Тендеры и лиды
Информация

500 000
Торговля
Июнь 2026
Практический кейс: создание гибридной поисковой системы для e-commerce, которая обходится без дорогой векторной RAG-архитектуры, снижает нагрузку на серверное оборудование и гарантирует абсолютную точность.
Контекст: Вызов и предпосылки
Цель проекта:
Разработать и внедрить ИИ-поиск на естественном языке по базе из 100 000 товарных позиций. Главные условия — сохранение 100% точности при числовой фильтрации (по цене и физическим характеристикам) и обновление данных в пределах жесткого 5-минутного окна.
В чем сложность классического подхода:
Стандартным выбором для подобных задач считается архитектура RAG (Retrieval-Augmented Generation). В ней текстовые описания товаров кодируются в векторные эмбеддинги, а затем сопоставляются с вектором запроса покупателя.
Однако на практике этот метод столкнулся с серьезными ограничениями: индексация динамически меняющегося ассортимента занимала до 60 минут и требовала дорогостоящих GPU-серверов. Кроме того, этот подход перегружал оперативную память (свыше 4 ГБ RAM) и регулярно выдавал «галлюцинации» — неточные результаты при попытке жестко ограничить выборку по стоимости или размерам.
Для решения этих проблем команда разработчиков под руководством Евгения Демидова спроектировала альтернативную гибридную поисковую систему. Было решено полностью отказаться от ресурсоемкой векторизации базы данных, а большую языковую модель (LLM) задействовать исключительно в роли лингвистического переводчика пользовательских намерений. Реализация проекта прошла в три шага.
Проблема: При парсинге тяжелого XML-файла каталога (размером более 500 МБ) стандартные библиотеки выстраивали полное DOM-дерево в памяти. Это требовало более 4 ГБ ОЗУ и регулярно приводило к аварийной остановке сервера из-за нехватки RAM (Out-of-Memory).
Решение: Разработчики написали кастомный потоковый парсер на основе SAX/streaming подхода. XML-файл считывается последовательно, и данные порциями (батчами) отправляются напрямую в документоориентированную СУБД MongoDB. Это позволило отказаться от тяжелой векторизации с применением GPU и снизило нагрузку на ОЗУ до минимума.
Проблема: Большие языковые модели склонны выдумывать факты («галлюцинировать») или рекомендовать товары из собственных устаревших баз знаний, искажая актуальные цены, бренды и информацию о наличии на складе.
Решение: Был создан жесткий системный промпт. Когда покупатель вводит запрос в свободной форме (например, «мне нужна узкая стиралка до 40 тысяч рублей и глубиной до 45 см»), нейросеть не ищет товары в своей памяти. Она работает как переводчик: извлекает параметры (тип товара: стиральная машина, цена <= 40 000, глубина <= 45) и конвертирует неструктурированный текст в строгий структурированный JSON-объект.
Проблема: Требовалось совместить строгую математическую точность традиционных баз данных с "живыми", персонализированными ответами искусственного интеллекта.
Решение: Полученный от LLM структурированный JSON-запрос отправляется напрямую в СУБД. База данных мгновенно проводит детерминированную фильтрацию по числовым диапазонам (что дает 100% попадание в заданные габариты и бюджет) и лексический поиск.
Итоговая компактная выборка (всего 3–5 наиболее подходящих позиций) передается обратно в LLM. Модель легко умещает этот объем в контекстное окно и формирует для покупателя естественный, аргументированный ответ, рассказывая о плюсах предложенных вариантов.
Тестирование новой архитектуры на демо-стенде Holodos.shop подтвердило ключевые преимущества гибридной модели перед стандартным векторным RAG:
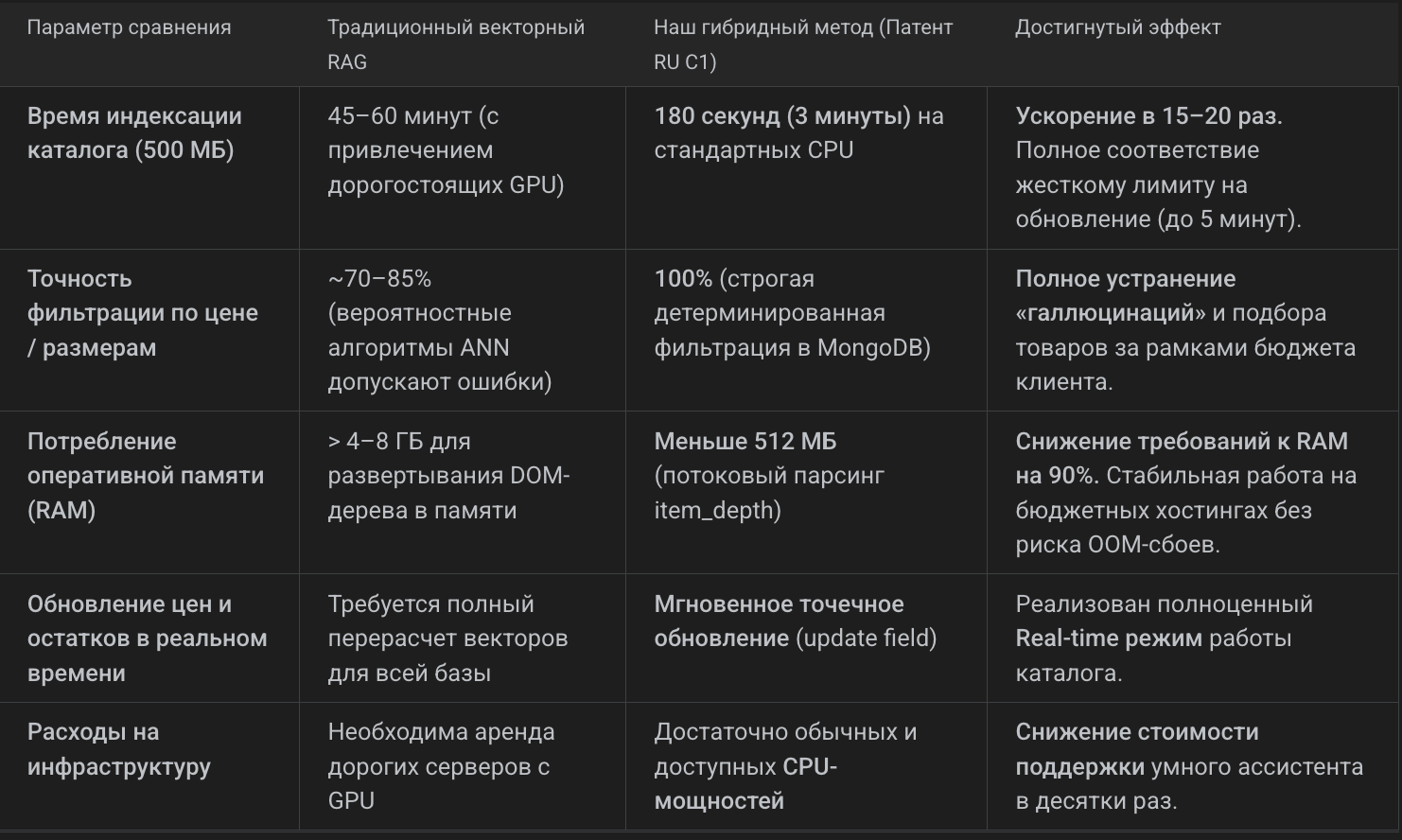
Индексация ускорилась в 20 раз: время обработки базы на 100 000 товаров сократилось с 1 часа до 3 минут, что позволило легко укладываться в обязательный 5-минутный интервал обновлений.
100% точность фильтрации: полностью решена проблема с предложением неподходящих по цене или габаритам товаров.
Нагрузка на RAM снизилась на 90%: объем потребляемой памяти при парсинге сократился с 4 ГБ до 512 МБ, что застраховало систему от падений из-за ошибок Out-of-Memory.
Сокращение инфраструктурных трат: отпала необходимость в дорогой аренде серверов с GPU для векторизации данных — система стабильно функционирует на стандартных CPU-процессорах.
Быстрый отклик: время обработки пользовательского поискового запроса в режиме реального времени составляет всего 1.5–2 секунды.

Евгений Демидов
Генеральный директор (CEO)
Успешные результаты внедрения гибридного метода доказали, что эффективные ИИ-технологии в ритейле могут быть доступными и не требовать колоссальных затрат на инфраструктуру. Чтобы закрепить уникальность нашей разработки и официально защитить интеллектуальную собственность, мы направили проект на регистрацию в Роспатент. Мы уверены, что этот подход станет новым стандартом оптимизации для рынка e-commerce.
 MongoDB
MongoDB
 Docker
Docker
 Node.js
Node.js
 Yandex DataLens
Yandex DataLens
 Grafana
Grafana
 NGINX
NGINX
 Gemini
Gemini
 DeepSeek
DeepSeek
