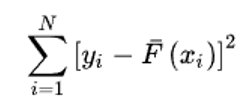
– сумма квадратов разности между фактическим и средним значением F(xi), N – число точек. [2].
Чем ближе значение коэффициента детерминации R² к 1, тем лучше модель соответствует экспериментальным данным. При оценке регрессионных моделей R² интерпретируется как степень объясненной вариации данных.
Выбор конкретного вида аппроксимирующей функции чаще всего определяется физическими или теоретическими соображениями, связанными с природой исследуемого явления. В зависимости от задачи это могут быть:
Таким образом, выбор функции основывается не только на математической точности, но и на физическом смысле, стоящем за данными.
Будем считать, что вид аппроксимирующей зависимости выбран и ее можно записать в виде:
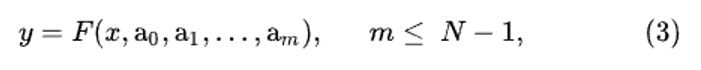
где F – известная функция, a0, a1, … am – неизвестные постоянные параметры, значения которых надо найти. В методе наименьших квадратов приближение функции (3) к экспериментальной зависимости считается наилучшим, если выполняется условие:
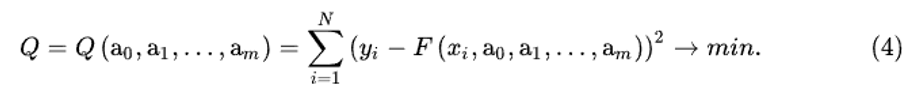
То есть суммa квадратов отклонений искомой аналитической функции от экспериментальной зависимости должна быть минимальна.
Необходимым условием минимума функции нескольких переменных является равенство нулю всех частных производных этой функции по параметрам. Таким образом, отыскание наилучших значений параметров аппроксимирующей функции (3), то есть таких их значений, при которых
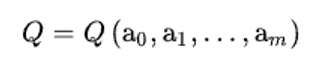
минимальна, сводится к решению системы уравнений:
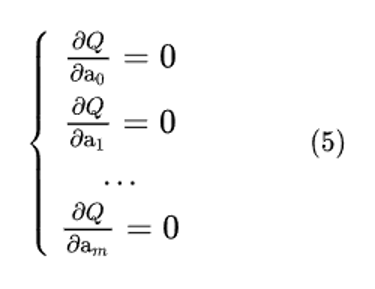
Строго говоря, с математической точки зрения, минимизация функции требует дополнительной проверки. Чтобы убедиться, что найденное значение действительно является минимумом, а не просто экстремумом, необходимо проверить, что вторые производные функции Q по параметрам ai положительны.
Однако для упрощения мы не будем выполнять такие расчеты. Вместо этого будем исходить из эмпирического критерия: если коэффициент детерминации R² оказывается меньше 0,5, это будет свидетельствовать о том, что аппроксимация плохо описывает экспериментальные данные. В таком случае аппроксимацию следует признать неудовлетворительной и рассмотреть альтернативные модели.
Одним из самых простых инструментов, с помощью которых можно построить аппроксимацию на основе экспериментальных данных, можно считать Excel из пакета Microsoft Office. Давайте посмотрим на то, как работает простейший вид аппроксимации на реальном примере. Excel позволяет нам не только построить аналитическую зависимость F(x), он еще и позволяет увидеть все численные коэффициенты как самой аналитической зависимости, так и величину достоверности.
В качестве экспериментального результата для исследования возьмем статистику роста интернет пользователей в зависимости от года (см. рис. 1) [3].
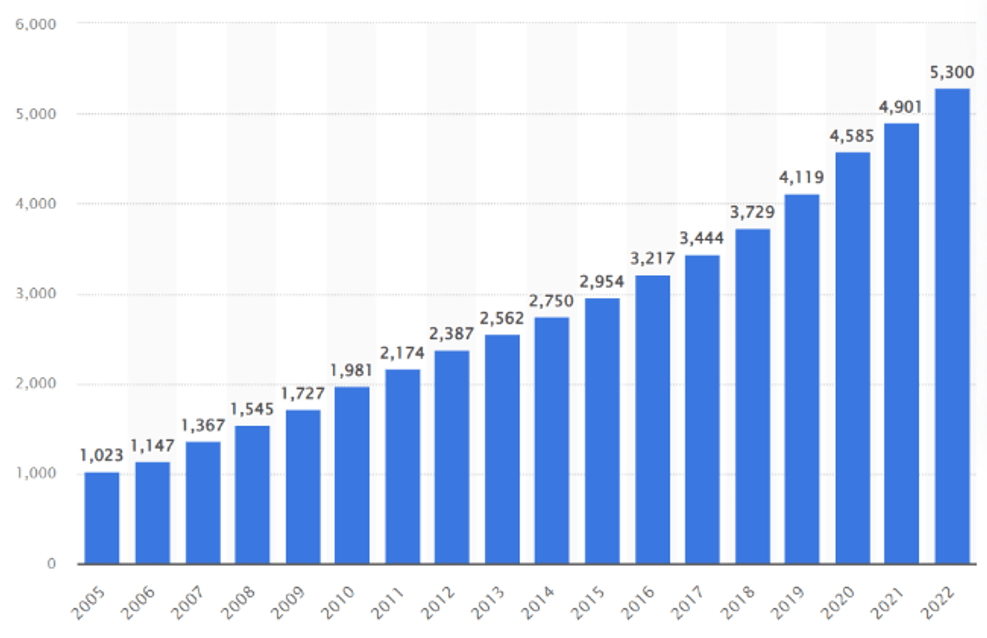
рис. 1 - Ежегодная статистика количества интернет пользователей [3]
Экспериментальные данные были перенесены в Excel, где была построена аппроксимация в виде линии тренда. В качестве модели выбрана простейшая линейная зависимость (Linear). В настройках аппроксимации были активированы опции «Display Equation on chart» (отображение уравнения на графике) и «Display R-squared value on chart» (отображение значения R²). Результаты этих настроек видны на рисунке. Дополнительно был задан диапазон прогнозирования на будущие годы – Forecast forward, установленный на 5 лет, что позволяет продлить зависимость на указанный период. Таким образом, с определённой степенью точности можно предсказать развитие событий в будущем, что отражено пунктирной частью красной линии, выходящей за пределы 2022 года.
Полученная аппроксимация, выраженная уравнением [F(x) = 0,242x – 0,5291] (см. рис. 2), достаточно хорошо описывает экспериментальные данные. Этот вывод подтверждается не только визуальным совпадением, но и высоким значением коэффициента R², которое существенно превышает теоретически требуемый порог (более 80% считается показателем хорошего совпадения). Однако возникает вопрос: можно ли считать эту аналитическую кривую наилучшим образом описывающей эксперимент? В принципе, да, но только до тех пор, пока не будет найдена другая кривая с более высоким значением достоверности аппроксимации.
Таким образом, теоретически мы получили ответы на поставленные вопросы: высокое значение R² указывает на наличие зависимости между аргументами и экспериментальными значениями, а также были определены численные коэффициенты аналитической зависимости (a и b). Хотя на данный момент нельзя утверждать, что данная аппроксимация является наилучшей, можно уверенно сказать, что она хорошо описывает имеющиеся экспериментальные данные (см. рис. 2).
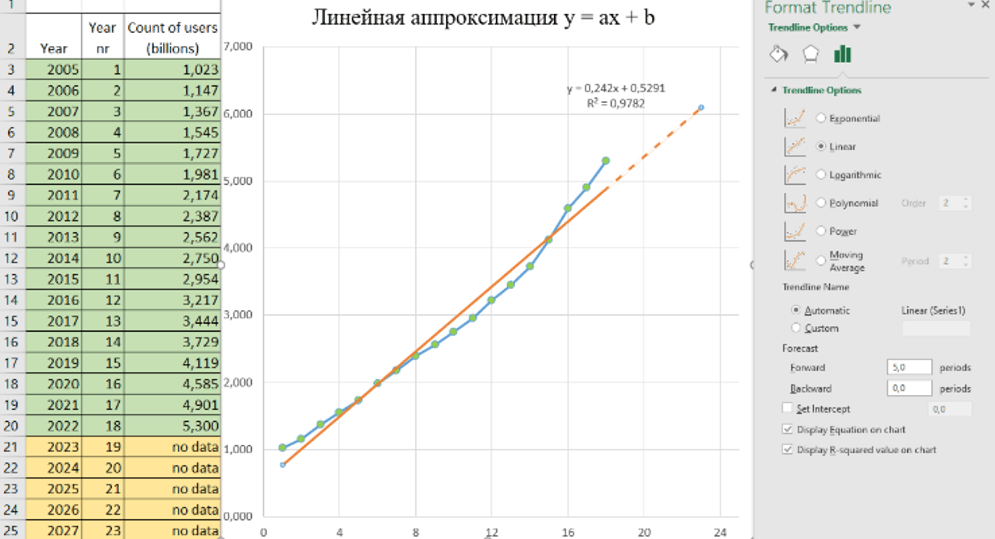
Рис. 2. Линия тренда (аппроксимация) на основе экспериментальных данных с учетом прогноза на последующие несколько лет. Для простоты расчета будем отсчитывать время наблюдения от 2005 года, т.е. 2005 год – это первый год наблюдения
Теперь выполним самостоятельно ряд расчетов на основе теории, изложенной выше. В качестве функций для аппроксимации выберем ряд простейших функций. Очевидно, что для описания имеющегося экспериментального результата необходимо использовать возрастающую функцию. Таким образом, нам подойдут не все функции, однако не будем исключать на данном этапе иные варианты, поскольку их вполне можно использовать для описания других экспериментальных результатов.
4.1 Линейная функция
Рассмотрим, как это работает на простом примере линейной функции. Будем считать, что F(xi) = axi + b. Тогда перепишем формулу (1) следующим образом:
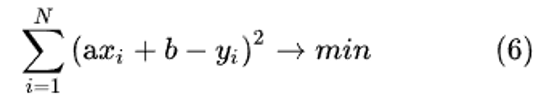
Переменными в данном случае выступают a и b, а поскольку результат должен стремиться к нулю, то можно записать условие экстремума по переменным a и b (см. (5)):
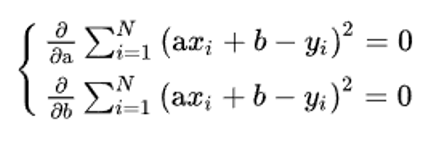
Выразив a и b,получим следующий результат:
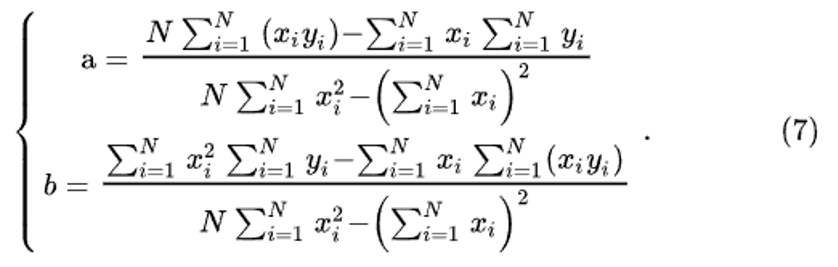
Теперь коэффициенты a и b можно подставить в уравнение F(x) = ax + b в явном виде.
Для работы с экспериментальными данными создадим таблицу, которая будет содержать два поля:
Затем заполним эту таблицу данными, аналогичными тем, что представлены на графиках, где год будет начинаться с единицы, а количество пользователей будет записано в поле ciu.
Далее мы создадим представление (view) для вычисления линейной зависимости, включая дополнительные расчеты для других типов аппроксимаций, которые понадобятся в будущем. Для оценки коэффициента достоверности R² необходимо будет выполнить еще один запрос, используя соответствующую формулу, который будет учитывать все необходимые параметры.

1. k_yval: Подзапрос, который определяет минимальный и максимальный год в данных для корректной работы с индексами временных рядов. Минимальный год уменьшается на 1 для правильной настройки временных меток.
2. k_stat: В этом подзапросе создаются новые столбцы, которые представляют собой преобразованные данные. Эти столбцы используются для дальнейших расчетов в аппроксимациях. Например, данные о годах и количестве пользователей преобразуются в новые значения, которые используются для вычисления коэффициентов в различных типах аппроксимации.
3. k_par: Этот подзапрос агрегирует необходимые статистические показатели, такие как суммы произведений и суммы отдельных параметров, которые будут использованы для вычислений в дальнейших шагах.
4. k_app: Здесь вычисляются коэффициенты для нескольких типов аппроксимации, включая линейную, экспоненциальную, степенную, логарифмическую, обратную и гиперболическую аппроксимации. Каждый из этих типов аппроксимаций требует своих специфических расчетов, основанных на ранее агрегированных данных.
5. Основной запрос: В финальном шаге выбираются данные для построения аппроксимаций. Для каждого года в выборке вычисляются значения аппроксимирующих функций. Для новых, недостающих данных (например, для прогнозирования будущих значений) создаются виртуальные строки с помощью UNION ALL, которые обеспечивают продолжение анализа для будущих годов. Итоговые данные содержат значения для каждого года, реальные данные о пользователях, а также значения, вычисленные на основе аппроксимирующих функций.

Полученные таким образом результаты представлены на рис. 3
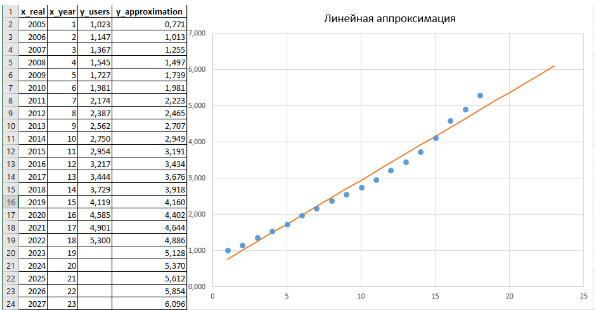
Рис. 3 Линейная аппроксимация y = ax + b, построенная на основе Листинга 1.
В расчете (Листинги 1, 2) были получены следующие численные значения: a_lin = 0,242; b_lin = 0,5291; R² = 0,9782, что говорит о хорошем совпадении аппроксимации с эмпирическими данными.
Наша система сама подберет вам исполнителей на услуги, связанные с разработкой сайта или приложения, поисковой оптимизацией, контекстной рекламой, маркетингом, SMM и PR.
Заполнить заявку
13517 тендеров
проведено за восемь лет работы нашего сайта.
4.2 Экспоненциальная аппроксимация
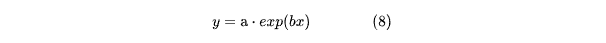
Снова решаем систему уравнений (5), но уже для другого вида функций аппроксимации (8). Проще всего это сделать, выполнив замену вида:
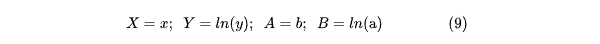
отсюда (8) можно записать как Y = B + AX, таким образом решение сводится к уже проделанному ранее (см. формулу 7):

Выполнив обратную замену в соответствии с (9), получим:

Теперь коэффициенты a и b можно подставить в уравнение (8) в явном виде. Аналогично предыдущему расчету можем записать соответствующий SQL запрос для построения экспоненциальной зависимости. Не будем, по сути, дублировать листинг 1, запишем только ту часть листинга, которую придётся скорректировать при переходе к экспоненциальной функции.

Полученные таким образом результаты представлены на рис. 4:
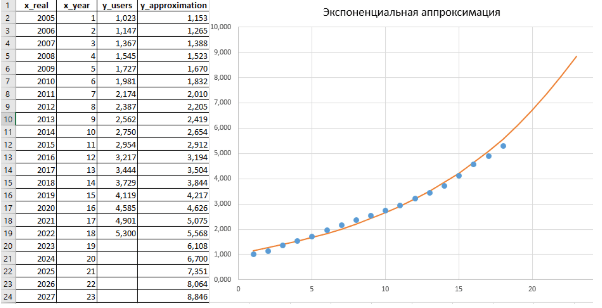
Рис. 4 Экспоненциальная аппроксимация y = a∙exp(bx), построенная на основе Листинга 3.
В расчете (Листинги 3 и 2) были получены следующие численные значения a_exp = 1,051; b_exp = 0,0926; R² = 0,9903, что говорит о хорошем совпадении аппроксимации с эмпирическими данными.
Следует отметить, что в общем виде формула 8 могла бы содержать дополнительное слагаемое – c, т. е. могла бы быть записана следующим образом: y=a∙exp(bx)+c. К сожалению, в таком виде свести функцию к линейному виду, а следовательно, решить аналитически уравнение методом МНК – не получится. Однако, если наблюдаемая экспериментальная зависимость, как и в нашем случае, возрастает (b > 0), а асимптотой является горизонтальная прямая, не совпадающая с осью Х, то величина с может быть определена как смещение по оси Y, т.е. c – расстояние от оси X до асимптоты. Тогда задачу можно будет решить в новой системе координат, где ynew = y – c, после чего вернуться к «старой» системе.
4.4 Логарифмическая функция
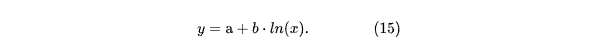
Линеаризация Y = B+AX и переобозначение:
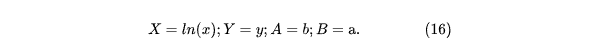
Отсюда получим такое же решение, как и в (10), а выполнив обратные преобразования (16), получаем:
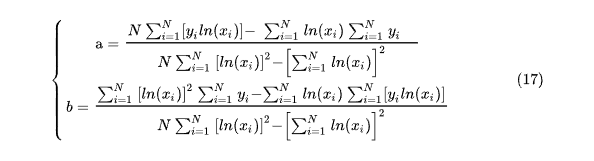

Полученные таким образом результаты представлены на рис. 6:
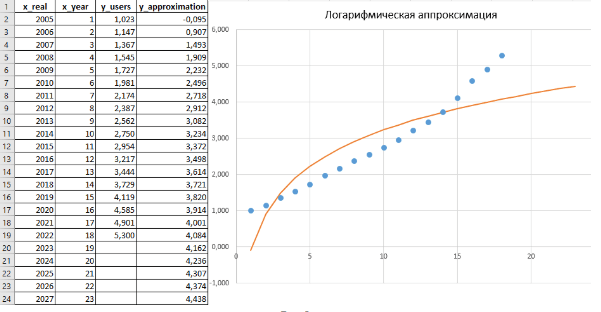
Рис. 6 Логарифмическая аппроксимация y = a + b ∙ ln(x), построенная на основе листинга 5.
В расчете (листинги 5 и 2) были получены следующие численные значения a_log = -0,0951; b_log = 1,4459; R² = 0,7876. Здесь величину достоверности уже нельзя считать удовлетворительной.
4.5 Обратная функция
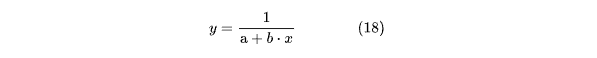
С первого взгляда на функцию становится очевидным, что она не подходит для корректного описания данного примера. Однако не стоит ограничиваться только этим частным случаем, поскольку в теории такая функция может успешно применяться для моделирования других экспериментальных зависимостей. Поэтому имеет смысл изучить её более детально.
Линеаризация Y = B+AX и переобозначение:
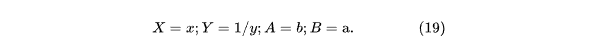
Отсюда получим такое же решение, как и в (10), а выполнив обратные преобразования (19) получаем:
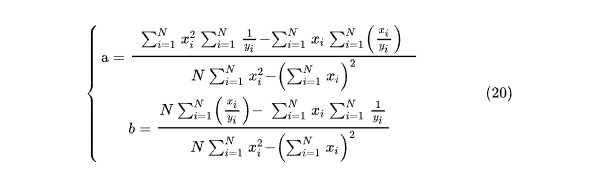
Теперь коэффициенты a и b можно подставить в уравнение (18) в явном виде. Аналогично предыдущему расчету можем записать соответствующий SQL-запрос для построения обратной зависимости. Запишем только ту часть листинга 1, которую придется скорректировать при переходе к обратной функции.

Полученные таким образом результаты представлены на рис. 7:
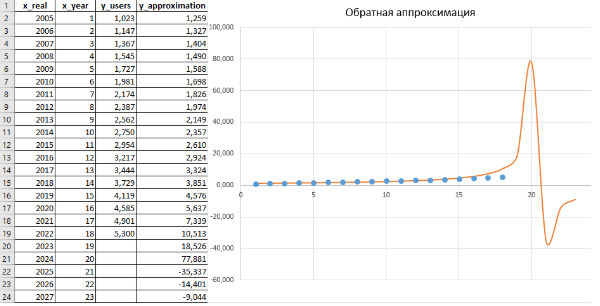
В результате расчетов (листинги 6 и 2) были получены следующие численные значения: a_inv = 0,8356; b_inv = -0,0411; R² = -0,1197. В данном случае значение коэффициента достоверности R² нельзя считать удовлетворительным. Кроме того, функция (18) имеет точку разрыва второго рода в точке x = -a/b, где она не определена. Однако на графике этот разрыв не был обнаружен из-за низкой точности аппроксимации. Это явно указывает на то, что обратная функция совершенно не подходит для построения линии тренда, описывающей имеющиеся экспериментальные данные.
4.6 Гиперболическая функция
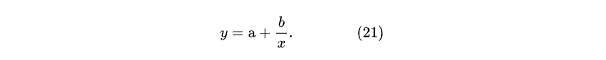
Линеаризация Y = B+AX и переобозначение:
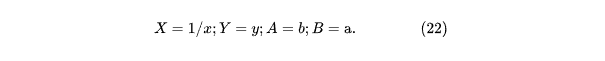
Отсюда получим такое же решение, как и в (10), а выполнив обратные преобразования (22) получаем:
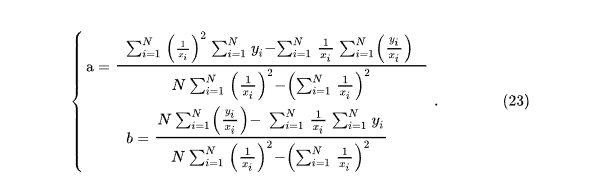
Теперь коэффициенты a и b можно подставить в уравнение (21) в явном виде. Аналогично предыдущему расчету можем записать соответствующий SQL-запрос для построения гиперболической зависимости. Запишем только ту часть листинга 1, которую придётся скорректировать при переходе к гиперболической функции.

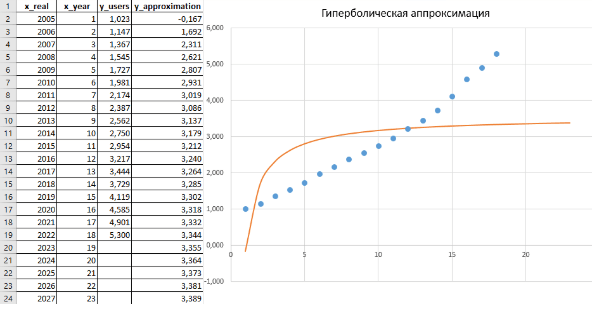
В расчете (Листинги 7 и 2) были получены следующие численные значения: a_hyp = 3,5503; b_hyp = -3,7176; R² = 0,4345, здесь величину достоверности уже нельзя считать удовлетворительной.
4.7 Полиномы второй степени
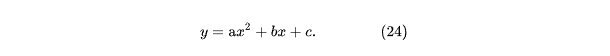
В соответствии с формулой (1) получаем:
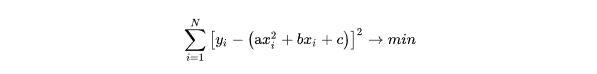
В таком случае согласно (5) получаем систему уравнений:
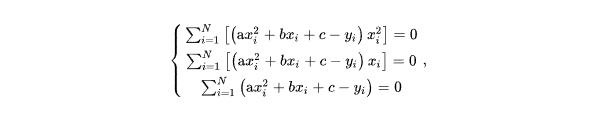
выполнив преобразования, получаем:
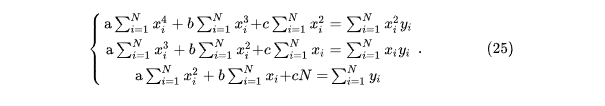
Проще всего решить данную систему уравнений методом Крамера [4] (напомню, что неизвестными в нашем случае являются переменные a, b и с):

Отсюда:
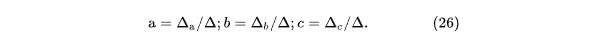
Теперь коэффициенты a, b и c можно подставить в уравнение (24) в явном виде. А значит можем записать соответствующий SQL-запрос для построения полиномиальной зависимости второй степени (см. листинг 8).

Результаты, полученные таким образом, представлены на рис. 9:
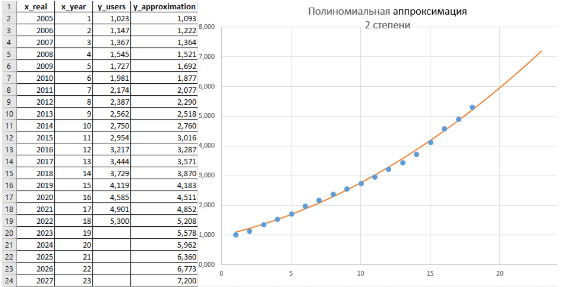
Рис. 9 Аппроксимация полиномом второй степени y = ax² + bx + c построенная на основе листинга 8.
В ходе расчетов (листинги 8 и 2) были получены следующие численные значения: a_sqr = 0,0071; b_sqr = 0,1070; c_sqr = 0,9791; R² = 0,9962. Эти результаты представляют собой наилучший вариант аппроксимации из всех полученных. Стоит отметить, что в принципе можно было бы провести аналогичные вычисления для полиномов более высоких степеней, поскольку их решение не вызывает принципиальных трудностей. Однако такие расчеты оказались бы значительно более сложными и трудоемкими по сравнению с аппроксимацией полиномом второй степени. В данном случае ограничимся констатацией того, что SQL вполне пригоден для работы с аппроксимацией полиномами более высокого порядка.
При этом важно учитывать, что увеличение степени полинома может улучшить точность интерполяции, то есть приблизить теоретическую кривую к экспериментальным точкам. Однако это может негативно сказаться на качестве прогнозирования, так как высокая степень полинома часто приводит к излишнему усложнению модели, что ухудшает её пригодность для построения линии тренда на будущие периоды. Аппроксимация, по своей сути, представляет собой попытку заменить сложные зависимости более простыми математическими моделями, и в этом процессе важно избегать чрезмерного усложнения, чтобы сохранить баланс между точностью и практической применимостью.
4.8 Результаты
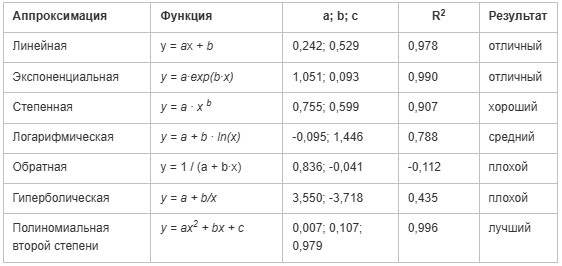
В таблице представлены результаты различных методов аппроксимации, применённых к экспериментальным данным. Каждая строка таблицы содержит информацию о типе аппроксимации, соответствующей математической функции, значениях коэффициентов (a, b, c), коэффициенте достоверности R² и оценке результата.
При переходе от Postgres/GreenPlum к Hive необходимо учитывать различия в обработке преобразований типов, что требует внесения изменений в синтаксис запросов. Например, в Postgres/GreenPlum выражение SELECT 1 / 2 возвращает 0, тогда как в Hive оно возвращает 0.5. Это означает, что в Hive нет необходимости явно выполнять преобразование типов (см. пункт 1, листинг 9). Число 5 в пункте 2 листинга 9 указывает на продолжительность прогноза, который в данном случае составляет пять лет.
Ниже приведены изменения, адаптированные под синтаксис Hive:

Для демонстрации полученных результатов потребовалось минимальное количество инструментов: таблица с экспериментальными данными, возможность написания SQL-запросов и Excel в качестве инструмента для визуализации. Однако стоит отметить, что современные BI-инструменты, такие как Grafana, Power BI и другие, также позволяют отображать результаты на дашбордах, используя SQL-запросы. В таком случае, для визуализации линий тренда достаточно интегрировать аппроксимирующий запрос в выбранный BI-инструмент, что существенно упрощает задачу.
Выбор аппроксимирующей функции должен основываться на вычисленных параметрах, которые наиболее точно описывают функциональную зависимость между исследуемыми величинами. Если существует несколько подходящих вариантов аппроксимирующих функций, предпочтение следует отдать той, которая обеспечивает наибольшее значение коэффициента достоверности R2R2.
Представленный набор функций для аппроксимации, хотя и не является исчерпывающим, включает наиболее распространённые и простые методы, которые подходят для аппроксимации непериодических экспериментальных данных. Используемый метод наименьших квадратов (МНК) обладает тем преимуществом, что предоставляет универсальную теоретическую основу, применимую к различным типам аппроксимирующих функций. Это позволяет исследователю самостоятельно добавлять новые функции, если существующие не удовлетворяют требованиям точности. Для этого необходимо выполнить аналогичные вычисления и оценить успешность аппроксимации, рассчитав коэффициент R2R2.
Однако МНК имеет ряд существенных ограничений. Во-первых, он не учитывает погрешность отдельных измерений. Во-вторых, метод не способен учитывать возможные систематические ошибки. В-третьих, его применение оправдано только при наличии достаточно большого количества экспериментальных данных. Действительно, набор точек (x,y)(x,y), полученных в результате эксперимента, неизбежно содержит ошибки измерений, шум, выбросы и другие искажения. При большом объёме исходных данных можно использовать методы интегрирования, такие как оконная функция AVG(x) OVER (PARTITION BY mygroup), где mygroup — группа точек за определённый период (неделя, месяц, квартал и т.д.), что позволяет уменьшить влияние ошибок на конечный результат.
Сложность и многообразие процессов, происходящих в реальных системах, не позволяют создать абсолютно точные математические модели. Математическая модель, описывающая формализованный процесс функционирования системы, может охватить только основные закономерности. Поэтому от аппроксимации разумно требовать, чтобы функция передавала общую тенденцию, а не точно проходила через все экспериментальные точки. Таким образом, процесс аппроксимации сводится к построению приближённой функции, которая отражает общий характер зависимости. Исследователь в этом случае вынужден полагаться на свою интуицию, опираясь на постановку задачи и понимание природы процессов, происходящих в системе.





