Тендеры и лиды
Информация

ООО «ПРАЙ»
Образование, наука, работа
Россия, Славянск-на-Кубани
Порталы и сервисы
Август 2025
Проект является нашей собственной разработкой, готовой для внедрения в экосистемы заказчика.
В России образовалась потребность в качественных технологиях распознавания с картинки неструктурированных текстовых документов.
Решений по распознаванию паспортов, СНИЛС итд на рынке достаточно, но сервисов, которые смогли бы с сохранением структуры распознать научную документацию, деловую переписку или отчёты, с различными графиками и таблицами — недостаточно.
Мы приняли решение создать сервис (с возможностью SaaS) который бы при помощи Искусственного интеллекта распознавал любые типы документов, от газетных статей до научных трудов, сохранял структуру документа и давал возможность её редактирования.
Особое внимание мы уделили возможности распознавания таблиц различных видов и распознаванию формул.
Этапы работы:
Анализ задачи
Составление плана работы(спринты)
Разработка алгоритма по спринтам
Интеграция алгоритма с системой
Тестирование
Запуск в production
Доработка и обновление
Мы изучили все имеющиеся технологии распознавания документов и определились с несколькими, которые взяли для тестирования. В хоте работы выявили, что наиболее подходящей для наших целей будет технология OCR.
Для обучения модели был собран пул текстов на русском языке и различными вариантами графической реализации. Тексты были подготовлены для обучения.
Мы произвели обучение механизма интеллектуального анализа привязке узлов онтологической модели к разделам выходного документа на основе многоклассовой классификации текстов.
Благодаря работе мы добились точности распознавания 98,1% при скорости 5,87 сек. При том, что Tesseract показывает точность 97,4%, скорость 5,29 сек. Тест проведён на RDIOD: русский документ и набор данных OCR
Далее был реализован механизм формирования XML документа в соответствии со сформированными онтологическими моделями (шаблонами) по стандарту ANSI/NISO STS 1.2.
Кроме того реализована выгрузка распознанного документа в DOCX и PDF
Создан пользовательский интерфейс, который позволяет получить информацию о возможностях сервиса, а также распознать документ с таблицами, формулами и картинками, с возможностью выгрузить распознанный документ.
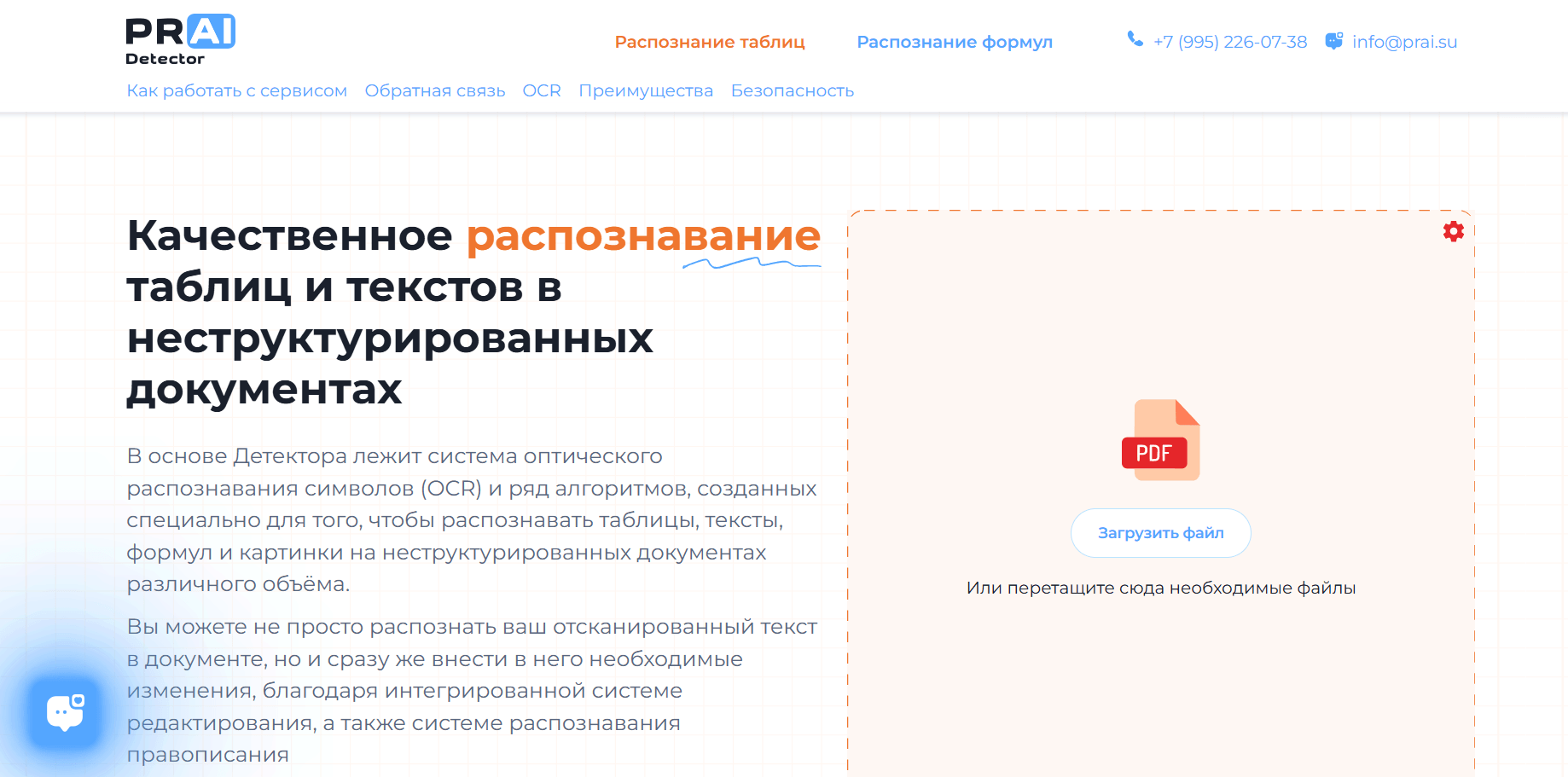
MVP проекта доступна для использования любому пользователю