


Тендеры и лиды
Информация
При приеме сотрудника в офис на должность программиста, работодатель испытывает кандидата не только вопросами о навыках, но и всевозможными логическими задачами, IT-кейсами и заданиями по разработке для профессиональных программистов.
Как правило, список этих задач у работодателей совпадает, а значит, мы можем подготовиться к любому собеседованию!
Издание Tproger собрало воедино все самые интересные и популярные задачи для программистов, которые могут встретиться вам на собеседовании. С разрешения этого издания мы решили перепубликовать эту подборку.
1. Есть однонаправленный список из структур. В нём random указывает на какой-то еще элемент этого же списка. Требуется написать функцию, которая копирует этот список с сохранением структуры (т.е. если в старом списке random первой ноды указывал на 4-ю, в новом списке должно быть то же самое – рандом первой ноды указывает на 4-ю ноду нового списка). O(n), константная дополнительная память + память под элементы нового списка. Нельзя сразу выделить память под все данные одник куском т.е. список должен быть честным, разбросанным по частям, а не единым блоком, как массив.
Вот один из вариантов решения. Делаем обход списка, создаём дубликаты узлов и вставляем их по next, получая 2*N элементов, каждый нечётный ссылается на свой дубликат. Делаем второй обход списка, в каждом чётном узле random = random.next. Делаем третий обход списка, в каждом узле next = next.next.
Есть ещё один вариант от Пашки Джиоева.
Node *copyList(Node *head)
{
for (Node* cur = head; cur != NULL; cur = cur->next) {
Node* dup = (Node*)malloc(sizeof(Node));
dup->data = cur->data;
dup->next = cur->random;
cur->random = dup;
}
Node* result = head->random;
for (Node* cur = head; cur != NULL; cur = cur->next) {
Node* dup = cur->random;
dup->random = dup->next->random;
}
for (Node* cur = head; cur != NULL; cur = cur->next) {
Node* dup = cur->random;
cur->random = dup->next;
dup->next = cur->next ? cur->next->random : NULL;
}
return result;
}
Node *copyList(Node *head)
{
for (Node* cur = head; cur != NULL; cur = cur->next) {
Node* dup = (Node*)malloc(sizeof(Node));
dup->data = cur->data;
dup->next = cur->random;
cur->random = dup;
}
Node* result = head->random;
for (Node* cur = head; cur != NULL; cur = cur->next) {
Node* dup = cur->random;
dup->random = dup->next->random;
}
for (Node* cur = head; cur != NULL; cur = cur->next) {
Node* dup = cur->random;
cur->random = dup->next;
dup->next = cur->next ? cur->next->random : NULL;
}
return result;
}
2. Классическая задачка с собеседований в Google. На доске записаны числа, вам нужно ответить на вопрос: какое число идёт дальше?
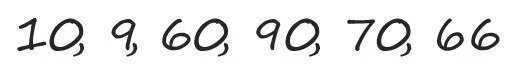
Чаще всего все пытаются отыскать – безуспешно – какую-либо закономерность в серии чисел, которая кажется совершенно бессмысленной. Но здесь нужно забыть математику. Произнесите эти числа на английском (см. рисунок), окажется, что они расположены в порядке возрастания числа букв, содержащихся в их написании.
Теперь приглядитесь еще более внимательно к этой серии. 10 – не единственное число из трёх букв. На этом месте могло бы быть 1, 2 и 6 (one, two и six). То же можно сказать и про 9, подойдут 0, 4 и 5 (zero, four и five). Таким образом можно сделать вывод, что в список включены самые крупные числа из тех, что можно выразить словами с заданным числом букв.
Так какой будет правильный ответ? Очевидно, что в числе, следующем за 66, должно быть девять букв (не считая возможного дефиса), и оно должно быть самым крупным в своём роде. Немного подумав, можно сказать, что ответ будет 96 (ninety-six). Вы понимаете, что сюда не подходят числа, превышающие 100, поскольку для «one hundred» уже нужно десять букв.
Может быть, у вас возникнет вопрос, почему в приведённом списке на месте 70 не стоит сто (hundred), или миллион, или миллиард, для написания которых также нужно семь букв. Скорее всего потому, что на правильном английском языке говорится не «сто», а «одна сотня», то же относится и к двум другим случаям.
Казалось бы, всё, вот он правильный ответ. В Google его считают приемлемым, но не самым совершенным. Есть число побольше:
10 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000,
которое записывается как «one googol» (девять букв).
Однако и это еще не самый лучший вариант. Идеальный ответ: «ten googol», десять гуголов.
Хотите узнать историю этого ответа? Погуглите;)
3. Допустим, вы летите из Москвы во Владивосток, а затем обратно, при полном безветрии. Затем вы совершаете точно такой же перелёт, но на этот раз на п ротяжении всего перелёта дует постоянный западный ветер: в одну сторону попутный, в обратную — лобовой.
Как изменится суммарное время перелёта туда-обратно?
Уменьшится
Увеличится
Не изменится
Обычно после прочтения задачи возникает желание заявить, что влиянее ветра в целом нулевое. Встречный ветер замедлит движение в одном направлении, но в обратном пути он будет дуть вам в спину, что позволит преодолеть путь быстрее. В целом это так, но будет ли при этом время полёта таким же?
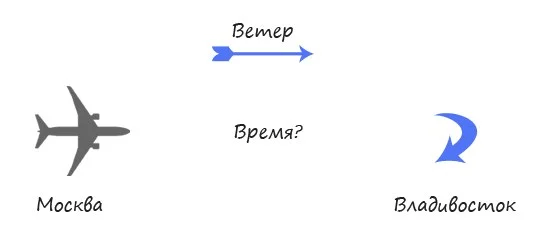
Представим самолёт, который летает со скоростью 800 км/ч. Так случилось, что из-за погодной аномалии возник поток воздуха, дующий с запада также со скоростью 800 км/ч. При полёте на восток это создаст дополнительную силу и вы сможете прибыть во Владивосток вдвое быстрее. Но при обратном полёте, даже если самолёт поднимется в воздух, его скорость относительно земли будет нулевой. Самолёт никогда не вернётся, суммарное время полёта будет бесконечным.
Если ориентироваться на этот предельный случай, то легко понять в чём трудность. При 5 часовом полёте попутный ветер может сэкономить вам максимум 5 часов, но встречный может стоить целой вечности. Этот базовый принцип верен при любом ветре. Ветер, дующий со скоростью 400 км/ч сократит время полёта в одном направлении примерно на 1.67 часа, но добавит 5 часов при полёте в другом направлении.
Вывод: постоянно дующий ветер всегда увеличивает общее время полёта туда и обратно.
Вопрос к подписчикам на засыпку: как изменится время при таком же перелёте, если ветер будет дуть с севера т.е. под прямым углом к направлению полёта?
4. Что не так в этом отрывке кода на С++?
operator int() const {
return *this;
}
А вот полный код для проверки.
class Foo {
public:
operator int() const {
return *this;
}
};
int main() {
Foo foo;
int i = foo;
return 0;
}
Он скомпилируется, хотя некоторые компиляторы могут кинуть warning, сразу же объясняющий в чём суть ошибки. Но вот при запуске вы словите stack overflow. Дело в том, что operator int будет пытаться привести возвращаемое значение к типу int, что вполне можно сделать, ведь для текущего объекта у нас есть замечательный operator int, который это и делает. Т.е. функцию вызовет сама себя и будет продолжать это делать рекурсивно, пока не переполнится стек.
5. Задача, которая была популярна в своё время на собеседованиях в Amazon. Мы русифицировали её, но смысл остался тот же. Вам нужно продолжить последовательность.
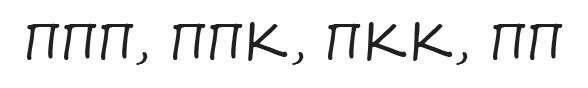
Вот один из возможных ответов на эту задачу. Последовательности сопоставлены буквы алфавита, закодированные в набор «П» и «К» — некоторых характеристик. Нужно найти что-то, чего в букве А три, в Б — две и т.д. Тут подходит количество прямых штрихов и кривых. Далее несложно догадаться, что букве Д соответствует, например, «ППППП», в случае её написания как на предложенном рисунке.
Последовательности сопоставлены буквы алфавита, закодированные в набор «П» и «К» — некоторых характеристик. Нужно найти что-то, чего в букве А три, в Б — две и т.д. Тут подходит количество прямых штрихов и кривых. Далее несложно догадаться, что букве Д соответствует, например, «ППППП», в случае её написания как на предложенном рисунке.
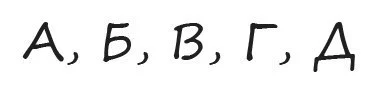
В комментариях к посту с задачей можно было найти множество интересных решений, которые перечислены ниже.
Оба алгоритма работают при проходе с конца строки.
{КК -> П; П -> К}
Ответ: ПК, КК, П, К
{ПП -> ПК; КК -> П}
Ответ: ПК
П — это 1, К — это 0.
Тогда закономерность в десятичной системе счисления будет иметь вид:
7 (ППП — 111),
6 (=7-1) (ППК — 110),
4 (=6-2) (ПКК — 100),
3 (=4-1) (ПП — 11),
а значит, далее следуют
1 (=3-2) (1 — П) и
(=1-1) (0 — К).
Ответ: П, К.
Существует цикл заполнения строки буквами К с конца, при этом, когда остается всего одна П (очевидно, слева), то вся строка преобразуется к строке из букв П, но на одну меньше, т.е.:
ППП
заполняем буквами К с конца
ППК
ПКК
осталась одна П, уменьшим длину
ПП
ПК
снова укорачиваем
П
Ответ: ПК, П
Забавный вариант: П — пусть, К — конец, тогда можно построить аналогию с открывающимися-закрывающимися скобками :) Закономерность не найдена.
UPD. Был предложен вариант рассматривать всю последовательность букв как единую скобочную последовательность:
((( (() ()) (( )) )))
ППП ППК ПКК ПП ККК КК
или
ППП ППК ПКК ПП КК ККК
Ответ: ККККК (в разных вариантах: КК, ККК или ККК, КК и т.п.)
Посчитаем количество «дырок в буквах»:
ППП — 3
ППК — 5
ПКК — 7
ПП — 2
Заметим, что все это — простые (т.е. не составные) числа до 10. Заметим, что есть еще только одно не составное число, меньшее 10 — это единица.
Ответ: П
П — это -1. К — это 1. Вариант наоборот, естественно, также подойдет. Тогда рассмотрим их произведения:
ППП = -1
ППК = 1
ПКК = -1
ПП = 1
вариантов продолжения несколько, автор предложил такой:
ПК = -1
КК = 1
П = -1
К = 1
Ответ: ПК, КК, П, К
П = 15, К = 10. Естественно, подойдут любые другие числа такие, что П:К = 3:2. Рассмотрим ряд:
ППП: П+П+П = 45
ППК: П+П+К = 40
ПКК: П+К+К = 35
ПП = 30
в качестве продолжения напрашиваются:
ПК = 25
КК = 20
П = 15* К = 10
Ответ: ПК, КК, П, К
Вариант с хронологией выпуска девайсов:
ППП — первое промышленное производство, или первое производство процессоров
ППК — первый персональный компьютер
ПКК — первый карманный компьютер
ПП — первый планшет
ПС — первый смартфон
Ответ: ПС
К сожалению, закономерности найти никто не смог. Может быть, это удастся вам?
Занимательно то, что при разных вариантах решения очень часто появлялся ответ ПК, КК, П, К…
6. Как это вычислить, не пользуясь калькулятором? Можете дать приблизительный ответ?
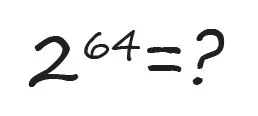
Приведём один из вариантов возможных рассуждений. Любой инженер знает, что 210 = 1024. Будем считать, что это приблизительно 1000. Умножим 210 на себя шесть раз и получим 260. Это около 1000 в шестой степени или 1018, также известное как квинтиллион. Осталось только умножить его на 24(16), чтобы получить искомое 264. Таким образом, очень приблизительный, но быстрый ответ будет 16 квинтиллионов.
На самом деле, чуть больше, т.к. 1024 на 2.4% больше 1000. Мы используем это приближение 6 раз, и поэтому ответ должен быть чуть более, чем на 12% больше. Это добавляет еще 2 квинтиллиона. Поэтому более точно будет 18 квинтиллионов.
Точное значение: 18 446 744 073 709 551 616
Есть еще один быстрый хак. Многие знают, что максимальное число 32-битного unsigned int — это что-то около 4 миллиардов т.е. 232 ? 4х109. Осталось только умножить это само на себя и получить около 16—17 квинтиллионов.
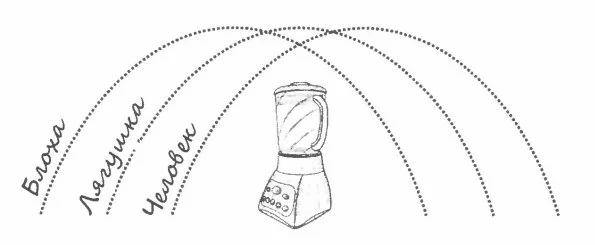
7. «Вас уменьшили до размеров 5-центовой монеты и бросили в блендер. Ваш вес уменьшился так, что плотность вашего тела осталась прежней. Лезвия начнут вращаться через 60 секунд. Ваши действия?»
Это классическая google-задачка, хороший разбор которой в рунете не так-то просто найти. Мы подготовили его для вас. Абсолютного правильного ответа нет, но есть те, которые явно лучше остальных.
Начнём с классификации наиболее популярных ответов, затем расскажем про тот, который считается лучшим среди интервьюверов в Google.
Многие соискатели выдают один забавный ответ: «Так как блендер очень скоро включат, можно предположить, что в него положат какие-то продукты, и поэтому мне, может быть, лучше подставить свою шею под лезвие, чем задохнуться из-за паров той жижи, которая скоро появится в блендере».Если же говорить о часто встречающихся серьезных ответах, то лидерами являются такие.
Первый. Лечь как можно плотнее к днищу, чтобы лезвия крутились надо мной.
Второй. Встать с той стороны блендера, где крепятся лезвия. Возможно, между стенкой и устройством крепления есть зазор шириной в 5-центовую монету.
Третий. Залезть по лезвию на ось вращения и найти такое место, где при вращении лезвий можно сохранять равновесие. Схватиться покрепче. Итоговая центростремительная сила в этом случае будет близка к нулю, что и позволит удержаться.
Первые три варианта дают некоторый шанс на выживание, но что если лезвия будут крутиться долго? Или конструкция такова, что вас всё таки заденет остриём? И вообще, если вдуматься, кто и зачем вас бросил в блендер? Если это какие-то враждебные существа, которые собираются приготовить соус из человека, то ваши долгосрочные шансы на выживание будут очень небольшими при любом варианте.
Вот стандартные ответы интервьюверов на уточняющие вопросы: «По поводу враждебных существ не беспокойтесь». «Никакой жидкости добавлено не будет». «Крышки у блендера нет». «Исходите из того, что лезвия будут вращаться до тех пор, пока вы не погибните».
Четвертый подход отличается — нужно выбраться во вне. Интервьювер поинтересуется, как вы будете это делать. Одним из самых ярких ответов был такой: при очень малом весе вы сможете взобраться по стенке примерно так же, как это делают мухи.
Пятый, не самый оптимистичный, вариант — воспользоваться телефоном и позвонить или отправить sms с просьбой о помощи. Тут всё зависит от того, уменьшился ли так же ваш телефон, сможет ли он работать с базовой станцией (которая осталась прежней) и какова будет скорость реакции службы спасения (и будет ли вообще?).
Шестой вариант: разорвать одежду на полосы, чтобы сделать из них верёрвку и воспользоваться её, чтобы выбраться. Но реально ли это сделать за одну минуту? Как крепить верёвку сверху? И даже если это удастся, как потом спуститься вниз?
Есть и седьмой: использовать одежду и собственные усилия, чтобы как-то заблокировать (или даже сломать) лезвия или работу мотора. Но и здесь могут возникнуть проблемы.
Ни один из перечисленных ответов не принесёт вам в Google много баллов. Интервьюверы рассказывали, что лучший ответ, который они слышали был таким — выпрыгнуть из блендера.
Ух ты? В вопросе даётся важный ключ — слово «плотность». Эта подсказка наводит на мысль, что важны вес и объем тела (а на другие «нереалистичности» можно не обращать внимания) и что подходящий ответ должен строиться на простейших законах физики.
Короче: интервьювер хочет, чтобы вы сфокусировались на последствиях, связанных с изменением размера. Вы, вероятно, слышали, что муравей способен поднять вес, в 50 раз превышающий вес его тела. Это объясняется не тем, что его мускулы лучше, чем у человека, а тем, что муравей маленький. Вес любого живого существа пропорционален кубу его высоты. Сила мускулов и скелета, поддерживающего их, зависит от площади их поперечного сечения, которая пропорциональна квадрату высоты. Если вас уменьшить до 1/10 вашего роста, сила ваших мускулов уменьшится в сто раз, но ваш вес уменьшится еще больше — в тысячу раз. Про прочих равных условиях небольшие существа «сильнее».
В середине 1600-х годов Джованни Альфонсо Борелли, современник Галилео, предположил, что всё, что прыгает, поднимается примерно на одинаковую высоту. Подумайте хорошенько об этом. Если вы физически здоровы, то, вероятно, сможете подпрыгнуть сантиметров на 70. Эта высота не преграда и для других живых существ: лошади, кролика, лягушки, кузнечика или блохи. Разумеется, есть вариации, но общее правило именно такое: самые крутые баскетболисты NBA могут поднять свой центр тяжести примерно на такую же высоту, как и блоха.
Мускульная энергия в конечном счёте определяется химическими процессами: глюкозой и водородом, циркулирующем в крови, а также АТФ, имеющимся в клетках мускул. Количество любых хим. веществ пропорционально объему вашего тела т.е. если вы уменьшитесь до 1/n вашего размера, то мускульная энергия сократится в n? раз.
К счастью, вес уменьшится так же. Поэтому при размере в монетку, высота вашего прыжка (если не учитывать сопротивление воздуха) никак не изменится. Высота блендера примерно 30 см. Если вы можете сейчас перепрыгнуть через препятствие такой высоты, то удрать из блендера для вас не будет проблемой.
Возможно, вы спросите, как же упав потом с такой высоты вы не поломаете себе кости? Поверхность, которую вы теперь занимаете, составит 1/n? по сравнению с вами обычным, а вес сократится еще больше, до 1/n? прежнего. Соотношение площади поверхности к весу возрастёт в n раз, поэтому когда вы приземлитесь, никаких поврежений у вас не будет. Это объясняет, почему любое существо размером с мышь и менее может не беспокоиться и падать с любой высоты.
8. Вопрос по С++. Что за ошибка «pure virtual function call»? В какой ситуации она может быть сгенерирована? Предоставьте минимальный код, приводящий к ней.
Те, кто столкнулись с этой ошибкой в живом проекте и не знали про неё ранее, наверняка потратили немало времени на отлов этого бага. Разберём его по полочкам.
Как работает механизм виртуальных функций? Обычно он реализуется через «vtbl» (virtual table) — таблицу с указателями на функции. Каждый экземпляр класса, содержащего хотя бы одну виртуальную функцию имеет указатель __vtbl на таблицу vtbl для своего класса. В случае с абстрактным классом и чистой виртуальной функцией, указатель всё равно есть, но на стандартный обработчик __pure_virtual_func_called(), который и приводит к такой ошибке. Но как его вызвать, ведь прямая попытка будет отловлена уже на этапе компиляции?
#include <iostream>
class Base
{
public:
Base() { init(); }
~Base() {}
virtual void log() = 0;
private:
void init() { log(); }
};
class Derived: public Base
{
public:
Derived() {}
~Derived() {}
virtual void log() { std::cout << "Derived created" << std::endl; }
};
int main(int argc, char* argv[])
{
Derived d;
return 0;
}
Разберём, что происходит при инстанцировании экземпляра объекта класса-потомка, который содержит vtbl.
Шаг 1. Сконструировать базовую часть верхнего уровня:
Установить указатель __vtbl на vtbl родительского класса;
Сконструировать переменные экземпляра базового класса;
Выполнить тело конструктора базового класса.
Шаг 2. Наследуемая часть(-и) (рекурсивно):
Поменять указатель __vtbl на vtbl класса-потомка;
Сконструировать переменные класса-потомка;
Выполнить тело конструктора класса-потомка.
Теперь взглянем на пример на картинке. Несложно догадаться, что когда будет создаваться объект класса Derived, то на шаге выполнения конструктора базового класса, он сам по себе будет еще считаться базовым классом и его vtbl будет от базового класса. Обычно компиляторы не детектируют такое заранее и ошибка ловится только в runtime.
Вывод: избегайте вызовов виртуальных функций в конструкторах и деструкторах, причём как явных, так и через другие функции.
Почитать подробнее про это можно на artima.com или в книжке Скотта Майерса «Effective C++», совет номер 9.
9. В вашем распоряжении 10 тысяч серверов в дата-центре с возможностью удалённого управления и один день, чтобы получить миллион долларов. Что вы для этого сделаете?
Ответ можно давать в двух направлениях.
Первое состоит в том, чтобы воспользоваться возможностью произвести на интервьювера положительное впечатление — предложить ему ваш любимый, но не реализованный пока бизнес-план. В Microsoft, например, вас скорее всего внимательно и вежливо выслушают, а затем спросят: «Да, это интересно, но вы уверены, что сможете заработать миллион долларов уже в первый день?».
А вот ответ в стиле Google: продайте серверы, по крайней мере, за 100 долларов каждый. Это принесёт вам 1 миллион долларов или, что более вероятно, еще больше — 10 миллионов. Затем, если у вас есть какой-то великолепный бизнес-план, используйте эти деньги как стартовый капитал. Это позволит вам проработать достаточно долго и успеть заинтересовать одного из венчурных капиталистов (который достаточно умён и понимает, что великие идеи не позволяют заработать миллион долларов уже в первый день).
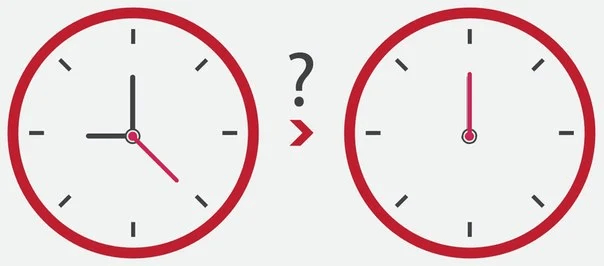
10. У вас есть аналоговые часы с секундной стрелкой. Сколько раз в день все три стрелки часов накладываются друг на друга?
Эта задача — вариант классического вопроса, задававшегося на собеседованиях в Microsoft, когда претендентов спрашивали, сколько раз в день часовая и минутная стрелки встречаются друг с другом. Посколько этот вопрос сейчас стал широко известен, интервьюверы начали использовать его разновидность.
Рассмотрим сначала вариант наиболее ожидаемого решения, математического. Во-первых, представьте ситуацию, когда часовая и минутная стрелки наложились. Все знают, что это происходит в полночь, затем приблизительно в 1:05, 2:10, 3:15 и так далее. Другими словами, они накладываются друг на друга каждый час, за исключением периода от 11:00 до 12:00. В 11:00 более быстрая минутная стрелка находится на 12, а более медленная часовая — на 11:00. До 12:00 дня они друг с другом не встретятся, и поэтому их наложения в районе 11 часов не будет.
Таким образом, за каждый 12-часовой период происходит 11 наложений. Они равномерно распределены во времени, поскольку обе стрелки двигаются с постоянной скоростью. Это означает, что интервалы между наложениями составляют 12/11 часа. Это эквивалентно 1 часу 5 минутам 27 и 3/11 секундам. Поэтому за каждый 12-часовой цикл наложения происходят в периоды, указанные на картинке.

Вернёмся к секундной стрелке. Её наложение на минутную возможно тогда, когда число минут совпадает с числом секунд. Точное наложение происходит в 00:00:00. В целом минутные и секундные стрелки накладыватся лишь на долю секунды. Например, в 12:37:37 секундная стрелка будет показывать на 37, отставая от минутной, которая в это время будет между 37 и 38 и отставать от часовой. Через мгновение минутная и секундная наложатся, но часовой возле них не будет. Т.е. наложения всех трёх стрелок не произойдет.
Секундная стрелка не наложится ни в одном из вариантов на картинке, за исключением полуночи и полудня. Это означает, что финальный ответ на вопрос: дважды в сутки.
А вот ответ, приветствуемый в Google. Секундная стрелка предназначена для показа коротких временных интервалов, а не для сообщения времени с точностью до секунды. Если она не синхронизирована с двумя другими стрелками, это вполне нормально. Под «синхронизацией» здесь понимается, что в полночь и полдень все три стрелки указывают точно на 12. Большинство аналоговых часов всех видов не позволяют вам точно установить секундную стрелку. Нужно было бы извлечь батарейку или подождать, если говорить о механических часах, когда закончится завод пружины, а затем, когда секундная стрелка остановлена, синхронизировать минутную и часовую стрелки друг с другом, после чего дождаться, когда наступит время, показанное на часах, чтобы вернуть батарейку или завести часы.
Чтобы все это проделать, нужно быть маньяком или фанатеть от пунктуальности. Но если вы всего этого не проделаете, секундная стрелка не будет показывать «реального» времени. Она будет отличаться от точных секунд на какую-то величину в случайном интервале, доходящем до 60 секунд. Учитывая случайные расходждения, шансов на то, что все три стрелки когда-либо встретятся, не существует. Этого не случается никогда.
11. В чём разница между string и String в C#?
Ответ на самом деле очень прост: string — это просто псевдоним (alias) для System.String т.е. технически, никакой разницы нет. Так же, как и нет разницы между int и System.Int32.
Что касается стиля оформления кода, то тут есть несколько советов.
Обычно рекомендуется использовать string, когда вы имеете в виду объект:
string name = "Jessica";
В противовес случаю, когда вам нужно обратиться именно к классу, например:
string msg = String.Format("Hi, {0}!", name);
По крайней мере этот тот стиль, которого придерживается Microsoft в своих примерах.
На картинке показан полный список псевдонимов. Единственный тип, который не имеет псевдонима — это System.IntPtr, его всегда нужно писать именно так.

Однако есть один случай, когда нужно обязательно использовать псевдонимы: в явных объявлениях типа для перечисления:
public enum Foo : UInt32 {} // Неправильно
public enum Bar : uint {} // Правильно
Также рекомендуем вам относится с осторожностью к типам, когда вы реализуете какой-либо API, который может использоваться клиентами на других языках. Например, метод ReadInt32 вполне однозначен, тогда как ReadInt — нет. Тот, кто использует ваш API может пользоваться языком, в котором int является 16 или 64-битным, что не совпадает с вашей реализацией. Этому совету отлично следуют разработчики .Net Framework, хорошие примеры можно найти в классах BitConverter, BinaryReader и Convert.
12. Вы играете в футбол на пустынном острове и хотите подбросить монетку, чтобы решить, какой команде достанется мяч. Единственная монета, что у вас есть, является гнутой, и поэтому вносит явные искажения в результат при подбрасывании. Как вы тем не менее можете использовать такую монету, чтобы принять справедливое решение?
Есть два варианта решения этой задачи.
Первый состоит в том, чтобы подбрасывать монету множество раз, чтобы определить процент выпадания орла и решки. После того как вы установите, например, что монета выпадает орлом в 54.7% случаев (с установленным пределом ошибки), вы используете этот факт, чтобы продумать ставку со множеством подбрасываний, при котором шансы на получение результата будут близки к желаемому.
Второй ответ куда проще: подбросьте монету дважды. Возможны четыре исхода: ОО, ОР, РО и РР (Р — решка, О — орёл). Поскольку монета «благосклонна» к одной стороне, шансы выпадения ОО не эквивалентны шансам РР. С другой стороны, вероятности выпадения ОР и РО должны быть одинаковы, независимо от степени «благосклонности» монеты. Одна команда ставит на ОР, вторая — на РО. Если выпадает ОО или РР, игнорируйте их результаты и бросайте еще два раза.
Помимо того, что эта схема проще, она к тому же и, бесспорно, справедлива. Первый же вариант, если говорить о точности, лишь приближается к шансам пятьдесят на пятьдесят.
13. Cколько мячей для гольфа войдет в школьный автобус?
Для справки: в Национальных стандартах транспотрных средств для школ в США на 1995 год указаны максимальные размеры школьного автобуса и равны 40 футам в длину и 8.5 футам в ширину. Стандартный диаметр мяча для гольфа — 1.69 дюйма с допуском 0.005 дюймов.
Очевидно, что это задача Ферми, где от вас требуется приблизительная прикидка, правдоподобная по порядку величины. Приведём пример таких рассуждений.
Школьный автобус, как и любое другое транспортное средство, должен по своим параметрам соответствовать дорожному полотну т.е. быть не намного шире, чем легковые авто. В фильмах мы видели, что в нём есть сиденья для четырёх детей (используются ли где-то такие автобусы в России? — прим. ред.), а также проход посередине. И есть место, где может стоять учитель. Будем исходить из того, что ширина автобуса около 2.5 метра, высота примерно 2 метра. Напомним, что точные цифры не так важны, важен порядок. Сколько рядов сидений в автобусе? Пусть будет 12. Каждому ряду необходимо около метра или чуть меньше, длину примем за 11 метров. Итого общий объём будет около 55 куб. метров.
Диаметр мяча для гольфа приблизительно 3 см. Будем считать, что ~3.3 см, чтобы 30 таких мячей, положенных в ряд, составили 100 см. Кубическая конструкция из 30х30х30 таких мячей, то есть 27 000 мячей, поместится в кубическом метре. Умножим это на 55, получится что-то около 1.5 млн.
Обратите внимание, что многие вопросы Ферми связаны со сферическими спортивными предметами, заполняющими автобусы, бассейны, самолёты или стадионы. Вы можете получить дополнительные баллы, если упомяните гипотезу Кеплера. В конце 1500-х годов сэр Уолтер Рейли попросил английского математика Томаса Хэрриота придумать более эффективный способ укладки пушечных ядер на кораблях британского военного флота. Хэрриот рассказал об этой задаче своему другу астроному Иоганну Кеплеру. Кеплер предположил, что самый плотный способ упаковки сфер уже и так применяется — при укладке пушечных ядер и фруктов. Первый слой кладётся просто рядом друг с другом в виде шестиугольной формы, второй в углублениях на стыках шаров нижнего слоя я и т.д. В крупной таре при таком варианте укладки максимальная плотность составит около 74%. Кеплер полагал, что это самый плотный вариант упаковки, но не смог этого доказать.
Гипотеза Кеплера, как её назвали позднее, оставалась великой нерешённой проблемой в течение нескольких столетий. В 1900 году Дэвид Гилберт составил известный список из 23 нерешённых математических задач. Некоторые люди утверждали, что им удалось доказать эту гипотезу, однако всех их решения на поверку оказывались неудачными и относились к числу неверных. Так длилось до 1998 года, когда Томас Хэйлс предложил сложное доказательство при помощи компьютера, которое подтвердило правоту Кеплера. Большинство специалистов уверены, что его результат в конечном счёте окажется верным, хотя его проверка не закончена.
Выше мы предположили, что каждый мяч для гольфа фактически лежит в кубе из прозрачного очень тонкого пластика так, что края куба равны диаметру мяча. Это означает, что мячи занимают около 52% пространства (Pi/6, если говорить точнее, можете подсчитать сами). Если вынуть мячи из воображаемого кубика, то можно поместить в заданный объем гораздо больше мячей, это проверенный эмпирически факт. Физики проделали эксперименты, заполняя стальными шариками крупные фляги и вычисляя плотность заполнения. Результат был от 55% до 64% использования пространства. Это более плотный вариант, чем применили мы, хотя он и не дотягивает до максимума Кеплера, равного примерно 74%. К тому же разброс результатов довольно большой.
Как же нам следует поступить? Укладывать шары строго идеально в реальности мы не сможем, это слишком абсурдно даже для ответа на абсурдный вопрос. Намного более реалистичная цель — плотность, достигаемая при периодическом потряхивании или помешивании контейнера. Вы можете добиться её, если будете распределять шары с помощью палки более равномерно. Это повысит плотность примерно на 20%, чем при варианте с кубической решёткой. Тем самым можно увеличить исходную оценку до 1.8 млн мячей.
14. Представьте себе вращающийся диск, например DVD. У вас есть в распоряжении черная (Ч) и белая (Б) краски. На краю диска установлен небольшой датчик, который определяет цвет под ним и выдает результат в виде сигнала. Как бы вы раскрасили диск, чтобы было возможно определить направление вращения по показаниям датчика?
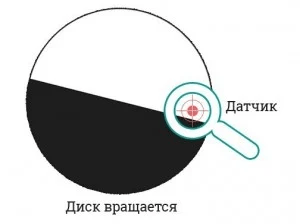
Дадим небольшое пояснение к задаче. Первое, что нужно иметь ввиду, это то, что нельзя наблюдать за самим диском. Например, вы сидите в офисе, а диск вращается в закрытой лаборатории. Единственная возможность определить направление вращения — использовать оцифрованные показания датчика, и ничего больше.
Датчик фиксирует цвет точки в непосредственном месте установки в последовательные моменты времени. Показания представляются в виде «ЧЧЧББ…». Задача сводится к такой раскраске диска, где последовательность показаний отличается при вращении в прямую и в противоположную стороны.
Дадим небольшое пояснение к задаче. Первое, что нужно иметь ввиду, это то, что нельзя наблюдать за самим диском. Например, вы сидите в офисе, а диск вращается в закрытой лаборатории. Единственная возможность определить направление вращения — использовать оцифрованные показания датчика, и ничего больше.
Датчик фиксирует цвет точки в непосредственном месте установки в последовательные моменты времени. Показания представляются в виде «ЧЧЧББ...». Задача сводится к такой раскраске диска, где последовательность показаний отличается при вращении в прямую и в противоположную стороны, то есть последовательность не должна быть палиндромом.
Палиндромы — это такие слова или фразы, которые читаются задом наперед так же как и обычным образом. Например: топот, ротор, «лезу в узел». Придумать палиндром не так легко, в то время как привести пример асимметричной фразы очень просто. Может показаться, что так же легко придумать такую раскраску диска, однако возникает две сложности. Во-первых, в постановке задачи мы ограничиваемся только 2 буквами Ч и Б. Во-вторых, нам нужно избавиться от циклического палиндрома, так же, как и от обычного.
Например, нельзя покрасить половину диска в белый цвет, а вторую половину в черный. Показания будут как «ЧБЧБЧБЧБЧБ». В обычном смысле это не палиндром, но это циклический палиндром. То есть, если соединить начало и конец последовательности, то получим одинаковые показания при вращении как по часовой стрелке, так и против. При наблюдении за бесконечным потоком показаний нельзя сказать, в каком направлении вращается такой диск.
Не все регулярные последовательности являются циклическими палиндромами. Если бы нам были доступны 3 цвета: черный (Ч), белый (Б) и красный (К), то можно нарисовать 3 одинаковых по площади сектора разных цветов. Тогда по часовой стрелке показания были бы вроде «ЧЧЧКККБББ», а наоборот «ЧЧЧБББККК». В данном случае они легко различимы. В первых показаниях красный сразу следует за черным, а на вторых показаниях красный следует за белым.
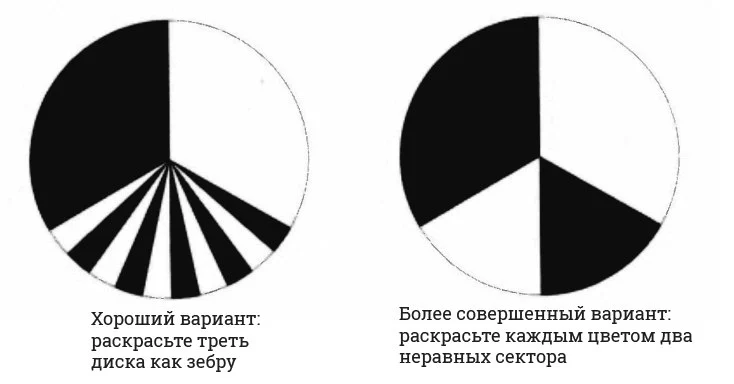
Изначальная постановка задачи не допускает использование третьего цвета, но позволяет взамен использовать раскраску «зебру». Один из трех секторов можно закрасить множеством тонких полос с чередованием черного и белого цветов. Тогда хорошо заметно, когда частые полосы идут после черного сектора (по часовой стрелке) или после белого сектора (против часовой стрелки).
Это решение можно улучшить. Ведь вам не сказано, насколько быстро вращается диск и с какой частотой датчик в состоянии регистрировать изменения цвета (грубо говоря, задержка экспозиции). Диск может вращаться настолько быстро, что датчик будет регистрировать цвет только одного места на диске и пропускать все остальные. Это может ввести в заблуждение при интерпретации полученных показаний.
Очевидно желание сделать меньшее число полос, а сами полосы шире, насколько это возможно. На самом деле достаточно 2 полосы в «полосатом секторе», если, конечно, они противоположного цвета, по отношению к смежным секторам.
При такой раскраске и при условии возможности снятия 6 показаний за 1 оборот, поворот по часовой стрелке будет давать последовательность вроде «ЧЧБЧББ», а против часовой стрелки, эта последовательность будет идти в обратном порядке.
Также представляет интерес похожая задача, где диск уже раскрашен на две половинки в черный и белый цвета. Допускается установка неограниченного числа фиксированных датчиков у края диска. Вопрос: сколько датчиков требуется установить для определения направления вращения?
Все что мы может получить с одного датчика (при новой постановке задачи) — это соотношение черного и белого в покраске, что и так известно (50/50). Если мы возьмем 2 датчика и разместим их диаметрально противоположно, то вновь не получим ничего полезного, так как второй датчик всегда будет давать противоположное показание.
Вместо этого, можно разместить 2 датчика рядом, например первый датчик в произвольном месте, а второй в 10 градусах по часовой стрелке от первого. Большую часть времени оба датчика будут давать одинаковые показания, однако, при смене цветов, один датчик заметит изменение раньше, чем другой.
Показания датчиков могут выглядеть следующим образом:
Датчик 1: ЧЧБББ
Датчик 2: ЧЧЧББ
Такие наблюдения означают, что переход Ч-Б фиксируется первым датчиком раньше, чем вторым. В этом случае переход Ч-Б и сам диск должен вращаться по часовой стрелке. Если это изменение, наоборот, фиксируется вторым датчиком раньше чем первым, то вращение происходит против часовой стрелки.
15. У вас есть исходный код приложения на языке С, которое аварийно завершается после запуска. После десяти запусков в отладчике вы обнаруживаете, что каждый раз программа падает в разных местах. Приложение однопоточное и использует только стандартную библиотеку С. Какие ошибки могут вызвать падение приложения? Как вы проверите каждую?
Вопрос в значительной степени зависит от типа диагностируемого приложения. Однако мы можем привести некоторые общие причины случайных отказов.
«Случайная» переменная: приложение может использовать некоторое «случайное» значение или переменную-компонент, которая не имеет конкретного точного значения. Примеры: ввод данных пользователем, случайное число, сгенерированное программой, время суток и т.д.
Неинициализированная переменная: приложение может использовать неинициализированную переменную, которая в некоторых языках программирования по умолчанию может принимать любое значение. Таким образом, код может каждый раз выполняется по-разному.
Утечка памяти: программа, возможно, исчерпала все ресурсы. Другие причины носят случайный характер и зависят от количества запущенных в определенное время процессов. Сюда же можно отнести переполнение кучи или повреждение данных в стеке.
Внешние причины: программа может зависеть от другого приложения, машины или ресурса. Если таких связей много, программа может «упасть» в любой момент.
Чтобы найти проблему, нужно максимально изучить приложение. Кто его запускает? Что делают пользователи? Что делает само приложение?
Хотя приложение падает не в каком-то конкретном месте, возможно, само падение связано с конкретными компонентами или сценариями. Например, приложение может оставаться работоспособным в момент запуска, а сбой происходит только после загрузки файла. Или же сбой происходит в зоне ответственности компонентов низкого уровня, например при файловом вводе-выводе.
Можно делать выборочное тестирование. Закройте все остальные приложения. Очень внимательно отслеживайте все свободные ресурсы. Если есть возможность отключить части программы, сделайте это. Запустите программу на другой машине и посмотрите, возникнет ли эта ошибка. Чем больше мы можем изменить, тем легче найти проблему.
Кроме того, можно использовать специальные инструменты проверки специфических ситуаций. Например, чтобы исследовать причину появления ошибок 2-го типа, можно использовать отладчики, проверяющие неинициализированные переменные. Подобные задачи позволяют вам продемонстрировать не только умственные способности, но и стиль вашей работы. Вы постоянно перескакиваете с одного на другое и выдвигаете случайные предположения? Или вы подходите к решению задачи логически? Хотелось бы надеяться на последнее.
16. Найдите ошибки в следующем коде.
unsigned int i;
for (i = 100; i >= 0; --i)
printf("%d
", i);
В коде есть две ошибки.
Первая заключается в том, что используется тип unsigned int, который работает только со значениями, большими или равными нулю. Поэтому условие цикла for всегда будет истинно, и цикл будет выполняться бесконечно.
Корректный код, выводящий значения всех чисел от 100 до 1, должен использовать условие i > 0. Если нам на самом деле нужно вывести нулевое значение, то следует добавить дополнительный оператор printf после цикла for.
unsigned int i;
for (i = 100; i > 0; --i)
printf("%d\n", i);
printf("%d\n", i);
Вторая ошибка — вместо %d следует использовать %u, поскольку мы выводим целые значения без знака.
unsigned int i;
for (i = 100; i > 0; --i)
printf("%u\n", i);
Теперь этот код правильно выведет список чисел от 100 до 1, в убывающем порядке.
17. Объясните, что делает этот код.
((n & (n – 1)) == 0)
Вернемся к «истокам».
Что означает A & B == 0?
Это означает, что А и B не содержат на одних и тех же позициях единичных битов. Если n & (n - 1) == 0, то n и n - 1 не имеют общих единиц.
На что похоже n - 1 (по сравнению с n)?
Попытайтесь проделать вычитание вручную (в двоичной или десятично системах).
Что произойдет?
Когда вы отнимаете единицу, посмотрите на младший бит. 1 вы замените на 0. Но если там стоит 0, то вы должны заимствовать из старшего бита. Вы изменяете каждый бит с 0 на 1, пока не дойдете до 1. Затем вы инвертируете единицу в ноль, — все готово.
Таким образом, можно сказать, что n - 1 будет совпадать с n в каких-то битах, за исключением того, что младшим нулям в n соответствуют единицы в n - 1, а последний единичный бит в n становится нулем в n - 1.
Что значит n & (n - 1) == 0?
n и n - 1 не содержат общих единиц. Предположим, они имеют вид:
n = abcde1000
n - 1 = abcde0111
abcde должны быть нулевыми битами, то есть n имеет вид 000001000. Таким образом, значение n — степень двойки.
Итак, наш ответ: логическое выражение ((n & (n-1)) == 0) истинно, если n является степенью двойки или равно нулю.
18. Дано 100-этажное здание. Если яйцо сбросить с высоты N-го этажа (или с большей высоты), оно разобьется. Если его бросить с любого меньшего этажа, оно не разобьется. У вас есть два яйца. Найдите N за минимальное количество бросков.
Обратите внимание, что независимо от того, с какого этажа мы бросаем яйцо №1, бросая яйцо №2, необходимого использовать линейный поиск (от самого низкого до самого высокого этажа) между этажом «повреждения» и следующим наивысшим этажом, при броске с которого яйцо останется целым. Например, если яйцо №1 остается целым при падении с 5-го по 10-й этаж, но разбивается при броске с 15-го этажа, то яйцо №2 придется (в худшем случае) сбрасывать с 11-го,12-го,13-го и 14-го этажей.
Предположим, что мы бросаем яйцо с 10-го этажа, потом с 20-го…
Если яйцо №1 разбилось на первом броске (этаж 10-й), то нам в худшем случае приходится проделать не более 10 бросков.
Если яйцо №1 разбивается на последнем броске (100-й этаж), тогда у нас впереди в худшем случае 19 бросков (этажи 10-й, 20-й, …, 90-й, 100-й, затем с 91-го до 99-го).
Это хорошо, но давайте уделим внимание самому плохому случаю. Выполним балансировку нагрузки, чтобы выделить два наиболее вероятных случая.
В хорошо сбалансированной системе значение Drops(Egg1) + Drops(Egg2) будет постоянным, независимо от того, на каком этаже разбилось яйцо №1.
Допустим, что за каждый бросок яйцо №1 «делает» один шаг (этаж), а яйцо №2 перемещается на один шаг меньше.
Нужно каждый раз сокращать на единицу количество бросков, потенциально необходимых яйцу №2. Если яйцо №1 бросается сначала с 20-го, а потом с 30-го этажа, то яйцу №2 понадобится не более 9 бросков. Когда мы бросаем яйцо №1 в очередной раз, то должны снизить количество бросков яйца №2 до 8. Для этого достаточно бросить яйцо №1 с 39 этажа.
Мы знаем, что яйцо №1 должно стартовать с этажа X, затем спуститься на X-1 этажей, затем — на X-2 этажей, пока не будет достигнуто число 100.
Можно вывести формулу, описыващее наше решение: X + (X — 1) + (X — 2) + … + 1 = 100 -> X = 14.
Таким образом, мы сначала попадаем на 14-й этаж, затем на 27-й, затем 39-й. Так что 14 шагов — худший случай.
Как и в других задачах максимизации/минимазиции, ключом к решению является «балансировка худшего случая».
19. Продолжаем задачки по С/С++. Что означает ключевое слово volatile и в каких ситуация оно может быть применено? Если даже помните формальное значение, попробуйте привести пример ситуации, где volatile на самом деле будет полезно.
Ключевое слово volatile информирует компилятор, что значение переменной может меняться извне. Это может произойти под управлением операционной системы, аппаратных средств или другого потока. Поскольку значение может измениться, компилятор каждый раз загружает его из памяти.
Волатильную целочисленную переменную можно объявить как:
int volatile х;
volatile int х;
Чтобы объявить указатель на эту переменную, нужно сделать следующее:
volatile int *х;
int volatile *х;
Волатильный указатель на неволатильные данные используется редко, но допустим:
int *volatile х;
Если вы хотите объявить волатильный указатель на волатильную область памяти, необходимо сделать следующее:
int volatile *volatile х;
Волатильные переменные не оптимизированы, что может пригодиться. Представьте следующую функцию:
int opt = 1;
void Fn(void) {
start:
if (opt == 1)
goto start;
else
break;
}
На первый взгляд кажется, программа зациклится. Компилятор может оптимизировать ее следующим образом:
void Fn(void) {
start:
int opt = 1;
if (true)
goto start;
)
Вот теперь цикл точно станет бесконечным. Однако внешняя операция позволит записать 0 в переменную opt и прервать цикл.
Предотвратить такую оптимизацию можно с помощью ключевого слова volatile, например объявить, что некий внешний элемент системы изменяет переменную:
volatile int opt = 1;
void Fn(void) {
start:
if (opt == 1)
goto start;
else
break;
}
Волатильные переменные используются как глобальные переменные в многопотоковых программах — любой поток может изменить общие переменные. Мы не хотим оптимизировать эти переменные.
20. У вас есть отсортированная матрица размера MxN. Предложите алгоритм поиска в ней произвольного элемента. Под отсортированной матрицей будем понимать такую матрицу, строки и столбцы которой отсортированы (см. пример).

Под отсортированной матрицей будем понимать такую матрицу, строки и столбцы которой отсортированы.
Чтобы найти нужный элемент, можно воспользоваться бинарным поиском по каждой строке. Алгоритм потребует O(M log(N)) времени, так как необходимо обработать М столбцов, на каждый из которых тратится O(log(N)) времени. Также можно обойтись и без сложного бинарного поиска. Мы разберем два метода.
Прежде чем приступать к разработке алгоритма, давайте рассмотрим простой пример:
| 15 | 20 | 40 | 85 |
| 20 | 35 | 80 | 95 |
| 30 | 55 | 95 | 105 |
| 40 | 80 | 100 | 120 |
Допустим, мы ищем элемент 55. Как его найти?
Если мы посмотрим на первые элементы строки и столбца, то можем начать искать расположение искомого элемента. Очевидно, что 55 не может находиться в столбце, который начинается со значения больше 55, так как в начале столбца всегда находится минимальный элемент. Также мы знаем, что 55 не может находиться правее, так как значение первого элемента каждого столбца увеличивается слева направо. Поэтому, если мы обнаружили, что первый элемент столбца больше х, нужно двигаться влево.
Аналогичную проверку можно использовать и для строк. Если мы начали со строки, значение первого элемента которой больше х, нужно двигаться вверх.
Аналогичные рассуждения можно использовать и при анализе последних элементов столбцов или строк. Если последний элемент столбца или строки меньше х, то, чтобы найти х, нужно двигаться вниз (для строк) или направо (для столбцов). Это так, поскольку последний элемент всегда будет максимальным.
Давайте используем все эти наблюдения для построения решения:
Если первый элемент столбца больше х, то х находится в колонке слева.
Если последний элемент столбца меньше х, то х находится в колонке справа.
Если первый элемент строки больше х, то х находится в строке, расположенной выше.
Если последний элемент строки меньше х, то х находится в строке, расположенной ниже.
Давайте начнем со столбцов.
Мы должны начать с правого столбца и двигаться влево. Это означает, что первым элементом для сравнения будет [0][с-1], где с — количество столбцов. Сравнивая первый элемент столбца с х (в нашем случае 55), легко понять, что х может находиться в столбцах 0,1 или 2. Давайте начнем с [0][2].
Данный элемент может не являться последним элементом строки в полной матрице, но это конец строки в подматрице. А подматрица подчиняется тем же условиям. Элемент [0][2] имеет значение 40, то есть он меньше, чем наш элемент, а значит, мы знаем, что нам нужно двигаться вниз.
Теперь подматрица принимает следующий вид (серые ячейки отброшены):
| 15 | 20 | 40 | 85 |
| 20 | 35 | 80 | 95 |
| 30 | 55 | 95 | 105 |
| 40 | 80 | 100 | 120 |
Мы можем раз за разом использовать наши правила поиска. Обратите внимание, что мы используем правила 1 и 4.
Следующий код реализует этот алгоритм:
public static boolean findElement(int[][] matrix, int elem) {
int row = 0;
int col = matrix[0].length - 1;
while (row < matrix.length && col >= 0) {
if (matrix[row][col] == elem) {
return true;
} else if (matrix[row][col] > elem) {
col--;
} else {
row++;
}
}
return false;
}
Другой подход к решению задачи — бинарный поиск. Мы получим более сложный код, но построен он будет на тех же правилах.
Давайте еще раз обратимся к нашему примеру:
| 15 | 20 | 70 | 85 |
| 20 | 35 | 80 | 95 |
| 30 | 55 | 95 | 105 |
| 40 | 80 | 100 | 120 |
Мы хотим повысить эффективность алгоритма. Давайте зададимся вопросом: где может находиться элемент?
Нам сказано, что все строки и столбцы отсортированы. Это означает, что элемент [i][j] больше, чем элементы в строке i, находящиеся между столбцами 0 и j и элементы в строке j между строками 0 и i-1.
Другими словами:
a[i][0] <= a[i][1] <= ... <= a[i][j-i] <= a[i][j]
a[0][j] <= a[1][j] <= ... <= a[i-1][j] <= a[i][j]
Посмотрите на матрицу: элемент, который находится в темно-серой ячейке, больше, чем другие выделенные элементы.
| 15 | 20 | 70 | 85 |
| 20 | 35 | 80 | 95 |
| 30 | 55 | 95 | 105 |
| 40 | 80 | 100 | 120 |
Элементы в белых ячейках упорядочены. Каждый из них больше как левого элемента, так и элемента, находящегося выше. Таким образом, выделенный элемент больше всех элементов, находящихся в квадрате.
| 15 | 20 | 70 | 85 |
| 20 | 35 | 80 | 95 |
| 30 | 55 | 95 | 105 |
| 40 | 80 | 100 | 120 |
Можно сформулировать правило: нижний правый угол любого прямоугольника, выделенного в матрице, будет содержать самый большой элемент.
Аналогично, верхний левый угол всегда будет наименьшим. Цвета в приведенной ниже схеме отражают информацию об упорядочивании элементов (светло-серый < белый < темно-серый):
| 15 | 20 | 70 | 85 |
| 20 | 35 | 80 | 95 |
| 30 | 55 | 95 | 105 |
| 40 | 80 | 100 | 120 |
Давайте вернемся к исходной задаче. Допустим, что нам нужно найти элемент 85. Если мы посмотрим на диагональ, то увидим элементы 35 и 95. Какую информацию о местонахождении элемента 85 можно из этого извлечь?
| 15 | 20 | 70 | 85 |
| 20 | 35 | 80 | 95 |
| 30 | 55 | 95 | 105 |
| 40 | 80 | 100 | 120 |
85 не может находиться в темно-серой области, так как элемент 95 расположен в верхнем левом углу и является наименьшим элементом в этом квадрате.
85 не может принадлежать светло-серой области, так как элемент 35 находится в нижнем правом углу.
85 должен быть в одной из двух белых областей.
Таким образом, мы делим нашу сетку на четыре квадранта и выполняем поиск в нижнем левом и верхнем правом квадрантах. Их также можно разбить на квадранты и продолжить поиск.
Обратите внимание, что диагональ отсортирована, а значит, мы можем эффективно использовать бинарный поиск.
Приведенный ниже код реализует этот алгоритм:
public Coordinate findElement(int[][] matrix, Coordinate origin, Coordinate dest, int x) {
if (!origin.inbounds(matrix) || !dest.inbounds(matrix)) {
return null;
}
if (matrix[origin.row][origin.column] == x) {
return origin;
} else if (!origin.isBefore(dest)) {
return null;
}
/* Установим start на начало диагонали, a end - на конец
* диагонали. Так как сетка, возможно, не является квадратной, конец
* диагонали может не равняться dest. */
Coordinate start = (Coordinate) origin.clone();
int diagDist = Math.min(dest.row - origin.row, dest.column - origin.column);
Coordinate end = new Coordinate(start.row + diagDist, start.column + diagDist);
Coordinate p = new Coordinated(0, 0);
/* Производим бинарный поиск no диагонали, ищем первый
* элемент больше х */
while (start.isBefore(end)) {
р.setToAverage(start, end);
if (x > matrix[p.row][p.column]) {
start.row = p.row + 1;
start.column = p.column + 1;
} else {
end.row = p.row - 1;
end.column = p.column - 1;
}
}
/* Разделяем сетку на квадранты. Ищем в нижнем левом и верхнем
* правом квадранте */
return partitionAndSearch(matrix, origin, dest, start, x);
}
public Coordinate partitionAndSearch(int[][] matrix,
Coordinate origin. Coordinate dest, Coordinate pivot, int elem) {
Coordinate lowerLeftOrigin = new Coordinate(pivot.row, origin.column);
Coordinate lowerLeftDest = new Coordinate(dest.row, pivot.column - 1);
Coordinate upperRightOrigin = new Coordinate(origin.row, pivot.column);
Coordinate upperRightDest = new Coordinate(pivot.row - 1, dest.column);
Coordinate lowerLeft = findElement(matrix, lowerLeftOrigin, lowerLeftDest, elem);
if (lowerLeft == null) {
return findElement(matrix, upperRightOrigin, upperRightDest, elem);
}
return lowerLeft;
}
public static Coordinate findElement(int[][] matrix, int x) {
Coordinate origin = new Coordinate(0, 0);
Coordinate dest = new Coordinate(matrix.length - 1, matrix[0].length - 1);
return findElement(matrix, origin, dest, x);
}
public class Coordinate implements Cloneable {
public int row;
public int column;
public Coordinate(int r, int c) {
row = r;
column = c;
}
public boolean inbounds(int[][] matrix) {
return row >= 0 && column >= 0 &&
row < matrix.length && column < matrix[0].length;
}
public boolean isBefore(Coordinate p) {
return row <= p.row && column <= p.column;
}
public Object clone() {
return new Coordinate(row, column);
}
public void setToAverage(Coordinate min, Coordinate max) {
row = (min.row + max.row) / 2;
column = (min.column + max.column) / 2;
}
}
Этот код довольно трудно написать правильно с первого раза.
Запомните, что вы облегчите себе жизнь, выделяя код в методы. При написании программ, концентрируйтесь на ключевых местах. А собрать все воедино вы всегда сможете.
21. Напишите метод, находящий максимальное из двух чисел, не используя операторы if-else или любые другие операторы сравнения.
Самый распространенный вариант реализации функции max — проверка знака выражения a - b. В этом случае мы не можем использовать оператор сравнения, но можем использовать умножение.
Примечание: Смысл задачи не в том, чтобы скрыть сравнение или условие в какую-нибудь стандартную функцию типа abs() или стандартный оператор типа целочисленного деления, а в том, чтобы всё это сделать вообще без инструкций ветвления на уровне процессора.
Обозначим знак выражения a - b как k. Если a - b >= 0, то k = 1, иначе k = 0. Пусть q будет инвертированным значением k.
Код будет иметь вид:
/* Отражаем 1 в 0 и 0 в 1 */
int flip(int bit) {
return 1^bit;
}
/* Возвращаем 1, если число положительное, и 0, если отрицательное*/
int sign(int a) {
return flip((a >> (sizeof(int) * CHAR_BIT - 1)))) & 0x1);
}
int getMaxNaive(int a, int b) {
int k = sign(a - b);
int q = flip(k);
return a * k + b * q;
}
Это почти работоспособный код (можете проверить). Проблемы начинаются при переполнении. Предположим, что a = INT_MAX - 2 и b = -15. В этом случае a - b перестанет помещаться в INT_MAX и вызовет переполнение (значение станет отрицательным).
Можно использовать тот же подход, но придумать другую реализацию. Нам нужно, чтобы выполнялось условие k = 1, когда a > b. Для этого придется использовать более сложную логику.
Когда возникает переполнение a - b? Только тогда, когда a положительное число, а b отрицательное (или наоборот). Трудно обнаружить факт переполнения, но мы в состоянии понять, что a и b имеют разные знаки. Если у а и b разные знаки, то пусть k = sign(a).
Логика будет следующей:
если у a и b разные знаки:
// если a > 0, то b < 0 и k = 1.
// если a < 0, то b > 0 и k = 0.
// так или иначе, k = sign(a)
пусть k = sign(a)
иначе пусть k = sign(a - b) // переполнение невозможно
Приведенный далее код реализует этот алгоритм, используя умножение вместо операторов сравнения (проверить):
int getMax(int a, int b) {
int c = a - b;
int sa = sign(a); // если a >= 0, то 1, иначе 0
int sb = sign(b); // если a >= 1, то 1, иначе 0
int sc = sign(c); // зависит от переполнения a - b
/* Цель: найти k, которое = 1, если а > b, и 0, если a < b.
* если a = b, k не имеет значения */
// Если у а и b равные знаки, то k = sign(a)
int use_sign_of_a = sa ^ sb;
// Если у a и b одинаковый знак, то k = sign(a - b)
int use_sign_of_c = flip(sa ^ sb);
int k = use_sign_of_a * sa + use_sign_of_c * sc;
int q = flip(k); // отражение k
return a * k + b * q;
}
Отметим, что для большей наглядности мы разделяем код на методы и вводим переменные. Это не самый компактный или эффективный способ написания кода, но так мы делаем код понятнее.
22. На пустынном шоссе вероятность появления автомобиля за 30-минутный период составляет 0.95. Какова вероятность его появления за 10 минут?
Это вопрос труден только потому, что та информация, которую вы получили, не является той, которую вы хотели бы иметь. Однако в реальной жизни такое часто встречается.
Вы хотели бы определить вероятность, относящуюся к 10 минутам, имея вероятность для 30 минут. Вы не можете поступить просто, то есть разделить 0.95 на три (хотя надо сказать, что некоторые пытаются это сделать). Не очень помогает знание вероятности того, то автомобиль проедет в течение 30 минут, поскольку это может случиться в любое время. Автомобиль может проехать в первый 10-минутный отрезок или во второй, или в третий. За каждый из этих периодов могут проехать два автомобиля или пять, или тысяча, но это все считается как проезд автомобиля.
То, что вы хотели бы на самом деле знать, — это вероятность того, что за 30-минутный период не проедет ни один автомобиль. Узнать ее довольно просто. Поскольку имеется шанс, равный 95%, что за 30 минут проедет по крайней мере один автомобиль, то вероятность того, что в течение этого временного промежутка не будет ни одной машины, должна быть равна 0.05.
Чтобы в течение 30-минутного отрезка не было ни одного автомобиля, должны случиться (или, наоборот, не случиться) три вещи. Во-первых, в течение 10 минут не должно быть ни одного автомобиля. Затем должно пройти еще 10 минут без всяких машин. И, наконец, третьи 10 минут также должны быть без автомобилей. В вопросе спрашивается вероятность появления автомобиля в течение 10-минутного периода. Назовем ее X. Вероятность отсутствия машин в эти 10 минут равна 1 - X. Умножим эту величину саму на себя три раза. Она должна быть равна 0.05, то есть
(1 - X)3 = 0.05
Извлечем кубический корень из обеих частей.
1 - X = 3?0.05
Решим это уравнение относительно X.
X = 1 - 3?0.05
Никто не ожидает, что вы можете в уме извлекать кубические корни. Компьютер вам подскажет, что ответ равен около 0.63. Такой результат вполне обоснован. Вероятность появления автомобиля в 10-минутный период должна быть меньше, чем вероятность его появления, равная 0.95, за 30-минутный период.
23. Напишите функцию суммирования двух целых чисел без использования «+» и других арифметических операторов.
Первое, что приходит в голову, — обработка битов. Почему? У нас нет выбора — нельзя использовать оператор «+». Так что будем суммировать числа так, как это делают компьютеры!
Теперь нужно разобраться, как работает суммирование. Дополнительные задачи позволяют нам выработать новые навыки, узнать что-нибудь интересное, создать новые шаблоны.
Так что давайте рассмотрим дополнительную задачу. Мы будем использовать десятичную систему счисления.
Чтобы просуммировать 759 + 674, я обычно складываю digit[0] обоих чисел, переношу единицу, затем перехожу к digit[1], переношу и т.д. Точно так же можно работать с битами: просуммировать все разряды и при необходимости сделать переносы единиц.
Можно ли упростить алгоритм? Да! Допустим, я хочу разделить «суммирование» и «перенос». Мне придется проделать следующее:
Выполнить операцию 759 + 674, забыв о переносе. В результате получится 323.
Выполнить операцию 759 + 674, но сделать только переносы (без суммирования разрядов). В результате получится 1110.
Теперь нужно сложить результаты первых двух операций (используя тот же механизм, описанный в шагах 1 и 2): 1110 + 323 = 1433.
Теперь вернемся к двоичной системе.
Если просуммировать пару двоичных чисел, без учета переноса знака, то i-й просуммированный бит может быть нулевым, только если i-e биты чисел a и b совпадали (оба имели значение 0 или 1). Это классическая операция XOR.
Если суммировать пару чисел, выполняя только перенос, то i-му биту суммы присваивается значение 1, только если i-1-е биты обоих чисел (a и b) имели значение 1. Это операция AND со смещением.
Нужно повторять эти шаги до тех пор, пока не останется переносов.
Следующий код реализует данный алгоритм.
public static int add(int a, int b) {
if (b == 0) return a;
int sum = a ^ b; // добавляем без переноса
int carry = (a & b) << 1; // перенос без суммирования
return add(sum, carry); // рекурсия
}
Задачи, связанные с реализацией базовых операций (сложение, вычитание), достаточно популярны. Чтобы решить такую задачу, нужно разобраться с тем, как обычно реализуются операции, а потом найти путь, позволяющий написать код с учетом ограничений.
24. У вас есть парк из 50 грузовиков. Каждый из них полностью заправлен и может проехать 100 км. Как далеко с их помощью вы можете доставить определенный груз? Что будет, если в вашем распоряжении N грузовиков?
Не все понимают сразу о чем речь: территориально это место, где нет никаких заправочных станций. Единственное место, где можно здесь найти горючее – это топливные баки грузовиков. Пересесть из грузовика в гибридный легковой автомобиль Prius нельзя. Бросить грузовик без топлива, где бы это ни случилось, и без водителя – в порядке вещей. И единственное, что здесь важно, – доставить как можно дальше ценный груз.
Не все понимают сразу о чем речь: территориально это место, где нет никаких заправочных станций. Единственное место, где можно здесь найти горючее — это топливные баки грузовиков. Пересесть из грузовика в гибридный легковой автомобиль Prius нельзя. Бросить грузовик без топлива, где бы это ни случилось, и без водителя — в порядке вещей. И единственное, что здесь важно, — доставить как можно дальше ценный груз.
Топлива хватит, чтобы отправить каждый из 50-ти грузовиков на расстояние 100 км, то есть на расстояние 50*100 = 5000 км. Но возможно ли считать 5000 км ответом? Нет, если только у вас нет способа, позволяющего телепортировать топливо из бака одного грузовика в другой. Вспомните, что каждый грузовик полностью заправлен и пока топливо не израсходовано, добавить его нельзя.
Начните с простого шага. Представьте, что у вас не 50 грузовиков, а всего один. Загружайте его, залезайте в кабину и отправляйтесь в путь. Через 100 км путь для вас закончится.
Теперь предположим, что у вас есть два грузовика. Загружаете первый и 100 км можете ни о чем не думать. Но потом? Сможет ли вам помочь второй грузовик? Нет. Он на расстоянии 100 км от вас. Ему придется следовать за вами, так что его бак закончится через те же 100 км.
Может быть, первому грузовику следовало бы взять второй на буксир? Когда первый грузовик останется без топлива, можно переложить груз во второй грузовик, бак которого полон, и двигаться дальше. Да, хорошо, еще 100 км.
И насколько далеко в такой сцепке сможет проехать первый грузовик? Вряд ли 100 км. Ему придется тащить вес вдвое больше обычного. Законы физики говорят, что в лучшем случае он проедет только половину прежнего расстояния. В реальной жизни расход топлива на 1 км пути для более тяжелого транспортного средства повышается более резко, чем вес.
А если посмотреть иначе? Пусть два грузовика отправляются в путь одновременно, каждый сам по себе. Через 50 км баки у каждого будут наполовину пустые, но один бак вы можете заполнить доверху. Перелейте топливо из одного бака в другой. Оставьте пустой грузовик и проезжайте на заполненном доверху баке еще 100 км. Пройденное суммарное расстояние составит 150 км. В отличие от буксировки, здесь нет теоретического ограничения, и такой подход в полной мере может быть использован на практике.
При трех грузовиках вариант с буксировкой ставится под сомнение, а вот идея с переливанием топлива по-прежнему работает отлично. Отправьте сразу три грузовика. Пусть они остановятся на трети пути расстояния в 100 км, то есть после того, как проедут примерно 33.33 км. В каждом баке осталось 2/3 топлива. Перелейте топливо из одного грузовика в баки двух других – они снова полны доверху. Затем отправьте в путь эти два грузовика. Мы уже знаем, что максимальное расстояние для них составит 150 км. Если добавить к этому пути первые 33.33 км, то общее расстояние будет чуть больше 183 км.
Закономерность становится очевидной. Один грузовик может проехать 100 км. Второй грузовик позволяет увеличить общий путь на 100/2 = 50 км. Третий грузовик увеличивает общий путь на 100/3 км. Четвертый грузовик добавляет 100/4 км. Для N грузовиков общее расстояние составит: 100*(1/1+1/2+1/3+1/4+1/5+…1/N)
Дробная часть в этом случае известна как гармонический ряд. Сумму членов гармонического ряда можно легко рассчитать. Если N равно 50, сумма этой прогрессии 4.499… Умножьте ее на 100 км, и вы увидите, что, имея в своем распоряжении 50 грузовиков, вы сможете доставить груз на 449.9 км.
При увеличении N сумма возрастает. При достаточном количестве грузовиков вы можете отвезти груз куда захотите. Однако с увеличением N расстояние увеличивается очень медленно, а эффективность использования энергии становится очень низкой. Тысячный грузовик добавит лишь 1/100 км к общему расстоянию перевозки груза (но при этом загрязнит атмосферу выбросами диоксида углерода точно так же, как и все остальные машины). Миллионный грузовик увеличит весь путь всего на несколько сантиметров.
Приведенный выше ответ имеет право на жизнь. Есть ли другой? Есть, если можно перевозить топливо, и если груз не очень тяжелый.
В вопросе говорится о грузовиках, которые предназначены для перевозок крупных и тяжелых грузов. Предположим, у вас грузовики марки GMC или Ford. Собственный вес такого полностью заправленного и оборудованного автомобиля — порядка 2250 кг. Он сконструирован так, чтобы безопасно перевозить такой тяжелый груз, если только вы не транспортируете упакованный арахис или сахарную «вату».
Бак грузовика вмещает около 30 галлонов топлива, этот объем эквивалентен примерно 120 литрам.
Ключевой вопрос: весит ли топливо меньше, чем сам грузовик? Меньше, поскольку 200/5000 составляет 1/25 веса грузовика без груза, но заправленного.
Было бы глупо буксировать или везти грузовик весом 2250 кг, когда вас интересует только 120 литров топлива в его баке. Не лучше ли везти топливо в кузове грузовика вместе с доставляемым грузом. (Может быть, вы сможете найти емкости для топлива или снять топливные баки с других грузовиков и использовать их как такие емкости.) Грузовик может перевезти топливо, эквивалентное полной заправке 25 грузовиков при условии, что полезный груз весит немного.
Это означает, что один такой грузовик может перевезти половину топлива парка, состоящего из 50 машин. Он может проехать 25*100 или 2500 км. Однако, вряд ли он это сделает, потому что перевозимый груз сократит это расстояние. Тем не менее, будем считать, что такой вариант позволит ему проехать порядка 1500 км. Это более чем в три раза превышает 450 км при варианте перелива топлива и требует всего лишь одного грузовика и одного водителя.
25. Опишите алгоритм для нахождения миллиона наименьших чисел в наборе из миллиарда чисел. Память компьютера позволяет хранить весь миллиард чисел. Если придумали какое-либо решение, то оцените его эффективность по времени. Есть ли более эффективное решение?
Существует много способов решить эту задачу. Мы остановимся только на трех — сортировка, минимум кучи и ранжирование.
Можно отсортировать элементы в порядке возрастания, а затем взять первый миллион чисел. Это потребует O(n log(n)) времени.
Чтобы решить эту задачу, можно использовать минимум кучи. Мы сначала создаем кучу для первого миллиона чисел с наибольшим элементом сверху.
Затем мы проходимся по списку. Вставляя элемент в список, удаляем наибольший элемент.
В итоге мы получим кучу, содержащую миллион наименьших чисел. Эффективность алгоритма O(n log(m)), где m — количество значений, которые нужно найти.
Данный алгоритм очень популярен и позволяет найти i-й наименьший (или наибольший) элемент в массиве.
Если элементы уникальны, поиск i-гo наименьшего элемента потребует О(n) времени. Основной алгоритм будет таким:
Выберите случайный элемент в массиве и используйте его в качестве «центра». Разбейте элементы вокруг центра, отслеживая число элементов слева.
Если слева находится ровно i элементов, вам нужно вернуть наибольший элемент.
Если слева находится больше элементов, чем i, то повторите алгоритм, но только для левой части массива.
Если элементов слева меньше, чем i, то повторите алгоритм справа, но ищите алгоритм с рангом i - leftSize.
Приведенный далее код реализует этот алгоритм.
public int partition(int[] array, int left, int right, int pivot) {
while (true) {
while (left <= right && array[left] <= pivot) {
left++;
}
while (left <= right && array[right] > pivot) {
right--;
}
if (left > right) {
return left - 1;
}
swap(array, left, right);
}
}
public int rank(int[] array, int left, int right, int rank) {
int pivot = array[randomIntInRange(left, right)];
/* Раздел и возврат конца левого раздела */
int leftEnd = partition(array, left, right, pivot);
int leftSize = leftEnd - left + 1;
if (leftSize == rank + 1) {
return max(array, left, leftEnd);
} else if (rank < leftSize) {
return rank(array, left, leftEnd, rank);
} else {
return rank(array, leftEnd + 1, right, rank - leftSize);
}
}
Как только найден наименьший i-й элемент, можно пройтись по массиву и найти все значения, которые меньше или равны этому элементу.
Если элементы повторяются (вряд ли они будут «уникальными»), можно слегка модифицировать алгоритм, чтобы он соответствовал этому условию. Но в этом случае невозможно будет предсказать время его выполнения.
Существует алгоритм, гарантирующий, что мы найдем наименьший i-й элемент за линейное время, независимо от «уникальности» элементов. Однако эта задача несколько сложнее. Если вас заинтересовала эта тема, этот алгоритм приведен в книге Т. Кормен, Ч. Лейзер-сон, Р. Ривестп, К. Штайн «CLRS’ Introduction to Algorithms» (есть в переводе).
26. Напишите метод, который будет подсчитывать количество цифр «2», используемых в десятичной записи целых чисел от 0 до n (включительно). Картинка дана в качестве подсказки к одному из возможных решений.

Как всегда, сначала мы попробуем решить задачу «в лоб».
/* Подсчитываем число '2' между 0 и n */
int numberOf2sInRange(int n) {
int count = 0;
for (int i = 2; i <= n; i++) { // Можем начать с 2
count += numberOf2s(i);
}
return count;
}
/* подсчитываем число '2' в одном числе */
int numberOf2s(int n) {
int count = 0;
while (n > 0) {
if (n % 10 == 2) {
count++;
}
n = n / 10;
}
return count;
}
Единственное интересное место в этом алгоритме — выделение numberOf2s в отдельный метод. Это делается для чистоты кода.
Можно смотреть на задачу не с точки зрения диапазонов чисел, а с точки зрения разрядов — цифра за цифрой.
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 ... 110 111 112 113 114 115 116 117 118 119
Мы знаем, что в последовательном ряду из десяти чисел последний разряд принимает значение 2 только один раз. И вообще, любой разряд может быть равен 2 один раз из десяти.
Хотя тут стоит использовать слово «приблизительно», потому что необходимо учитывать граничные условия. Посчет количества двоек для диапазонов 1-100 и 1-37 будет различаться.
Точно количество двоек можно вычислить, рассмотрев все по отдельности разряды: digit < 2, digit = 2 и digit > 2.
Случай: digit < 2
Если x = 61523 и d = 3, то x[d] = 1 (это означает, что d-й разряд x равен 1). Рассмотрим двойки, находящиеся в 3-м разряде, в диапазонах 2000-2999, 12000-12999, 22000-22999, 32000-32999, 42000-42999 И 52000-52999. Мы не будем учитывать диапазон 62000-62999. В перечисленные диапазоны попадает 6000 двоек, находящихся в 3-м разряде. Такое же количество двоек можно получить, если подсчитать все двойки в 3-м разряде в диапазоне чисел от 1 до 6000.
<Другими словами, чтобы рассчитать количество двоек в d-м разряде, достаточно округлить значение до 10d+1, а затем разделить на 10.
if x[d] < 2: count2sInRangeAtDigit(x, d) =
let y = round down до ближайшего 10d+1
return y / 10
Случай: digit > 2
Давайте рассмотрим случай, когда значение d-гo разряда больше, чем 2 (х[d] > 2). Если использовать ту же логику, становится понятно, что количество двоек в 3-м разряде диапазона 0-63525 будет таким же, как в диапазоне 0-7000. Таким образом, вместо округления вниз мы будем округлять вверх.
if x[d] > 2: count2sInRangeAtDigit(x, d) =
let y = round up до ближайшего 10d+1
return y / 10
Случай: digit = 2
Последний случай самый трудный, но мы можем использовать ту же логику. Пусть х = 62523 и d = 3. Мы знаем, что диапазоны не изменились (2000-2999, 12000-12999, ..., 52000-52999). Сколько двоек может появиться в 3-м разряде в диапазоне 62000-62523? Подсчитать несложно — 524 (62000, 62001, ..., 62523).
if x[d] > 2: count2sInRangeAtDigit(x, d) =
let y = округляем вниз до 10d+1
let z = правая сторона x (т.е. х % 10d)
return y / 10 + z + 1
Теперь нам нужно пройтись по каждой цифре в числе. Реализация данного кода относительно проста:
public static int count2sInRangeAtDigit(int number, int d) {
int powerOf10 = (int) Math.pow(10, d);
int nextPowerOf10 = powerOf10 * 10;
int right = number % powerOf10;
int roundDown = number - number % nextPowerOf10;
int roundUp = roundDown + nextPowerOf10;
int digit = (number / powerOf10) % 10;
if (digit < 2) { // если digit меньше 2
return roundDown / 10;
} else if (digit == 2) {
return roundDown / 10 + right + 1;
} else {
return roundUp / 10;
}
}
public static int count2sInRange(int number) {
int count = 0;
int len = String.valueOf(number).length();
for (int digit = 0; digit < len; digit++) {
count += count2sInRangeAtDigit(number, digit);
}
return count;
}
Данная задача требует тщательного тестирования. Убедитесь, что вы знаете все граничные случаи и проверили каждый из них.
27. Где вы будете плыть быстрее — в воде или сиропе?
Это классическая задача с долгой историей, которую обсуждал в своё время еще Исаак Ньютон. Когда-то она использовалась и на IT-собеседованиях в Google (сейчас — нет). Тем не менее предлагаем вам порассуждать над решением.
Исаак Ньютон и Христиан Гюйгенс обсуждали этот вопрос в 1600-е годы, но так и не дали на него исчерпывающий ответ. Три столетия спустя два химика из Университета Миннесоты, Брайан Геттельфингер и Эдвард Касслер проделали эксперимент для сравнения сиропа и воды. Может быть, не стоит удивляться, что его проведение заняло много времени. Касслер рассказал, что ему потребовалось получить 22 согласования, в том числе и разрешение на то, чтобы затем вылить большой объем сиропа в канализационную систему. Ему пришлось отказаться от предложенных 20-ти грузовиков с бесплатным кукурузным сиропом, поскольку руководство университета посчитало, что он будет опасен для канализационной системы Миннеаполиса. Вместо этого Касслер использовал пищевой загуститель, применяемый для производства мороженого, шампуней и заправок для салата. Около 300 кг этого вещества вылили в плавательный бассейн. «Сказать по правде, смесь эта походила на сопли», — заметил Касслер. И все же это были не сопли, а размазня примерно вдвое плотнее воды.
Брайан Геттельфингер, пловец, подававший надежды и претендент на участие в Олимпиаде, получил уникальную возможность опробовать плавание в новой для себя жидкости. Результаты были опубликованы в 2004 году в American Institute of Chemical Engineers Journal. На следующий год Геттельфингер и Касслер получили Шнобелевскую премию по химии за 2005 год. Шнобелевская премия – это юмористический вариант более известных наград, присуждаемых в Стокгольме, но благодаря широкому освещению в новостях об этой премии многим известно. Может быть, именно внимание СМИ к этой задаче о сиропе и объясняет ее повторное появление в списке садистских вопросов, задаваемых на собеседовании.
В описываемом здесь эксперименте вязкость сиропообразной жидкости была примерно в два раза больше, чем у обычной воды, а вот плотности обеих жидкостей были примерно одинаковыми. Это важно, потому что, как пловцы уже давно знают, в более плотной соленой воде люди плавают быстрее. Как и корабль, тело пловца в соленой воде располагается выше, из-за чего сопротивление его движению вперед снижается.
Геттельфингер и студенты из Миннесоты плавали на скорость и в воде, и в «сиропе» стандартными стилями: на спине, брассом, баттерфляй, вольным. Но ни разу скорость плавания в обеих жидкостях не различалась более чем на несколько процентных пунктов. Выявить какой-то общей закономерности, позволяющей отдать предпочтение сиропу или воде, не удалось.
Это означало, что Ньютон был неправ: он полагал, что вязкость сиропа замедлит движение пловцов. Гюйгенс верно предсказывал, что заметной разницы в скорости не будет. Статья Геттельфингера и Касслера подтвердила обоснованность взглядов Гюйгенса. Вспомните о том, как поднимается дым от сигареты: на расстоянии нескольких сантиметров от сигареты он видится в виде ровной вертикальной колонны, однако выше его форма становится более сложной, так как начинают возникать воронки и завихрения. Воронки являются результатом турбулентности. Турбулентность мешает реактивным самолетам, быстроходным катерам и всем телам, которые хотят быстрее пройти через поток. Поскольку человеческое тело не оптимизировано для плавания, то когда мы плаваем, мы создаем до смешного много турбулентности, с которой затем сражаемся, чтобы переместить себя в воде. Турбулентность создает гораздо большее сопротивление движению, чем вязкость. Более того, вязкость здесь вообще вряд ли что-то значит. Поскольку турбулентность возникает и в воде, и в сиропе, скорость плавания в этих жидкостях приблизительно одинакова.
Поток воды намного менее турбулентен для рыб и особенно для бактерий, которые в сиропе будут плыть медленнее.
Можно ли считать этот вопрос на собеседовании честным? Касслер говорил, что для ответа на вопрос о плавании в сиропе «не нужно, скорее всего, обладать хорошими познаниями в компьютерных науках», добавив, что «любой человек, имеющий базовые знания в физике, сможет на него ответить». Тот, кто серьезно изучает физику может увидеть, что это излишне оптимистическая точка зрения. В любом случае, большинство претендентов, кому этот вопрос задают на собеседованиях при приеме на работу, не знают физику достаточно глубоко. Поэтому хорошие ответы предусматривают использование простых интуитивных аналогий, объясняющих, почему решение необходимо получить при помощи эксперимента. Вот четыре аргумента.
1. Некоторые жидкости слишком густые, чтобы в них можно было бы плавать.
Попросите мастодонтов поплавать в битумных озерах. Представьте попытку поплавать в жидком цементе или зыбучих песках. Разумеется, в очень густых жидкостях, хотя сила отталкивания здесь и больше, вы будете плыть значительно медленнее, чем в воде, если вообще вам это удастся сделать.
2. Под понятием «сироп» можно понимать очень широкий диапазон жидкостей.
В вопросе не говорится о смоле или зыбучих песках, а только о сиропе. А сиропы бывают очень разными, к примеру, кленовый сироп, сироп от кашля, шоколадный сироп, кукурузный сироп с большим содержанием фруктозы и те жидкости с разными консистенциями, варьирующиеся от водянистого напитка до густого осадка, остающегося на дне бутылки. На заданный вопрос нельзя ответить, пока вы не узнаете, о каком именно сиропе идет речь, или пока вы не сможете доказать, что плавание будет медленным в любой жидкости, более густой, чем вода.
3. Предположим, имеется оптимальный уровень вязкости, при которой скорость плавания является максимальной. Есть ли причина верить, что такой оптимальной жидкостью для плавания окажется H2O?
Может быть, вы с этим утверждением и согласились бы, будь вы очень проницательной рыбой. Эволюция постаралась, чтобы рыбы «соответствовали» той среде, а это вода, которая обтекает их изящные тела. Люди не очень похожи на рыб, и способ, каким мы плаваем, не очень напоминает то, как это делают рыбы. Никто из людей и наших ближайших предков не проводил много времени в бассейнах, а также в реках, озерах и океанах, чтобы сформировать такой набор генов, который был бы в значительной степени ориентирован на плавание. Конечно, мы иногда плаваем и даже порой летаем на параплане, но мы не созданы для этих занятий. Существо, заточенное под плавание австралийским кролем, слишком не похоже на человека. Эдвард Касслер по этому поводу сказал: «Идеальный пловец должен иметь тело змеи и руки гориллы».
Что уж тут удивляться, что можно отыскать людей, способных плавать быстрее в жидкости с другой вязкостью, чем у воды. Не будет удивительным и открытие, что скорость плавания является одинаковой в жидкостях с самыми разными вязкостями.
4. Плавание является хаотичным процессом.
Движение жидкости и газов — это пример хаоса, приводимый в учебниках. Слишком многое зависит от мельчайших деталей, чтобы заниматься предсказанием исхода. Вот почему для тестирования своих конструкций разработчикам самолетов нужны аэродинамические трубы. Не приспособленное хорошо к плаванию человеческое тело с его относительно неуклюжими движениями в воде еще больше осложняет ответ. Вот поэтому -то вопрос из тех, для которых необходимо провести эксперименты – с конкретным видом сиропа.
Речь, с которой Касслер выступил при вручении ему Шнобелевской премии, была краткой: «Причины этого сложны».
28. Напишите методы для умножения, вычитания и деления целых чисел, используя из арифметических операций только оператор суммирования. Язык реализации не важен, об оптимизации скорости работы и использования памяти также можете не особо беспокоиться. Главное, что можно использовать только сложение. В подобных задачах полезно вспомнить суть математических операций.
В этой задаче можно использовать только сложение. В подобных задачах полезно вспомнить суть математических операций и как их можно реализовать с помощью сложения (или других операций).
Как реализовать вычитание с помощью сложения? Это предельно просто. Операция a — b — то же самое, что и a + (-1) * b. Посколько мы не можем использовать оператор умножения, нам придется создать функцию negate.
public static int negate(int a) {
int neg = 0;
int d = a < 0 ? 1 : -1;
while (a != 0) {
neg += d;
a += d;
}
return neg;
}
public static int subtract(int a, int b) {
return a + negate(b);
}
Отрицательное значение k получается суммированием k раз числа -1.
Связь между сложением и умножением тоже достаточно очевидна. Чтобы перемножить a и b, нужно сложить значение a с самим собой b раз.
public static int multiply(int a, int b) {
if (a < b) {
return multiply(b, a); // алгоритм будет быстрее, если b < a
}
int sum = 0;
for (int i = abs(b); i > 0; i--) {
sum += a;
}
if (b < 0) {
sum = negate(sum);
}
return sum;
}
public static int abs(int a) {
if (a < 0) {
return negate(a);
} else {
return a;
}
}
При умножении нам нужно обратить особое внимание на отрицательные числа. Если b — отрицательное число, то необходимо учесть знак суммы:
multiply(a, b) < – abs(b) * a * (-1 if b < 0).
Кроме того, для решения это задачи мы создали простую функцию abs.
Самая сложная из математических операций — деление. Хорошая идея — использовать для реализации метода divide методы multiply, subtract и negate.
Нам нужно найти x, если x = a / b. Давайте переформулируем задачу: найти x, если a = bx. Теперь мы изменили условие так, чтобы задачу можно было решить с помощью уже известной нам операции — умножения.
Обратите внимание, что можно вычислить x как результат суммирования b, пока не будет получено a. Количество экземпляров b, необходимых, чтобы получить a, и будет искомой величиной x.
Конечно, это решение нельзя назвать полноценным делением, но оно работает. Вы должны понимать, что при такой реализации не получить остаток от деления.
Приведенный ниже код реализует данный алгоритм:
public int divide(int a, int b)
throws java.lang.ArithmeticException {
if ( b == 0) {
throw new java.lang.ArithmeticException("ERROR");
}
int absa = abs(a);
int absb = abs(b);
int product = 0;
int x = 0;
while (product + absb <= absa) {
product += absb;
x++;
}
if ((a < 0 && b < 0) || (a > 0 && b > 0)) {
return x;
} else {
return negate(x);
}
}
29. Допустим, вы пишете конвейер, в котором 2 потока, используя общий буфер, обрабатывают данные. Поток-producer эти данные создает, а поток-consumer их обрабатывает (Producer–consumer problem). Следующий код представляет собой самую простую модель: с помощью std::thread мы порождаем поток-consumer, a создавать данные мы будем в главном потоке.
Опустим механизмы синхронизации двух потоков, и обратим внимание на функцию main(). Попробуйте догадаться, что с этим кодом не так, и как его исправить?
void produce() {
// создаем задачу и кладем в очередь
}
void consume() {
// читаем данные из очереди и обрабатываем
}
int main(int , char **) {
std::thread thr(consume); // порождаем поток
produce(); // создаем данные для обработки
thr.join(); // ждем завершения работы функции consume()
return 0;
}
Допустим, вы пишете конвейер, в котором 2 потока, используя общий буфер, обрабатывают данные. Поток-producer эти данные создает, а поток-consumer их обрабатывает (Producer–consumer problem). Следующий код представляет собой самую простую модель: с помощью std::thread мы порождаем поток-consumer, a создавать данные мы будем в главном потоке.
void produce() {
// создаем задачу и кладем в очередь
}
void consume() {
// читаем данные из очереди и обрабатываем
}
int main(int , char **) {
std::thread thr(consume); // порождаем поток
produce(); // создаем данные для обработки
thr.join(); // ждем завершения работы функции consume()
return 0;
}
Опустим механизмы синхронизации двух потоков, и обратим внимание на функцию main(). Попробуйте догадаться, что с этим кодом не так, и как его исправить?
В С++, если не сказано иного, принято считать, что каждая функция может выбросить исключение.
Допустим, функция consume() бросает исключение. Поскольку это исключение генерируется в дочернем потоке, поймать и обработать его в главном потоке нельзя. Если во время развертывания стека дочернего потока не нашлось подходящего обработчика исключения, будет вызвана функция std::terminate(), которая по-умолчанию вызовет функцию abort(). Иными словами, если не обработать исключение в потоке, порожденном объектом thr, то программа завершит свою работу с ошибкой.
С функцией produce() немного сложнее. Допустим, эта функция генерирует исключение. Первое, что хочется сделать, это обернуть тело main() в try-catch блок:
try {
std::thread thr(consume);
produce(); // бросает исключение
thr.join();
} catch (...) {
}
Кажется, что проблема решена, но если вы попытаетесь запустить этот код, то программа упадет в любом случае. Почему так происходит? Давайте разбираться.
Как вы уже, может быть, догадались, проблема не имеет отношение к конвейеру, а относится к правильному использованию потоков выполнения стандартной библиотеки в принципе. В частности следующая обобщенная функция равнозначна, и имеет те же проблемы:
void run(function<void()> f1, function<void()> f2) {
std::thread thr(f1);
f2();
thr.join();
}
...
run(consume, produce);
...
Прежде чем перейти к решению нашей задачи, давайте вкратце вспомним как работает std::thread.
1) конструктор для инициализации:
template <class Fn, class... Args> explicit thread (Fn&& fn, Args&&... args);
При инициализации объекта std::thread создается новый поток, в котором запускается функция fn с возможными аргументами args. При успешном его создании, конкретный экземпляр объекта начинает представлять этот поток в родительском потоке, а в свойствах объекта выставляется флаг joinable.
Запомним: joinable ~ объект связан с потоком.
2) Ждем конца выполнения порожденного потока:
void thread::join();
Этот метод блокирует дальнейшее выполнение родительского потока, до тех пока не будет завершен дочерний. После успешного выполнения, объект потока перестает его представлять, поскольку нашего потока больше не существует. Флаг joinable сбрасывается.
3) Немедленно «отсоединяем» объект от потока:
void thread::detach();
Это неблокирующий метод. Флаг joinable сбрасывается, а дочерний поток предоставлен сам себе и завершит свою работу когда-нибудь позже.
4) Деструктор:
thread::~thread();
Деструктор уничтожает объект. При этом если, у этого объекта стоит флаг joinable, то вызывается функция std::terminate(), которая по умолчанию вызовет функцию abort().
Внимание! Если мы создали объект и поток, но не вызвали join или detach, то программа упадет. В принципе, это логично — если объект до сих пор связан с потоком, то надо что-то с ним делать. А еще лучше — ничего не делать, и завершить программу (по крайней мере так решил комитет по стандарту).
Поэтому при возникновении исключения в функции produce(), мы пытаемся уничтожить объект thr, который является joinable.
Почему же стандартный комитет решил поступить так и не иначе? Не лучше было бы вызвать в деструкторе join() или detach()? Оказывается, не лучше. Давайте разберем оба этих случая.
Допустим, у нас есть класс joining_thread, который так вызывает join() в своем деструкторе:
joining_thread::~joining_thread() {
join();
}
Тогда, прежде чем обработать исключение, мы должны будем подождать завершения работы дочернего потока, поскольку join() блокирует дальнейшее выполнение программы. А если так получилось, что порожденном потоке оказался в бесконечный цикл?
void consume() {
while(1) { ... }
}
...
try {
joining_thread thr(consume);
throw std::exception();
} catch (...) {
// может случится не скоро, или даже никогда
}
Хорошо, мы выяснили, что join() в деструкторе лучше не вызывать (до тех пор пока вы не уверены, что это корректная обработка события), поскольку это блокирующая операция. А что насчет detach()? Почему бы не вызвать в деструкторе этот неблокирующий метод, дав главному потоку продолжить работу? Допустим у нас есть такой класс detaching_thread.
Но тогда мы можем прийти к такой ситуации, когда порожденный поток пытается использовать ресурс, которого уже нет, как в следующей ситуации:
try {
int data;
detaching_thread th(consume, &data); // в данном случае consume принимает указатель на int в качестве аргумента
throw std::exception()
} catch (...) {
// корректно обработаем исключение
// consume продолжает исполняться, но ссылается на уже удаленный объект data
}
Таким образом, создатели стандарта решили переложить ответственность на программиста — в конце концов ему виднее, как программа должна обрабатывать подобные случаи. Исходя из всего этого, получается, что стандартная библиотека противоречит принципу RAII — при создании std::thread мы сами должны позаботиться о корректном управлении ресурсами, то есть явно вызвать join или detach. По этой причине некоторые программисты советуют не использовать объекты std::thread. Так же как new и delete, std::thread предоставляет возможность построить на основе них более высокоуровневые инструменты.
Одним из таких инструментов является класс из библиотеки Boost boost::thread_joiner. Он соответствует нашему joining_thread в примере выше. Если вы можете позволить себе использовать сторонние библиотеки для работы с потоками, то лучше это сделать.
Другое решение — позаботиться об это самому в RAII-стиле, например так:
class Consumer {
public:
Consumer()
: exit_flag(false)
, thr( &Consumer::run, this )
{
// после создания потока не делайте тут ничего, что бросает исключение,
// поскольку в этом случае не будет вызван деструктор объекта Consumer,
// поток не будет завершен, а программа упадет
}
~Consumer() {
exit_flag = true; // говорим потоку остановиться
thr.join();
}
private:
std::atomic<bool> exit_flag; // флаг для синхронизации (опционально)
std::thread thr;
void run() {
while (!exit_flag) {
// делаем что-нибудь
}
}
};
В случае, если вы собираетесь отделить поток от объекта в любом случае, лучше сделать это сразу же:
std::thread(consume).detach(); // создаем поток, и сразу же освобождаем объект, связанный с ним
30. Дано 20 баночек с таблетками. В 19 из них лежат таблетки весом 1 г, а в одной – весом 1.1 г. Даны весы, показывающие точный вес. Как за одно взвешивание найти банку с тяжелыми таблетками?
Иногда «хитрые» ограничения могут стать подсказкой. В нашем случае подсказка спрятана в информации о том, что весы можно использовать только один раз.
У нас только одно взвешивание, а это значит, что придется одновременно взвешивать много таблеток. Фактически, мы должны одновременно взвесить 19 банок. Если мы пропустим две (или больше) банки, то не сможем их проверить. Не забывайте: только одно взвешивание!
Как же взвесить несколько банок и понять, в какой из них находятся «дефектные» таблетки? Давайте представим, что у нас есть только две банки, в одной из них лежат более тяжелые таблетки. Если взять по одной таблетке из каждой банки и взвесить их одновременно,то общий вес будет 2.1 г, но при этом мы не узнаем, какая из банок дала дополнительные 0.1 г. Значит, надо взвешивать как-то иначе.
Если мы возьмем одну таблетку из банки №1 и две таблетки из банки №2, то, что покажут весы? Результат зависит от веса таблеток. Если банка №1 содержит более тяжелые таблетки, то вес будет 3.1 г. Если с тяжелыми таблетками банка №2 — то 3.2 грамма. Подход к решению задачи найден.
Можно обобщить наш подход: возьмем одну таблетку из банки №1, две таблетки из банки №2, три таблетки из банки №3 и т.д. Взвесьте этот набор таблеток. Если все таблетки весят 1 г, то результат составит 210 г. «Излишек» внесет банка с тяжелыми таблетками.
Таким образом, номер банки можно узнать по простой формуле: (вес — 210) / 0.1. Если суммарный вес таблеток составляет 211.3 г, то тяжелые таблетки находились в банке №13.
31. Дана шахматная доска размером 8×8, из которой были вырезаны два противоположных по диагонали угла, и 31 кость домино; каждая кость домино может закрыть два квадратика на поле. Можно ли вымостить костями всю доску? Дайте обоснование своему ответу.

С первого взгляда кажется, что это возможно. Доска 8×8, следовательно, есть 64 клетки, две мы исключаем, значит остается 62. Вроде бы 31 кость должна поместиться, правильно?
Когда мы попытаемся разложить домино в первом ряду, то в нашем распоряжении только 7 квадратов, одна кость переходит на второй ряд. Затем мы размещаем домино во втором ряду, и опять одна кость переходит на третий ряд.
В каждом ряду всегда будет оставаться одна кость, которую нужно перенести на следующий ряд, не имеет значения сколько вариантов раскладки мы опробуем, у нас никогда не получится разложить все кости.
Шахматная доска делится на 32 черные и 32 белые клетки. Удаляя противоположные углы (обратите внимание, что эти клетки окрашены в один и тот же цвет), мы оставляем 30 клеток одного и 32 клетки другого цвета. Предположим, что теперь у нас есть 30 черных и 32 белых квадрата.
Каждая кость, которую мы будем класть на доску, будет занимать одну черную и одну белую клетку. Поэтому 31 кость домино займет 31 белую и 31 черную клетки. Но на нашей доске всего 30 черных и 32 белых клетки. Поэтому разложить кости невозможно.
32. Дан входной файл, содержащий четыре миллиарда целых 32-битных чисел. Предложите алгоритм, генерирующий число, отсутствующее в файле. Имеется 1 Гбайт памяти для этой задачи. Дополнительно: а что если у вас всего 10 Мбайт? Количество проходов по файлу должно быть минимальным.
В нашем распоряжении 232 (или 4 миллиарда) целых чисел. У нас есть 1 Гбайт памяти, или 8 млрд бит.
8 млрд бит — вполне достаточный объем, чтобы отобразить все целые числа. Что нужно сделать?
BV.set(num, 1).Следующий код реализует наш алгоритм:
byte[] bitfield = new byte [0xFFFFFFF/8];
void findOpenNumber2() throws FileNotFoundException {
Scanner in = new Scanner(new FileReader("file.txt"));
while (in.hasNextInt()) {
int n = in.nextInt ();
/* Находим соответствующее число в bitfield, используя
* оператор OR для установки n-го бита байта
* (то есть 10 будет соответствовать 2-му биту индекса 2
* в массиве байтов). */
bitfield [n / 8] |= 1 << (n % 8);
}
for (int i = 0; i < bitfield.length; i++) {
for (int j = 0; j < 8; j++) {
/* Получает отдельные биты каждого байта. Когда будет найден
* бит 0, находим соответствующее значение. */
if ((bitfield[i] & (1 << j)) == 0) {
System.out.println(i * 8 + j);
return;
}
}
}
}
Можно найти отсутствующее число, воспользовавшись двойным проходом по данным. Давайте разделим целые числа на блоки некоторого размера (мы еще обсудим, как правильно выбрать размер). Пока предположим, что мы используем блоки размером 1000 чисел. Так, blоск0 соответствует числам от 0 до 999, block1 — 1000 — 1999 и т.д.
Нам известно, сколько значений может находиться в каждом блоке. Теперь мы анализируем файл и подсчитываем, сколько значений находится в указанном диапазоне: 0-999, 1000-1999 и т.д. Если в диапазоне оказалось 998 значений, то «дефектный» интервал найден.
На втором проходе мы будем искать в этом диапазоне отсутствующее число. Можно воспользоваться идеей битового вектора, рассмотренного в первой части задачи. Нам ведь не нужны числа, не входящие в конкретный диапазон.
Как же выбрать размер блока? Давайте введем несколько переменных:
Нам нужно выбрать значение rangeSize так, чтобы памяти хватило и на первый (массив) и на второй (битовый вектор) проходы.
Массив на первом проходе может вместить 10 Мбайт, или 223 байт, памяти. Поскольку каждый элемент в массиве относится к типу int, а переменная типа int занимает 4 байта, мы можем хранить примерно 221 элементов.
Нам нужно место, чтобы хранить rangeSize бит. Поскольку в память помещается 223 байт, мы сможем поместить 226 бит в памяти. Таким образом:
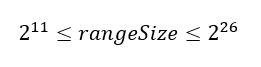
Мы получаем достаточно пространства для «маневра», но чем ближе к середине, которую мы выбираем, тем меньше памяти будет использоваться в любой момент времени.
Нижеприведенный код предоставляет одну реализацию для этого алгоритма:
int bitsize = 1048576; // 2^20 bits (2^17 bytes)
int blockNum = 4096; // 2^12
byte[] bitfield = new byte[bitsize/8];
int[] blocks = new int[blockNum];
void findOpenNumber() throws FileNotFoundException {
int starting = -1;
Scanner in = new Scanner (new FileReader ("file.txt"));
while (in.hasNextInt()) {
int n = in.nextInt();
blocks[n / (bitfield.length * 8)]++;
}
for (int i = 0; i < blocks.length; i++) {
if (blocks[i] < bitfield.length * 8) {
/* если значение < 2^20, то отсутствует как минимум 1 число
* в этой секции. */
starting = i * bitfield.length * 8;
break;
}
}
in = new Scanner(new FileReader("input_file.txt"));
while (in.hasNextInt()) {
int n = in.nextInt();
/* Если число внутри блока, в котором отсутствуют числа,
* мы записываем его */
if (n >= starting && n < starting + bitfield.length * 8) {
bitfield[(n - starting) / 8] |= 1 << ((n - starting) % 8);
}
}
for (int i = 0 ; i < bitfield.length; i++) {
for (int j = 0; j < 8; j++) {
/* Получаем отдельные биты каждого байта. Когда бит 0
* найден, находим соответствующее значение. */
if ((bitfield[i] & (1 << j)) == 0) {
System.out.println(i * 8 + j + starting); return;
}
}
}
}
А что если вам нужно решить задачу, используя более серьезные ограничения на использование памяти? В этом случае придется сделать несколько проходов. Сначала пройдитесь по «миллионным» блокам, потом по тысячным. Наконец, на третьем проходе можно будет использовать битовый вектор.
33. Предложите алгоритм, генерирующий все корректные комбинации пар круглых скобок. Под корректными комбинациями пар будем понимать правильно открытые и закрытые скобки. На вход подаётся число пар скобок, на выходе должны быть все возможные их комбинации в виде набора строк.
Под корректными комбинациями пар будем понимать правильно открытые и закрытые скобки. На вход подаётся число пар скобок, на выходе должны быть все возможные их комбинации в виде набора строк.
Первая мысль — использовать рекурсивный подход, который строит решение для f(n), добавляя пары круглых скобок в f(n-1). Это, конечно, правильная мысль.
Рассмотрим решение для n = 3:
(()()) ((())) ()(()) (())() ()()()
Как получить это решение из решения для n = 2?
(()) ()()
Можно расставить пары скобок в каждую существующую пару скобок, а также одну пару в начале строки. Другие места, куда мы могли вставить скобки, например в конце строки, получатся сами собой.
Итак, у нас есть следующее:
(()) -> (()()) /* скобки вставлены после первой левой скобки */
-> ((())) /* скобки вставлены после второй левой скобки */
-> ()(()) /* скобки вставлены в начале строки */
()() -> (())() /* скобки вставлены после первой левой скобки */
-> ()(()) /* скобки вставлены после второй левой скобки */
-> ()()() /* скобки вставлены в начале строки */
Но постойте! Некоторые пары дублируются! Строка ()(()) упомянута дважды! Если мы будем использовать данный подход, то нам понадобится проверка дубликатов перед добавлением строки в список. Реализация такого метода выглядит так:
public static Set<String> generateParens(int remaining) {
Set<String> set = new HashSet<String>();
if (remaining == 0) {
set.add("");
} else {
Set<String> prev = generateParens(remaining - 1);
for (String str : prev) {
for (int i = 0; i < str.length(); i++) {
if (str.charAt(i) == '(') {
String s = insertInside(str, i);
if (!set.contains(s)) {
set.add(s);
}
}
}
if (!set.contains("()" + str)) {
set.add("()" + str);
}
}
}
return set;
}
public String insertInside(String str, int leftIndex) {
String left = str.substring(0, leftIndex + 1);
String right = str.substring(leftIndex + 1, str.length();
return left + "()" + right;
}
Алгоритм работает, но не очень эффективно. Мы тратим много времени на дублирующиеся строки.
Избежать проблемы дублирования можно путем построения строки с нуля. Этот подход подразумевает, что мы добавляем левые и правые скобки, пока наше выражение остается правильным.
При каждом рекурсивном вызове мы получаем индекс определенного символа в строке. Теперь нужно выбрать скобку (левую или правую). Когда использовать левую скобку, а когда — правую?
Таким образом, нам нужно отслеживать количество открывающих и закрывающих скобок. Если в строку можно вставить левую скобку, добавляем ее и продолжаем рекурсию. Если левых скобок больше, чем правых, то вставляем правую скобку и продолжаем рекурсию.
public void addParen(ArrayList<String> list, int leftRem, int rightRem, char[] str, int count) {
if (leftRem < 0 || rightRem < leftRem) return; // некорректное состояние
if (leftRem == 0 && rightRem == 0) { /* нет больше левых скобок */
String s = String.copyValueOf(str);
list.add(s);
} else {
/* Добавляем левую скобку, если остались любые левые скобки */
if (leftRem > 0) {
str[count] = '(';
addParen(list, leftRem - 1, rightRem, str, count + 1);
}
/* Добавляем правую скобку, если выражение верно */
if (rightRem > leftRem) {
str[count] = ')';
addParen(list, leftRem, rightRem - 1, str, count + 1);
}
}
}
public ArrayList<String> generateParens(int count) {
char[] str = new char[count * 2];
ArrayList<String> list = new ArrayList<String>();
addParen(list, count, count, str, 0);
return list;
}
Поскольку мы добавляем левые и правые скобки для каждого индекса в строке, индексы не повторяются, и каждая строка гарантированно будет уникальной.
34. Вы поставили стакан воды на диск проигрывателя виниловых пластинок и медленно увеличиваете скорость вращения. Что произойдет раньше: стакан сползет в сторону, стакан опрокинется, вода расплескается?
Этот вопрос задавали ранее на собеседованиях в Apple. При ответе рассмотрите возможные варианты и укажите, от чего зависит ответ, если их несколько.
Этот вопрос задавали ранее в Apple. Большинство людей понимают, что при его анализе необходимо учесть центробежную силу. В равной степени вам нужно знать и силу трения. Оно возникает между дном стакана и вращающимся диском, который приводит стакан в движение.
Чтобы сделать ситуацию более понятной, представьте мир, где трение вообще отсутствует. Каждая вещь становится более скользкой, чем тефлон, причем более скользкой бесконечно. Тогда в эксперименте, описанном в вопросе, не будет никакого влияния на стакан. Диск проигрывателя будет вращаться под стаканом, не оказывая на него никакого влияния, то есть стакан вообще не будет двигаться. Это верно в соответствии с первым законом Ньютона: неподвижные объекты остаются в этом положении до тех пор, пока на них не воздействует какая-то сила. Без силы трения стакан не будет перемещаться.
Теперь представьте противоположный вариант: стакан при помощи очень прочного клея Krazy Glue приклеили к диску, и между двумя поверхностями появилась практически бесконечно высокая сила трения. Стакан и диск в этом случае будут вращаться как единое целое. Увеличьте скорость диска, и стакан будет вращаться быстрее. Это приведет к увеличению центробежной силы. Единственное, что сможет в этих условиях свободно реагировать на эту силу, будет вода. Ведь она-то ко дну стакана не приклеена. Когда стакан будет крутиться с достаточно большой скоростью, вода прольется в сторону, противоположную центру вращения.
В вопросе вас просят рассмотреть вариант, лежащий между предельными ситуациями. Вначале трение будет достаточным, чтобы удерживать стакан на месте. Он будет вращаться вместе с диском, создавая небольшую центробежную силу. По мере увеличения скорости вращения, центробежная сила будет возрастать. Давление, удерживающее стакан на месте, будет оставаться примерно одинаковым. Поэтому должен наступить какой-то момент, когда центробежная сила превысит силу давления.
Те, кто изучал физику или проводил много времени в детских играх, вспомнят, что когда предмет начинает скользить, сила трения становится меньше, чем когда он стоит. На верхней части ледяной горки вы немного «прилипаете», но затем неожиданно начинаете свободно по ней двигаться вниз. То же самое относится и к диску. Вместо того, чтобы все время ускоряться постепенно, стакан вначале удерживается, и только через какое-то время начинает двигаться.
Что случится потом? Ответ здесь таков: это зависит от формы стакана и от того, насколько он заполнен водой. Однако если вы ограничитесь только этим ответом, интервьюер может решить, что вы пытаетесь уйти от вопроса. Вот варианты, которые возможны в реальной жизни.
Важно учесть и поверхность диска. Если она изготовлена из резины, это повысит трение и с большей вероятностью приведет к выплескиванию и опрокидыванию, здесь они в равной мере вероятны. Более скользкая твердая пластиковая поверхность способствует реализации варианта скольжения.
35. Короткая задачка по С++ в виде вопроса для новичков. Почему деструктор полиморфного базового класса должен объявляться виртуальным? Полиморфным считаем класс, в котором есть хотя бы одна виртуальная функция.
Давайте разберемся, зачем нужны виртуальные методы. Рассмотрим следующий код:
class Foo {
public:
void f();
};
class Bar : public Foo {
public:
void f();
}
Foo *p = new Bar();
p->f();
Вызывая p->f(), мы обращаемся к Foo::f(). Это потому, что р — указатель на Foo, a f() — невиртуальная функция.
Чтобы гарантировать, что p->f() вызовет нужную реализацию f(), необходимо объявить f() как виртуальную функцию.
Теперь вернемся к деструктору. Деструкторы предназначены для очистки памяти и ресурсов. Если деструктор Foo не является виртуальным, то при уничтожении объект Bar все равно будет вызван деструктор базового класса Foo.
Поэтому деструкторы объявляют виртуальными — это гарантирует, что будет вызван деструктор для производного класса.
36. Напишите функцию, меняющую местами значения переменных, не используя временные переменные. Предложите как можно больше вариантов.
Это классическая задача, которую любят предлагать на собеседованиях, и она достаточно проста. Пусть a0 — это исходное значение a, а b0 — исходное значение b. Обозначим diff разницу а0 - b0.
Давайте покажем взаимное расположение всех этих значений на числовой оси для случая, когда a > b:
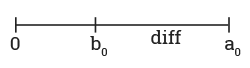
Присвоим а значение diff. Если сложить значение b и diff, то мы получим a0 (результат следует сохранить в b). Теперь у нас b = а0 и a = diff. Все, что нам остается сделать, — присвоить b значение а0 - diff, а это значение представляет собой b - a.
Приведенный далее код реализует этот алгоритм:
public static void swap(int a, int b) {
// Пример для a = 9, b = 4
a = a - b; // a = 9 - 4 = 5
b = a + b; // b = 5 + 4 = 9
a = b - a; // a = 9 - 5
System.out.println("a: " + a);
System.out.println("b: " + b);
}
Можно решить эту задачу с помощью битовой манипуляции. Такой подход позволит нам работать с разными типами данных, а не только с integer.
public static void swap_opt(int a, int b) {
//Пример для a = 101 (в двоичной системе) и b = 110
a = a ^ b; // a = 101^110 = 011
b = a ^ b; // b = 011^110 = 101
a = a ^ b; // a = 011^101 = 110
System.out.println("a: " + a);
System.out.println("b: " + b);
}
Этот код использует операцию XOR. Проще всего понять, как работает код, взглянув на два бита — р и q. Давайте обозначим как р0 и q0 исходные значения.
Если мы сможем поменять местами два бита, то алгоритм будет работать правильно. Давайте рассмотрим работу алгоритма пошагово:
В строке 1 выполняется операция p = p0^q0, результатом которой будет 0, если p0 = q0, и 1, если p0 != q0.
В строке 2 выполняется операция q = p^q0. Давайте проанализируем оба возможных значения p. Так как мы хотим поменять местами значения p и q, в результате должен получиться 0:
p = 0: в этом случае p0 = q0, так как нам нужно вернуть p0 или q0. XOR любого значения с 0 всегда дает исходное значение, поэтому результатом этой операции будет q0 (или p0).p = 1: в этом случае p0 != q0. Нам нужно получить 1, если q0 = 0, и 0, если p0 = 1. Именно такой результат получается при операции XOR любого значения с 1.В строке 3 выполняется операция p = p^q. Давайте рассмотрим оба значения p. В результате мы хотим получить q0. Обратите внимание, что q в настоящий момент равно p0, поэтому на самом деле выполняется операция p^p0.
p = 0: так как p0 = q0, мы хотим вернуть p0 или q0. Выполняя 0^p0, мы вернем p0(q0).p = 1: выполняется операция 1^p0. В результате мы получаем инверсию p0, что нам и нужно, так как p0 != q0.Остается только присвоить p значение q0, a q — значение р0. Мы удостоверились, что наш алгоритме корректно меняет местами каждый бит, а значит, результат будет правильным.
37. Предложите алгоритм поиска в односвязном списке k-го элемента с конца. Список реализован вручную, есть только операция получения следующего элемента и указатель на первый элемент. Алгоритм, по возможности, должен быть оптимален по времени и памяти.
Данный алгоритм можно реализовать рекурсивным и нерекурсивным способом. Рекурсивные решения обычно более понятны, но менее оптимальны. Например, рекурсивная реализация этой задачи почти в два раза короче нерекурсивной, но занимает O(n) пространства, где n — количество элементов связного списка.
При решение данной задачи помните, что можно выбрать значение k так, что при передаче k = 1 мы получим последний элемент, 2 — предпоследний и т.д. Или выбрать k так, чтобы k = 0 соответствовало последнему элементу.
Если размер связного списка известен, k-й элемент с конца легко вычислить (длина — k). Нужно пройтись по списку и найти этот элемент.
Такой алгоритм рекурсивно проходит связный список. По достижении последнего элемента алгоритм начинает обратный отсчет, и счетчик сбрасывается в 0. Каждый шаг инкрементирует счетчик на 1. Когда счетчик достигнет k, искомый элемент будет найден.
Реализация этого алгоритма коротка и проста — достаточно передать назад целое значение через стек. К сожалению, оператор return не может вернуть значение узла. Так как же обойти эту трудность?
Подход А: не возвращайте элемент
Можно не возвращать элемент, достаточно вывести его сразу, как только он будет найден. А в операторе return вернуть значение счетчика.
public static int nthToLast(LinkedListNode head, int k) {
if (head == null) {
return 0;
}
int i = nthToLast(head.next, k) + 1;
if (i == k) {
System.out.println(head.data);
}
return i;
}
Решение верно, но можно пойти другим путем.
Подход Б: используйте C++
Второй способ — использование С++ и передача значения по ссылке. Такой подход позволяет не только вернуть значение узла, но и обновить счетчик путем передачи указателя на него.
node* nthToLast(node* head, int k, int& i) {
if (head == NULL) {
return NULL;
}
node* nd = nthToLast(head->next, k, i);
i = i + 1;
if (i == k) {
return head;
}
return nd;
}
Итерационное решение будет более сложным, но и более оптимальным. Можно использовать два указателя — p1 и p2. Сначала оба указателя указывают на начало списка. Затем перемещаем p2 на k узлов вперед. Теперь мы начинаем перемещать оба указателя одновременно. Когда p2 дойдет до конца списка, p1 будет указывать на нужный нам элемент.
LinkedListNode nthToLast(LinkedListNode head, int k) {
if (k <= 0) return 0;
LinkedListNode p1 = head;
LinkedListNode p2 = head;
for (int i = 0; i < k - 1; i++) {
if (p2 == null) return null;
p2 = p2.next;
}
if (p2 == null) return null;
while (p2.next != null) {
p1 = p1.next;
p2 = p2.next;
}
return p1;
}
38. Напишите функцию, определяющую количество битов, которые необходимо изменить, чтобы из целого числа А получить целое число B. Числа, допустим, 32-битные, язык любой.
Это одна из типичных задач на работу с битами, которые любят давать на собеседовании. Если вы никогда с ними не сталкивались, вам будет сложно сразу решить задачу с учётом стрессовой ситуации, поэтому запомните использованные при решении трюки.
На первый взгляд кажется, что задача сложная, но фактически она очень проста. Чтобы решить ее, задайте себе вопрос: «Как узнать, какие биты в двух числах различаются?». Ответ прост — с помощью операции XOR.
Каждая единица результирующего числа соответствует биту, который не совпадает в числах A и B. Поэтому расчет количества несовпадающих битов в числах А и В сводится к подсчету число единиц в числе A XOR B:
int bitSwapRequired(int a, int b) {
int count = 0;
for (int c = a ^ b; c != 0; c = c >> 1) {
count += c & 1;
}
return count;
}
Этот код хорош, но можно сделать его еще лучше. Вместо многократного сдвига для проверки значащего бита достаточно будет инвертировать младший ненулевой разряд и подсчитывать, сколько раз понадобится проделать эту операцию, пока число не станет равным нулю. Операция c = c & ( c — 1) очищает младший ненулевой бит числа c.
Приведенный далее код реализует данный метод:
public static int bitSwapRequired(int a, int b) {
int count = 0;
for (int c = a ^ b; c != 0; c = c & (c - 1)) {
count++;
}
return count;
}
Это одна из типичных задач на работу с битами, которые любят давать на собеседовании. Если вы никогда с ними не сталкивались, вам будет сложно сразу решить задачу, поэтому запомните использованные здесь трюки.
39. В книге N страниц, пронумерованных как обычно от 1 до N. Если сложить количество цифр, содержащихся в каждом номере страницы, будет 1095. Сколько страниц в книге?
У каждого числа, обозначающего страницу, имеется цифра на месте единиц. При N страниц имеется N цифр, стоящих на месте единиц.
У всех, за исключением первых 9 страниц, числа являются как минимум двухзначными. Поэтому добавим еще N-9 цифр.
У всех, за исключением первых 99 страниц, числа являются трехзначными, что добавляет еще N-99 цифр.
Я мог бы продолжать действовать так же и дальше, но лишь у небольшого числа книг количество страниц превышает 999. По крайней мере книга с общим числом цифр, равным 1095, к категории толстых не относится.
Из сказанного следует, что 1095 должно равняться:
N + (N - 9) + (N - 99).
Это равенство можно привести к более простой форме:
1095 = 3N - 108.
Из этого следует, что 3N = 1203 или N = 401.
Поэтому ответ таков: в книге 401 страница.
40. Задачка по С++, которая, тем не менее, будет полезна и для других языков. Сопоставьте хэш-таблицу и mар из стандартной библиотеки шаблонов (STL). Как организована хэш-таблица? Какая структура данных будет оптимальной для небольших объемов данных?
В хэш-таблицу значение попадает при вызове хэш-функции с ключом. Сами значения хранятся в неотсортированном порядке. Так как хэш-таблица использует ключ для индексации элементов, вставка или поиск данных занимает O(1) времени (с учетом минимального количества коллизий в хэш-таблицах). В хэш-таблице также нужно обрабатывать потенциальные коллизии. Для этого используется цепочка — связный список всех значений, ключи которых отображаются в конкретный индекс.
map(STL) вставляет пары ключ/значение в дерево двоичного поиска, основанное на ключах. При этом не требуется обрабатывать коллизии, а так как дерево сбалансировано, время вставки и поиска составляет O(log N).
Хэш-таблица реализуется как массив связных списков. Когда мы хотим вставить пару ключ/значение, то, используя хеш-функцию, отображаем ключ в индекс массива. При этом значение попадает в указанную позицию связного списка.
Нельзя сказать, что элементы связного списка с определенным индексом массива имеют один и тот же ключ. Скорее, функция hashFunction(key) для этих значений совпадает. Поэтому, чтобы получить значение, соответствующее ключу, мы должны хранить в каждом узле и ключ и значение.
Подведем итог: хэш-таблица реализуется как массив связных списков, где каждый узел списка содержит два компонента: значение и исходный ключ. Давайте перечислим особенности реализации хэш-таблиц:
Можно использовать mар (из STL) или бинарное дерево. Хотя это потребует O(log(n)) времени, объем данных не велик, поэтому временные затраты будут незначительными.
У дерева есть по крайней мере одно заметное преимущество по сравнению с хеш-таблицей. В map можно пройтись итератором по возрастанию или убыванию ключей и сделать это быстро. Хеш-таблица в этом плане проигрывает.
41. Разработайте класс, обеспечивающий блокировку так, чтобы предотвратить возникновение мертвой блокировки.
Существует несколько общих способов предотвратить мертвые блокировки. Один из самых популярных — обязать процесс явно объявлять, в какой блокировке он нуждается. Тогда мы можем проверить, будет ли созданная блокировка мертвой, и если так, можно прекратить работу.
Давайте разберемся, как обнаружить мертвую блокировку. Предположим, что мы запрашиваем следующий порядок блокировок:
А = {1, 2, 3, 4}
В = {1, 3, 5}
С = {7, 5, 9, 2}
Это приведет к мертвой блокировке, потому что:
А блокирует 2, ждет 3
В блокирует 3, ждет 5
С блокирует 5, ждет 2
Можно представить этот сценарий в виде графа, где 2 соединено с 3, а 3 соединено с 5, а 5 соединено с 2. Мертвая блокировка описывается циклом. Ребро (w, v) существует в графе, если процесс объявляет, что он запрашивает блокировку v немедленно после блокировки w. В предыдущем примере в графе будут существовать следующие ребра:
(1, 2), (2, 3), (3, 4), (1, 3), (3, 5), (7, 5), (5, 9), (9, 2)
«Владелец» ребра не имеет значения.
Этот класс будет нуждаться в методе declare, который использует потоки и процессы для объявления порядка, в котором будут запрашиваться ресурсы. Метод declare будет проверять порядок объявления, добавляя каждую непрерывную пару элементов (v, w) к графу. Впоследствии он проверит, не появилось ли циклов. Если возник цикл, он удалит добавленное ребро из графика и выйдет.
Нам нужно обсудить только один нюанс. Как мы обнаружим цикл? Мы можем обнаружить цикл с помощью поиска в глубину через каждый связанный элемент (то есть через каждый компонент графа). Существуют сложные компоненты, позволяющие выбрать все соединенные компоненты графа, но наша задача не настолько сложна.
Мы знаем, что если возникает петля, то виновато одно из ребер. Таким образом, если поиск в глубину затрагивает эти ребра, мы обнаружим петлю.
Псевдокод для этого обнаружения петли примерно следующий:
boolean checkForCycle(locks[] locks) {
touchedNodes = hash table(lock -> boolean)
//инициализировать touchedNodes, установив в false каждый lock в locks
for each (lock x in process.locks) {
if (touchedNodes[x] == false) {
if (hasCycle(x, touchedNodes)) {
return true;
}
}
}
return false;
}
boolean hasCycle(node x, touchedNodes) {
touchedNodes[r] = true;
if (x.state == VISITING) {
return true;
} else if (x.state == FRESH) {
//...(см. полный код ниже)
}
}
В данном коде можно сделать несколько поисков в глубину, но touchedNodes нужно инициализировать только один раз. Мы выполняем итерации, пока все значения в touchedNodes равны false.
Приведенный далее код более подробен. Для простоты мы предполагаем, что все блокировки и процессы (владельцы) последовательно упорядочены.
public class LockFactory {
private static LockFactory instance;
private int numberOfLocks = 5; /* по умолчанию */
private LockNode[] locks;
/* Отображаем процесс (владельца) в порядок,
* в котором владелец требовал блокировку */
private Hashtable<Integer, LinkedList<LockNode>> lockOrder;
private LockFactory(int count) { ... }
public static LockFactory getInstance() { return instance; }
public static synchronized LockFactory initialize(int count) {
if (instance == null)
instance = new LockFactory(count);
return instance;
}
public boolean hasCycle(Hashtable<Integer, Boolean> touchedNodes, int[] resourcesInOrder) {
/* проверяем на наличие петли */
for (int resource : resourcesInOrder) {
if (touchedNodes.get(resource) == false) {
LockNode n = locks[resource];
if (n.hasCycle(touchedNodes)) {
return true;
}
}
}
return false;
}
/* Чтобы предотвратить мертвую блокировку, заставляем процессы
* объявлять, что они хотят заблокировать. Проверяем,
* что запрашиваемый порядок не вызовет мертвую блокировку
* (петлю в направленном графе) */
public boolean declare(int ownerId, int[] resourcesInOrder) {
Hashtable<Integer, Boolean> touchedNodes = new Hashtable<Integer, Boolean>();
/* добавляем узлы в граф */
int index = 1;
touchedNodes.put(resourcesInOrder[0], false);
for (index = 1; index < resourcesInOrder.length; index++) {
LockNode prev = locks[resourcesInOrder[index - 1]];
LockNode curr = locks[resourcesInOrder[index]];
prev.joinTo(curr);
touchedNodes.put(resourcesInOrder[index], false);
}
/* если получена петля, уничтожаем этот список ресурсов
* и возвращаем false */
if (hasCycle(touchedNodes, resourcesInOrder)) {
for (int j = 1; j < resourcesInOrder.length; j++) {
LockNode p = locks[resourcesInOrder[j - 1]];
LockNode c = locks[resourcesInOrder[j]];
p.remove(c);
}
return false;
}
/* Петля не найдена. Сохраняем порядок, который был объявлен,
* так как мы можем проверить, что процесс действительно вызывает
* блокировку в нужном порядке */
LinkedList<LockNode> list = new LinkedList<LockNode>();
for (int i = 0; i < resourcesInOrder.length; i++) {
LockNode resource = locks[resourcesInOrder[i]];
list.add(resource);
}
lockOrder.put(ownerId, list);
return true;
}
/* Получаем блокировку, проверяем сначала, что процесс
* действительно запрашивает блокировку в объявленном порядке*/
public Lock getLock(int ownerld, int resourceID) {
LinkedList<LockNode> list = lockOrder.get(ownerId);
if (list == null) return null;
LockNode head = list.getFirst();
if (head.getId() == resourceID) {
list.removeFirst();
return head.getLock();
}
return null;
}
}
public class LockNode {
public enum VisitState { FRESH, VISITING, VISITED );
private ArrayList<LockNode> children;
private int lockId;
private Lock lock;
private int maxLocks;
public LockNode(int id, int max) { ... }
/* Присоединяем "this" в "node", проверяем, что мы не создадим этим
* петлю (цикл) */
public void joinTo(LockNode node) { children.add(node); }
public void remove(LockNode node) { children.remove(node); }
/* Проверяем на наличие цикла с помощью поиска в глубину */
public boolean hasCycle(Hashtable<Integer, Boolean> touchedNodes) {
VisitState[] visited = new VisitState[maxLocks];
for (int i = 0; i < maxLocks; i++) {
visited[i] = VisitState.FRESH;
}
return hasCycle(visited, touchedNodes);
}
private boolean hasCycle(VisitState[] visited,
Hashtable<Integer, Boolean> touchedNodes) {
if (touchedNodes.containsKey(lockId)) {
touchedNodes.put(lockId, true);
}
if (visited[lockId) == VisitState.VISITING) {
/* Мы циклично возвращаемся к этому узлу, следовательно,
* мы знаем, что здесь есть цикл (петля) */
return true;
} else if (visited[lockId] == VisitState.FRESH) {
visited[lockId] = VisitState.VISITING;
for (LockNode n : children) {
if (n.hasCycle(visited, touchedNodes)) {
return true;
}
}
visited[lockId] = VisitState.VISITED;
}
return false;
}
public Lock getLock() {
if (lock == null) lock = new ReentrantLock();
return lock;
}
public int getId() { return lockId; }
}
42. Напишите функцию на С++, выводящую в стандартный поток вывода K последних строк файла. При этом файл очень большой, допустим 50 ГБ, длина каждой строки не превышает 256 символов, а число K < 1000.
Можно действовать прямо — подсчитать количество строк (N) и вывести строки с N-K до N. Для этого понадобится дважды прочитать файл, что очень неэффективно. Давайте найдем решение, которое потребует прочитать файл только один раз и выведет последние K строк.
Можно создать массив для K строк и прочитать последние K строк. В нашем массиве там будут храниться строки от 1 до K, затем от 2 до K+1, затем от 3 до K+2 и т.д. Каждый раз, считывая новую строку, мы будем удалять самую старую строку из массива.
Вы можете удивиться: разве может быть эффективным решение, требующее постоянного сдвига элементов в массиве? Это решение станет эффективным, если мы правильно реализуем сдвиг. Вместо того чтобы каждый раз выполнять сдвиг массива, можно «закольцевать» массив.
Используя такой массив, читая новую строку, мы всегда будем заменять самый старый элемент. Самый старый элемент будет храниться в отдельной переменной, которая будет меняться при добавлении новых элементов.
Пример использования закольцованного массива:
шаг 1 (исходное состояние): массив = {a, b, с, d, е, f}. р = 0
шаг 2 (вставка g): массив = {g, b, с, d, е, f}. р = 1
шаг 3 (вставка h): массив = {g, h, с, d, е, f}. р = 2
шаг 4 (вставка i): массив = {g, h, i, d, e, f}. p = 3
Приведенный далее код реализует этот алгоритм:
void printLast10Lines(char* fileName) {
const int K = 10;
ifstream file (fileName);
string L[K];
int size = 0;
/* читаем файл построчно в круговой массив */
while (file.good()) {
getline(file, L[size % K]);
size++;
}
/* вычисляем начало кругового массива и его размер */
int start = size > K ? (size % K) : 0;
int count = min(K, size);
/* выводим элементы в порядке чтения */
for (int i = 0; i < count; i++) {
cout << L[(start + i) % K] << endl;
}
}
Мы считываем весь файл, но в памяти хранится только 10 строк.
43. Дан кусок сыра в форме куба и нож. Какое минимальное количество разрезов потребуется сделать, чтобы разделить этот кусок на 27 одинаковых кубиков? А на 64 кубика? После каждого разреза части можно компоновать как угодно.
Такую задачку раньше часто давали на собеседованиях, а придумана она была ещё в 1950 году.
Чтобы получить 27 маленьких кубиков, вам нужно разрезать каждую из трех граней куба на три части. Для получения трех частей нужны два разреза. Очевидный ответ – сделать эти разрезы параллельно друг другу по всем трем осям, для чего вам потребуется всего шесть разрезов.
НО! При подобных вопросах первый ответ, который появляется у вас в голове, обычно не является лучшим. Можно ли усовершенствовать ответ? Вспомните, что вы можете передвигать кусочки после каждого разреза (как это часто делают повара, когда режут лук). Это в значительной степени повышает число возможных вариантов, и тогда вы, может быть, отыщете тот, на который вначале не обратили внимания.
На самом деле, нет способа, позволяющего вам разрезать куб на 27 кусочков меньше, чем за шесть разрезов. В идеале вы должны доказать это. Покажем, как это можно сделать. Представьте маленький кубик, получившийся после разреза первоначального куба на 3 х 3 х 3 = 27 частей, и этот кубик находится в самой середине исходного куба. У этого кубика нет поверхности, граничащей с внешним миром. Поэтому вам придется создать каждую из его шести сторон при помощи ножа. Шесть прямых разрезов – это тот минимум, который нужен для решения этой задачи. Этот вопрос относится к категории обратных головоломок. Очевидно, первый ответ оказывается правильным, хотя многие пытаются придумать и неочевидные варианты.
По мнению Мартина Гарднера, автором этой загадки был Фрэнк Хоторн, директор отдела образования Нью-Йорка, который опубликовал ее в 1950 году. Идея перегруппировать части, чтобы уменьшить число разрезов, вовсе не такая сумасшедшая, какой может показаться. Так, в этом случае куб можно разрезать на 4 х 4 х 4 кубиков всего при помощи шести разрезов (при прежнем подходе понадобилось бы сделать девять разрезов).
В 1958 году Юджин Путцер и Лоуэн опубликовали общий вариант решения для разрезания куба на N х N х N кубиков. Они уверили всех практически мыслящих читателей, что их метод может иметь «важные последствия для отраслей, производящих сыр и кусковой сахар».
Этот вопрос отдаленно напоминает другой, который задают на собеседованиях в некоторых финансовых организациях: сколько кубиков находится в центре кубика Рубика? Поскольку такой стандартный кубик состоит из З х З х З частей, часто дают неправильный ответ – один. Однако любой человек, который когда-либо разбирал кубик Рубика, знает, что правильный ответ другой – ноль. В середине находится не кубик, а сферический шарнир.
44. Реализуйте метод, определяющий, является ли одна строка перестановкой другой. Под перестановкой понимаем любое изменение порядка символов. Регистр учитывается, пробелы являются существенными.
Для начала нужно уточнить детали. Следует разобраться, является ли сравнение анаграмм чувствительным к регистру. То есть является ли строка «God» анаграммой «dog»? Также нужно выяснить, учитываются ли пробелы.
Предположим, что для данной задачи регистр символов учитывается, а пробелы являются существенными. Поэтому строки « dog» и «dog» не совпадают.
Сравнивая две строки, помните, что строки разной длинны не могут быть анаграммами.
Существует два способа решить эту задачу.
Если строки являются анаграммами, то они состоят из одинаковых символов, расположенных в разном порядке. Сортировка двух строк должна упорядочить символы. Теперь остается только сравнить две отсортированные версии строк.
public String sort(String s) {
char[] content = s.toCharArray();
java.util.Arrays.sort(content);
return new String(content);
}
public boolean permutation (String s,String t) {
if (s.length() != t.length()) {
return false;
}
return sort(s).equals(sort(t));
}
Хотя этот алгоритм нельзя назвать оптимальным во всех смыслах, он удачен, поскольку его легко понять. С практической точки зрения это превосходный способ решить задачу. Однако если важна эффективность, нужно реализовывать другой вариант алгоритма.
Для реализации этого алгоритма можно использовать свойство анаграммы – одинаковые «счетчики» символов. Мы просто подсчитываем, сколько раз встречался каждый символ в строке. Затем сравниваем массивы, полученные для каждой строки.
public boolean permutation(String s, String t) {
if (s.length() != t.length()) {
return false;
}
int[] letters = new int[256];
char[] s_array = s.toCharArray();
for (char c : s_array) {
letters[c]++;
}
for (int i = 0; i < t.length(); i++) {
int c = (int) t.charAt(i);
if (--letters[c] < 0) {
return false;
}
}
return true;
}
Обратите внимание на строку 6. В данной реализации мы подразумеваем, что используется набор символов ASCII, но алфавит может быть разным.
45. В тёмной комнате вам вручают колоду карт, в которой известное количество карт N лежат рубашкой вверх, а остальные — вниз. Вы не можете видеть карты, но можете их переворачивать. Как вы разделите колоду на две стопки, чтобы в каждой из них было одинаковое число карт, лежащих рубашкой вверх?
Эта головоломка в своё время была популярна в JP Morgan Chase. Понятное дело, оказавшись в темноте, вы просто достанете сотовый телефон и воспользуетесь экраном как фонариком. Однако эта задачка появилась до эпохи сотовых телефонов, и её можно решить, даже не видя карт.
Эта головоломка в своё время была популярна в JP Morgan Chase. Понятное дело, оказавшись в темноте, вы просто достанете сотовый телефон и воспользуетесь экраном как фонариком. Однако эта задачка появилась до эпохи сотовых телефонов, и её можно решить, даже не видя карт. Вполне вероятно, вы начнете со следующих наблюдений.
Ожидаемый ответ заключается в том, что вы должны отсчитать N карт, начиная с верха колоды, и перевернуть их. Это будет одна стопка. Оставшаяся часть колоды составит вторую стопку.
Объясним, почему это работает. В N картах, которые вы отсчитали, может быть любое число карт, лежащих рубашкой вверх, от нуля до N. Представим, что там было (до переворачивания) f таких карт. Перевернув карты, вы добились, что каждая карта рубашкой вверх становится картой рубашкой вниз и наоборот. Поэтому вместо f карт рубашкой вверх вы приходите к варианту N-f карт рубашкой вверх в этой стопке.
В другой стопке, в которой содержится остаток колоды, имеется N карт, лежащих рубашкой вверх, за минусом тех f, которые вы отсчитали. Это то же самое количество, как в первой стопке с перевернутыми картами.
46. Реализуйте вручную стек со стандартными функциями push/pop и дополнительной функцией min, возвращающей минимальный элемент стека. Все эти функции должны работать за O(1). Решение оптимизируйте по использованию памяти.
Итак, оценка времени работы функция push, pop и min – O(1).
Экстремумы изменяются не часто. Фактически минимум может поменяться только при добавлении нового элемента.
Одно из решений – сравнивать добавляемые элементы с минимальным значением. Когда минимальное значение (minValue) удаляется из стека, приходится «перерывать» весь стек в поисках нового минимума. К сожалению, это нарушает ограничение на время выполнения О(1).
Если мы будем отслеживать минимум в каждом состоянии, то легко узнаем минимальный элемент. Можно, например, записывать для каждого узла текущий минимальный элемент, Затем, чтобы найти min, достаточно «вытолкнуть» вершину и посмотреть, какой элемент является минимальным.
Как только элемент помещается в стек, локальное значение минимума становится глобальным.
public class StackWithMin extends Stack<NodeWithMin> {
public void push(int value) {
int newMin = Math.min(value,min());
super.push(new NodeWithMin(value, newMin));
}
public int min() {
if (this.isEmpty()) {
return Integer.MAX_VALUE;
} else {
return peek().min;
}
}
}
class NodeWithMin {
public int value;
public int min;
public NodeWithMin(int v, int min) {
value = v;
this.min = min;
}
}
У решения один недостаток – если нужно обрабатывать огромный стек, то отслеживание минимального элемента потребует много ресурсов. Существует ли лучшее решение?
Оптимизировать код можно за счет использования дополнительного стека, который будет отслеживать минимумы.
public class StackWithMin2 extends Stack<Integer> {
Stack<Integer> s2;
public StackWithMin2() {
s2 = new Stack<Integer>();
}
public void push(int value) {
if (value <= min()) {
s2.push(value);
}
super.push(value);
}
public Integer pop() {
int value = super.pop();
if(value == min()) {
s2.pop();
}
return value;
}
public int min() {
if (s2.isEmpty()) {
return Integer.MAX_VALUE;
} else {
return s2.peek();
}
}
}
Почему такое решение более эффективно? Предположим, что мы работаем с огромным стеком, первый вставленный элемент автоматически станет минимумом. В первом решение необходимо хранить n чисел, где n – размер стека. Во втором решении достаточно сохранить несколько фрагментов данных.
47. У скольких целых чисел, лежащих в диапазоне от 1 до 1000, есть цифра 3? Посчитать нужно без использования компьютера, приведя свои рассуждения в комментариях.
Некоторые числа (например, 333) содержат больше одной 3. Вам не следует такие числа считать дважды, а то и трижды . Вопрос заключается в том, как много разных чисел имеет по крайней мере одну 3.
Каждое число от 300 до 399 содержит по крайней мере одну 3. В целом эта группа сразу дает сотню чисел.
Также имеется и сотня чисел, где тройка занимает место десяток: от 30 до 39; от 130 до 139; и так до чисел от 930 до 939. Десяток таких чисел мы уже учли раньше, а именно числа от 330 до 339. Поэтому десять этих чисел надо убрать, чтобы не было двойного счета. В совокупности мы пока отобрали 100 + 90 = 190 чисел.
И, наконец, имеется сотня чисел, оканчивающихся на 3 в диапазоне от 2 до 993. Не включайте в их число 10 чисел, которые начинаются с 3 (303, 313, 323,…, 393), потому что мы их уже включили раньше. Получается еще 90 чисел. У одной десятой из этих 90 чисел на месте десяток стоит 3 (33, 133, 233,…, 933). Уберем эти 9 чисел, остается 81 число. Теперь можно определить общее число интересующих нас чисел.
Оно равно 100 + 90 + 81 = 271.
Да, вполне.
Сначала узнаем, сколько чисел не имеют 3 в своей записи. Для этого на каждое место ставим 9 цифр, не включающие 3 т.е. 9 * 9 * 9 = 729. Если всего чисел 1000, то ответ 1000 — 729 = 271.
48. У вас есть много URL-адресов, порядка 10 миллиардов. Как бы вы организовали эффективный поиск дубликатов, учитывая, что все они, конечно же, не поместятся в памяти?
Сложность задачи заключается в том, что адресов дано 10 миллиардов. Сколько пространства понадобится для хранения 10 миллиардов URL-адресов? Если в среднем URL-адрес занимает 100 символов, а каждый символ представляется 4 байтами, то для хранения списка из 10 миллиардов URL понадобится около 4 Тбайт. Скорее всего, нам не понадобится хранить так много информации в памяти.
Давайте попробуем сначала решить упрощенную версию задачи. Представим, что в памяти хранится весь список URL. В этом случае можно создать хэш-таблицу, где каждому дублирующемуся URL ставится в соответствие значение true (альтернативное решение: можно просто отсортировать список и найти дубликаты, это займет некоторое время, но даст и некоторые преимущества).
Теперь, когда у нас есть решение упрощенной версии задачи, можно перейти к 400 Гбайт данных, которые нельзя хранить в памяти полностью. Давайте сохраним некоторую часть данных на диске или разделим данные между компьютерами.
Если мы собираемся хранить все данные на одной машине, то нам понадобится двойной проход документа. На первом проходе мы разделим список на 400 фрагментов по 1 Гбайт в каждом. Простой способ — хранить все URL-адреса и в файле <x>.txt, где х = hash(u) % 400. Таким образом, мы разбиваем URL-адрсса по хэш-значениям. Все URL-адреса с одинаковым хэш-значением окажутся в одном файле.
На втором проходе можно использовать придуманное ранее решение: загрузить файл в память, создать хэш-таблицу URL-адресов и найти повторы.
Этот алгоритм очень похож на предыдущий, но для хранения данных используются разные компьютеры. Вместо того чтобы хранить данные в файле <x>.txt, мы отправляем их на машину х.
У данного решения есть преимущества и недостатки.
Основное преимущество заключается в том, что можно организовать параллельную работу так, чтобы все 400 блоков обрабатывались одновременно. Для больших объемов данных мы получаем больший выигрыш во времени.
Недостаток заключается в том, что все 400 машин должны работать без сбоев, что на практике (особенно с большими объемами данных и множеством компьютеров) не всегда получается. Поэтому необходимо предусмотреть обработку отказов.
Оба решения хороши и оба имеют право на существование.
49. Вы должны выбрать одну из двух ставок. При первом варианте вы должны забросить баскетбольный мяч в корзину за один бросок. Если попадёте, то получите 50 тыс. рублей. Во втором варианте вам надо попасть два раза из трёх бросков, и тогда вы также получите те же 50 тыс. рублей. Какой из этих вариантов вы предпочтёте? Будет ли ваше умение забрасывать мячи влиять на выбор?
Обозначим вероятность попадания в корзину р. При первом броске у вас шанс выигрыша 50 тыс. рублей равен р. В случае промаха вы ничего не получите. В среднем можно ожидать, что ваш выигрыш составит 50 000 ? р.
При втором варианте вы бросаете три раза и должны попасть в корзину дважды, чтобы получить деньги. Вероятность попадания при каждой отдельной попытке по-прежнему составляет р. Вероятность промаха при любой попытке равна 1 — p.
При втором варианте имеется 23, или 8, сценариев развития. Давайте перечислим их в виде таблички. Знак ? означает, что вы попали, пустое место свидетельствует о том, что вы промахнулись.
Первый сценарий относится к ситуации, когда вы полностью провалили игру. Вы промазали при всех трёх бросках. Вероятность такого исхода составляет 1 — р, умноженная сама на себя три раза. Разумеется, при таком развитии событий никаких денег вы не получите.
| Первый бросок | Второй бросок | Третий бросок | Вероятность | Выиграли ли вы 50 тыс. рублей? |
| (1 — p)3 | Нет | |||
| ✓ | p(1 — p)2 | Нет | ||
| ✓ | p(1 — p)2 | Нет | ||
| ✓ | ✓ | p2(1 — p) | Да | |
| ✓ | p(1 — p)2 | Нет | ||
| ✓ | ✓ | p2(1 — p) | Да | |
| ✓ | ✓ | p2(1 — p) | Да | |
| ✓ | ✓ | ✓ | p3 | Да |
В четырех из восьми сценариев вы выигрываете деньги. В трёх из них вы промахиваетесь один раз. У этих сценариев вероятность составляет p2(1 — p). В одном случае вы попадаете все три раза, вероятность чего равна p3. Сложите все эти вероятности. Три раза p2(1 — p) можно представить в виде 3p2 — 3p3. Добавьте к этой сумме p3, и вы получите 3p2 — 2p3. Ожидание составляет 50 000 x (3p2 — 2p3).
Какой из вариантов для вас лучше?
Ожидание при первом варианте: 50 000 x р.
Ожидание при втором варианте: 50 000 x (3p2 — 2p3).
Вы можете быть полным профаном в баскетболе (р приблизительно равно 0) или мастером бросков, играющим в НБА. В качестве ссылки сделаем то, чего вы не сделаете на собеседовании, если вам дадут такую задачу: переведём формулу в электронную таблицу и составим график. Этот график показывает, как меняется ожидаемая величина выигрыша в зависимости от р.
Прямая диагональная линия отражает первый вариант ставки, S-образная кривая – второй. Первый вариант лучше для вас, если ваши шансы на попадание в корзину ниже 50%. В противном случае вам лучше выбрать второй вариант.
Это вполне объяснимо. Плохой игрок не может надеяться на победу ни при том, ни при другом варианте. Он должен рассчитывать лишь на слепую удачу, которая, очевидно, случится, скорее всего, один раз, а не дважды. Поэтому плохому игроку лучше выбрать первый вариант. Очень хороший игрок должен победить при любой ставке, хотя есть небольшая вероятность, что при единственном броске он промахнётся. Два из трех бросков лучше отражают степень его мастерства, и поэтому он захочет выбрать этот вариант. Существует юридическое правило: если вы виноваты, вы хотите, чтобы ваше дело рассматривал суд присяжных (потому что всё может случиться); если невиновны, для вас лучше, чтобы ваше дело рассматривал один судья.
Если вы дошли в своих рассуждениях до этого момента, то интервьюер на собеседовании задаст вам следующий вопрос: какое значение р заставит вас перейти от одного варианта к другому? Чтобы ответить на этот вопрос, приравняйте вероятности выигрыша в обеих ставках. Вы получите уровень мастерства, при котором выбор ставки можно сделать путем подбрасывания монеты.
p = 3p2 — 2p3
Разделите обе части уравнения на p:
1 = 3p — 2p2,
и тогда вы получите
2p2 — 3p + 1 = 0.
Добравшись до этого места, вы можете просто решить это квадратное уравнение, мысленно поблагодарив своего школьного учителя математики. Интервьювер отметит не только знание вами материала учебника, но и то, как живо вы выполните эти вычисления. Вы знаете, что р – вероятность – должна быть между 0 и 1. Лучше всего попробовать разумное значение: «Хорошо, мне необходимо число от 0 до 1. Давайте попробуем 0.5». Такой ответ сработает.
50. Представьте себе треугольник, составленный из чисел. Одно число расположено в вершине. Ниже размещено два числа, затем три, и так до нижней грани. Вы начинаете на вершине, и нужно спуститься к основанию треугольника. За каждый ход вы можете спуститься на один уровень и выбрать между двумя числами под текущей позицией. По ходу движения вы «собираете» и суммируете числа, которые проходите. Ваша цель — найти максимальную сумму, которую можно получить из различных маршрутов.
Какой алгоритм вы предложите? Какая у него будет сложность и можно ли предложить лучший вариант?
В этом выпуске рассмотрим классическую задачу, известную под названием «Золотая гора». На CheckiO её реализовали в этой задаче.
Представьте себе треугольник, составленный из чисел. Одно число расположено в вершине. Ниже размещено два числа, затем три, и так до нижней грани. Вы начинаете на вершине, и нужно спуститься к основанию треугольника. За каждый ход вы можете спуститься на один уровень и выбрать между двумя числами под текущей позицией. По ходу движения вы «собираете» и суммируете числа, которые проходите. Ваша цель – найти максимальную сумму, которую можно получить из различных маршрутов.
Рассмотрим различные методы решения.
Первым делом в голову приходит мысль использовать рекурсию и просчитать все пути от вершины. Когда мы спускаемся на один уровень, то все доступные числа ниже образуют новый меньший треугольник, и можно запустить нашу функцию уже для нового подмножества и так пока не достигнем основания.
def golden_pyramid(triangle, row=0, column=0, total=0):
global count
count += 1
if row == len(triangle) - 1:
return total + triangle[row][column]
return max(golden_pyramid(triangle, row + 1, column, total + triangle[row][column]),
golden_pyramid(triangle, row + 1, column + 1, total + triangle[row][column]))
Как мы видим, на первом уровне мы запустим нашу функцию два раза, затем 4, 8, 16 раз и так далее. В итоге мы получим сложность алгоритма 2N и, например, для 100-уровневой пирамиды нам нужно будет уже где-то ?1030 вызовов функции. Многовато.
Что если попробовать использовать принцип динамического программирования и разбить нашу проблему на множество мелких подзадач, результаты которых мы затем аккумулируем. Попробуйте взглянуть на треугольник вверх ногами. А теперь на второй уровень (то есть предпоследний от основания). Для каждой ячейки мы можем решить, каким будет лучший выбор в наших маленьких трёхэлементных треугольничках. Выбираем лучший, суммируем с рассматриваемой ячейкой и записываем результат. Таким образом, мы получили наш треугольник, но на один уровень ниже. Повторяем данную операцию снова и снова. В результате нам нужно (N-1)+(N-2)+…2+1 операций и сложность алгоритма равна N2.
def golden_pyramid_d(triangle):
tr = [row[:] for row in triangle] # copy
for i in range(len(tr) - 2, -1, -1):
for j in range(i + 1):
tr[i][j] += max(tr[i + 1][j], tr[i + 1][j + 1])
return tr[0][0]
Пользователь gyahun_dash написал интересную реализацию описанного выше метода ДП в своем решении «DP». Он использовал reduce, чтобы проходить по парам строк, и map чтобы обработать каждую из них.
from functools import reduce
def sum_triangle(top, left, right):
return top + max(left, right)
def integrate(lowerline, upperline):
return list(map(sum_triangle, upperline, lowerline, lowerline[1:]))
def count_gold(pyramid):
return reduce(integrate, reversed(pyramid)).pop()
Игрок evoynov использовал двоичные числа, чтобы перебрать все возможные маршруты, представленные как последовательность 1 и 0 в своем решении «Binaries». И это наглядный пример сложности алгоритма с рекурсией и перебором всех маршрутов.
def count_gold(p):
path = 1 << len(p) res = 0 while bin(path).count("1") != len(p) + 1: s = ind = 0 for row in range(len(p)): ind += 1 if row > 0 and bin(path)[3:][row] == "1" else 0
s += p[row][ind]
res = max(res, s)
path += 1
return res
И чтобы не было скучно, посмотрим на легкий мозгодробитель от пользователя nickie и его однострочник «Functional DP», который только формально состоит из двух строк. Конечно, это решение из категории «Творческих» («Creative»). Не думаю, что автор использует такое на боевом коде. А просто для так для веселья, почему бы и нет.
ount_gold=lambda p:__import__("functools").reduce(lambda D,r:[x+max(D[j],D[j+1])
for j,x in enumerate(r)],p[-2::-1],list(p[-1]))[0]
Вот и всё на сегодня. Делитесь вашими идеями и мыслями.
51. Даны два слова или фразы, и ваша задача — проверить, являются ли они анаграммами.
Анаграмма — это игра со словами, когда в результате перестановки букв слова или фразы получаем другое слово или фразу. Два слова являются анаграммами, если мы можем получить одно из другого переставляя буквы местами.

На этот раз будем изучать задачу «Проверка анаграмм» («Verify Anagrams»).
Мы уже писали об этой задаче ранее, но теперь расскажем о ней немного другим способом.
Анаграмма — это игра со словами, когда в результате перестановки букв слова или фразы получаем другое слово или фразу. Два слова являются анаграммами, если мы можем получить одно из другого переставляя буквы местами. Даны два слова или фразы, и ваша задача — проверить, являются ли они анаграммами.
Итак, нам нужно сравнить две фразы. Для начала нам нужно их «обработать»: выбрать только буквы и перевести их в нижний регистр. Также, на этом шаге мы можем преобразовать строку в массив. Вынесем эту процедуру в отдельную функцию.
def sanitize(text): return [ch.lower() for ch in text if ch.isalpha()]
Или, если вы бережете память и предпочитаете генераторы:
def sanitize(text): yield from (ch.lower() for ch in text.lower() if ch.isalpha())
Или любите функциональный стиль программирования:
sanitize = lambda t: map(str.lower, filter(str.isalpha, text))
Далее нам нужно сосчитать каждую букву в тексте, и, если количественные характеристики проверяемых слов/фраз совпадают, то они анаграммы. Предположим, что мы используем только английские буквы. Тогда мы можем использовать массив из 26 элементов для ведения счета.
def count_letters(text):
counter = [0] * 26
for ch in text:
counter[ord(ch) - ord("a")] += 1
return counter
Честно говоря, это выглядит как код написанный на С, но никак не на Python. Кроме того, мы привязаны жестко к английскому алфавиту. Давайте заменим список на словарь (dictionary).
def count_letters(text):
counter = {}
for ch in text:
counter[ch] = counter.get(ch, 0) + 1
return counter
Уже лучше, но известный девиз Python гласит — «Батарейки прилагаются». И класс Counter дает возможность просто подсчитать буквы в тексте.
from collections import Counter def count_letters(text): return Counter(text)
Думаю, вы и сами видите, что наша отдельная функция count_letters уже не так уж и нужна, и итоговое решение можно записать так:
from collections import Counter def sanitize(text): yield from (ch.lower() for ch in text.lower() if ch.isalpha()) def verify_anagrams(first, second): return Counter(sanitize(first)) == Counter(sanitize(second))
Когда я решал первый раз эту задачу, я не использовал счетчики. Вместо этого я преобразовывал текст в некий универсальный вид для перестановок. Конечно, я говорю об упорядоченном виде. Если мы отсортируем строки и сравним их, то это по сути то же самое, что считать элементы массива. И, так как в нашей задаче текст содержит только буквы и пробелы, то можно использовать один трюк:
def verify_anagrams(first, second): return "".join(sorted(first.lower())).strip() == "".join(sorted(second.lower())).strip()
Как можно заметить, мы одним движением руки можем преобразовать эту функцию в однострочник (забавы ради):
verify_anagrams=lambda f,s,p=lambda x: "".join(sorted(x.lower())).strip():p(f)==p(s)
Вот такая вот история об анаграммах.
52. Предложите алгоритм, который обнуляет столбец N и строку M матрицы, если элемент в ячейке (N, M) нулевой. Конечно же, нужно минимизировать затраты памяти и время работы.
На первый взгляд задача очень проста – просто пройтись по матрице и для каждого нулевого элемента обнулить соответствующие строку и столбец. Но у такого решения есть один большой недостаток: на очередном шаге мы столкнемся с нулями, которые сами же установили. Невозможно будет понять, установили эти нули мы сами или они присутствовали в матрице изначально. Довольно скоро вся матрица обнулится.
Один из способов – создать вторую матрицу, содержащую флаги исходных нулей. Но тогда потребуется сделать два прохода по матрице,что потребует O(N*M).
Так ли нам нужно O(N*M)? Нет. Так как мы собираемся обнулять строки и столбцы, нет необходимости запоминать значения этих элементов. Пусть ноль находится в ячейке [2][4]. Это означает, что необходимо обнулить строку 2 и столбец 4. А если мы обнуляем эти строку и столбец, то зачем их запоминать?
Приведенный ниже код реализует наш алгоритм. Мы используем два массива, чтобы отследить все строчки и столбцы с нулями. После чего делаем второй проход и расставляем нули на основании созданного массива.
public void setZeros(int[][] matrix) {
boolean[] row = new boolean[matrix.length];
boolean[] column = new boolean[matrix[0].length];
for (int i = 0; i < matrix.length; i++) {
for (int j = 0; j < matrix[0].length; j++) {
if (matrix[i][j] == 0) {
row[i] = true;
column[j] = true;
}
}
}
for (int i = 0; i < matrix.length; i++) {
for (int j = 0; j < matrix[0].length; j++) {
if (row[i] || column[j]) {
matrix[i][j] = 0;
}
}
}
}
Для оптимизации можно использовать вместо булева массива бинарный массив.
53. Разработайте алгоритм, обнаруживающий в массиве все пары целых чисел, сумма которых равна заданному значению.
Эту задачу можно решить двумя способами. Выбор определяется компромиссом между эффективностью использования времени, памяти или сложностью кода.
Очень простое и эффективное (по времени) решение — создание хэш-таблицы, отображающей целое число в целое число. Данный алгоритм работает, пошагово проходя весь массив. Для каждого элемента x в хэш-таблице ищется sum – x и, если запись существует, выводится (x, sum — x). После этого x добавляется в таблицу и проверяется следующий элемент.
Давайте начнем с формулировки. Если мы попытаемся найти пару чисел, сумма которых равна z, то дополнение будет z – x (величина, которую нужно добавить к x, что бы получить z). Если мы попытаемся найти пару чисел, при суммировании которых получается 12, дополнением к -5 будет число 17.
Представьте, что у нас есть отсортированный массив {-2, -1, 0, 3, 5, 6, 7, 9, 13, 14}. Пусть first указывает на начало массива, а last — на его конец. Чтобы найти дополнение к first, мы двигаем last назад, пока не найдем искомую величину. Если first + last < sum, то дополнения к first не существует. Можно также перемещать first на встречу к last. Тогда мы остановимся, если first окажется больше, чем last.
Почему такое решение найдет все дополнения к first? Поскольку массив отсортирован, мы проверяем меньшие числа. Когда first + last меньше sum, нет смысла проверять меньшие значения, они не помогут найти дополнение.
Почему данное решение найдет все дополнения last? Потому что все пары формируются с помощью first и last. Мы нашли все дополнения first, а значит, нашли все дополнения last.
void printPairSums (int[] array, int sum) {
Arrays.sort(array);
int first = 0;
int last = array.length - 1;
while (first < last) {
int s = array[first] + array[last];
if (s == sum) {
System.out.printIn(array[first] + "" + array[last]);
first++;
last--;
} else {
if (s < sum) first++;
else last--;
}
}
}
54. Предположим, вам нужно разработать алгоритм, демонстрирующий круг знакомств человека для социальных сетей. Как бы вы это сделали, при условии, что база очень большая?
Под большой базой подразумевается порядка миллиарда зарегистрированных пользователей и не менее 100 миллиардов «дружеских» связей между ними.
Предположим, что нам требуется разработать алгоритм, демонстрирующий связи человека с человеком, но при условии, что база очень большая. Например, для использования в Facebook или LinkedIn.
Хороший способ решить эту задачу — устранить ограничения и сначала разобраться с упрощенной версией.
Прежде всего, давайте забудем, что имеем дело с миллионами пользователей. Найдем решение для простого случая.
Можно создать граф и рассматривать каждого человека как узел, а существование связи между двумя узлами говорит, что пользователи — друзья.
class Person {
Person[] friends;
// Другая информация
}
При необходимости нахождения связи между людьми, очевидно, стоит использовать всеми известный алгоритм поиска в ширину.
Почему не в глубину? Это очень неэффективно. Два пользователя могут быть «соседями», но нам придется просмотреть миллионы узлов в их поддеревьях, прежде чем связь обнаружится.
Когда мы имеем дело с огромными сервисами Linkedln или Facebook, то не можем хранить все данные на одном компьютере. Это означает, что простая структура данных Person не будет работать — наши друзья могут оказаться на разных компьютерах. Таким образом, нам нужно заменить списки друзей списками их ID и работать с ними следующим образом:
int machine_index = getMachineIDForUser(personID).Person friend = getPersonWithID(person_id).Приведенный далее код демонстрирует этот процесс. Мы определили класс Server, хранящий список всех компьютеров, и класс Machine, представляющий отдельную машину. У обоих классов есть хэш-таблицы, обеспечивающие эффективный поиск данных.
public class Server {
HashMap<Integer, Machine) machines = new HashMap<Integer, Machine>();
HashMap<Integer, Integer) personToMachineMap = new HashMap<Integer, Integer>();
public Machine getMachineWithId(int machinelD) {
return machines.get(machineID);
}
public int getMachineIDForUser(int personID) {
Integer machinelD = personToMachineMap.get(personID);
return machineID == null ? -1 : machineID;
}
public Person getPersonWithID(int personID) {
Integer machineID = personToMachineMap.get(personID);
if (machineID == null)
return null;
Machine machine = getMachineWithId(machineID);
if (machine == null) return null;
return machine.getPersonWithID(personID);
}
}
public class Person {
private ArrayList<Integer> friendIDs;
private int personID;
public Person(int id) { this.personID = id; }
public int getID() { return personID; }
public void addFriend(int id) { friends.add(id); }
}
public class Machine {
public HashMap<Integer, Person> persons = new HashMap<Integer, Person>();
public int machinelD;
public Person getPersonWithID(int personID) {
return persons.get(personID);
}
}
Существует несколько направлений оптимизации и дополнительные вопросы, которые следует обсудить.
«Путешествие» с одной машины на другую — дорогая операция (с точки зрения системных ресурсов). Вместо перехода с машины на машину в произвольном порядке работайте в пакетном режиме. Например, если пять друзей «живут» на одной машине, сначала получите информацию о них.
Чаще всего друзья живут в одной и той же стране. Вместо того чтобы делить данные о пользователях по произвольному принципу, попытайтесь использовать информацию о стране, городе, состоянии и т. д. Эго сократит количество переходов между машинами.
При поиске в ширину мы устанавливаем флаг visited для посещенных узлов и храним его в классе узла. В нашем случае так поступать нельзя. Поскольку одновременно выполняется множество запросов, данный подход помешает редактировать данные. Вместо этого можно имитировать маркировку узлов с помощью хэш-таблицы, в которой будет храниться id узла и отметка, посещен он или нет.
Это всего лишь некоторые из множества вопросов, которые могут возникнуть у вас при реализации такого алгоритма.
55. Допустим, у вас есть однонаправленный список с петлёй. Его «последний» элемент содержит указатель на один из элементов этого же списка, причём не обязательно на первый. Ваша задача — найти начальный узел петли.
Элементы списка менять нельзя, память можно использовать только константную.
Эта задача является разновидностью классической задачи, задаваемой на собеседованиях, — определить, содержит ли связный список петлю. Давайте используем подход «Сопоставление с образцом».
Простейший способ выяснить есть ли в связном списке петля,— использовать метод бегунка (быстрый/медленный). FastRunner делает два шага за один такт, а SlowRunner — только один. Подобно двум гоночным автомобилям, мчащимся по одной трассе разными путями, они непременно должны встретиться.
Проницательный читатель может задать вопрос: может ли быстрый бегунок «перепрыгнуть» медленный без столкновения? Это невозможно. Допустим, что FastRunner перепрыгнул через SlowRunner и теперь находится в элементе i+1 (а медленный – в i). Это означает, что на предыдущем шаге SlowRunner был в точке i-1, а FastRunner — ((i+1)-2)=i-1. Следовательно, столкновение неизбежно.
Давайте введем обозначение: k – длина связного списка в разомкнутом виде. Как узнать, когда FastRunner и SlowRunner встретятся, используя алгоритм из части 1?
Мы знаем, что FastRunner перемещается в два раза быстрее, чем SlowRunner. Поэтому когда SlowRunner через k шагов попадет в петлю, FastRunner пройдет 2k шагов. Поскольку k существенно больше, чем длина петли, введем обозначение K=mod(k, LOOP_SIZE).
В каждом последующем шаге FastRunner и SlowRunner становятся на шаг (или два шага) ближе к цели. Поскольку система замкнута, когда A перемещается на q, оно становится на q шагов ближе к B.
Можно установить следующие факты:
Когда же они встретятся? Если FastRunner на LOOP_SIZE – K шагов отстает от SlowRunner, а FastRunner нагоняет его со скоростью 1 шаг за единицу времени, они встретятся через LOOP_SIZE- k шагов. В этой точке они будут отстоять на k шагов от начала петли. Давайте назовем эту точку CollisionSpot.
Мы теперь знаем, что CollisonSpot – это k узел до начала петли. Поскольку K=mod(k, LOOP_SIZE) (или k=K+M*LOOP_SIZE для любого целого M), можно сказать, что до начала петли k узлов. Если узел N-2 узла в петле из 5 элементов, то элементы 7, 12 и даже 397 принадлежать петле.
Поэтому и CollisionSpot, и LinkedListHead находятся в k узлах от начала петли.
Если мы сохраним один указатель в CollisionSpot и переместим другой в LinkedListHead, то каждый из них будет отстоять на k узлов от LoopStart. Перемещение этих указателей заставит их столкнуться — на сей раз через k шагов – в точке LoopStart. Все, что нам нужно сделать, — возвратить этот узел.
FastPointer двигается в два раза быстрее, чем SlowPointer. Через k узлов SlowPointer оказывается в петле, а FastPointer – на k-м узле связного списка. Это означает, что FastPointer и SlowPointer отделяют друг от друга LOOP_SIZE-k узлов.
Если FastPointer двигается на 2 узла за одиночный шаг SlowPointer, указатели будут сближаться на каждом цикле и встретятся через LOOP_SIZE-k циклов. В этой точке они окажутся на расстоянии k узлов от начала петли.
Начало связного списка расположено в k узлах от начала петли. Следовательно, если мы сохраним быстрый указатель в текущей позиции, а затем переместим медленный в начало связного списка, точка встречи окажется в начале петли.
Давайте запишем алгоритм, воспользовавшись информацией из частей 1-3:
Следующий код реализует описанный алгоритм:
LinkedListNode FindBegining(LinkedListNode head) {
LinkedListNode slow = head;
LinkedListNode fast = head;
/*Находим первую точку встречи LOOP_SIZE-k шагов по связному списку.*/
while (fast != null && fast.next != null) {
slow = slow.next;
fast = fast.next.next;
if (slow == fast) { //Коллизия
break;
}
}
/* Ошибка - нет точки встречи, следовательно, нет петли */
if (fast == null || fast.next == null) {
return null;
}
/* Перемещаем медленный бегунок в начало списка (Head). Быстрый остается
в точке встречи.
*Каждые k шагов от Loop Start. Если указатели продолжат
движение с той же скоростью, то
* встретятся в точке Loop Start. */
slow = head;
while (slow != fast) {
slow = slow.next;
fast = fast.next;
}
/* Возвращаем точку начала петли. */
return fast;
}
56. На острове существует правило — голубоглазые люди не могут там находиться. Самолет улетает с острова каждый вечер в 20:00. Все жители собираются за круглым столом ежедневно, каждый человек может видеть цвет глаз других людей, но не знает цвет собственных. Никто не имеет права сказать человеку, какой у него цвет глаз. На острове находится не менее одного голубоглазого человека. Сколько дней потребуется, чтобы все голубоглазые уехали?
На острове существует правило — голубоглазые люди не могут там находиться. Самолет улетает с острова каждый вечер в 20:00. Все жители собираются за круглым столом ежедневно, каждый человек может видеть цвет глаз других людей, но не знает цвет собственных. Никто не имеет права сказать человеку, какой у его цвет глаз. На острове находится не менее одного голубоглазого человека. Сколько дней потребуется, чтобы все голубоглазые уехали?
Давайте используем подходы «базовый случай» и «сборка». Предположим, что на острове находится N голубоглазых людей. Мы знаем, что N > 0.
Предположим, что все люди на острове достаточно умны. Если известно, что на острове есть только один голубоглазый человек, то, обнаружив, что у всех глаза не голубые, он придет к выводу, что он и является тем единственным голубоглазым человеком, которому следует улететь вечерним рейсом.
Два человека с голубыми глазами видят друг друга, но не знают, чему равно c: c = 1 или c = 2. Из предыдущего случая известно, что если c = 1, то голубоглазый человек может себя идентифицировать и покинуть остров в первый же вечер. Если голубоглазый человек находится на острове (c = 2), это означает, что человек, видящий только одного голубоглазого, сам голубоглаз. Оба человека должны будут вечером покинуть остров.
Давайте использовать ту же логику. Если N = 3, то эти три человека сразу увидят, что на острове есть еще 2 (или 3) человека с голубыми глазами. Если бы таких людей было двое, они покинули бы остров накануне. Поскольку на острове все еще остаются голубоглазые люди, то любой человек может прийти к заключению, что c = 3 и что у него голубые глаза. Все они уедут той же ночью.
Такой шаблон можно использовать для произвольного значения N — если на острове находится N человек с голубыми глазами, понадобится N ночей, чтобы все они покинули остров.
57. Напишите код, удаляющий дубликаты из несортированного связного списка. Можно использовать только константную память.
Дополнительное задание. Как вы будете решать задачу, если запрещается использовать временный буфер?
Что бы удалить копии из связного списка, их нужно сначала найти. Для этого подойдет простая хэш-таблица. В приведенном далее решении выполняется проход по списку, каждый элемент которого добавляется в хэш-таблицу. Когда обнаруживается повторяющийся элемент, он удаляется, и цикл продолжает работу. За счет использования связного списка всю задачу можно решить за один проход.
public static void deleteDups (LinkedListNode n) {
Hashtable table = new Hashtable();
LinkedListNode previous = null;
while (n != null) {
if (table.containsKey(n.data)) {
previous.next = n.next;
} else {
table.put(n.data, true);
previous = n;
}
n = n.next;
}
}
Приведенное решение потребует O(N) времени, где N – количество элементов в связном списке.
В этом случае мы можем реализовать цикл с помощью двух указателей: current (работает через связный список) и runner (проверяет все последующие узлы на наличие дубликатов).
public static void deleteDups (LinkedListNode head) {
if (head == null) return;
LinkedListNode current = head;
while (current != null) {
/* Удаляем все следующие узлы с таким же значением */
LinkedListNode runner = current;
while (runner.next != null) {
if (runner.next.data == current.data) {
runner.next = runner.next.next;
} else{
runner = runner.next;
}
}
current = current.next;
}
}
Данный код требует всего O(1) пространства, но занимает O(N2) времени.
58. Напишите метод, тасующий карточную колоду. Колода должна быть идеально перемешана т.е. перестановки карт должны быть равновероятными. Вы можете использовать идеальный генератор случайных чисел.
Это очень популярная задача и известный алгоритм. Если вы еще не знакомы с решением, читайте дальше.
Давайте будем решать задачу «в лоб». Можно выбрать карты в произвольном порядке и поместить их в новую колоду. Фактически колода представляет собой массив, следовательно, нам нужен способ, позволяющий заблокировать отдельные элементы.
Исходная колода (до выбора 4): [1] [2] [3] [4] [5] /* Выбираем случайный элемент для помещения его в начало перетасованной колоды * Помечаем элемент в оригинальной колоде как "заблокированный", чтобы * не выбрать его снова */ Перемешанная колода (после выбора 4): [4] [?] [?] [?] [?] Исходная колода (после выбора 4): [1] [2] [3] [X] [5]
Если мы пометим элемент [4], что помешает выбрать его еще раз? Один из способов – поменять местами «мертвый» ([4]) и первый элементы колоды:
Исходная колода (до выбора 4): [1] [2] [3] [4] [5] /* Выбираем случайный элемент для перемещения его в начало перетассованной колоды * Существует элемент 1, который заменит выбранный элемент. */ Перемешанная колода (после выбора 4): [4] [?] [?] [?] [?] Исходная колода (после выбора 4): [X] [2] [3] [1] [5] /* Выбираем случайный элемент для перемещения его в начало * перетасованной колоды. Есть элемент 2, который заменит только что * выбранный элемент */ Перетасованная колода (после выбора 3): [4] [3] [?] [?] [?] Исходная колода (после выбора 3): [X] [X] [2] [1] [5]
Алгоритм проще реализовать для ситуации, когда «мертвы» первые k карт, чем для ситуации, когда, например, «мертвы» третья, четвертая и девятая карты.
Оптимизировать алгоритм можно, объединив перемешанную и исходную колоды вместе.
Исходная колода (до выбора 4): [1] [2] [3] [4] [5] /*Выбираем случайный элемент между 1 и 5 и меняем его местами с 1. * В этом примере мы выбрали элемент 4. * После этого элемент 1 - "мертв" */ Исходная колода (после выбора 4): [4] [2] [3] [1] [5] /* Элемент 1 "мертв". Выбираем случайный элемент для замены с * элементом2. В этом примере пусть мы выберем элемент * 3.*/ Исходная колода (после выбора 3): [4] [3] [2] [1] [5] /* Повторяем. Для всех i между 0 и n-1 меняем местами случайный элемент j * (j >= i, j < n) и элемент i. */
Этот алгоритм легко реализовать итеративно:
public void shuffleArray(int[] cards) {
int temp, index;
for (int i = 0; < cards.length; i++) {
/*Карты с индексами от 0 до i-1 уже были выбраны
* (они перемещены в начало массива), поэтому сейчас мы
* выбираем случайную карту с индексом, больше или равным i
* */
index = (int) (Math.random() * (cards.length - i)) + i;
temp = cards[i];
cards[i] = cards[index];
cards[index] = temp;
}
}
Подобный алгоритм можно придумать и самостоятельно, он достаточно часто встречается на собеседовании. Перед интервью стоит убедиться, что вы понимаете механизм его работы.
59. Допустим, вам поручили задачу по разработке поискового робота — программы, которая, грубо говоря, посещает страницы в Интернете, индексирует, выделяет из них ссылки, переходит по ним и повторяет процесс. Вопрос: как избежать зацикливания?
Прежде всего, давайте зададим себе вопрос: при каких условиях в этой задаче может возникнуть бесконечный цикл? Такая ситуация вполне вероятна, например, если мы рассматриваем Всемирную паутину как граф ссылок.
Чтобы предотвратить зацикливание, нужно его обнаружить. Один из способов — создание хэш-таблицы, в которой после посещения страницы v устанавливается hash[v] = true.
Подобное решение применимо при поиске в ширину. Каждый раз при посещении страницы мы собираем все ее ссылки и добавляем их в конец очереди. Если мы уже посетили страницу, то просто ее игнорируем.
Здорово, но что означает посетить страницу v? Что определяет страницу v: ее содержимое или URL?
Если для идентификации страницы использовать URL, то нужно сознавать, что параметры URL-адреса могут указывать на другую страницу. Например, страница www.careercup.com/page?id=microsoft-interview-questions отличается от страницы www.careercup.com/page?id=google-interview-questions. С другой стороны, можно добавить параметры, а страница от этого не изменится. Например, страница www.careercup.com?foobar=hello — это та же страница, что и www.careercup.com.
Вы можете сказать: «Хорошо, давайте идентифицировать страницы на основании их содержимого». Это звучит правильно, но не очень хорошо работает. Предположим, что на домашней странице careercup.com представлен некий генерирующийся случайным образом контент. Каждый раз, когда вы посещаете страницу, контент будет другим. Такие страницы можно назвать разными? Нет.
На самом деле не существует идеального способа идентифицировать страницу, и задача превращается в головоломку.
Один из способов решения — ввести критерий оценки подобия страницы. Если страница похожа на другую страницу, то мы понижаем приоритет обхода ее дочерних элементов. Для каждой страницы можно создать своего рода подпись, основанную на фрагментах контента и URL-адресе.
Давайте посмотрим, как такой алгоритм может работать.
Допустим, что существует база данных, хранящая список элементов, которые необходимо проверить. При каждой итерации мы выбираем страницу с самым высоким приоритетом:
Такой алгоритм не позволит нам полностью обойти Всемирную паутину, но предотвратит зацикливание. Если нам понадобится возможность полного обхода страницы (подходит для небольших интранет-систем), можно просто понижать приоритет так, чтобы страница все равно проверялась.
Это упрощенное решение, но есть множество других, которые тоже можно использовать. Фактически, обсуждение этой задачи может трансформироваться в другую задачу.
60. У вас есть стеклянный кувшин, в котором лежат небольшие шарики, и вы в любое время можете определить их количество. Вы со своим другом играете в следующую игру: каждый из вас по очереди забирает из кувшина 1 или 2 шарика. Игрок, который забирает последний шарик, выигрывает. Какая самая лучшая стратегия в этой игре? Можете ли вы в самом начале предсказать, кто выиграет?
У вас есть стеклянный кувшин, в котором лежат небольшие шарики, и вы в любое время можете определить их количество. Вы со своим другом играете в следующую игру: каждый из вас по очереди забирает из кувшина 1 или 2 шарика. Игрок, который забирает последний шарик, выигрывает. Какая самая лучшая стратегия в этой игре? Можете ли вы в самом начале предсказать, кто выиграет?
Число шариков становится все меньше и меньше с каждым ходом, и, в конце концов, их станет как-то совсем мало. Вот тут-то стратегия становится совершенно понятной.
Давайте исходить из того, что в кувшине остался всего один шарик и теперь моя очередь брать. Взяв последний шарик, я выиграю.
Я выиграю и при двух оставшихся шариках, потому что могу взять оба.
Но три оставшихся шарика для меня плохой вариант. Мне придется оставить либо один, либо два шарика, и тут-то мой соперник немедленно воспользуется таким подарком.
Четыре и пять шариков — хороший вариант. Я могу оставить моего соперника с неудачным (уже для него) числом три.
Ну что ж, все понятно. Число, которое делится на три, означает для меня проигрыш: 3, 6, 9, 12… — плохие варианты, когда моя очередь ходить. Все другое (1, 2, 4, 5, 7, 8…) — прекрасно.
Так как теперь этим воспользоваться в игре? Мы начинаем с большого, но неизвестного числа шариков. Разделим его на 3. Если число делится без остатка, это неудачный для нас вариант. Тогда постарайтесь не ходить первым. Если соперник предложит вам бросить монетку, чтобы решить, кто должен ходить первым, проявите «великодушие» и позвольте ему сделать первый ход. Если же вам улыбнулась удача и число шариков не делится на три, и вы ходите первым, то стратегия выигрыша проста: с каждым ходом берите столько шариков, чтобы в кувшине оставалось проигрышное число. Скажем, если вы начнете с 304 шариков (прекрасно для вас), вы забираете один, оставляя сопернику неудачные для него 303. Поступайте так при каждом ходе, и, в конце концов, он останется с тремя шариками. Такая стратегия обеспечит вам победу.
Более того, такая стратегия совершенно надежно приведет вас к выигрышу, независимо от того, как будет действовать другой игрок (если только в порыве гнева он не размахнется кувшином об пол). Ему приходится забирать один или два шарика из оставшегося числа, неудачного для него. Это всегда позволяет вам при следующем ходе оставлять в кувшине «удачное» число шариков.
Но что делать, если вы начинаете с неудачного расклада? Вы обречены на поражение, если другой игрок сам применит описанную выше стратегию. Однако пока никакой трагедии нет. Ваш соперник может и не знать о такой стратегии, а может просто просчитаться. Любой, кто играет без стратегии, почти обязательно рано или поздно предоставит вам возможность перейти к счастливому (для вас) числу, поскольку две трети всех чисел для вас выигрышны. Человек, который знает оптимальную стратегию, но в ходе игры ошибется хотя бы раз, обречен: он больше не командует парадом (конечно, при условии, что вы такой ошибки не совершите).
Но, собственно, вас-то спрашивают, можно ли предсказать, кто выиграет. Да, если оба игрока идеально знают теорию этой игры. Определите, является ли первоначальное число шариков «счастливым». Если да, то первый игрок всегда выиграет. И наоборот.
Но живем мы с вами в реальном мире. Кто возьмется предсказать конечный результат?! Даже если оба игрока знают правильную стратегию, чем больше шариков в игре, тем выше вероятность ошибки. Шансы выше у того, кто не ошибется, следуя выигрышной стратегии.
Встречаются и варианты этого вопроса, например такой: проигрывает тот, кто забирает последний шарик. Как поступить в этом случае? «Неудачное» число шариков запишем в виде 3N+1, а затем будем применять ту же самую стратегию.
61. Имеется N компаний, и вы хотите, чтобы они слились и образовали одну крупную компанию. Сколько разных способов вы можете использовать для этого? Поглощение можно считать частным случаем слияния, когда А поглощает Б и Б полгощает А — два разных способа. Равнозначные слияния тоже возможны.
При правильном толковании термина «слияние» две компании отказываются от своей прежней индивидуальности и сливаются в новое образование, имеющее новый бренд. Так, фармацевтические гиганты Glaхо Wеllсоmе и SmithКlіnе Веесham в 2000 году слились, после чего на свет появился фармацевтический колосс GlaxoSmithKline. (К тому же, как вы правильно угадали, обе родительские компании сами были результатом многочисленных предыдущих слияний).
Если учесть эго главных исполнительных директоров, настоящие слияния встречаются нечасто. Для слияния требуется, чтобы силы переговорщиков были примерно одинаковы. Гораздо чаще встречаются ситуации, при которых руководство одной компании имеет преимущество и поэтому не позволяет лидерам более слабой компании об этом забыть. Поэтому сделка по своей сути больше напоминает поглощение, то есть вариант объединения, при котором компания А проглатывает компанию В, после чего В перестает существовать как отдельная организация (хотя часто сохраняется как бренд). Примером такого развития событий можно назвать поглощение Google в 2006 году YоuТubе.
В этом отношении слияния являются симметричными, так как имеется всего лишь один способ, когда две компании сливаются как равные. Поглощение же асимметрично: одна компания является поглощающей, а другая — поглощаемой. Вариант, при котором Google купил YоuТubе, не эквивалентен варианту, когда YоuТubе приобрела бы Google.
Большинство людей, не работающих в инвестиционных банках, не видят большой разницы между слияниями и поглощениями. Поэтому любое объединение корпораций они не очень строго называют «слиянием». Из этого следует, что вам необходимо спросить интервьюера, что он понимает в своем вопросе под «слиянием». К счастью, большинство обоснований, приведенных ниже, сохраняются независимо от того, каким будет пояснение интервьюера.
Начните с поглощений, поскольку они встречаются чаще (и к тому же эти случаи немного легче для разъяснений). Можно воспользоваться аналогией: представим компании игроками в шашки, а поглощения — ходами в продолжающейся игре. Начните с того, что число игроков составляет N. Ход в игре заключается в том, чтобы поставить одну шашку на другую, что означает, что верхняя шашка «поглотила» нижнюю. После поглощения вы можете пользоваться «высокими» шашками так, как «дамками» в обычной игре.
Каждый ход приводит к снижению числа шашек (как простых, так и «высоких») на одну. В итоге вы поставите все шашки в одну пирамиду и создадите максимально высокую комбинацию. Чтобы добиться цели в этой игре, вам потребуется N-1 шагов, в результате чего, в конце концов, появится пирамида, состоящая из N шашек. Сколько различных сценариев могут привести к такому исходу?
Самый простой случай — участие двух компаний, при котором компания А может поглотить компанию В или В может поглотить А. В этом случае имеется два возможных сценария.
Если компаний три, вам вначале надо решить, какая компания первой поглотит другую компанию и какую именно. Существует шесть вариантов такого первого поглощения, которые можно представить в виде шести возможных пар, состоящих из трех составляющих (АВ, АС, ВА, ВС, СА и СВ). После первоначального поглощения у вас остается две компании. Теперь ситуация точно такая же, как та, которая описана в предыдущем абзаце. Поэтому число возможных поглощений при трех компаниях составляет 6 x 2 = 12.
Если компаний четыре, вы получаете 12 возможностей для первого поглощения: АВ, АС, АD, ВА, ВС, ВD, СА, СВ, СD, DА, DВ и DС. Как вы уже поняли, если при трех компаниях на этом этапе возможно 12 вариантов, то при наличии четырех компаний имеется 12 x 6 x 2, то есть 144 варианта поглощений.
Давайте обобщим. При N компаниях число первоначальных поглощений составляет
N х (N-1).
Это означает лишь, что любая из N компаний может стать первой из поглощающей, а любая из оставшихся (N-1) компаний — первой поглощаемой. После первого поглощения остается N-1 отдельных компаний и имеется (N-1) х (N-2) возможностей для совершения второго поглощения. После этого остается (N-2) компаний и (N-2) х (N-3) возможных поглощений. Продолжим умножать все время уменьшающееся число возможных поглощений и будем делать это до тех пор, пока не придем к последнему поглощению, в котором остается 2 х 1 возможностей. Легко понять, что, используя обозначение при помощи факториала, произведение можно выразить как N! х (N-1)!, то есть именно таким будет число возможных сценариев поглощений.
Что произойдет, если мы рассмотрим не поглощения, а собственно слияния. При таком подходе можно взять результаты приведенного выше анализа для каждого из N-1 поглощений и разделить его на 2. Из этого следует, что число действительных вариантов слияний равняется N! х (N-1)!, деленное на 2^(N-1).
И наконец, если слияние может означать как слияние, так и поглощение, вы просто складываете друг с другом оба ответа.
62. Какой минимальный комплект монет необходим для того, чтобы выдать любую сдачу от 1 до 99 центов? Доступные номиналы монет: 1, 5, 10, 25, 50 центов и 1 доллар.
Есть два способа интерпретации этого вопроса. Они приводят к разным ответам, и поэтому вам лучше спросить интервьюера, что он имеет в виду (или подготовить оба варианта ответов). Одна интерпретация заключается в том, чтобы отыскать наименьший ассортимент монет, позволяющий дать точную сдачу от 1 до 99 центов. Назовем такой комплект универсальным набором для выдачи сдачи. Сколько монет будет в этом наборе?
Наша система сама подберет вам исполнителей на услуги, связанные с разработкой сайта или приложения, поисковой оптимизацией, контекстной рекламой, маркетингом, SMM и PR.
Заполнить заявку
13496 тендеров
проведено за восемь лет работы нашего сайта.
В задаче используются монеты США. Доллар США (USD, $), равный 100 центам. В обращении находятся монеты — penny (1 цент), nickel (5 центов), dime (10 центов), quarter (25 центов), half dollar (50 центов), а также 2 и 1 доллар.
Представим, что вы владелец лавки и педантичный по натуре человек, который любит начинать день, имея в своей кассе достаточно монет, чтобы можно было дать сдачу при первой покупке в день, независимо от суммы. Каково минимальное число монет должно быть в вашей кассе, чтобы в любом случае вы могли дать сдачу?
Ответ легкий, поскольку монеты в Америке специально подобраны по номиналу так, чтобы облегчить сдачи. Каждая монета по стоимости, по крайней мере, вдвое дороже предыдущей. Это означает, что вы можете использовать следующий алгоритм для выдачи сдачи, равной Х центов.
Если требуемая сдача Х равна 50 центам и более, положите 50-центовую монету и вычтите эту сумму из Х.
Если Х теперь равно 25 центам или более, положите четвертак (25 центов) и вычтите его из Х.
Разделите новое значение Х на 10 и выделите целую часть. Положите в кассу 10-центовики в количестве, равном целой части.
Если оставшаяся сумма равна 5 центам и более, положите в кассу 5-центовик и вычтите остаток из суммы.
Разделите оставшуюся сумму на центы и положите в кассу 1-центовые монеты в количестве последнего остатка.
Это правило не только работает, но и позволяет вам выдать любую сдачу при наличии минимально возможного числа монет. Вы можете, например, пропустить первую строку и использовать два четвертака вместо одной 50-центовой монеты, но это означает, что вам потребуется дополнительная монета.
Хотите дать любую сумму сдачи минимальным числом монет? Всегда имейте в своем распоряжении одну 50-центовую, один четвертак, один 5-центовик, причем каждую из этих монет достаточно иметь только в одном экземпляре. Вам также может потребоваться два 10-центовика (скажем, если надо выдать сдачу, равную 20 центам) и не более четырех 1-центовых монет (чтобы выдать 4 цента). Это означает, что у вас должны быть девять монет на общую сумму, равную 1,04 доллара. Это универсальный набор, позволяющий выдать любую сдачу. Очевидно, чтобы дать сдачу с доллара, вам никогда не потребуется использовать все девять монет сразу.
Альтернативная интерпретация вопроса такова: каково наименьшее число Х, при котором вам никогда не потребуется больше Х монет, чтобы выдать сдачу. Фактически здесь спрашивается, для выдачи, какой сдачи вам потребуется больше всего монет. Может быть, вы полагаете, что больше всего монет вам будет нужно для сдачи, равной 99 центам? Вы правы. Для этого вам потребуется восемь монет, а именно одна 50-центовая, четвертак, два 10-центовика и четыре 1-центовика. Восемь монет также потребуется и для сдачи, равной 94 центам (по сравнению с предыдущим набором вместо одного 10-центовика вы воспользуетесь 5-центовиком).
Этот вопрос считается довольно запутанным и используется в психологических тестах на креативность.
63. У вас есть 25 лошадей. Сколько забегов вам нужно устроить, чтобы определить трех самых быстрых из них? Вы не можете пользоваться секундомером. В каждом заезде могут участвовать только пять лошадей.
Вы можете начать свой ответ с уточнения: спросите интервьюера, следует ли считать «самой быстрой лошадью» ту, которая выигрывает конкретную скачку. Хотя этот вариант не работает на ипподроме, он в значительной степени упрощает задачу: предположим, что если А побеждает В в одной гонке, то А объективно и бесспорно более быстрая лошадь, чем В. Если вам скажут, что использовать это допущение можно, то в отдельной гонке действительно победит самая быстрая лошадь.
Первое, что приходит в голову, — нужны, по крайней мере, пять забегов. Любая из лошадей может быть в числе первых трех. К тому же вам потребуется устроить забеги для всех 25 лошадей. Пять забегов по пять лошадей в каждом — никак иначе.
Логично. Второй вывод: пяти забегов недостаточно. Разделите 25 лошадей на группы по пять, и устройте забеги. В каждом забеге одна лошадь будет конкурировать с другими четырьмя. Скажем, в одной из гонок будут участвовать лошади, которые придут к финишу в следующем порядке.
Ридонна
Бавкида
Харцея
Вероника
Альмадена
Хотя в этом забеге победила Ридонна, по его результатам вы не можете прийти к выводу, что она является самой быстрой лошадью из 25 или даже входит в тройку сильнейших. Чтобы пояснить последнее утверждение, воспользуемся крайним случаем: представим, что все самые медленные лошади в других заездах являются более быстрыми, чем Ридонна (которая, возможно, в общем рейтинге займет лишь 21-е место из 25 возможных).
Узнали ли мы что-нибудь из этого заезда? Разумеется, да. Мы узнали, как проранжировать пять конкретных лошадей. Мы также узнали, что можем вычеркнуть из числа претенденток на число лучших Веронику и Альмадену. Поскольку они не вошли в тройку первых в этом заезде, они не могут быть и в тройке самих быстрых из 25 лошадей.
То же самое можно сказать о лошадях, занявших четвертое и пятое места в других забегах. В каждом забеге из пяти лошадей две выбывают из дальнейшего рассмотрения. После первых пяти забегов мы можем вычеркнуть 10 лошадей, оставив 15 в качестве претендентов на звание самих быстрых трех.
Шестая гонка должна сравнить лошадей, которые хорошо показали себя в первых пяти заездах. Кажется разумным устроить гонки для победителей первых пяти заездов. Давайте так и сделаем. Возьмем Ридонну из заезда, описанного выше, и отправим ее на соревнования с победителями других заездов. Конечный результат может выглядеть следующим образом.
Фидана
Ридонна
Флавия
Принцесса Гита
Сикарель
Опять же мы можем обоснованно вычеркнуть из числа претендентов на победу Принцессу Гиту и Сикарель. Они, очевидно, если руководствоваться результатами этого забега, не могут входить в число трех быстрейших из 25. Мы также узнаем, что самой быстрой лошадью является Фидана, поскольку она опередила всех остальных лошадей, которые были первыми в предыдущих забегах. Если вопрос заключался бы в том, чтобы определить самую быструю лошадь из 25, то мы уже получили бы ответ. Ею является Фидана.
Однако нам надо определить трех самых быстрых. Из числа претенденток на победу мы можем вычеркнуть не только Принцессу Гиту и Сикарель, но и всех тех лошадей, которых они опередили в первых скачках. Лошади, которых они опередили, были более медленными, а мы уже знаем, что победители двух забегов из списка вычеркнуты.
Теперь давайте разберемся с Флавией. Поскольку она пришла третьей в этом забеге, все лошади, которых она опередила в первом забеге, также исключаются из дальнейшего рассмотрения.
Теперь перейдем к Ридонне. Исходя из последней гонки, она, возможно, в лучшем случае является второй лошадью из всех. Это оставляет открытым вопрос о Бавкиде. которая в первом круге пришла второй, после Ридонны, но в целом она может быть третьей из всех лошадей. (В этом случае список победителей был бы таким: Фидана, Ридонна, Бавкида).
Харцея, пришедшая третьей в первой гонке, где победителем была Ридонна, теперь выбывает из дальнейшего участия.
Две лошади, пришедшие второй и третьей после Фиданы в первой гонке, все еще остаются претендентами. Возможно, эти лошади быстрее Ридонны. но они никогда с ней не соревновались.
Итак, осталось шесть лошадей. Из них три были первыми в последней гонке: две, которые пришли второй и третьей в гонке с общим победителем, и одна, которая пришла второй в своей первой гонке, уступив только лошади, которая в общем зачете заняла второе место.
Мы уже знаем, что самая быстрая из всех лошадей — Фидана. По этой причине нет смысла опять устраивать с ней гонки. Остается всего пять лошадей. Естественно, мы устроим забег для них в седьмом и последнем раунде. Первые две лошади, оказавшиеся здесь победителями, в итоге займут второе и третье места.
Небольшое изменение правил. Начните с квалификационного раунда из пяти забегов, в которых будут соревноваться все 25 лошадей. Затем выберите вариант чемпионской гонки: в следующий круг будут допущены только победители квалификационных заездов. Лошадь, которая придет первой во второй гонке, и станет общим победителем.
64. Короткая задачка на сообразительность. По результатам исследования известно, что 70% людей любят кофе, в то же время 80% любят чай. Каковы верхние и нижние границы доли людей, которые одновременно любят кофе и чай?
Не все любители чая положительно относятся к кофе; не все любители котов терпят собак, и не все фанаты одной команды одновременно являются болельщиками другой. Нарисуйте диаграмму Венна на доске или хотя бы мысленно. Она представляет собой прямоугольник, чья площадь соответствует числу участников исследования. Пусть большая часть этого прямоугольника соответствует 70% — это число респондентов, любящих кофе, а небольшой кружок внутри отражает 30% тех людей, которые, очевидно, не любят кофе. (Общая площадь всего прямоугольника должна составлять 100%, хотя добиваться такой точности на картинке не обязательно.)

80% респондентов любят чай. Если эти проценты показать в виде круга, то он наложится на те части, которые отражают любителей кофе, и тех, кто негативно относится к этому напитку. (Группа любителей кофе просто недостаточна, чтобы вобрать в себя всех тех, кто любит чай.) Чтобы задать верхнюю границу людей, любящих оба напитка, предположим, что каждый любитель кофе любит и чай.
Поэтому круг, отражающий 80% любителей чая, можно разделить на две части: тех, кто любит и чай, и кофе (70%) и тех, кто любит только чай (10%). 70% являются верхней границей.
Чтобы получить нижнюю границу, сместим круг, относящийся к любителям чая, так, чтобы он закрыл круг тех, кто не любит кофе. Теперь каждый, кому не нравится кофе (30%), любит чай. Это приводит к 80 – 30 = 50% тех, кто любит чай и кофе. Эта цифра является нижней границей.

65. Задачка, которую нужно решать без калькулятора и компьютера, имея под рукой только карандаш и бумагу. Сколько нулей в конце факториала 100?
Факториал одной сотни записывается как 100! Это произведение всех натуральных чисел до ста включительно. Иногда запись факториала имеет такой вид:
100 х 99 х 98 х 97 х … х 4 х 3 х 2 х 1
Для ответа на вопрос задачи вам не обязательно находить результат умножения. От вас ждут, чтобы вы лишь определили число нулей в конце произведения, не зная, каким именно оно будет. Для решения этой задачи потребуется сформулировать несколько правил. Одно из них вы уже знаете. Взгляните на следующее выражение.
387 000 х 12 900 = 5 027 131 727
Вам не кажется, что здесь есть что-то забавное? Ведь при перемножении двух круглых чисел, то есть тех, которые оканчиваются на нули, невозможно получить некруглое число. Это нарушило бы закон сохранения конечных нулей (закон, который я только что вывел, но, тем не менее, он является верным). Произведение всегда унаследует нулевые окончания своих составляющих. Вот несколько верных примеров этого:
10 х 10 = 100 7 х 20 = 140 30 х 400 = 12 000
Из сомножителей факториала 100 десять заканчиваются на ноль: 10, 20, 30, 40, 50, 60, 70, 80, 90 и 100 (заканчивается на два 0). Это дает уже как минимум одиннадцать конечных нулей, которые 100! обязательно унаследует.
Предупреждение: следование только этому правилу иногда побуждает некоторых кандидатов в своем ответе заявить, что в конце факториала 100 стоят одиннадцать нулей. Такой ответ является неверным. Иногда можно умножить два числа, не заканчивающихся на ноль, и получить произведение, имеющее в конце один или несколько нулей. Вот несколько примеров этого рода:
2 х 5 = 10 5 х 8 = 40 6 х 15 = 90 8 х 125 = 1000
Все, кроме последней пары, входят в сотню составляющих факториала 100. Поэтому ваша работа не закончилась. Теперь мы подходим к закону «сосисок и булочек». Представьте себе ситуацию, когда на пикник одни люди приносят сосиски (в упаковках по десять штук), другие — булочки (упакованные по восемь штук), а некоторые — и то, и другое. Есть единственный способ, позволяющий определить, сколько хотдогов из этих продуктов можно приготовить. Сосчитайте сосиски, сосчитайте булочки и выберите меньшее число из двух.
Тот же самый закон следует использовать и отвечая на наш вопрос. Для этого надо заменить «сосиски» и «булочки» на «сомножители на 2» и «сомножители на 5».
В каждом из приведенных выше уравнений число, которое делится на 2, умножается на число, которое делится на 5. Сомножители на 2 и на 5 при их перемножении «совместно» дают идеальную десятку, что добавляет еще один ноль к общему произведению. Посмотрите на последний пример, где в конце, можно сказать, из воздуха возникает три нуля.
8 х 125 = (2 х 2 х 2) х (5 х 5 х 5) = (2 х 5) х (2 х 5) х (2 х 5) = 10 х 10 х 10 = 1000
Поэтому надо составить пары из двоек и пятерок. Возьмем, к примеру, число, равное 692 978 456 718 000 000.
Оно оканчивается на шесть нулей. Это означает, что его можно записать следующим образом:
692 978 456 718 х 10 х 10 х 10 х 10 х 10 х 10,
или так:
692 978 456 718 х (2 х 5) х (2 х 5) х (2 х 5) х (2 х 5) х (2 х 5) х (2 х 5).
Первая часть, 692 978 456 718, не делится на 10. В ином случае она бы оканчивалась на ноль, и можно было бы эту часть уменьшить еще в 10 раз. К тому же здесь есть шесть сомножителей, равных 10 (или 2 х 5), что соответствует шести нулям в конце числа 692 978 456 718 000 000. Ну как, убедительно?
Это дает нам надежную систему для определения количества нулей в конце любого большого числа. Выделите сомножители 2 и 5. Составьте из них пары и перемножьте их: (2 х 5) х (2 х 5) х (2 х 5) х … Число пар из двоек и пятерок равно количеству нулей в конце. Закройте глаза на все, что осталось слева.
В целом слева у вас останется двойка или пятерка, для которых не нашлось пары. Обычно это двойки. Более того, когда вы имеете дело с факториалом, это всегда двойки. (В факториалах имеется больше четных множителей, чем множителей, которые делятся на 5.) Поэтому узким местом является число пятерок. Из этого следует, что вопрос можно сформулировать по-другому: сколько раз 100! можно разделить без остатка на 5?
Эту арифметическую операцию можно легко проделать даже в голове. В диапазоне от 1 до 100 есть 20 чисел, которые делятся на пятерку: 5, 10, 15, …, 95, 100. Обратите внимание, что 25 дает 2 множителя, равные 5 (25 = 5 х 5), и к тому же в этой группе есть еще три числа, в состав которых входит 25: 50, 75 и 100. В совокупности это добавляет еще четыре пятерки, а всего их 24. 24 множителя на пять дают 24 пары с равным числом двоек, в результате чего получается 24 множителя на 10 (оставляя слева еще множество двоек, для которых не оказалось пары). Таким образом, в конце 100! будет 24 нуля.
Если вам любопытно узнать точный ответ, то значение факториала 100 равно:
93 326 215 443 944 152 681 699 238 856 266 700 490 715 968 264 381 621 468 592 963 895 217 599 993 229 915 608 941 463 976 156 518 286 253 697 920 827 223 758 251 185 210 916 864 000 000 000 000 000 000 000 000.
66. Предложите алгоритм нахождения самой большой суммы непрерывной последовательности из массива целых чисел, как положительных, так и отрицательных.
Это довольно сложная, но очень популярная задача. Давайте решим ее на примере массива:
2 3 -8 -1 2 4 -2 3
Если рассматривать массив как содержащий чередующиеся последовательности положительных и отрицательных чисел, то не имеет смысла рассматривать части положительных или отрицательных субпоследовательностей. Почему? Включая часть отрицательной субпоследовательности, мы уменьшаем итоговое значение суммы, значит, нам не стоит включать часть отрицательной субпоследовательности вообще. Включение части положительной субпоследовательности выглядит еще более странным, поскольку включение этой субпоследовательности целиком всегда даст больший результат.
Нужно придумать алгоритм, рассматривая массив как последовательность отрицательных и положительных чисел, расположенных вперемежку.
Любое число можно представить в виде суммы субпоследовательностей положительных и отрицательных чисел. В нашем примере массив можно сократить до:
5 -9 6 -2 3
Мы еще не получили отличный алгоритм, но теперь лучше понимаем, с чем имеем дело.
Рассмотрим предыдущий массив. Нужно ли учитывать субпоследовательность {5, -9}? В сумме мы получим -4, значит, нет смысла учитывать оба этих числа, достаточно только {5}.
В каких случаях имеет смысл учитывать отрицательные числа? Только если это позволяет нам объединить две положительные субпоследовательности, сумма каждой из которых больше, чем вклад отрицательной величины.
Давайте продвигаться, начиная с первого элемента в массиве.
5 — это самая большая сумма, встретившаяся нам. Таким образом, maxsum = 5 и sum = 5. Затем мы видим следующее число (-9). Если добавить это число к sum, то получится отрицательная величина. Нет смысла расширять субпоследовательность с 5 до -9 (-9 уменьшает общую сумму до 4). Таким образом, мы просто сбрасываем значение sum.
Теперь мы дошли до следующего элемента (6). Эта субпоследовательность больше, чем 5, таким образом, мы обновляем значения maxsum и sum.
Затем мы смотрим на следующий элемент (-2). Добавление этого числа к 6 сделает sum = 4. Так как это не окончательное значение, наша субпослсдовательность выглядит как {6, -2}. Мы обновляем sum, но не maxsum.
Наконец мы смотрим па следующий элемент (3). Добавление 3 к sum (4) даст нам 7, таким образом, мы обновляем maxsum. Максимальная последовательность имеет вид {6, -2, 3}.
Когда мы работаем с развернутым массивом, логика остается такой же. Следующий код реализует этот алгоритм:
public static int getMaxSum(int[] a) {
int maxsum = 0;
int sum = 0;
for (int i = 0; i < a.lenght; i++) {
sum += a[i];
if (maxsum < sum) {
maxsum = sum;
} else if (sum < 0) {
sum = 0;
}
}
return maxsum;
}
А если массив состоит из отрицательных чисел? Как действовать в этом случае? Рассмотрим простой массив {-3, -10, -5}. Можно дать три разных ответа:
-3 (если считать, что субпоследовательность не может быть пустой);
0 (субпоследовательность может иметь нулевую длину);
MINIMUM_INT (для случая ошибки).
В нашем коде был использован второй ответ (sum = 0), но в этом вопросе не существует однозначного «правильного» решения. Обсудите это с интервьюером.
67. Напишите программу расчета значения медианы в потоке чисел, динамически отслеживающую новые поступающие числа, получаемые рандомом.
Одно из возможных решений — использовать две кучи разных приоритетов: максимальная куча (maxHeap) для значений выше среднего и минимальная куча (minHeap) для значений ниже среднего. Это позволит разделить элементы примерно поровну с двумя значениями — вершинами куч. Теперь найти среднее значение очень просто.
Что означает «примерно поровну»? «Примерно» означает, что при нечетном количестве чисел в одной из куч окажется лишнее число. Можно сформулировать:
если maxHeap.size() > min.Heap.size(), то heap1.top() будет средним значением; если maxHeap.size() == minHeap.size(), то средним значением будет среднее значений maxHeap.top() и min.Heap.top().
В алгоритме с балансировкой мы гарантируем, что maxHeap будет всегда содержать дополнительный элемент.
Алгоритм работает следующим образом. Если новое значение меньше или равно среднему, оно помещается в maxHeap, в противном случае оно попадает в minHeap. Размеры куч могут совпадать или в maxHeap может быть один дополнительный элемент. Это требование легко выполнить, сдвигая элемент из одной кучи в другую. Среднее значение находится в вершине. Обновления занимают O(log(n)) времени.
private Comparator<Integer> maxHeapComparator;
private Comparator<Integer> minHeapComparator;
private PriorityQueue<Integer> maxHeap, minHeap;
public void addNewNumber(int randomNumber) {
/*Заметьте: addNewNumber поддерживает условие, что
*maxHeap.size() >= minHeap.size() */
if (maxHeap.size() >= minHeap.size()) {
if ((minHeap.peek() != null) &&
randomNumber > minHeap.peek()) {
maxHeap.offer(minHeap.poll());
minHeap.offer(randomNumber);
} else {
maxHeap.offer(randomNumber);
}
} else {
if(randomNumber < maxHeap.peek()) {
minHeap.offer(maxHeap.poll());
maxHeap.offer(randomNumber)
}
else {
minHeap.offer(randomNumber);
}
}
}
public static double getMedian() {
/*maxHeap является всегда по крайней мере столь же большой,
*как minHeap. Если maxHeap пуста, то minHeap тоже пуста. */
if (maxHeap.isEmpty()) {
return 0;
}
if(maxHeap.size() == minHeap.size()) {
return ((double)minHeap.peek()+(double)maxHeap.peek()) / 2;
} else {
/* Если maxHeap и minHeap разных размеров, то
* в maxHeap есть один дополнительный элемент.
* Возвращаем вергину кучи maxHeap */
return maxHeap.peek();
}
}
68. Идет дождь, а вам надо добраться до вашей машины, которая стоит в самом дальнем конце парковки. Побежите ли вы к ней или нет, если ваша цель — как можно меньше промокнуть? Как вы будете себя вести, если у вас есть зонтик?
Идет дождь, а вам надо добраться до вашей машины, которая стоит в самом дальнем конце парковки. Побежите ли вы к ней или нет, если ваша цель — как можно меньше промокнуть? Как вы будете себя вести, если у вас есть зонтик?
Чтобы ответить на этот вопрос, нужно примирить два противоречащих факта, влияющих на ход ваших размышлений. Вот аргументы в пользу бега: чем дольше вы находитесь под дождем, тем больше капель упадет на вашу голову, и тем больше вы промокнете. Если же вы побежите, вы сократите время воздействия на вас дождя и тем самым останетесь более сухим.
Но есть и довод против бега. При горизонтальном перемещении вы попадаете и под те капли дождя, которые на вас не упали бы, если бы вы остались на месте. Человек, который бежит под дождем, промокает больше, чем тот, кто стоит под тем же самым дождем.
Это весомый довод, но в данном случае он просто неприменим. Вам нужно добраться до вашего автомобиля, и ничего с этим нельзя поделать. Представьте, что вы мчитесь через парковку с бесконечно высокой скоростью. Ваши чувства также бесконечно обострились, и поэтому вы не натыкаетесь на другие машины. Время для вас как бы остановилось. Это напоминает эффект замедленной съемки. Капли дождя как бы не двигаются, а «висят» в воздухе. Во время этого стремительного бега ни одна капля не упадет на вашу голову, спину или бока. Но, чтобы добраться до автомобиля, вам необходимо «пробить» своего рода туннель в дожде. Поэтому часть вашей одежды спереди впитает в себя каждую каплю, находящуюся на пути от укрытия до машины.
Когда вы перемещаетесь с нормальной скоростью, вы обречены встретиться с теми же самыми каплями или, точнее, с их последователями. При нормальной скорости свою долю капель получит и ваша голова. Число дождевых капель, с которыми вы встретитесь, зависит от длины вашего горизонтального пути, а также от того времени, которое вам потребуется для его преодоления. Длина пути в этой задаче — заданное условие. Единственная вещь, которую вы можете контролировать, — это время перемещения. Чтобы остаться максимально сухим, вам следует бежать как можно быстрее. Бег приведет к тому, что вы промокнете меньше, конечно, при условии, что у вас нет с собой зонтика.
Если бы у вас был зонтик, и он был бы размером с городской квартал, и если вы смогли бы его удерживать, то было бы совсем не важно, ползете ли вы как черепаха или мчитесь как спринтер. В любом случае с таким зонтиком вы останетесь сухим, как ломтик хлеба в тостере.
Большинство зонтиков достаточно большие, чтобы человек, если он стоит под обычным вертикально идущим дождем, не промок. Но, как вы знаете, на практике вы все равно чуть-чуть промокнете.
Зонтики создают препятствия для дождя и образуют зону, где нет дождевых капель. При вертикальном падении капель и при зонтике в виде круга защитная зона от дождя похожа на цилиндр. Если дождь падает под углом, зона защиты от дождя становится скошенным цилиндром. Поэтому, как знает каждый опытный «пользователь», лучше всего наклонить зонтик в направлении падения дождя. Это приведет к тому, что зона защиты снова станет правильным цилиндром, хотя и наклоненным на некоторый угол относительно вертикали.
Стоящее человеческое тело не вписывается в наклоненный цилиндр. Если же дождь сопровождается ураганным ветром, который направляет капли на вас горизонтально, вам придется держать зонтик горизонтально, и зонт диаметром в три фута (около 90 см) будет защищать лишь половину вашего тела. Вторая половина промокнет.
От ветра, как и движения, вы намокнете больше. Профи знает, что зонт нужно наклонить вперед в направлении движения, чтобы обеспечить максимальную защиту. Фактически, даже если зонтик занимает оптимальное положение, ветер и движение человека все равно все сведут на нет. Бег со скоростью десять миль в час без ветра при вертикальном дожде потребует того же самого наклона, как и стояние под дождем при ветре в десять миль в час. В любом случае, помимо своей обычной скорости падения, дождевые капли будут воздействовать на вас и горизонтально, со скоростью 10 миль в час.
При вертикальном дожде лучший для вас вариант — идти медленно. Зонтик не придется сильно наклонять, и вы окажетесь в «укромном уголке». В идеале вам следует идти с такой скоростью, чтобы ваши ноги не оказывались вне этой зоны. Тогда вы останетесь сухим.
Разумеется, в реальной жизни все гораздо сложнее. Тут вам и порывы ветра, брызги от ударов капель о мостовую, и капли, стекающие с самого зонтика. Дождь, упавший на зонтик, никуда не испаряется. Капли стекают и падают вниз — по той же самой поверхности цилиндра, что создает ваш зонтик. И уж тут-то, по краям зонта, дождя больше, чем где-либо еще. Это означает, что любая часть вашего тела, которая высунется за этот край защиты, промокнет быстрее, чем если бы вы шли без зонта.
При резких порывах ветра преимущества медленного движения сходят на нет. Вам придется наклонить зонтик так, что нижняя половина вашего тела останется не под зонтом. Так что независимо ни от чего, наполовину вы точно промокнете.
Однако забудьте все эти мудреные рассуждения и вспомните совет своей мамы: идите, если у вас есть зонтик, и бегите, если у вас его нет.
Так же можно посмотреть расследование «Разрушителей легенд» начиная с 15 минуты.
69. Представьте, что существует квадратная матрица, каждый пиксель которой может быть черным или белым. Разработайте алгоритм поиска максимального субквадрата, у которого все стороны черные.
Разбор двух вариантов решения за O(N^4) и O(N^3). Можете ли вы найти другие варианты?
Эту задачу также можно решить двумя способами: простым и сложным. Давайте рассмотрим оба решения.
Мы знаем, что длина стороны самого большого квадрата равна N и существует только один квадрат размером N*N. Можно проверить, является ли квадрат искомым, и сообщить, если это так.
Если квадрат размером N*N не найден, можно попытаться найти следующий квадрат: (N-1)*(N-1). Проверяя все квадраты этого размера, мы возвращаем первый найденный квадрат. Затем аналогичные операции повторяются для N-2, N-3 и т. д. Так как каждый раз мы уменьшаем размер квадрата, то первый найденный квадрат будет самым большим.
Наш код работает так:
Subsquare findSquare(int[][] matrix) {
for (int i = matrix.length; i >= 1; i--) {
Subsquare square = findSquareWithSize(matrix, i);
if (square != null) return square;
}
return null;
}
Subsquare findSquareWithSize(int[][] matrix, int squareSize) {
/* На стороне размером N есть (N - sz + 1) квадратов
* длины sz. */
int count = matrix.length - squareSize + 1;
/* Перебор всех квадратов со стороной squareSize. */
for (int row = 0; row < count; row++) {
for (int col = 0; col < count; col++) {
if (isSquare(matrix, row, col, squareSize)) {
return new Subsquare(row, col, squareSize);
}
}
}
return null;
}
boolean isSquare(int[][] matrix, int row, int col, int size) {
// Проверяем верхнюю и нижнюю стороны
for (int j = 0; j < size; j++){
if (matrix[row][col+j] == 1) {
return false;
}
if (matrix[row+size-l][col+j] == 1){
return false;
}
}
// Проверяем левую и правую стороны
for (int 1=1; i < size - 1; i++){
if (matrix[row+i][col] == 1){
return false;
}
if (matrix[row+i][col+size-1] == 1){
return false;
}
}
return true;
}
Неторопливость «простого» решения связана с тем, что мы должны произвести O(N) операций при каждой проверке квадрата–кандидата. Проведя предварительную обработку, можно сократить время isSquare до O(1), тогда алгоритм потребует O(N3) времени.
isSquare пытается узнать, не являются ли нулевыми squareSize, находящиеся правее (и ниже) определенных ячеек. А эту информацию можно узнать заранее.
Мы выполним проверку справа налево и снизу вверх. Для каждой ячейки нужно рассчитать:
если А[r][с] является белым, А[r][с].zerosRight = 0 и A[r][с].zerosBelow = 0
иначе A[r][c].zerosRight = А[r][с + 1].zerosRight + 1
А[r][с].zerosBelow = А[r + 1][с].zerosBelow + 1
Посмотрите на значения для некоторой матрицы.
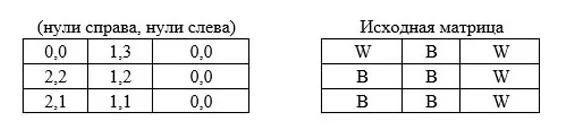
Теперь, вместо того чтобы итерировать по O(N) элементов, метод isSquare проверяет углы на zerosRight и zerosBelow.
Далее приведен код этого алгоритма. Обратите внимание, что findSquare и findSquare — WithSize совпадают, за исключением вызова processMatrix и последующей работы с новым типом данных:
public class SquareCell {
public int zerosRight = 0;
public int zerosBelow = 0;
/* объявления, функции установки и получения значений */
}
Subsquare findSquare(int[][] matrix) {
SquareCell[][] processed = processSquare(matrix);
for (int i = matrix.length; i >= 1; i--) {
Subsquare square = findSquareWithSize(processed, i);
if (square != null) return square;
}
return null;
}
Subsquare findSquareWithSize(SquareCell[][] processed,
int squareSize) {
/* эквивалентна первому алгоритму */
}
boolean isSquare(SquareCell[][] matrix, int row, int col,
int size) {
SquareCell topLeft = matrix[row][col];
SquareCell topRight = matrix[row][col + size - 1];
SquareCell bottomRight = matrix[row + size - l][col];
if (topLeft.zerosRight < size) { // Проверяем верхнюю сторону
return false;
}
if (topLeft.zerosBelow < size) { // Проверяем левую сторону
return false;
}
if (topRight.zerosBelow < size) { // Проверяем правую сторону
return false;
}
if (bottomRight.zerosRight < size) { // Проверяем нижнюю сторону
return false;
}
return true;
}
SquareCellf][] processSquare(int[][] matrix) {
SquareCell[][] processed =
new SquareCell[matrix.length][matrix.length];
for (int г = matrix.length - 1; г >= 0; r--) {
for (int c = matrix.length - 1; c >= 0; c--) {
int rightZeros = 0;
int belowZeros = 0;
// нужно обработать, только если ячейка черная
if (matrix[r][с] == 0) {
rightZeros++;
belowZeros++;
// следующая колонка в этом ряду
if (с + 1 < matrix.length) {
SquareCell previous = processed[r][с + 1];
rightZeros += previous.zerosRight;
}
if (r + 1 < matrix.length) {
SquareCell previous = processed[r + 1][c];
belowZeros += previous.zerosBelow;
}
}
processed[r][c] = new SquareCell(rightZeros, belowZeros);
}
}
return processed;
}
70. Предположим, в некоторый бар ходят только необщительные посетители. Вдоль барной стойки расположены 25 мест. Всякий раз, когда входит новый посетитель, он обязательно садится на самое дальнее, насколько это возможно, место от остальных гостей. Ни один не сядет рядом с кем-то другим: если посетитель входит и видит, что «свободных» мест нет, он тут же разворачивается и уходит из бара. Бармену, естественно, хочется, чтобы за стойкой сидело как можно больше клиентов. Если ему разрешено усадить первого посетителя на любое место, куда выгоднее его посадить с точки зрения бармена?
В этот бар ходят необщительные посетители. Вдоль барной стойки расположены 25 мест. Всякий раз, когда входит новый посетитель, он обязательно садится на самое дальнее, насколько это возможно, место от остальных гостей. Ни один не сядет рядом с кем-то другим: если посетитель входит и видит, что «свободных» мест нет, он тут же разворачивается и уходит из бара. Бармену, естественно, хочется, чтобы за стойкой сидело как можно больше клиентов. Если ему разрешено усадить первого посетителя на любое место, куда выгоднее его посадить с точки зрения бармена?
Самый плотный из возможных вариантов — чередование клиентов и пустых мест, при котором оба крайних места заняты. Это позволило бы остальным посетителям сесть на все места с нечетными номерами, в том числе и крайние под номерами 1 и 25, и оставить все четные номера пустыми. В этом случае у стойки могло бы разместиться 13 клиентов.
Однако такое размещение не всегда работает. Предположим, первый клиент уселся на место № 1. Следующий «отшельник» выбирает место под номером № 25, поскольку оно располагается на самом далеком из всех возможных расстояний от № 1 Третьему клиенту придется сесть в середину барной стойки, на место № 13. Два следующих посетителя заполнят пустоты и усядутся соответственно на места № 7 и № 19. Пока все хорошо.
В конце концов, кто–то захочет сесть между клиентами, занимающими места № 1 и № 7. Он выберет № 4, поскольку это позволит ему иметь два пустых сиденья между собой и ближайшими соседями. Но ни один из следующих гостей не сядет рядом с ним. Остальная часть барной стойки заполнится точно так же, и поэтому между двумя посетителями будут пустоты в два места, что делает эту схему минимально эффективной из возможных (при ней у стойки окажутся лишь девять клиентов вместо оптимального числа — 13).
Многие задачи, в том числе и эту, лучше всего решать, двигаясь от конца к началу. Мы знаем, каким должен быть желательный для нас план рассадки, и надо определить, как на него выйти.
Как показано на диаграмме, для этой схемы характерна большая симметрия, напоминающая рост кристалла. Небольшие части барной стойки заполняются как раз таким образом. Обратите внимание на ту часть стойки, в которой идут первые номера. Нужно, чтобы посетители заняли места № 1 и № 5, так как это позволит другому клиенту усесться на № 3.
Как вам добиться, чтобы пришедший в бар человек сел на место № 5? Ответ: надо, чтобы клиенты уже сидели на местах № 1 и № 9. Тогда пятое место будет посредине между ними, поскольку оно занимает максимальное расстояние и от № 1, и от № 9.
Как добиться, чтобы человек сел на № 9? Для этого предыдущие клиенты должны занять № 1 и № 17. А как сделать так, чтобы посетитель отправился на № 17? Скажем так, барная стойка недостаточно длинная, чтобы посадить клиентов на места № 1 и № 33. Поэтому бармену придется поступить просто — попросить первого посетителя сесть за № 17. Вот ответ.
Давайте отмотаем пленку назад. Первый клиент усаживается на № 17 (верхняя строка в диаграмме). Второй посетитель усаживается от него как можно дальше, на место № 1.
У третьего посетителя два варианта выбора: место № 9 пли № 25. Оба находятся на расстоянии семи пустых мест от любого другого клиента. Если исходить из замкнутого характера посетителей этого бара, третий клиент выберет скорее всего место № 25, поскольку в этом случае у него на расстоянии будет всего один сосед, а не двое, между которыми ему придется сидеть, и поэтому № 9 остается для четвертого клиента.
Следующие три посетителя выберут места между первыми четырьмя и займут соответственно места № 5, № 13 и № 21. На каждом из этих мест до ближайшего соседа их будет разделять три пустых сиденья.
И наконец, следующие шесть посетителей займут шесть оставшихся мест, у которых нет ближайших соседей, а именно: № 3, № 7, № 11, № 15, № 19 и № 23.
Бармен с таким же успехом мог бы попросить первого посетителя сесть на место № 9, и в этом случае диаграмма стала бы зеркальным отображением той, которая представлена выше.
71. Опишите, как можно использовать один одномерный массив для реализации трех стеков.
Подобно многим задачам, все зависит от того, как мы собираемся поддерживать эти стеки. Если нам нужно выделить определенное пространство для каждого стека, можно так и поступить. Но в этом случае один из стеков может исчерпать ресурсы, а другие будут практически пустыми.
Можно, конечно, использовать более гибкую систему разделения пространства, но это значительно усложняет задачу.
Можно разделить массив на три равные части и разрешить стекам развитие в пределах ограниченного пространства. Обратите внимание, что далее мы будем описывать границы диапазонов с помощью скобок: квадратные скобки [] означают, что граничные значения входят в диапазон, а круглые скобки — значения не входят.
Стек 1: [0, n/3).
Стек 2: [n/3, 2n/3).
Стек 3: [2n/3, n].
Код для этого решения приведен ниже:
int stackSize = 100;
int[] buffer = new int [stackSize * 3];
int[] stackPointer = {0,0,0}; //указатели для отслеживания верхних элементов
void push(int stackNum, int value) throws Exception {
/* Проверяем, есть ли пространство */
if (stackPointer[stackNum] >= stackSize){
throw new Exception("Недостаточно пространства.");
}
/* аходим индекс верхнего элемента массива + 1,
* и увеличиваем указатель стека */
int index = stackNum * stackSize + stakPointer[stackNum] + 1;
stackPointer[stackNum]++;
buffer[index] = valuse;
}
int pop(int stackNum) throws Exception {
if (stackPointer[stackNum] == 0) {
throw new Exception("Попытка использовать пустой стек");
}
int index = stackNum * stackSize + stackPointer[stackNum];
stackPointer[stackNum]--;
int value = buffer[index];
buffer[index] = 0;
return value;
}
int peek(int stackNum) {
int index = stackNum * stackSize + stackPointer[stackNum];
return buffer[index];
}
boolean isEmpty(int stackNum) {
return stackPointer[stackNum] ==0;
}
Если у нас есть дополнительная информация о назначении стеков, можно модифицировать алгоритм. Например, если предполагается, что в стеке 1 будет больше элементов, чем в стеке 2, можно перераспределить пространство в пользу стека 1.
Второй подход — гибкое выделение пространства для блоков стека. Когда один из стеков перестает помещаться в исходном пространстве, мы увеличиваем объем необходимого ресурса и при необходимости сдвигаем элементы.
Кроме того, можно создать массив таким образом, чтобы последний стек начинался в конце массива и заканчивался в начале, — «закольцевать» массив.
Впрочем, на собеседовании вас не заставят писать столь сложный код, поэтому мы ограничимся упрощенной версией (псевдокодом).
/* StackData - простой класс, который хранит набор данных о каждом стеке
* Коласс не содержит элементы стека! */
public class stackData{
public int start;
public int pointer;
public int size = 0;
public int capacity;
public stackData(int _start, int _capacity){
start = _start;
pointer = _start -1;
capacity = _capacity;
}
public boolean isWithinStack(int index, int total_size){
if(start + capacity <= total_size) { // нормальный размер
if(start <= index && index <= start + capacity) {
return true;
} else {
return false;
}
} else { // стек отсекается вокруг начала массива
int shifted_index = index + total_size;
if (start <= shifted_index &&
shifted_index <= start + capacity){
return true;
} else {
return false;
}
}
}
}
public class Question B {
static int number_of_stack = 3;
static int default_size = 4;
static int total_size = default_size * number_of_stack;
static StackData [] stacks = {new StackData(0, default_size),
new StackData(default_size, default_size),
new StackData(default_size * 2, default_size)};
static int [] buffer = new int [total_size];
public static void main(String [] args) throw Exception {
push(0,10);
push(1,20);
push(2,30);
int v = pop(0);
...
}
public static int nextElement(int index) {
if (index + 1 == total_size) return 0;
else return index + 1;
}
public static int previousElement(int index) {
if (index ==0) return total_size - 1;
else return index - 1;
}
public static void shift(int stackNum) {
StackData stack = stacks[stackNum];
if (stack.size >= stack.capacity) {
int nextStack = (stackNum + 1) % number_of_stacks;
shift(nextStack); // выполняем сдвиг
stack.capacity++;
}
//Сдвигаем элементы в обратном порядке
for (int i = (stack.start + stack.capacity -1) % total_size;
stack.isWithinStack(i, total_size);
i=previousElement(i)) {
buffer[i] = buffer[previousElement(i)];
}
buffer[stack.start] = 0;
stack.start = nextElement(stack.start); //перемещаем начало стека
stack.pointer = nextElement(stack.pointer); // перемещаем указатель
stack.capacity--; // устанавливаем оригинальный размер
}
/* Расширяем стек, сдвигаем остальные стеки */
public static void expand(int stackNum) {
shift((stackNum + 1) % number_of_stacks);
stacks[stackNum].capacity++;
}
public static void push(int stackNum, int value)
throws Exception {
StackData stack = stacks[stackNum];
/* Проверим, есть ли размер */
if (stack.size >= stack.capacity) {
if (numberOfElements() >= total_size) { // Totally full
throw new Exception("Ндостаточно пространства.");
} else { // Нужно выполнить сдвиг
expand(stackNum);
}
}
/* Находим индекс верхнего элемента в массиве +1,
* и увеличиваем указатель стека */
stack.size++;
stack.pointer = nextElement(stack.pointer);
buffer[stack.pointer] = value;
}
public static int pop(int stackNum) throws Exception{
StackData stack = stacks[stackNum];
if (stack.size == 0) {
throw new Exception("Попытка использовать пустой стек");
}
int value = buffer[stack.pointer];
buffer[stack.pointer] = 0;
stack.pointer = previousElement(stack.pointer);
stack.size--;
return value;
}
public static int peek(int stackNum) {
StackData stack = stacks[stackNum];
return buffer[stack.pointer];
}
public static boolean isEmpty(int stackNum) {
StackData stack = stacks[stackNum];
return stack.size == 0;
}
}
В подобных задачах важно сосредоточиться на написании чистого и удобного в сопровождении кода. Вы должны использовать дополнительные классы, как мы сделали со StackData, а блоки кода нужно выделить в отдельные методы. Этот совет пригодится не только для прохождения собеседования, его можно использовать и в реальных задачах.
72. У вас есть неограниченное количество монет достоинством 25, 10, 5 и 1 цент. Напишите код, определяющий количество способов представления n центов.
Это рекурсивная задача, поэтому давайте разберемся, как рассчитать makeChange(n), основываясь на предыдущих решениях (подзадачах). Пусть n = 100. Мы хотим вычислить количество способов представления 100 центов.
Нам известно, что для получения 100 центов мы можем использовать монеты 0, 1, 2, 3 или 4 четвертака (25 центов):
makeChange(100)= makeChange(100, используя 0 четвертаков) + makeChange(100, используя 1 четвертак) + makeChange(100, используя 2 четвертака) + makeChange(100, используя 3 четвертака) + makeChange(100, используя 4 четвертака)
Двигаемся дальше: попробуем упростить некоторые из этих задач. Например, makeChange(100, используя 1 четвертак) = makeChange(75, используя 0 четвертаков). Это так, потому что если мы должны использовать один четвертак для представления 100 центов, оставшиеся варианты соответствуют различным представлениям 75 центов.
Мы можем применить эту же логику для makeChange(100, используя 2 четвертака), makeChange(100, используя 3 четвертака) и makeChange(100, используя 4 четвертака).
Приведенное ранее выражение можно свести к следующему:
makeChange(100)= makeChange(100, используя 0 четвертаков) + makeChange(75, используя 0 четвертаков) + makeChange(50, используя 0 четвертаков) + makeChange(25, используя 0 четвертаков) + 1
Заметьте, что последнее выражение — makeChange(100, используя 4 четвертака) — равно 1.
Что делать дальше? Теперь мы израсходовали все четвертаки и можем использовать следующую самую крупную монету — 10 центов.
Подход, использованный для четвертаков, подойдет и для 10–центовых монет. Мы применим его для четырех частей приведенного выше выражения. Так, для первой части:
makeChange(100, используя 0 четвертаков) = makeChange(100, используя 0 четвертаков, 0 монет в 10 центов) + makeChange(100, используя 0 четвертаков, 1 монету в 10 центов) + makeChange(100, используя 0 четвертаков, 2 монеты в 10 центов) + … makeChange(100, используя 0 четвертаков, 10 монет в 10 центов) makeChange(75, используя 0 четвертаков) = makeChange(75, используя 0 четвертаков, 0 монет в 10 центов) + makeChange(75, используя 0 четвертаков, 1 монету в 10 центов) + makeChange(75, используя 0 четвертаков, 2 монеты в 10 центов) + … makeChange(75, используя 0 четвертаков, 7 монет в 10 центов) makeChange(50, используя 0 четвертаков) = makeChange(50, используя 0 четвертаков, 0 монет в 10 центов) + makeChange(50, используя 0 четвертаков, 1 монету в 10 центов) + makeChange(50, используя 0 четвертаков, 2 монеты в 10 центов) + … makeChange(50, используя 0 четвертаков, 5 монет в 10 центов) makeChange(25, используя 0 четвертаков) = makeChange(25, используя 0 четвертаков, 0 монет в 10 центов) + makeChange(25, используя 0 четвертаков, 1 монету в 10 центов) + makeChange(25, используя 0 четвертаков, 2 монеты в 10 центов)
После этого можно перейти к монеткам в 5 и 1 цент. В результате мы получим древовидную рекурсивную структуру, где каждый вызов расширяется до четырех или больше вызовов.
Базовый случай для нашей рекурсии — полностью сведенное (упрощенное) выражение. Например, makeChange(50, используя 0 четвертаков, 5 монет в 10 центов) полностью сводится к 1, так как 5 монет по 10 центов дает ровно 50 центов.
Рекурсивный алгоритм будет иметь примерно такой вид:
public int makeChange(int n, int denom) {
int next_denom = 0;
switch (denom) {
case 25:
next_denom =10;
break;
case 10:
next_denom =5;
break;
case 5:
next_denom =1;
break;
case 1:
return 1;
}
int ways = 0;
for (int I = 0; I * denom<= n; i++){
ways += makeChange (n – 1 * denom , next_denom);
}
return ways;
}
System.out.writeln(makeChange(100, 25));
Хотя мы реализовали код, опираясь на монеты, используемые в США, его можно легко адаптировать для любой другой валюты.
73. Напишите код, который позволяет найти минимальное расстояние (выражаемое количеством слов) между любыми двумя словами в файле. Порядок не важен.
Достаточно ли будет линейного времени?
Сколько памяти понадобится для решения?
Давайте считать, что порядок появления слов word1 и word2 не важен. Этот вопрос нужно согласовать с интервьюером. Если порядок слов имеет значение, нужно будет модифицировать приведенный далее код.
Чтобы решить эту задачу, достаточно будет прочитать файл только один раз. При этом мы сохраним информацию о том, где находились последние word1 или word2 в lastPosWord1 и lastPosWord2 и при необходимости обновляем значение min, а затем обновляем lastPosWord1. Аналогичным образом мы действуем и с word2. По окончании работы алгоритма в нашем распоряжении окажется правильное значение min (минимальное расстояние).
Приведенный далее код иллюстрирует этот алгоритм:
public int shortest(String[] words, String word1, String word2) {
int min = Integer.MAX_VALUE;
int lastPosWord1 = -1;
int lastPosWord2 = -1;
for (int i = 0; i < words.lenght; i++) {
String currentWord = words[i];
if (currentWord.equals(word1)) {
lastPosWord1 = i;
// Закомментируйте 3 следующие строки, если порядок слов
// имеет значение
int distance = lastPosWord1 - lastPosWord2;
if (lastPosWord2 >= 0 && min > distance) {
min = distance;
}
} else if (currentWord.equals(word2)) {
lastPosWord2 = i;
int distance = lastPosWord2 - lastPosWord1;
if (lastPosWord >= 0 && min > distance) {
min = distance;
}
}
}
return min;
}
Если нам придется выполнять ту же работу для других пар слов, можно создать хэш–таблицу, связывающую слова с позицией в файле. Тогда решением будет минимальная (арифметическая) разница между значением из списков listA и listB.
Существует несколько способов вычислить минимальную разницу между значениями из listA и listB. Давайте рассмотрим списки:
listA: {1, 2, 9, 15, 25}
listB: {4, 10, 19}
Можно объединить списки в один отсортированный список, но связать каждое значение с исходным списком. Эта операция выполняется «обертыванием» каждого значения в класс, у которого будет две переменные экземпляра: data (для хранения фактического значения) и listNumber.
list: {1a, 2a, 4b, 9a, 10b, 15a, 19b, 20a}
Расчет минимального расстояния превращается в поиск минимального расстояния между двумя последовательными числами, у которых разные теги списка. В этом случае решением будет 1 (расстояние между 9a и 10b).
74. Смоделируйте использование игральной кости с семью гранями, если в вашем распоряжении имеется только кость с пятью гранями.
Иными словами, как получить случайное число в диапазоне от 1 до 7, используя генератор случайных целых чисел от 1 до 5?
Как вы можете получить случайное число в диапазоне от 1 до 7, используя игральную кость с пятью гранями?
Иначе говоря, в вашем распоряжении устройство, которое генерирует случайное целое число от 1 до 5. Но вам необходимо воспользоваться им для генерирования случайных чисел в диапазоне от 1 до 7. Представьте, что семь человек с лотерейными билетами под номерами от 1 до 7 страстно ждут розыгрыш. Как вы используете кость с пятью сторонами, чтобы выбрать победителя, заведомо зная, что проигравшие будут недовольны и что вам, возможно, придется в суде доказывать, что процедура определения победителя была совершенно случайной.
Есть несколько простых идей, но, увы, они могут показаться несправедливыми. Одна из них — бросить кость дважды и сложить выпавшие числа. Это даст результат в диапазоне от 2 до 10. Кажется, все справедливо? Нет. Любой знает, что не все суммы двух бросков в равной степени вероятны. Сумма в середине распределения (7) более вероятна. То же самое верно и в отношении кости с пятью сторонами.
Другая идея — бросить кость дважды и умножить полученные значения или каким–то другим способом получить на их основе большее число. Затем разделить его на 7 и взять только остаток. Остаток будет в диапазоне от 0 до 6. 0 нам не нужен, и поэтому будем считать его за 7. Такой вариант обеспечит нам получение «случайного» числа в диапазоне от 1 до 7.
Я поставил слово «случайный» в кавычки, потому что математик Джон фон Нейман писал, что любой, кто рассматривает арифметические методы получения случайных чисел, попадает, конечно, в «страну греха». Хотя такой подход для некоторых целей может быть вполне приемлем, результат на самом деле не является в полной мере случайным, и поэтому в Google или Amazon такой ответ высоко не ценится. А вот в Интернете числа должны быть действительно случайными, так как в противном случае хакеры воспользовались бы этим преимуществом. В казино, например.
Для получения действительно случайного исхода пусть каждый из семи игроков бросает кость с пятью сторонами один раз. Игрок, показавший более крупное число, выигрывает. Если высшее значение показали несколько игроков, они бросают кость снова (столько раз, сколько необходимо). Единственный минус в таком подходе — возможно, придется много раз подбрасывать кость. Даже если равенства (ничьих) не будет, потребуется семь бросков.
Есть более совершенный ответ. Подумайте более внимательно о цифрах. Числа с 1 по 7 можно представить в виде трех битов, то есть бинарных чисел от 001 до 111. Можете ли вы сгенерировать три случайных бита, используя кость с пятью сторонами?
Разумеется, каждый бросок даст вам одну цифру трехбитного числа. Если выпадет 2 или 4, назовите результат ноликом, если 1 или 3 — единица, если 5 — бросайте снова. Продолжайте бросать столько, сколько необходимо, если выпадет пятерка.
Повторение этой процедуры три раза генерирует число в диапазоне от 000 до 111. Переведите снова в десятичное исчисление, и тогда человек, у которого выпало большее число, выигрывает (например, 101 означает, что выиграл лотерейный билет № 5). Если выпал 000, проведите броски снова.
Это потребует всего три броска кости, если не будет повторений. В среднем при таком подходе требуется чуть больше четырех бросков.
75. Напишите код, разбивающий связный список вокруг некоторого значения так, чтобы все меньшие узлы оказались перед узлами, большими или равными этому значению.
Если бы мы работали с массивом, то было бы много сложностей, связанных со смещением элементов.
Со связным списком задача намного проще. Вместо того чтобы смещать и менять местами элементы, мы можем создать два разных связных списка: один для элементов, меньших х, а второй — для элементов, которые больше или равны х.
Мы проходим по списку, расставляя элементы по спискам before и after. Как только конец исходного связного списка будет достигнут, можно выполнить слияние получившихся списков.
>Приведенный код реализует данный подход:
/* Передаем начало списка, который нужно разделить, и значение х, вокруг которого
* список будет разделен */
public LinkedListNode partition(LinkedListNode node, int x) {
LinkedListNode beforeStart = null;
LinkedListNode beforeEnd = null;
LinkedListNode afterStart = null;
LinkedListNode afterEnd = null;
/* Разбиваем список */
while (node != null) {
LinkedListNode next = node.next;
node.next = null;
if (node.data < x) {
/* Вставляем узел в конец списка before*/
if (beforeStart == null) {
beforeStart = node;
beforeEnd = beforeStart;
} else {
beforeEnd.next = node;
beforeEnd = node;
}
} else {
/* Вставляем узел в конец списка after */
if (afterStart == null) {
afterStart = node;
afterEnd = afterStart;
} else {
afterEnd.next = node;
afterEnd = node;
}
}
node = next;
}
if (beforeStart == null) {
return afterStart;
}
/* Слияние списков before и after */
beforeEnd.next = afterStart;
return return beforeStart;
}
Если вы не хотите использовать четыре переменные, чтобы отслеживать всего два связных списка, можно избавиться от части из них за счет небольшой потери эффективности. Но «ущерб» будет не очень велик, оценка алгоритма по времени останется такой же, зато код станет более коротким и красивым.
Альтернативное решение: вместо вставки узлов в конец списков before и after можно вставлять элементы в начало списка.
public LinkedListNode partition(LinkedListNode node, int x) {
LinkedListNode beforeStart = null;
LinkedListNode afterStart = null;
/ Разбиваем список */
while (node != null) {
LinkedListNode next = node.next;
if (node.data < x) {
/* Вставляем узел в начало списка before */
node.next = beforeStart;
beforeStart = node;
} else {
/* Вставляем узел в начало списка after */
node.next = afterStart;
afterStart = node;
}
node = next;
}
/* Выполняем слияние списков */
if (beforeStart == null) {
return afterStart;
}
/* Находим конец списка before и соединяем списки*/
LinkedListNode head = beforeStart;
while (beforeStart.next != null) {
beforeStart = beforeStart.next;
}
beforeStart.next = afterStart; return head;
return head;
}
Обратите внимание на нулевые значения. В строке 7 добавлена дополнительная проверка. Необходимо сохранить следующий узел во временной переменной так, чтобы запомнить, какой узел будет следующим.
76. Напишите метод, генерирующий случайную последовательность m целых чисел из массива размером n. Все элементы выбираются с одинаковой вероятностью.
Первое, что приходит в голову, — выбрать случайные элементы из массива и поместить их в новый массив. Но что если мы выберем один и тот же элемент дважды?
Первое, что приходит в голову, — выбрать случайные элементы из массива и поместить их в новый массив. Но что если мы выберем один и тот же элемент дважды? В идеале, нам нужно сократить массив так, чтобы выкинуть выбранный элемент. Но уменьшение массива достаточно трудоемкая операция, поскольку требует смещения элементов.
Вместо того чтобы сокращать (сдвигать) массив, можно поставить элемент (поменять элементы местами) в начало массива и «запомнить», что теперь массив начинается с элемента j. Если элемент subset[0] становится элементом array[k], то мы должны заменить элемент array[k] первым элементом в массиве. Когда мы переходим к элементу subset[1], то подразумеваем, что элемент array[0] «мертв», и выбираем случайный элемент из интервала от 1 до array.size(). Теперь subset[1] = array[y] и array[y] = subset[1]. Элементы 0 и 1 «мертвы», а subset[2] выбирается в диапазоне от array[2] до array[array.size()] и т.д.
/* Случайное число между lower и higher включительно */
public static int rand(int lower, int higher) {
return lower + (int)(Math.random() * (higher - lower + 1));
}
/* Выбрать M элементов из исходного массива. Клонируемый исходный
* массив так, чтобы не уничтожить ввод */
public static int[] pickMRandomly(int[] original, int m) {
int[] subset = new int[m];
int[] array = original.clone();
for(int j = 0; j < m; j++) {
int index = rand(j, array.length - 1);
subset[j] = array[index];
array[index] = array[j]; //array[j] теперь "мертв"
}
return subset;
}
77. Представьте себе робота, находящегося в левом верхнем углу сетки с координатами (X, Y). Робот может перемещаться в двух направлениях: вправо и вниз. Сколько существует маршрутов, проходящих от точки (0, 0) до точки (X, Y)?
Дополнительно предположите, что на сетке существуют области, которые робот не может пересекать. Разработайте алгоритм построения маршрута от левого верхнего до правого нижнего угла.
Нам нужно подсчитать количество вариантов прохождения дистанции с Х шагов вправо и Y шагов вниз (X + Y шагов).
Чтобы создать путь, мы делаем Х шагов вправо так, чтобы общее количество перемещений оставалось фиксированным (X + Y). Таким образом, количество путей должно совпадать с количеством способов выбрать Х элементов из X + Y, то есть биномиальным коэффициентом. Биномиальный коэффициент из n по r имеет вид:
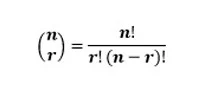
Для нашей задачи выражение будет следующим:
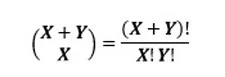
Даже если вы незнакомы с комбинаторикой, то все равно можете найти решение этой задачи самостоятельно.
Представим путь как строку длиной X + Y, состоящую из X символов R и Y символов D. Мы знаем, что из X + Y неповторяющихся символов мы можем составить (X + Y)! строк. Но в нашем случае используется X символов R и Y символов D. Символы R могут быть расставлены X! способами (то же самое мы можем сделать и с символами D). Таким образом, необходимо убрать лишние строки X! и Y!. В итоге мы получим то же самое выражение:
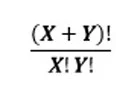
Найдите маршрут (на карте есть места, через которые не может пройти робот).
Если мы изобразим нашу карту, то единственный способ попасть в квадрат (X, Y) — оказаться в одном из смежных квадратов: (X-1, Y) или (X, Y-1). Следовательно, необходимо найти путь к любому из этих квадратов ((X-1, Y) или (X, Y-1)).
Как это осуществить? Чтобы найти путь в квадрат (X-1, Y) или (X, Y-1), мы должны оказаться в одной из смежных ячеек. То есть нам необходимо найти путь к квадрату, смежному с (X-1, Y) ((X-2, Y) и (X-1, Y-1)) или (X, Y-1) ((X-1, Y-1) и (X, Y-2)). Обратите внимание: в наших рассуждениях точка (X-1, Y-1) упоминается дважды, мы еще вернемся к этому факту.
Давайте попробуем найти путь от исходного квадрата, двигаясь в обратном направлении, — начинаем с последней ячейки и пытаемся найти путь к каждому смежному квадрату. Далее приведен рекурсивный код, реализующий наш алгоритм.
public boolean getPath(int x, int y, ArrayList<Point> path) {
Point p = new Point(x, y);
path.add(p);
if (x == 0 && y == 0) {
return true; // найти путь
}
bolean success = false;
if (x >= 1 && isFree(x – 1, y)) { // Пытаемся идти вправо
success = getpath(x – 1, y, path); // Свободно! Можно идти вправо
}
if ( !success && y >= 1 && isFree(x, y - 1)) { // Пытаемся идти вниз
success = getPath(x, y – 1, path); // Свободно! Можно идти вниз
}
if (!success) {
path.remove(p); // Неверный путь! Прекратить движение этим маршрутом
}
return success;
}
Помните, что маршруты дублируются? Чтобы найти все пути к (X, Y), мы находим все пути к (X-1, Y) и (X, Y-1). Затем мы смотрим на координаты смежных квадратов: (X-2, Y), (X-1, Y-1), (X-1, Y-1) и (X, Y-2). Квадрат (X-1, Y-1) появляется дважды. Давайте будем запоминать посещенные квадраты, чтобы не тратить на них время.
Это можно сделать с помощью следующего алгоритма динамического программирования:
public Boolean getPath(int x, int y, ArrayList<Point> path,
Hashtable<Point, Boolean> cache){
Point p = new Point(x, y);
if (cache.containsKey(p)) { // Мы уже посещали эту ячейку
return cache.get(p);
}
path.add(p);
if (x == 0 && y == 0) {
return true; // Найден путь
}
boolean success = false;
if (x >= 1 && isFree(X - 1, Y)) { //Пытаемся идти вправо
success = getPath(x - 1, y, path, cache); // Свободно! Можно идти вправо
}
if (!success && y >= 1 && isFree(x, y - 1)) { // Пытаемся идти вниз
success = getPath(x, y - 1, path, cache); // Свободно! Можно идти вниз
}
if (!success) {
path.remove(p); //Неверный путь! Прекратить движение этим маршрутом
}
cache.put(p, success); // Вычисляем результат
return success;
}
Это простое изменение сделает наш код более быстрым.
78. Реализуйте метод сжатия строки на основе счетчика повторяющихся символов. Например, строка aabcccccaaa должна превратиться в а2b1с5аЗ. Если «сжатая» строка оказывается длиннее исходной, метод должен вернуть исходную строку.
Например, строка aabcccccaaa должна превратиться в а2b1с5аЗ. Если «сжатая» строка оказывается длиннее исходной, метод должен вернуть исходную строку.
public String compressBad(String str) {
String mystr = "";
char last = str.charAt(0);
int count = 1;
for (int i = 1; i < str.length(); i++) {
if (str.charAt(i) == last) { // Находим повторяющийся символ
count++;
} else { // Вставляем счетчик символа и обновляем последний символ
mystr += last + count;
last = str.charAt(i);
count = 1;
}
}
return mystr + last + count;
}
Этот код не отслеживает случай, когда сжатая строка получается длиннее исходной. Но эффективен ли этот алгоритм?
Давайте оценим время выполнения этого кода: 0(р + k?), где р — размер исходной строки, a k — количество последовательностей символов. Например, если строка aabccdeeaa содержит 6 последовательностей символов. Алгоритм работает медленно, поскольку используется конкатенация строк, требующая обычно 0(n?) времени.
Улучшить код можно, используя, например StringBuffer в Java:
String compressBetter(String str) {
/* Проверяем, вдруг сжатие создаст более длинную строку */
int size = countCompression(str);
if (size >= str.length()) {
return str;
}
StringBuffer mystr = new StringBuffer();
char last = str.charAt(0);
int count = 1;
for (int i = 1; i < str.length(); i++) {
if (str.charAt(i) == last) { // Найден повторяющийся символ
count++;
} else { // Вставляем счетчик символов, обновляем последний символ
mystr.append(last); // Вставляем символ
mystr.append(count); // Вставляем счетчик
last = str.charAt(i);
count = 1;
}
}
/* В строках 15-16 символы вставляются, когда
* изменяется повторяющийся символ. Мы должны обновить строку
* в конце метода, так как самый последний повторяющийся символ
* еще не был установлен в сжатой строке
* */
mystr.append(last);
mystr.append(count);
return mystr.toString();
}
int countCompression(String str) {
char last = str.charAt(0);
int size = 0;
int count = 1;
for (int i = 1; i < str.length(); i++) {
if (str.charAt(i) == last) {
count++;
} else {
last = str.charAt(i);
size += 1 + String.valueOf(count).length();
count = 0;
}
}
size += 1 + String.valueOf(count).length();
return size;
}
Этот алгоритм намного эффективнее. Обратите внимание на проверку размера в строках 2—5.
Если мы не хотим (или не можем) использовать stringBuffer, можно решить эту задачу иначе. В строке 2 рассчитывается конечный размер строки, что позволит создать массив подходящего размера:
String compressAlternate(String str) {
/* Проверяем, вдруг сжатие создаст более длинную строку */
int size = countCompression(str);
if (size >= str.length()) {
return str;
}
char[] array = new char[size];
int index = 0;
char last = str.charAt(0);
int count = 1;
for (int i = 1; i < str.length(); i++) {
if (str.charAt(i) == last) { // Найдите повторяющийся символ
count++;
} else {
/* Обоновляем счетчик повторяющихся символов */
index = setChar(str, array, last, index, count);
last = str.charAt(i);
count = 1;
}
}
/* Обновляем строку с последним набором повторяющихся символов */
index = setchar(str, array, last, index, count);
return String.valueOf(array);
}
int setChar(String str, char[] array, char c, int index,
int count) {
array[index] = c;
index++;
/* Конвертируем счетчик в строку */
char[] cnt = String. valueOf (count) .toCharArray();
/* Копируем символы от большего разряда к меньшему */
for (char х : cnt) {
array[index] = х;
index++;
}
return index;
}
int countCompression(String str) {
/* так же, как и раньше */
}
Подобно предыдущему решению, этот код потребует O(N) времени и 0(N) пространства.
79. Вы находитесь в автомобиле, где к полу веревочкой привязан шар, наполненный гелием. Окна закрыты. Вы нажимаете на педаль газа. Что произойдет с шаром: переместится он вперед, назад или останется в прежнем положении?
Что произойдет с шаром?
Переместится назад, против движения
Переместится вперёд, по движению
Останется на месте
Интуиция подсказывает нам (практически всем), что при ускорении шарик будет отбрасываться назад. Однако интуиция в данном случае ошибается. Ваша задача — путем, дедуктивных размышлений определить, как на самом деле движется шарик, и объяснить это интервьюеру.
Хороший ответ — предложить аналогию с ватерпасом (строительный уровень). Хотя эта штука не всегда имеется под рукой, когда она необходима, есть люди, которые работают с ней постоянно. Особенно часто она бывает у плотников, он и пользуются уровнем, чтобы убедиться, что поверхность является горизонтальной. В ватерпасе есть узкая стеклянная трубка с цветной жидкостью, а в ней — пузырек воздуха. Всякий раз, когда уровень ставится на идеально горизонтальную поверхность, пузырек оказывается в середине трубки. Если поверхность негоризонтальная, пузырек смещается в сторону более высокой части трубки. Аналогия здесь в том, что пузырек — это всего лишь «дырка» в жидкости. Когда поверхность не является ровной, сила тяжести толкает жидкость в сторону более низкого края. Это, в свою очередь, перемещает пузырек туда, где жидкости нет, — к противоположному краю.
Отвяжите шарик с гелием и позвольте ему удариться о «лунную крышу». Теперь он станет своего рода уровнем. Шарик является «пузырьком», состоящим из гелия, газа с меньшей плотностью, который находится в более плотном воздухе, и вся эта комбинация газов находится в емкости (автомобиле). Сила тяжести толкает белее тяжелый воздух вниз, заставляя легкий шарик давить на «лунную крышу».
Когда автомобиль ускоряется, воздух, как и ваше тело, отбрасывается назад. Это заставляет более легкий, чем воздух, шарик двигаться вперед. Если резко нажать на тормоза, воздух надавит на переднее окно, но шарик при этом отбрасывается назад. То же самое наблюдается и при поворотах. Центробежная сила в этом случае толкает воздух в сторону, противоположную) оси поворота, а шарик — в ее сторону. Разумеется, то же самое происходит и тогда, когда шарик привязан к чему–то, но теперь у него появляется меньше свободы для перемещения. Короткий ответ на заданный вопрос такой: шарик с гелием смещается в направлении любого ускорения.
Вы не верите? Тогда прямо сейчас отложите книгу, сходите в супермаркет, купите шарик, наполненный гелием, и привяжите его веревочкой к рычагу переключения передач или к рычагу парковочного тормоза. Отправляйтесь домой (необязательно это делать на сумасшедшей скорости). Вы будете удивлены, но шарик действительно смещается в другом направлении, а не в том, о котором вы думали. Когда вы нажимаете на газ, шарик устремляется вперед, словно пытается соревноваться с машиной на участке до следующего светофора. Резко затормозите, так, чтобы детские игрушки упали с сидения, и шарик дернется назад. При повороте на высокой скорости, когда ваше тело сильно наклоняется в одну сторону, сумасшедший шарик резко двигается в другую. Об этой кажущейся странности есть ролики на YouTube.
Почему наша интуиция подсказывает нам правильные ответы о строительном уровне и неправильные о шарике с гелием. Если говорить о ватерпасе, тяжелая жидкость в нем окрашена флуоресцентной краской (и в этом отношении похожа по цвету на напитки для спортсменов), в то время как пузырек в ней практически бесцветный. Мы ассоциируем цвет с плотностью, а прозрачность — с пустотой. Поэтому этот инстинкт в случае с шариком оказывается совершенно неправильным. Воздух невидим, и в 99 % всего времени мы его игнорируем. Шарик же окрашен в симпатичный цвет и, кажется, кричит: «Посмотри на меня!» Мы почти все забываем, что в окружающем нас воздухе появляется частичный вакуум. Шарик с гелием двигается в направлении, которое противоположно перемещению основной массы, потому что ему не хватает веса. Реальная масса — воздух — остается невидимой.
Интервьюеры, задающие этот вопрос, не ожидают, что вы хорошо знаете физику. Имеется альтернативный вариант вопроса, который строится на теории относительности. Я говорю серьезно.
Он относится к известному мысленному эксперименту Альберта Эйнштейна, связанному с лифтом. Представьте, что вы находитесь в лифте и едете в кабинет вашего консультанта по налогам, а в этот момент злобное внеземное существо решает, что было бы забавно телепортировать вас и лифт в межгалактическое пространство. Лифт — закрытое помещение, и там достаточно воздуха, чтобы вы какое–то время оставались в живых и несколько минут развлекали это чужеземное существо. Окон нет, и поэтому вы не можете выглянуть и увидеть, где находитесь. Существо подцепило лифт к тросу и тянет его с постоянным ускорением, совершенно равным силе тяжести Земли. Можете ли вы в закрытом лифте определить, действует ли на вас фактическое ускорение Земли или «искусственная» сила тяжести, имитируемая при помощи ускорения?
Эйнштейн утверждал, что нет. Если вы вытащили бы ключи из кармана и подбросили, они полетели бы на пол лифта точно же, как на Земле. Если бы мы взяли шарик с гелием, привязанный к веревочке, он устремился бы вверх так же, как на Земле. Другими словами, вам в лифте все будет казаться совершенно нормальным.
Принцип эквивалентности Эйнштейна заключается в том, что нет простого физического эксперимента, способного показать разницу между силой тяжести и ускорением. Это допущение является основным в теории гравитации Эйнштейна, известной как общая теория относительности. Физики пытаются отыскать сбои в принципе эквивалентности уже почти столетие. Пытаются и не могут. Поэтому можно вполне безопасно предположить, что идея Эйнштейна является правильной, по крайней мере для любых экспериментов, которые вы можете проделать в машине с шариком за два доллара.
Итак, вот физический эксперимент. Привяжите веревку с одной стороны к свинцовому грузу, а с другой — к вашему указательному пальцу на правой руке. Привяжите к тому же пальцу и шарик с гелием. Обратите внимание на угол между двумя веревками.
В лифте, в припаркованном автомобиле или в реактивном самолете, терпящем аварию, результаты будут теми же самыми. Веревка с привязанным грузом будет направлена прямо вниз, веревка шарика — прямо вверх. Так что две веревки, привязанные к вашему пальцу, образуют прямую линию. И так будет всякий раз, когда вы подвергаетесь действию силы тяжести.
Теперь представьте, что произойдет, когда вы начнете движение. С увеличением скорости ваше тело будет вдавливаться в сиденье. Ошибочно подсказывающая вам интуиция может сообщить, что свинцовый груз и шарик будут оба отбрасываться немного назад по отношению к вашему пальцу и что в ходе ускорения между двумя веревочками образуется угол (если верить интуиции). Этот угол позволил бы определить разницу между силой тяжести и силой ускорения. Когда автомобиль подвергается только силе тяжести, две веревочки образуют прямую линию. Но когда на них воздействует центробежная сил или другой вид ускорения, между веревочками образуется угол, при котором в качестве его вершины выступает ваш палец. Это все, что вам необходимо, чтобы доказать, что общая теория относительности является ошибочной. Если это случится, можете смело забыть о своем желании получить работу в Google, потому что теперь ваши амбиции резко повысятся — вы захотите получить Нобелевскую премию.
Однако поскольку принцип эквивалентности строго и много раз проверялся, и всегда демонстрировалась его правота, описанный вариант не случится, и вы можете использовать принцип эквивалентности для ответа на этот вопрос. Физика проявит себя точно так же в ускоряющемся автомобиле, как и в машине, подвергающейся действию только силы тяжести. В обоих случаях шарик, ваш палец и свинцовый груз будут образовывать прямую линию. Так что шарик с гелием (из нашего вопроса) действительно движется в ту сторону, которая противоположно ожидаемому нами движению объекта, обладающего массой. Другими словами, он сместится вперед, а не назад… влево, а не вправо… и, конечно, вверх, а не вниз.
80. Задачка, на примере который можно кратко ознакомиться с основами RSA-криптографии.
Допустим, вы хотите удостовериться, что у вашего друга Пети есть номер вашего телефона. Но вы не можете спросить его об этом прямо. Вам придется написать ему сообщение на карточке и отдать карточку Кате, которая будет выступать в качестве посредника. Катя отнесет карточку Пете, он напишет свое сообщение и отдаст его Кате, которая передаст его вам. Вы не хотите, чтобы Катя узнала ваш номер телефона. Как в таких обстоятельствах следует сформулировать свой вопрос Пете?
Даже не зная ничего про RSA можно попробовать придумать ответ.
Как удостовериться, что у друга есть ваш номер телефона так, чтобы никто об этом не узнал, причём нельзя спросить его напрямую?
Поясним условия подробнее. Например, вы хотите удостовериться, что у Пети есть номер вашего телефона. Но вы не можете спросить его об этом прямо. Вам придется написать ему сообщение на карточке и отдать карточку Кате, которая будет выступать в качестве посредника. Катя отнесет карточку Пете, он напишет свое сообщение и отдаст его Кате, которая передаст его вам. Вы не хотите, чтобы Катя узнала ваш номер телефона. Как в таких обстоятельствах следует сформулировать свой вопрос Пете?
Даже если вы дадите короткий и простой ответ, вас могут попросить представить и ответ на основе RSA. Он не такой сложный, если у Пети есть компьютер, и если он сможет следовать вашим рекомендациям. Спросите интервьюера, насколько Петя продвинут в математике и компьютерах.
При использовании RSA генерируется два ключа: общественный и частный. Общественный ключ похож на адрес электронной почты. Он позволяет любому человеку отправить вам сообщение. Частный ключ — это что-то вроде вашего пароля к электронной почте. Вам он необходим, чтобы получить ваши е-мейлы, и вы должны держать его в секрете, так как в противном случае сообщение, адресованное вам, сможет прочитать любой желающий.
Вы не сможете послать Пете секретное сообщение, поскольку он не создал свои ключи. Он, может быть, даже не знает, что такое RSA, и не будет о нем ничего знать до тех пор, пока вы ему не расскажете! Но для этого вам и не нужно отправлять ему секретное сообщение. Вы хотите, чтобы Петя отправил такое сообщение вам, а именно — ваш номер телефона. Это означает, что нам нужны ключи для себя, а не для Пети. Вот общая схема решения.
«Привет, Петя! Мы собираемся воспользоваться криптографией RSA. Может быть, ты не знаешь, что это такое, но я объясню тебе, что надо сделать. Вот мой общественный ключ… Возьми его и мой номер телефона и придумай зашифрованный номер, следуя инструкциям. Пришли этот зашифрованный номер обратно мне через Катю».
Трюк в том, чтобы составить инструкцию так, чтобы ею мог воспользоваться практически каждый. К тому же вам нужно обеспечить и необходимую точность.
Криптография RSA впервые была описана, как теперь считается, в 1973 году. Её первым создателем был британский математик Клиффорд Кок, который тогда работал на секретной службе Её Величества. В те годы его схема считалась непрактичной: для нее обязательно нужен был компьютер. В те времена, когда шпионы обычно обходились фотоаппаратами, спрятанными в запонки, эту трудность было не так легко преодолеть. До 1997 года идея Кока считалась секретной. Однако в 1978 году трое ученых из MIT, Рональд Ривест, Ади Шамир и Леонард Адлеман, предложили ее независимо от Кока. Первые буквы их фамилий (RSA) стали акронимом и названием этого алгоритма.
В системе RSA человек, который хочет получать сообщения, должен выбрать два случайных простых числа p и q. Числа должны быть большими и, по крайней мере, такими же крупными (по числу цифр), как и числа или сообщения, которые надо передать. Для телефонного номера из десяти цифр р и q также должны состоять (каждое) по крайней мере из десяти цифр.
Один из способов выбора p и q — воспользоваться Google и найти веб-сайт, на котором перечисляются крупные простые числа. Скажем, Primes Pages, который ведет Крис Колдуэлл из Университета Теннесси в Мартине. Выберите случайным образом два десятизначных простых числа. Вот пример такой парочки:
1 500 450 271 и 3 367 900 313
Назовите их соответственно р и q. Вам придется перемножить их и получить точный ответ. Здесь может быть небольшая трудность, так как вы не сможете воспользоваться калькуляторами, Excel или Google, да и большинством любых других потребительских программ, поскольку они показывают ограниченное число значимых цифр. Один из вариантов — умножить вручную. Или использовать Wolfram Alpha. Введите
1 500 450 271 и 3 367 900 313
и вы получите точный ответ:
5 053 366 937 341 834 823
Назовите это произведение N. Оно является одной из составляющих вашего общественного ключа. Другим компонентом является число, называемое е, произвольно выбранное и равное по длине, в идеале N, но которое не делится точно на произведение (р - 1) (q - 1). Я, возможно, запутал вас последним предложением, но пока об этом не беспокойтесь.
Во многих прикладных программах в качестве е шифровальщики выбирают простую тройку. Этот достаточно хороший вариант для многих целей и позволяет быстро шифровать.
Вы получили N и е, у вас теперь имеется все необходимое для решения задачи. Всего лишь нужно отправить эти два числа Пете, а также полное «Руководство для чайников по криптографии RSA». Пете необходимо вычислить
хe mod N,
где Х – это номер телефона. Поскольку в качестве e мы выбрали 3, часть слева — это х, возведенное в куб. Это будет число из 30 цифр. «Mod» указывает на деление по модулю, что означает, что вы разделите x? на N и возьмете только остаток. Этот остаток должен быть в диапазоне от 0 до N - 1. Вполне вероятно, что будет число из 20 цифр. Это число является зашифрованным посланием, которое Петя отправит обратно вам.
Для решения этой задачи Пете необходимо возвести в куб число, и произвести деление. Важная часть инструкции может быть такой.
«Петя, я хочу, чтобы ты внимательно следовал этим инструкциям и не сомневался. Исходи из того, что мой телефонный номер — это обычное число из десяти цифр. Вначале необходимо, чтобы ты возвел в куб это число (умножь вначале его на само себя, а затем полученное произведение умножь еще раз на первоначальный номер). Ответ будет числом из 30 цифр, и оно должно быть точным. Выполни это умножение, даже если придется сделать это вручную, и дважды его проверь. Затем необходимо, чтобы ты осуществил самый длинный процесс деления за всю свою жизнь. Раздели полученный результат на число 5 053 366 937 341 834 823. Важно не ошибиться! Пришли мне только остаток этого деления. Важно, чтобы ты не прислал целую часть, а только остаток».
Предположим, что у Пети есть доступ к Интернету (довольно обоснованное допущение в настоящее время, не так ли?), тогда пишем:
«Петя, отправляйся на веб-сайт и www.wolframalpha.com. Ты увидишь там длинный прямоугольник с границами, окрашенными в оранжевый цвет. Введи мой номер телефона из 10 цифр в этот прямоугольник без всяких дефисов, точек и скобок, только десять цифр. Сразу же после номера телефона напечатай следующее
^3 mod 5053366937341834823
Затем кликни на маленький знак равенства, находящийся в правой части прямоугольника. Ответом будет, вероятно, число из 20 цифр, которое появится в прямоугольнике со словом Result (Результат). Пришли мне этот ответ, и только этот ответ».
Естественно, Катя прочитает эти инструкции, а также прочитает ответ Пети. Но она не сможет ничего понять. Она получила число из 20 цифр, которое, как она знает, является остатком куба телефонного номера, разделенного на 5053366937341834823, по модулю. Пока никто не придумал эффективного способа, позволяющего восстановить по остатку исходное число, в данном случае являющееся телефонным номером.
Можете ли вы предложить что-то еще лучше? Да, поскольку у вас есть секретный декодирующий ключ. Это d, инверсивное значение е mod (р - 1) (q - 1). Для его вычисления имеется удобный алгоритм, которым можно воспользоваться, конечно, при условии, что вы знаете два простых числа p и q, которые были использованы для получения N. (Вы ведь знаете их, потому что сами их выбрали, не забыли?)
Назовите кодированное число/сообщение, которое Петя отправил вам назад. Y. Его первоначальное сообщение было
Yd mod N.
Для определения этого значения нужно всего лишь ввести это в Wolfram Alpha (замените Y, d и N фактическими числами).
Катя знает N, поскольку оно было написано на карточке, которую вы попросили её передать Пете. Она знает Y, поскольку это число было указано в ответе Пети, отправленном вам. Но она не знает d, и у нее нет возможности его выяснить. Катя сталкивается с алгоритмической трудностью. При умножении двух чисел никаких сложностей ни у кого не возникнет, ведь этому все-таки в школе всех научили. А вот определить множитель, имея огромное число, гораздо сложнее.
81. Задача на знание конкретных языков. Объясните разницу между шаблонами в C++ и дженериками в Java.
Многие программисты полагают, что шаблоны C++ и дженерики (например в Java) — это одно и то же, ведь их синтаксис похож: в обоих случаях можно написать что-то вроде List. Но различия на самом деле есть.
Многие программисты полагают, что шаблоны C++ и дженерики (например в Java) — это одно и то же, ведь их синтаксис похож: в обоих случаях можно написать что-то вроде List<T>. Чтобы найти различия, давайте разберемся, что такое шаблоны и дженерики, и как они реализуется в каждом из языков.
Дженерики Java связаны с идеей «стирания типов» (type erasure). Эта техника устраняет параметры типов, когда исходный код преобразуется в байткод JVM.
Предположим, что у вас есть Java-код:
Vector vector = new Vector();
vector.add(new String("hello"));
String str = vector.get(0);
Во время компиляции он будет преобразован:
Vector vector = new Vector();
vector.add(new String("hello"));
String str = (String) vector.get(0);
Использование обобщений Java не повлияло на наши возможности, но сделало код более красивым. Поэтому дженерики в Java часто называют «синтаксическим сахаром».
Дженерики сильно отличаются от шаблонов C++. Шаблоны в C++ представляют собой набор макросов, создающих новую копию шаблонного кода для каждого типа. Особенно это заметно на следующем примере: экземпляр MyClass<Foo> не сможет совместно с MyClass<Bar> использовать статическую переменную. А два экземпляра MyClass<Foo> будут совместно использовать статическую переменную.
Чтобы проиллюстрировать этот пример, рассмотрим следующий код:
/*** MyClass.h ***/
template
class MyClass {
public:
static int val;
MyClass(int v){ val = v; }
};
/*** MyClass.cpp ***/
template
int MyClass::val;
template class MyClass;
template class MyClass;
/*** main.cpp ***/
MyClass * foo1 = new MyClass(10);
MyClass * foo2 = new MyClass(15);
MyClass * bar1 = new MyClass(20);
MyClass * bar2 = new MyClass(35);
int f1 = foo1->val; //будет равно 15
int f2 = foo2->val; //будет равно 15
int b1 = bar1->val; //будет равно 35
int b2 = bar2->val; //будет равно 35
В Java различные экземпляры MyClass могут совместно использовать статические переменные, независимо от параметров типа.
Из-за различий в архитектуре дженерики Java и шаблоны C++ имеют множество отличий:
int, а дженерики Java — нет, они обязаны использовать Integer.CardDeck и указать, что параметр типа должен наследоваться от CardGame.Foo в MyClass<Foo>) для статических методов и переменных, так как они могут совместно использоваться в MyClass<Foo> и MyClass<Bar>. В C++ — это разные классы, поэтому тип из параметра можно использовать для статических методов и переменных.MyClass<T>, независимо от их параметров, относятся к одному и тому же типу. Параметры типов уничтожаются после компиляции. В C++ экземпляры с разными параметрами типов — различные типы.Помните, что хотя дженерики Java и шаблоны C++ внешне похожи, это разные вещи.
82. Реализуйте вручную «умный» указатель с автоматическим управлением памятью на C++.
Умный (интеллектуальный) указатель — это тот же обычный указатель, обеспечивающий безопасность благодаря автоматическому управлению памятью. Такой указатель помогает избежать множества проблем: «висячие» указатели, «утечки» памяти и отказы в выделении памяти. Интеллектуальный указатель должен подсчитывать количество ссылок на указанный объект.
На первый взгляд эта задача кажется довольно сложной, особенно если вы не эксперт в C++.
Умный (интеллектуальный) указатель — это тот же обычный указатель, обеспечивающий безопасность благодаря автоматическому управлению памятью. Такой указатель помогает избежать множества проблем: «висячие» указатели, «утечки» памяти и отказы в выделении памяти (графические библиотеки помогают избежать таких проблем при создании UI). Интеллектуальный указатель должен подсчитывать количество ссылок на указанный объект.
На первый взгляд эта задача кажется довольно сложной, особенно если вы не эксперт в C++. Один из полезных подходов к решению — разделить задачу на две части: 1) обрисовать общий подход и создать псевдокод, а затем 2) написать подробный код.
Нам нужна переменная — счетчик ссылок, которая будет увеличиваться, как только мы добавляем новую ссылку на объект, и уменьшаться, когда мы ее удаляем. Наш псевдокод может иметь следующий вид:
template
class SmartPointer {
/* Класс интеллектуального указателя нуждается в указателях на собственно
* себя и на счетчик ссылок. Оба они должны быть указателями, а не реальным
* объектом или значением счетчика ссылок, так как цель интеллектуального
* указателя - в подсчете количества ссылок через множество интеллектуальных
* указателей н один объект */
T * obj;
unsigned * ref_count;
}
Для этого класса нам потребуется конструктор и деструктор, поэтому опишем их:
SmartPointer(T * object) {
/* Мы хотим установить значение T * obj и установить счетчик
* ссылок в 1. */
}
SmartPointer(SmartPointer & sptr) {
/* Этот конструктор создает новый интеллектуальный указатель на существующий
* объект. Нам нужно сперва установить obj и ref_count
* такими же, как в sptr. Затем,
* поскольку мы создали новую ссылку на obj, нам нужно
* увеличить ref_count. */
}
~SmartPointer(SmartPointer sptr) {
/* Уничтожаем ссылку на объект. Уменьшаем
* ref_count. Если ref_count = 0, освобождаем память и
* уничтожаем объект. */
}
Существует дополнительный способ создания ссылок — установка одного SmartPointer в другой. Нам понадобится переопределить оператор = для обработки этого случая, но сначала давайте сделаем набросок кода:
onSetEqals(SmartPointer ptr1, SmartPointer ptr2) {
/* Если ptr1 имеет существующее значение, уменьшить его количество ссылок.
* Затем копируем указатели obj и ref_count. Наконец,
* так как мы создали новую ссылку, нам нужно увеличить
* ref_count. */
}
Осталось только написать код, а это дело техники:
template
class SmartPointer {
public:
SmartPointer(T * ptr) {
ref = ptr;
ref_count = (unsigned*)malloc(sizeof(unsigned));
*ref_count = 1;
}
SmartPointer(SmartPointer & sptr) {
ref = sptr.ref;
ref_count = sptr.ref_count;
++(*ref_count);
}
/* Перезаписываем оператор равенства (eqal), поэтому когда вы установите
* один интеллектуальный указатель в другой, количество ссылок старого указателя
* будет уменьшено, а нового - увеличено.
*/
SmartPointer & operator=(SmartPointer & sptr) {
/* Если уже присвоено объекту, удаляем одну ссылку. */
if (*ref_count > 0) {
remove();
}
if (this != &sptr) {
ref = sptr.ref;
ref_count = sptr.ref_count;
++(*ref_count);
}
return *this;
}
~SmartPointer() {
remove(); // удаляем одну ссылку на объект.
}
T operator*() {
return *ref;
}
protected:
void remove() {
--(*ref_count);
if (ref_count == 0) {
delete ref;
free(ref_count);
ref = NULL;
ref_count = NULL;
}
}
T * ref;
unsigned * ref_count;
}
83. Эта головоломка, в которой вас пытаются запутать, предложив поменять свое решение, известна также под именем «Парадокс Монти Холла». Монти Холл был первым ведущим телевизионной игры-шоу «Давайте заключим сделку».
Перед вами три коробки, в одной из которых находится ценный приз, в двух других ничего нет. Вы можете выбрать любую коробку, но вам по-прежнему неизвестно, в какой именно приз. Одну из двух не выбранных вами коробок открывают и показывают, что она пустая. Теперь вы можете или оставить коробку, которую вы первоначально выбрали (оставить), или поменять ее на другую, неоткрытую (заменить). Что вы предпочтете сделать (оставить или заменить)?
Этот вопрос является разновидностью парадокса Монти Холла и был сформулирован в 1975 году статистиком географических данных Стивом Селвином. Монти Холл был первым ведущим телевизионной игры-шоу «Давайте заключим сделку». Загадка Селвина относится к ситуации, немного напоминающей финальный раунд в этом телевизионном шоу, при котором участники выбирают призы, находящиеся за дверями. В письме в American Statistician Селвин утверждал, что вам следует согласиться на обмен. Этот вариант показался многим настолько противоречивым, что в следующем письме Селвину пришлось его защищать. Монти Холл написал Селвину и согласился с его анализом.
С тех пор этот парадокс стал темой огромного числа обсуждений. После упоминания о нем в 1990 году Мэрилин вос Савант в своей колонке, которую она ведет в журнале Parade, он стал популярным и у широкой общественности. На следующий год Джон Тьерни из New York Times рассказал, что эту загадку «обсуждают и в залах Центрального разведывательного управления, и в казармах пилотов самолетов-истребителей, участвующих в войне в Персидском заливе. Ее анализировали математики из Массачусетского технологического института, и программисты из Los Alamos National Laboratory…». Выяснилось, что эта задача используется и в передаче Car Talk, которая ведется на NRP а также в телевизионном шоу NUMB3RS. К ней прибегают на собеседованиях в Bank of America и в других финансовых фирмах. Циники могут отыскать параллель с управлением рисками в финансовой отрасли, когда вероятности тайно меняются и вам пытаются подсунуть «пустой ящик».
Самое интересное в загадке Селвина — ее трудность.
В ходе одного исследования было установлено, что только 12% людей, которым задавали этот вопрос, давали правильные ответы. Этот результат удивителен, если учесть, что любой человек, не имеющий никаких подсказок, при простой догадке может оказаться правым в 50 случаях из 100. Другими словами, это случай, когда интуиция ведет вас в неправильном направлении.
Большинство отвечающих полагают, что нет никакой разницы, оставите ли вы первую коробку или ее поменяете. Более продвинутые могут добавить, что любой, кто думает, что может повысить свои ожидания при помощи обмена, заблуждается, то есть ведет себя так же, как игроки-неудачники, настаивающие, что игровой автомат «подкручен» и поэтому в нем никогда нельзя выиграть джек-пот.
При любом вопросе, связанном с вероятностями, важно знать, что происходит случайно, а что преднамеренно. Скажем, ваш друг подбрасывает монету 10 раз, и каждый раз она падает орлом вверх. Каков шанс, что при следующем броске снова выпадет орел? Вы не можете это точно сказать до тех пор, пока не выясните, была ли предыдущая серия простым результатом удачи или следствием того, что у этой монеты имеются какие-то особенности.
Когда Селвин предложил эту загадку, первоначальный вариант шоу «Давайте заключим сделку» все еще выходил в эфир и уже стал неотъемлемой частью поп-культуры. Моя бабушка, которая смотрела это шоу, считала Монти мошенником, хотя и знаменитым. Вот как она это обосновывала, громко обращаясь к телевизору: «Если он хочет предложить вам эту дверь, он, должно быть, знает, что за ней находится что-то менее ценное, чем то, что уже есть у участника».
Надо сказать, что она не сильно ошибалась. В одном интервью Холл заявил, что, когда он знал, что участник выбрал самый крупный приз, он предлагал деньги человеку взамен того, что находится за выбранной им дверью. Это добавляло передаче зрелищности. Когда человек менял крупный приз на мелочевку, он превращался в неудачника, а это вызывает у аудитории гораздо больше эмоций.
Давайте дадим коробкам названия. Пусть они будут такими: выбранная, открываемая и искушающая. Первоначально шансы на то, что вы выберете коробку с призом, равны один к трем.
После вашего выбора открывается одна из двух оставшихся коробок, и оказывается, что она пустая. Чтобы определить, как это повлияло на ваши шансы получить крупный приз, вам необходимо знать, кто открывает вторую коробку и какова его цель.
Имеется два вероятных варианта.
Исходная задачка Селвина не оставляет сомнений, что второй вариант желателен для ТВ. («Несомненно, Монти Холл знает, какая коробка является ценной, и поэтому не открывает коробку, где лежат ключи от автомобиля.»)
Это важное уточнение часто упускается из виду. Как уже говорилось выше, эта задачка, задаваемая на собеседовании, является противоречивой. В ней не упоминается о ведущем, который может прибегать к махинациям, и не рассказывается, как выбирается открываемая коробка. Вам следует попросить интервьюера уточнить эти детали и указать, что вопрос позволяет дать разные ответы в зависимости от того, окак выбирается вторая коробка.
Открыв коробку при первом варианте, вы получаете определенную информацию: в этой коробке приза нет, хотя он мог там быть. Это резко повышает ваши шансы на то, что в выбранной вами коробке есть приз, с 1⁄3 до 1⁄2. Так же меняются шансы на наличие приза и в искушающей коробке. Поскольку и у той, и другой коробки шансы на выигрыш пятьдесят на пятьдесят, менять одну коробку на другую нет никакого смысла.
Открыв коробку при втором варианте, никакой полезной информации вы не получаете. Монти (или любой другой человек) знает, что лежит в коробках, и всегда может выбрать пустую и показать ее вам. Его преднамеренная демонстрация никак не повышает шансы, что выбранная вами первоначально коробка является ценной. Другими словами, первоначальный шанс, равный 1⁄3, после открытия второй коробки таким же и остается.
Другими словами, открытие второй коробки не изменило вероятности, равной 2⁄3, что в одной из двух коробок находится приз. Но поскольку одна из этих коробок, как было показано, пустая, эта вероятность, равная 2⁄3, теперь полностью приходится на искушающую коробку. Приняв предложение ведущего о замене, вы удваиваете ваши шансы на получение приза.
Если вы по-прежнему не понимаете, почему ответ Селвина является правильным, представьте, что имеется 100 коробок. Вы выбираете коробку № 79. Затем Монти открывает 98 из оставшихся 99 коробок. Все они пустые. После этого, помимо вашей коробки, неоткрытой остается, скажем, коробка № 18. Монти спрашивает вас, хотите ли вы поменять коробку № 79 на коробку № 18?
Вы начинали с вероятности 1 к 99, что ключи от машины лежат в вашей коробке. Монти ведет себя как ведущий. И он не намерен показать вам ничего, кроме пустой коробки, и он может это сделать. Шанс, что приз находится в вашей коробке, остается прежним, то есть 1⁄100, в то время как шанс, что он в ящике № 18, после того, как ведущий открыл все остальные коробки, которые оказались пустыми, возрастает до 99⁄100. Так что, если перед вами 100 коробок, вы повышаете шансы в 99 раз (!), если меняете ее на оставшуюся.
Когда психологи Дональд Грэнберг и Тад Браун во время собеседования предлагали эту задачку (в их случае люди выбирали двери), они все время слышали объяснения, вроде следующих:
«Я не стал бы выбирать другую дверь: если я ошибусь при обмене, я буду больше терзать себя, чем если я останусь со своей дверью и проиграю».
«Это был мой первый выбор, сделанный инстинктивно, и, если я ошибся, что ж, пусть так оно и будет. Но если я поменяю двери и окажусь неправым, это будет еще хуже».
«Я действительно буду сожалеть, если я поменяю двери и проиграю. Психологически лучше оставаться верным своему первому выбору».
Все это синдромы боязни потери. Нам, людям, свойственно уходить от решений, которые могут оказаться плохими, даже если шансы на выигрыш благоприятны. Лучше быть в безопасности, чем сожалеть. Любой, кто придумывает новые продукты, должен хорошо об этом помнить. Потребитель, думающий о смене коробок или брендов, возможно, ориентируется на что-то такое, что не имеет ничего общего с логикой.
Боязнь потери свойственна и математическим гениям. В этом отношении они не отличаются от всех остальных. Говорят, что знаменитый математик Пол Эрдёш, когда в первый раз услышал об этой загадке, решил ее неправильно. «Даже физики, нобелевские лауреаты, регулярно дают неправильные ответы, — рассказал психолог Массимо Пьяттелли-Палмарини, — причем они настаивают на своем неверном варианте и готовы разнести в пух и прах любого, кто предлагает правильный ответ».
84. У вас есть пустое помещение и группа людей снаружи. За один ход вы можете либо позволить одному человеку войти в помещение, либо выпустить из него одного человека. Можете ли вы предложить серию ходов, при которой каждая возможная комбинация людей находится в помещении только один раз?
Нужно время, чтобы понять, чего именно хочет от вас интервьюер. Разобраться в этом помогает простой пример. Скажем, за порогом находятся два человека, Ларри и Сергей. Возможны четыре комбинации их присутствия в комнате, учитывая тот случай, когда в комнате вообще никого нет.
Вот они:
В помещении никого нет.
В помещении только Ларри.
В помещении только Сергей.
В помещении Ларри и Сергей.
Вопрос заключается в том, можем ли мы начать с того, что в комнате никого нет, а затем пройти указанную последовательность шагов?
Иными словами, как сгенерировать неповторяющиеся комбинации, меняя только один элемент за раз?
Полное условие задачи звучит так: «У вас есть пустое помещение и группа людей снаружи. За один ход вы можете либо позволить одному человеку войти в помещение, либо выпустить из него одного человека. Можете ли вы предложить серию ходов, при которой каждая возможная комбинация людей находится в помещении только один раз».
Нужно время, чтобы понять, чего именно хочет от вас интервьюер. Разобраться в этом помогает простой пример. Скажем, за порогом находятся два человека, Ларри и Сергей. Возможны четыре комбинации их присутствия в комнате, учитывая тот случай, когда в комнате вообще никого нет.
Вот они:
Вопрос заключается в том, можем ли мы начать с того, что в комнате никого нет, а затем пройти указанную последовательность шагов? Мы помним, что только один человек может входить в комнату и покидать ее за один раз, и никакие шаги не могут повторяться даже в течение доли секунд. Так что следовать указанному порядку не удастся, потому что нельзя перейти от «только Ларри» к «только Сергею» за один шаг. Либо Ларри покивает комнату до того, как в нее войдет Сергей, но в этом случае мы повторяем шаг «никого нет», либо Сергей входит до того, как Ларри выходит, и в этом случае в какой-то момент в комнате находятся оба. Решение здесь другое.
Это простой случай, а вас просят универсальный вариант, подходящий для любого возможного числа людей N. Каждый человек может входить в помещение или выходить из него, что означает, что число комбинаций с увеличением N возрастает по экспоненте, так что подбирать варианты вручную нереально. Потребуется хороший алгоритм.
Для решения этой задачи есть два обычных пути. Один из них — начать с небольшого числа и наращивать его. Мы уже знаем, как решить эту задачу для двух человек. Добавим третьего участника — Эрика. Как он изменит ситуацию? На базовом уровне это означает, что нам нужно повторить шаги для двух человек дважды, без Эрика и с Эриком. Итак, в помещении никого нет.
Затем появляется Эрик.
Мы хотим повторить шаги, теперь уже с Эриком. Но нам надо повторять их в обратном порядке, поскольку мы начинаем там, где шаг № 4, при котором Сергей остается один в помещении, уже сделан. Фактически, мы меняем направленность движений Ларри и Сергея, то есть каждый их вход становится их выходом и наоборот. Все это время Эрик остается в помещении. Вот остальная часть инструкций:
Вот шаблон для алгоритма. Пусть теперь героев четверо. Вы проводите указанные восемь шагов, а затем добавляете шаги с четвертым человеком. При четырех участниках общее количество шагов составляет 16. Число шагов при каждом следующем участнике возрастает вдвое. Если у нас n человек, то необходимо сделать 2n шагов.
В самом широком смысле этот вопрос относится к столкновению аналогового и цифрового процессов. Люди входят и выходят — это аналоговый процесс. Вы не можете мгновенно перенести человека из одного места в другое, как это можно сделать с цифрами. С подобным столкнулись уже в начале информационной эпохи. В те годы, когда возник первый вал цифрового Джаггернаута, Фрэнк Грей был ученым в Bell Labs. Грей разработал многие принципы, лежащие в основе цветных телевизионных передач. Его имя хорошо знают благодаря коду Грея, придуманному им в середине 1940-х годов.
Вначале телевидение было только аналоговым. Электронный луч горизонтального сканирования отклонялся вверх и вниз при помощи магнитного поля, создаваемого все время меняющимся напряжением. Грей хотел перевести аналоговое напряжение в цифровое значение (серию закодированных импульсов). У инженеров того времени было довольно специфическое понимание (скорее близкое к знаниям, почерпнутым из научно-фантастической литературы, а не научным) того, как можно направить электронный луч через маску с отверстиями, представляющими бинарные числа. Разные части маски, соответствующие разным углам отклонения, имели разные шаблоны отверстий. Луч должен был определять необходимое напряжение, выраженное в бинарных числах. Как и многие другие умные идеи, на практике она не работала. Электронные лучи двигались неупорядоченно. Скорее происходящее напоминало стрельбу из водяного пистолета по нашкодившему коту.
Главная проблема заключалась в том, что при переходе луча от одного числа, соответствующего напряжению, к другому возникали ошибочные считывания. Чтобы добиться нормальной работы Грею потребовался числовой код, где при переходе от числа к числу менялась только одна цифра. Такая система теперь называется кодами Грея. Вы можете создать их при любом основании, в том числе и при 10, но самым известным примером этого рода является бинарный код Грея. Он представлен на рисунке ниже.
Цифры в коде Грея не представляют степени 2 или чего-то другого реального. Это всего лишь код. Код 111 означает 5, и вам не следует пытаться извлечь из него что-то еще. Единственная причина существования кода Грея в том, что каждый номер может быть сгенерирован из предыдущего путем изменения всего одной цифры. Чтобы перейти от 5 (111) к 6, вам всего лишь нужно изменить среднюю цифру (и получится 101).
Грей придумал простую процедуру генерирования своих кодов. Начнем с 0 и 1. Они присваиваются обычным числам 0 и 1 (никакого фокуса в этом нет). Затем нолик и единичка идут в обратной последовательности — 1 и 0, и эти варианты добавляются к первым двум. Мы получаем 0, 1 и 1, 0.
Чтобы отличить исходную последовательность от обратной, необходимо слева от каждого кода добавить дополнительную цифру. Используем 0 для исходной последовательности и 1 для обратной версии. Это дает 00, 01, 11, 10.
Это первые четыре кода Грея. Хотите еще? Поставьте эту последовательность в обратном порядке, добавьте ее к первоначальной, и вы получите 00, 01, 11, 10, 10, 11, 01, 00. Затем добавьте нолик к первым четырем кодам и единичку к последним четырем: 000, 001, 011, 010, 110, 111, 101, 100.
Вот почему шестерку можно представить, как 101. Вы сможете без всякого труда понять, что у числа 8 код равен 1100. Схему Грея можно легко расширить до любого значения.
Коды Грея являются цикличными. Представьте, что вам удалось проехать на автомобиле миллион миль. На одометре появилось 999 999, а затем значение меняется на 000 000 (никакого миллионного числа нет). При использовании кодов Грея последнее число также возвращается к первому, но меняется всего на одну цифру. В приведенной выше таблице самое высшее число (100) можно изменить на самое низшее (000), всего лишь поменяв один бит.
Код Грея может быть использован и для решения нашей задачи. Любой инженер, решая эту задачу, должен связать ее с кодами Грея.
Представьте помещение в виде числа из n цифр, где n — количество людей. Каждая цифра соответствует разному человеку. Цифра 1 — человек находится в помещении, цифра 0 — пусто. Вот пример.
Каждое возможное бинарное число из n цифр (их 2n) представляет разную группировку людей. Нам необходимо составить цикл со всеми возможными группировками. Обычный порядок подсчета с бинарными цифрами не работает. А вот коды Грея здесь себя проявят отлично. Надо всего лишь пройти по кодам Грея в порядке их расположения, начав с 0000000000, интерпретировать их как этапы решения задачи. (Например, смена с 0 на 1 справа означает «Ларри вошел».) Решение начинается таким образом.
Это гарантирует, что на каждом шаге меняется только одна цифра и что только один человек входит в помещение или выходит из него.
Код Грея — это отмычка ко многим классическим загадкам, особенно таким, как «Башни Ханоя» и «Китайские кольца». Возможно, вы не бывали ни в Ханое, ни в Китае, но это неважно. К Азии это не имеет никакого отношения. А вот в жизни вы с этими загадками скорее всего встречались. В Башнях Ханоя имеется восемь цилиндрических дисков, надетых на один из трех штырей (внизу самый большой, вверху самый маленький). Игрок должен переместить все восемь дисков на другой штырь. Ограничение: нельзя класть диск на диск меньшего размера. Задача «Башня Ханоя» стала клише для видеоигр жанра «квест» (таких как Mass Effect, Zork Zero и «Звездные войны: рыцари Старой республики»). Все студенты, изучающие компьютерные науки, изучают и коды Грея, поэтому им часто на занятиях дается задание написать код для игры «Башни Ханоя» (который они должны использовать в видеоигре).
85. Напишите код поиска субматрицы с максимально возможной суммой в матрице N*N, содержащей положительные и отрицательные числа.
Полное условие задачи звучит так: дана матрица размером N*N, содержащая положительные и отрицательные числа. Напишите код поиска субматрицы с максимально возможной суммой.
Существует множество решений этой задачи. Мы начнем с метода грубой силы, а затем займемся оптимизацией.
Подобно другим задачам, связанным с поиском максимума, у этой задачи есть простое решение. Достаточно проверить все субматрицы, вычислить сумму каждой и найти самую большую.
Чтобы проверить все субматрицы и избежать повторов. Придется пройтись по всем упорядоченным парам строк и затем по всем упорядоченным парам столбцов.
Это решение потребует O(N6) времени, так как необходимо проверить O(N4) матриц, а проверка одной матрицы занимает O(N2) времени.
Обратите внимание, что предыдущее решение работает медленно из-за расчета суммы элементов матрицы — O(N2) — очень медленная операция. Можно ли сократить это время? Да! Мы можем уменьшить время computeSum до O(1).
Посмотрите на следующий прямоугольник:
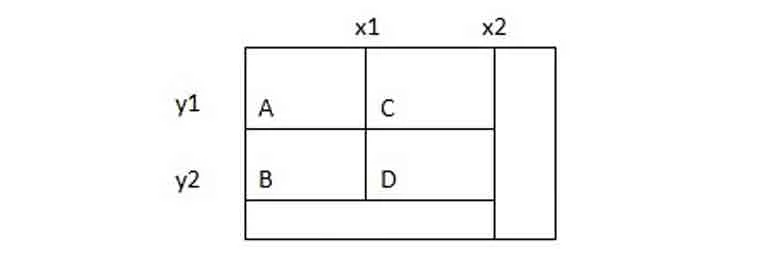
Предположим, что нам известны следующие значения:
ValD = area(point(0, 0) -> point(x2, y2)) ValC = area(point(0, 0) -> point(x2, yl)) ValB = area(point(0, 0) -> point(xl, y2)) ValA = area(point(0, 0) -> point(xl, yl))
Каждое Val* начинается в исходной точке и заканчивается в нижнем правом углу подпрямоугольника. Про эти значения мы знаем следующее:
area(D) = ValD - area(A union С) - area(A union B) + area(A).
Или:
area(D) = ValD - ValB - ValC + ValA
Данная информация позволит эффективно рассчитать эти значения для всех точек матрицы:
Уа1(х, у) = Уа1(х-1, у) + Уа1(у-1, х) - Уа1(х-1, у-1)
Можно заранее рассчитать подобные значения и затем найти максимальную субматрицу. Следующий код реализует данный алгоритм.
int getMaxMatrix(int[][] original) {
int maxArea = Integer.MIN_VALUE; // Важно! Max может быть < 0
int rowCount = original.length;
int columnCount = original[0].length;
int[][] matrix = precomputeMatrix(original);
for (int rowl = 0; rowl < rowCount; rowl++) {
for (int row2 = rowl; row2 < rowCount; row2++) {
for (int coli = 0; coli < columnCount; coll++) {
for (int col2 = coli; col2 < columnCount; col2++) {
maxArea = Math.max(maxArea, computeSum(matrix, rowl, row2, coli, col2));
}
}
}
}
return maxArea
}
int[][] precomputeMatrix(int[][] matrix) {
int[][] sumMatrix = new int[matrix.length][matrix[0].length];
for (int i = 0; i < matrix.length; i++) {
for (int j = 0; j < matrix.length; j++) {
if (i == 0 && j == 0) { // первая ячейка
sumMatrix[i][j] = matrix[i][j];
} else if (j == 0) { // ячейка в первой колонке
sumMatrix[i][j] = sumMatrix[i - l][j] + matrix[i][j];
} else if (i == 0) { // ячейка в первом ряду
sumMatrix[i][j] = sumMatrix[i][j-1] + matrix[i][j];
} else {
sumMatrix[i][j] = sumMatrix[i-l][j] +
sumMatrix[i][j-1] - sumMatrix[i-l][j-1] +
matrix[i][j];
}
}
}
return sumMatrix;
}
int computeSum(int[][] sumMatrix, int il, int i2, int jl, int j2) {
if (il == 0 && jl == 0) { // начинаем с ряда 0, колонки 0
return sumMatrix[i2][j2];
} else if (il == 0) { // начинаем с ряда 0
return sumMatrix[i2][j2] - sumMatrix[i2][jl - 1];
} else if (jl == 0) { // начинаем с колонки 0
return sumMatrix[i2][j2] - sumMatrix[il-l][j2];
} else {
return sumMatrix[i2][j2] - sumMatrix[i2][jl-1] - sumMatrix[il-l][j2] + sumMatrix[il-1][jl-1];
}
}
Невероятно, но существует еще более оптимальное решение. Если у нас есть R строк и С столбцов, то задачу можно решить за О(R2C) времени.
Вспомните решение задачи про поиск максимального субмассива: для массива целых чисел (integer) найдите субмассив с максимальной суммой. Такой максимальный субмассив можно найти за О(N) времени. Давайте используем это решение для нашей задачи.
Каждую субматрицу можно представить в виде последовательности строк и последовательности столбцов. Можно пройтись по строкам и найти столбцы, дающие максимальную сумму.
Код будет таким:
maxSum = 0 foreach rowStart in rows foreach rowEnd in rows /* У нас есть количество возможных субматриц с границами * rowStart и rowEnd * Найдите границы colStart и colEnd, дающие * максимальную сумму. */ maxSum = max(runningMaxSum, maxSum) return maxSum
Теперь остается вопрос: как найти «лучшие» colStart и colEnd?
Рассмотрим субматрицу:
Нам необходимо найти colStart и colEnd, которые дают нам максимально возможную сумму всех субматриц rowStart сверху и rowEnd снизу. Можно вычислить сумму каждого столбца и использовать функцию maximumSubArray, которая обсуждалась в начале решения этой задачи.
В предыдущем примере максимальный субмасив охватывал пространство с первой по четвертую колонку. Это означает, что максимальная субматрица должна простираться от (rowStart, первый столбец) до (rowEnd, четвертый столбец).
Теперь мы можем записать следующий псевдокод:
maxSum = 0 foreach rowStart in rows foreach rowEnd in rows foreach col in columns partialSum[col] = sum of matrix[rowStart, col] through matrix[rowEnd, col] runningMaxSum = maxSubArray(partialSum) maxSum = max(runningMaxSum, maxSum) return maxSum
Вычисление суммы в строках 5 и 6 занимает R*C времени (так как требует итерации от rowStart до rowEnd), что дает общее время выполнения О(R3C).
В строках 5 и 6 мы добавляли a[0]…a[i] с нуля, даже если на предыдущей итерации внешнего цикла добавились a[0]…a[i-1]. Давайте избавимся от двойной работы.
maxSum = 0 foreach rowStart in rows clear array partialSum foreach rowEnd in rows foreach col in columns partialSum[col] += matrix[rowEnd, col] runningMaxSum = maxSubArray(partialSum) maxSum = max(runningMaxSum, maxSum) return maxSum
Полная версия кода выглядит так:
public void clearArray(int[] array) {
for (int i = 0; i < array.length; i++) {
array[i] = 0;
}
}
public static int maxSubMatrix(int[][] matrix) {
int rowCount = matrix.length;
int colCount = matrix[0].length;
int[] partialSum = new int[colCount];
int maxSum = 0; // Макс, сумма = 0 (матрица пуста)
for (int rowStart = 0; rowStart < rowCount; rowStart++) {
clearArray(partialSum);
for (int rowEnd = rowStart; rowEnd < rowCount; rowEnd++) {
for (int i = 0; i < colCount; i++) {
partialSum[i] += matrix[rowEnd][i]j
}
int tempMaxSum = maxSubArray(partialSum, colCount);
/* Если вы хотите отслеживать координаты, добавьте
* код здесь, чтобы сделать это. */
maxSum = Math.max(maxSum, tempMaxSum);
}
}
return maxSum;
}
public static int maxSubArray(int array[], int N) {
int maxSum = 0;
int runningSum = 0;
for (int i = 0; i < N; i++) {
runningSum += array[i];
maxSum = Math.max(maxSum, runningSum);
/* Если runningSum < 0, нет смысла продолжать ряд
* Сброс. */
if (runningSum < 0) {
runningSum = 0;
}
}
return maxSum;
}
Это чрезвычайно сложная задача. Вряд ли вы сможете решить подобную задачу на собеседовании без подсказки интервьюера.
86. Сложная задача, требующая умения придумывать алгоритмы.
По условию требуется разработать алгоритм, позволяющий найти k-e число из упорядоченного числового ряда, в разложении элементов которого на простые множители присутствуют только 3, 5 и 7.
Решение с примерами кода на Java есть у нас на сайте.
По условию задачи любое число этого ряда должно представлять собой произведение 3a · 5b · 7c.
Давайте посмотрим на список чисел, удовлетворяющих нашим требованиям:

Поскольку 3a-1 · 5b · 7c < 3a · 5b · 7c, то число 3a-1 · 5b · 7c должно попасть в список, как и все перечисленные далее числа:
Другой способ — представить каждое число в следующем виде:
Мы знаем, что Ak можно записать как (3, 5 или 7) · (некоторое значение из { A1, …, Ak-1}). Мы также знаем, что Ak является следующим числом в данном ряду. Поэтому Ak должно быть наименьшим «новым» числом, которое может быть получено умножением каждого значения в списке на 3, 5 или 7.
Как найти Ak? Мы можем умножить каждое число в списке на 3, 5 или 7 и найти наименьший новый результат. Но такое решение потребует O(k2) времени. Неплохо, но можно сделать и лучше.
Вместо умножения всех элементов списка на 3, 5 или 7 можно рассматривать каждое предыдущее значение как основу для расчета трёх последующих значений. Таким образом, каждое число Ai может использоваться для формирования следующих форм:
Эта идея поможет нам спланировать все заранее. Каждый раз, когда мы добавляем в список число Ai, мы держим значения 3Ai, 5Ai и 7Ai в «резервном» списке. Чтобы получить Ai+1, достаточно будет найти наименьшее значение во временном списке.
Наш код может быть таким:
public static int removeMin(Queue<integer> q) {
int min = q.peek();
for(Integer v : q) {
if (min >v){
min=v;
}
}
while (q.contains(min)) {
q.remove(min);
}
return min;
}
public static void addProducts(Queue<Integer> q, int v) {
q.add(v * 3);
q.add(v * 5);
q.add(v * 7);
}
public static int getKthMagicNumber(int k) {
if (k < 0) return 0;
int val = 1;
Queue<Integer> q = new LinkedList<Integer>();
addProducts(q, 1);
for(int i = 0; i < k; i++) {
val = removeMin(q);
addProducts(q, val);
}
return val;
}
Данный алгоритм гораздо лучше предыдущего, но все еще не идеален.
Для генерирования нового элемента Ai мы осуществляем поиск по связному списку, где каждый элемент имеет вид:
Давайте уберем избыточные расчеты. Допустим, что наш список имеет вид:
q6 = {7A1, 5A2, 7A2, 7A3, 3A4, 5A4, 7A4, 5A5, 7A5}
Когда мы ищем минимальный элемент в списке, то проверяем сначала 7A1 < min, а затем 7A5 < min. Глупо, не правда ли? Поскольку мы знаем, что A1 < A5, то достаточно выполнить проверку 7A1 < min.
Если бы мы разделили список по постоянным множителям, то должны были бы проверить только первое из произведений на 3, 5 и 7. Все последующие элементы будут больше.
Таким образом, наш список принимает вид:
Чтобы найти минимум, достаточно проверить начало каждой очереди:
Y = min(Q3.head(), Q5.head(), Q7.head())
Как только мы вычислим y, нужно добавить 3y в список Q3, 5y в Q5 и 7y в Q7. Но мы хотим вставлять эти элементы, только если они отсутствуют в других списках.
Как, например, 3y может попасть в какой-нибудь другой список? Допустим, элемент y был получен из Q7, это значит, что y = 7x. Если 7x — наименьшее значение, значит, 3x уже было задействовано. А как мы действовали, когда увидели 3x? Правильно, мы вставили 7 · 3x в Q7. Обратите внимание, что 7 · 3x = 3 · 7x = 3y.
В общем виде: если мы берем элемент из Q7, он будет иметь вид 7 · suffix. Мы знаем, что 3 · suffix и 5 · suffix уже обработаны, и элемент 7 · 3 ·suffix добавлен в Q7. Единственное значение, которое мы еще не встречали — 7 · 7 · suffix, поэтому добавляем его в Q7.
Давайте рассмотрим пример, чтобы разобраться, как работает данный алгоритм. Инициализация:
Q3 = 3 Q5 = 5 Q7 = 7 Удаляем min = 3, вставляем 3*3 в Q3, 5*3 в Q5, 7*3 в Q7 Q3 = 3*3 Q5 = 5, 5*3 Q7 = 7, 7*3 Удаляем min = 5. 3*5 – дубль, значит, мы уже обработали 5*3. Вставляем 5*5 в Q5, 7*5 в Q7 Q3 = 3*3 Q5 = 5*3, 5*5 Q7 = 7, 7*3, 7*5 Удаляем min = 7. 3*7 и 5*7 – дубли, уже обработали 7*3 и 7*5. Вставляем 7*7 в Q7 Q3 = 3*3 Q5 = 5*3, 5*5 Q7 = 7*3, 7*5, 7*7 Удаляем min = 3*3 = 9. Вставляем 3*3*3 в Q3, 3*3*5 в Q5, 3*3*7 в Q7. Q3 = 3*3*3 Q5 = 5*3, 5*5, 5*3*3 Q7 = 7*3, 7*5, 7*7, 7*3*3 Удаляем min = 5*3 =15. 3*(5*3) – дубль, так как уже обработали 5*(3*3). Вставляем 5*5*3 в Q5, 7*5*3 в Q7 Q3 = 3*3*3 Q5 = 5*5, 5*3*3, 5*5*3 Q7 = 7*3, 7*5, 7*7, 7*3*3, 7*5*3 Удаляем min = 7*3 = 21. 3*(7*3) и 5*(7*3) – дубли, уже обработали 7*(3*3) и 7*(5*3). Вставляем 7*7*3 в Q7 Q3 = 3*3*3 Q5 = 5*5, 5*3*3, 5*5*3 Q7 = 7*5, 7*7, 7*3*3, 7*5*3, 7*7*3
Структура нашего алгоритма будет иметь вид:
Следующий код реализует данный алгоритм:
public static int getKthMgicNumber(int k) {
if (k < 0) {
return 0;
}
int val = 0;
Queue<Integer> queue3 = new LinkedList<Integer>();
Queue<Integer> queue5 = new LinkedList<Integer>();
Queue<Integer> queue7 = new LinkedList<Integer>();
queue3.add(1);
/* Итерация от 0 до k */
for (int i = 0; i <= k; i++) {
int v3 = queue3.size() > 0 ? queue3.peek() :
Integer.MAX_VALUE;
int v5 = queue5.size() > 0 ? queue5.peek() :
Integer.MAX_VALUE;
int v7 = queue7.size() > 0 ? queue7.peek() :
Integer.MAX_VALUE;
val = Math.min(v3,Mathmin(v5, v7));
if(val == v3){ // ставим в очередь 3, 5 и 7
queue3.remove();
queue3.add(3 * val);
queue5.add(5 * val);
} else if (val == v5) { // ставим в очередь 5 и 7
queue5.remove();
queue5.add(5 * val);
} else if (val == v7) { // ставим в очередь Q7
queue7.remove();
}
queue7.add(7 * val); // всегда добавляем в очередь Q7
}
return val;
}
Если вам досталась подобная задача, приложите все усилия, чтобы ее решить, потому что это действительно трудное задание. Вы можете начать с решения «в лоб» (спорно, зато не слишком сложно), а затем попытаться оптимизировать его. Или попытайтесь найти шаблон, спрятанный в числах.
Интервьюер поможет, если вы будете испытывать затруднения. Не сдавайтесь! Рассуждайте вслух, задавайте вопросы и объясняйте ход ваших мыслей. Интервьюер наверняка начнет помогать вам.
Помните, никто не ожидает, что вы найдете идеальное решение. Ваши результаты будут сравнивать с результатами других кандидатов. Все будут находиться в одинаковых условиях.
87. Дан список из миллиона слов. Разработайте алгоритм, создающий максимально возможный прямоугольник из букв так, чтобы каждая строка и каждый столбец образовывали слово (при чтении слева направо и сверху вниз). Слова могут выбираться в любом порядке, строки должны быть одинаковой длины, а столбцы — одинаковой высоты.
Условие задачи звучит так: дан список из миллиона слов. Разработайте алгоритм, создающий максимально возможный прямоугольник из букв так, чтобы каждая строка и каждый столбец образовывали слово (при чтении слева направо и сверху вниз). Слова могут выбираться в любом порядке, строки должны быть одинаковой длины, а столбцы — одинаковой высоты.
Большинство задач, использующих словарь, требуют некоторой предварительной обработки. Как можно провести предварительную обработку?
Если мы собираемся создать квадрат из слов, то длина всех строк и высота всех столбцов должны быть одинаковыми. Давайте сгруппируем слова словаря по длине. Назовем эту группу D, где D[i] — список слов длиной i.
Обратите внимание, что мы ищем самый большой прямоугольник. Какой самый большой квадрат можно сформировать? Это (length(longestWord))^2.
int maxRectangle = longestWord * longestWord;
for z = maxRectangle to 1 {
for each pair of numbers (i,j) where i*j = z {
/* пытаемся создать прямоугольник, возвращаемся, если успешно */
}
}
Мы проходим по прямоугольникам от самого большого до самого маленького, таким образом, первый найденный прямоугольник будет самым большим.
Теперь самая сложная часть — makeRectangle(int l, int h). Этот метод пытается создать прямоугольник из слов размером lxh.
Можно, например, пройтись по всем упорядоченным наборам h-слов и затем проверить, содержат ли колонки допустимые слова. Такой метод будет работать, но очень неэффективно.
Предположим, что мы пытаемся создать прямоугольник размером 6×5, и первыми парами строк будут:
В этой точке мы уже знаем, что первый столбец начинается с tqp. Мы знаем (или должны знать), что ни одно из слов в словаре не начинается с tqp. Зачем мы продолжили создавать прямоугольник, если знали, что у нас не получится создать допустимый прямоугольник?
Значит, нужна оптимизация. Можно создать выборку, позволяющую упростить поиск, если будем анализировать подстроки как префиксы слов в словаре. При построчном формировании прямоугольника можно ввести проверку, являются ли столбцы допустимыми префиксами. Если нет, мы сразу прекращаем работу с этим прямоугольником.
Приведенный далее код реализует этот алгоритм. Это длинный и сложный алгоритм, поэтому мы будем анализировать его по частям.
Прежде всего, нам необходима предварительная обработка, позволяющая сгруппировать слова по длине. Мы создаем массив выборок (по одной на каждую длину слова), но пока не будем их использовать.
WordGroup[] groupList = WordGroup.createWordGroups(list); int maxWordLength = groupList.length; Trie trieList[] = new Trie[maxWordLength];
Метод maxRectangle — главная часть нашего кода. Он начинает работу с самого большого возможного прямоугольника (maxWordLength2) и пытается построить прямоугольник этого размера. Если это невозможно, он пытается создать прямоугольник меньшего размера. Первый прямоугольник, который удастся построить, будет самым большим.
Rectangle maxRectangleO {
int maxSize = maxWordLength * maxWordLength;
for (int z = maxSize; z > 0; z–) { // начинаем с наибольшей области
for (int i = 1; i <= maxWordLength; i ++ ) {
if (z % i == 0) {
int j = z / i;
if (j <= maxWordLength) {
/* Создаем прямоугольник длиной i и высотой j.
* Заметьте, что i * j = z. */
Rectangle rectangle = makeRectangle(i, j);
if (rectangle != null) {
return rectangle;
}
}
}
}
}
return null;
}
maxRectangle вызывает метод makeRectangle и пытается построить прямоугольник указанных размеров.
Rectangle makeRectangle(int length, int height) {
if (groupList[length-l] == null ||
groupList[height-l] == null) {
return null;
}
/* Создает выборку для длины слова, если мы ее еще не создали */
if (trieList[height-1] == null) {
LinkedList words = groupListfheight-1) .getWordsQ;
trieList[height-1] = new Trie(words);
}
return makePartialRectangle(length, height,
new Rectangle(length));
}
Метод makePartialRectangle — наш основной метод, производящий всю работу. Ему передаются окончательные значения длины и высоты, а также частично сформированный прямоугольник. Если нам известно окончательное значение высоты прямоугольника, то мы должны проверить, что колонки содержат допустимые слова, и выйти.
В противоположном случае мы проверяем, сформированы ли столбцы из допустимых префиксов. Если нет, работа останавливается, поскольку нет смысла продолжать строить этот прямоугольник.
Если все нормально и все колонки содержат правильные префиксы, мы перебираем все слова нужной длины, добавляем каждое из них к прямоугольнику и пытаемся построить новый прямоугольник (текущий прямоугольник с новым добавленным словом).
Rectangle makePantialRectangle(int 1, int h, Rectangle rectangle) {
if (rectangle.height == h) { // Проверяем, полный ли прямоугольник
if (rectangle.isComplete(l, h, groupList[h-1])) {
return rectangle;
} else {
return null;
}
}
/* Сравниваем колонки с выборкой, чтобы увидеть */
/* потенциально допустимый прямоугольник */
if (!rectangle.isPartialOK(l, trielist[h-1])) {
return null;
}
/* Проходимся по всем словам нужной длины. Добавляем каждое в
* текущий частичный прямоугольник и пытаемся построить прямоугольник
* рекурсивно. */
for (int i=0; i<groupList[l-l].length(); i++) {
/* Создаем новый прямоугольник, добавляя новое слово в текущий */
Rectangle orgPlus = rectangle.append(groupList[l-l].getWord(i));
/* Пытаемся построить прямоугольник с этим новым, */
/* частичным прямоугольником */
Rectangle rect = makePartialRectangle(l, h, orgPlus);
if (rect != null) {
return rect;
}
}
return null;
}
Класс Rectangle представляет собой частотно или полностью сформированный прямоугольник из слов. Метод isPartialOk вызывается для проверки допустимости прямоугольника. Метод isComplete выполняет аналогичную функцию, но дополнительно проверяет, чтобы колонки содержали полное слово.
public class Rectangle {
public int height, length;
public char [][] matrix;
/* Создаем "пустой" прямоугольник. Длина - фиксированная, но высота
* может изменяться при добавлении слов */
public Rectangle(int 1) {
height = 0;
length = 1;
}
/* Создаем прямоугольный массив слов
* определенной длины и высоты
* (Предполагается, что длина и высота определены
* как аргументы и не противоречат
* размерам массива) */
public Rectangle(int length, int height, char[][] letters) {
this.height = letters.length;
this.length = letters[0].length;
matrix = letters;
}
public char getLetter (int i, int j) { return matrix[i][j]; }
public String getColumn(int i) { ... }
/* Проверяем, все ли колонки допустимы. Все строки будут
* допустимы, так как они были добавлены непосредственно из словаря */
public boolean isComplete(int 1, int h, WordGroup groupList) {
if (height == h) {
/* Проверяем, является ли каждая колонка словарным словом*/
for (int i = 0; i < 1; i++) {
String col = getColumn(i);
if (!groupList.containsWord(col)) {
return false;
}
}
return true;
}
return false;
}
public boolean isPartialOK(int 1, Trie trie) {
if (height == 0) return true;
for (int i = 0; i < 1; i++ ) {
String col = getColumn(i);
if (!trie.contains(col)) {
return false;
}
}
return true;
}
/* Создаем новый Rectangle: берем строки текущего
* прямоугольника и добавляем s. */
public Rectangle append(String s) { ... }
}
Класс WordGroup — контейнер, содержащий слова определенной длины. Для упрощения поиска мы будем хранить слова в хэш-таблице так же, как в ArrayList.
Списки в WordGroup создаются с помощью статического метода createWordGroups.
public class WordGroup {
private Hashtable<String, Boolean> lookup =
new Hashtable<String, Boolean>();
private ArrayList group = new ArrayList();
public boolean containsWord(String s) {
return lookup.containsKey(s));
}
public void addWord (String s) {
group.add(s);
lookup.put(s, true);
}
public int lengthQ { return group.size(); }
public String getWord(int i) { return group.get(i); }
public ArrayList getWords() { return group; }
public static WordGroup[] createWordGroups(String[] list) {
WordGroupf] groupList;
int maxWordLength = 0;
/* Находим длину самого длинного слова */
for (int i = 0; i < list.length; i++) { if (list[i].length() > maxWordLength) {
maxWordLength = list[i].length();
}
}
/* Группируем слова в словаре в списки одинаковой длины
* length.groupList[i] будет содержать список слов
* длиной (i+1). */
groupList = new WordGroup[maxWordLength];
for (int i = 0; i < list.length; i++) {
/* Мы делаем wordLength - 1 вместо просто wordLength, так как
* мы используем wordLength и нет слов длиной 0 */
int wordLength = list[i].length() - 1;
if (groupList[wordLength] == null) {
groupList[wordLength] = new WordGroupO;
}
groupList[wordLength].addWord(list[i]);
}
return groupList;
}
}
Полный код для этой задачи, включая коды методов Trie и TrieNode, вы можете скачать с сайта автора книги. Не забудьте, что в подобных сложных задачах лучше использовать псевдокод. На написание полного кода вам просто не хватит времени.
88. Дан массив с числами типа Integer. Вам нужно написать функцию, которая на входе получит исходный массив, а на выходе вернет массив, в котором каждое значение получено путем произведения всех значений исходного массива с отличным от текущего индексом.
Для ясности приведем пример. Допустим, исходный массив имеет вид:
[1, 7, 3, 4]
Тогда функция должна вернуть:
[84, 12, 28, 21]
Расчет значений происходит следующим образом:
[7*3*4, 1*3*4, 1*7*4, 1*7*3]
Дополнительные условия:
Нельзя использовать деление.
Функция должна быть с наименьшими затратами памяти и времени выполнения.
Для того, чтобы вычислить возвращаемый массив без использования деления, мы дважды пройдемся по массиву. Проходя первый раз, мы будем получать произведение всех значений до текущего индекса и сохранять это произведение в отдельном массиве poducts_of_all_ints_except_at_index. В этом же массиве будем сохранять результат произведения всех значений после текущего индекса, но уже идя в обратном порядке. Ответ же мы получим, перемножив значения перед и после индекса во время обратного прохода по массиву.
Код решения (на Python):
def get_products_of_all_ints_except_at_index(int_list):
# создаем дополнительный массив с таким же размером, что и исходный.
products_of_all_ints_except_at_index = [None] * len(int_list)
# Находим произведение всех значений до текущего.
# Результат помещаем в новый массив.
product_so_far = 1
i = 0
while i < len(int_list):
products_of_all_ints_except_at_index[i] = product_so_far
product_so_far *= int_list[i]
i += 1
# Находим произведение всех значений после текущего,
# при этом двигаясь по массиву в обратную сторону.
# Параллельно вычисляем значение текущей ячейки.
product_so_far = 1
i = len(int_list) - 1
while i >= 0:
products_of_all_ints_except_at_index[i] *= product_so_far
product_so_far *= int_list[i]
i -= 1
return products_of_all_ints_except_at_index
Сложность полученного алгоритма — O(n) по памяти и O(n) по времени. Свои варианты предлагайте в комментариях.
89. Задача на умение рассуждать. Конкретный ответ не важен, важно показать как вы мыслите. Представьте, что вам необходимо добраться из точки A в точку B, но вы не знаете, как. Как вы будете действовать?
Ответ студента, обучающегося по программе MBA: «Я взял бы свой сотовый и ввел точки А и В в Google Maps. Если точки В на этой карте нет, я вызвал бы такси, доехал до нее, а потом отдал бы счет в бухгалтерию. Задавайте следующий вопрос».
Доктор со степенью в компьютерных науках ответил бы так: «О, я знаю. Вы спрашиваете о задаче отыскания сети…»
Программист, скорее всего, начнет обсуждать относительные достоинства конкретных поисковых алгоритмов. Хотя эти алгоритмы были разработаны для анализа компьютерной памяти и интернета, они в равной степени подходят для ориентации при покупках в торговом центре, в садовом лабиринте или в причудливо расположенных деревнях Умбрии. Далее я привожу ответ на основе здравого смысла, и он, в конечном счете, не так далек от ответа ученого-компьютерщика.
Давайте изменим формулировку вопроса. Вы находитесь в точке A и хотите отыскать точку B, но никакого руководства для этого у вас нет. Вам придется изучить дороги и тропинки, ведущие из A. Вы отыщете точку B только тогда, когда в нее попадете (если это вообще случится). Но вы можете в ней и не оказаться. Точка B может находиться вне сети дорог и поэтому быть недоступной.
Вам следует начать с ряда важных вопросов, которые надо задать интервьюеру.
Любят, любят интервьюеры такие вопросы! Несомненно, человек, который их задает, достаточно умный, чтобы уточнить детали. Но при ответе на первый ваш вопрос они сообщат, что вы не сможете получить надежные рекомендации, связанные с направлением поиска.
Второй вопрос важен потому, что умные инженеры стараются не тратить понапрасну время и усилия, если они все равно не приведут к нужному результату. Вы ведь не хотите обыскать всю планету, и, в конце концов, сделать вывод, что попасть в B из A нельзя.
Последний вопрос, третий, немного запутывает. Поэтому разберем его. Что, если вы потерялись в лабиринте на кукурузном поле с двумя хныкающими малышами? Назовем это место, где вы сейчас находитесь, точкой A. Вы хотите отыскать выход — точку B. Вас, в первую очередь, интересует то, как можно выбраться из этого чертова лабиринта.
Вы хотите получить процедуру поиска, которая отыщет точку B как можно быстрее. Однако в этом лабиринте почти всегда есть повороты, вводящие в заблуждение, и путь, который вы проделаете до выхода (от A до B), не обязательно будет самым коротким. Впрочем, в вашей ситуации это не самое главное.
А вот вам альтернативный пример: вы хотите добираться из дома (A) на работу (B) общественным транспортом. Вы подбираете для себя маршрут, чтобы потом ездить каждый рабочий день. Поэтому вы не просто ищете путь до B, но и хотите, чтобы дорога от A до B была самой короткой.
В любом поиске приходится в той или иной мере прибегать к пробам и ошибкам. Какую-то роль в этом процессе играют, конечно, ваши знания или интуиция. Может быть, вы заранее убеждены, что в B можно попасть при помощи карт, догадок, встречных местных жителей, мудрости, оставшейся у нас со времен трапперов французской Канады, или дорожных знаков, указывающих, что до точки B осталось 17 миль. Однако в любом случае процедура поиска должна быть как-то упорядочена независимо от того, какой информацией вы располагаете (и учитывая тот факт, что эта информация необязательно является надежной). Вы начнете с изучения маршрута, который, как вы считаете, является, самым коротким путем до B. По мере вашего продвижения составляйте карту, чтобы в случае чего вы могли вернуться назад и попробовать другие пути.
До сих пор все рекомендации бесспорны. Чтобы произвести впечатление на интервьюера, вам необходимо заявить что-то не столь очевидное. Скажем, попробуйте следующее: «Фундаментальный философский вопрос при поиске места назначения — когда мне следует повернуть назад?»
Бывают времена, когда вы чувствуете, что заблудились, то есть у вас появилась мысль, что вы отклонились от пути, ведущего от А к В. Вернетесь ли вы туда, где были до этого, до того, как сбились? Или вы постараетесь отыскать прямой путь до В от того места, где вы сейчас находитесь?
Вполне вероятно, вам нужно было принять такое решение во время вашей последней дальней поездки. Если шутки о мужчинах-водителях правильны, мужчины очень неохотно возвращаются назад или спрашивают других о том, куда надо ехать. Предположим, дружески настроенный незнакомец уверяет Эшли и Бена, что точка В находится дальше, «прямо вон по той дороге», и заявляет, что «вы не сможете ее пропустить». Они едут полчаса, готовые за каждым поворотом увидеть В. Но этого так и не происходит. «Мы, очевидно, не туда едем, — роняет Эшли. — Давай вернемся к тому месту, где мы были до этого, прежде чем отправились по этой дороге».
«Да ну, это бессмысленно, — возражает Бен. — Мы уже столько проехали, скорее всего мы теперь находимся ближе к В, чем были до этого. Впереди должен быть какой-то указатель».
Стратегия Бена напоминает вариант, который ученые-компьютерщики называют первым лучшим алгоритмом. Всякий раз, когда вы добираетесь до развилки на дороге, вы следуете тем путем, который вам кажется самой короткой дорогой к В, и делаете это основываясь на том, что вы знаете. Если вам повезет, это знание окажется на 100% точным, и тогда Бен доберется до пункта В кратчайшим путем.
Стратегия Эшли скорее напоминает поисковый алгоритм А* (произносится А звездочка), описанный учеными-компьютерщиками Питером Хартом, Нилсом Нилссоном и Бертраном Рафаэлем в 1968 году. Его суть (в самом первом приближении) следующая: вам следует стремиться к выбору самой близкой к самой короткой дороге из А в В. Вы, вероятно, удивитесь, а чем этот вариант, собственно говоря, отличается от стратегии Бена? Ничем, если вы на правильном пути. А вот если вы уклонились… Принимая решение, что делать дальше, Бен ориентируется на единственный аргумент — свою догадку о том, насколько далеко В лежит от того места, где Бен сейчас находится. Бен всегда пытается двигаться в сторону В. Эшли же опирается на два факта: свою оценку расстояния до В и свое знание расстояния по дороге от А до того места, где он сейчас находится. Цель Эшли минимизировать оба числа или, что будет точнее, их сумму. Эшли пытается изучить точки, которые с максимальной вероятностью лежат на кратчайшем пути между А и В.
Кто прав, Бен или Эшли? Процедура поиска Эшли лучше, когда приходится иметь дело с поворотами, заводящими не туда, куда нужно. Сущность ее подхода показана на приведенной ниже диаграмме. Начав из А, путешественник добирается до развилки дорог и должен выбрать, налево или направо ему податься. Если Бен выберет левый путь — ошибочный! — ему придется отправиться длинным кружным путем. После многих блужданий путь приведет его ближе к В.
Если Эшли также повернет неправильно, в данном случае налево, она через какое-то время поймет, что проделала уже слишком длинный путь от A, а В все еще не видать. Это для нее знак, что она, скорее всего, выбрала не самый короткий путь. Тогда Эшли вернется к развилке и попробует другой путь. И есть вероятность, она доберется до В быстрее, чем Бен.
В целом можно ожидать, что одной развилкой дело не обойдется, и поэтому подобные решения придется принимать частенько. И каждый раз надо выбирать тот или иной компромиссный вариант: метод поиска с оптимальным числом возвратов назад обычно оказывается лучше варианта, когда к такому возврату прибегают очень редко.
Вернемся на интервью. Предпочтение стоит отдать поиску в виде А*, поскольку в формулировке вопроса утверждается, что вы не знаете, можете ли вы вообще добраться до места. Если пути, позволяющего добраться до В нет, Бен будет бродить целую вечность. Эшли исследует системно все пути, ведущие из пункта А, поскольку она минимизирует расстояние, пройденное от А. Затем она составит карту территории, которая поможет ей определить, что возможности добраться из А в В нет. Это позволит ей не тратить напрасно ресурсы.
У варианта поиска А* есть одно особое преимущество, которое проявляется тогда, когда нужно отыскать самый короткий из всех путей. По этой причине он используется в дорожных приложениях и в видеоиграх, когда персонажам надо пробраться через виртуальные миры. Поиск по методу А* также обладает и психологическим преимуществом. Нам свойственно ошибаться, и при этом нам свойственно искать оправдания. Очень соблазнительно тратить ресурсы на исследование ложного пути или реализацию плохо составленного бизнес-плана, продолжение отношений с неподходящим романтическим партнером, защиту ошибочной идеи, убеждая себя, что успех ожидает нас уже за следующим углом. А вот поиск в варианте А* позволит отказаться от бессмысленного занятия и перейти к чему-то новому. И это применимо всюду. Ведь важно не только не сдаться слишком быстро, но и вовремя признать себя побежденным.
Подведем итоги. Пытаясь добраться из точки А в точку В, старайтесь как можно ближе держаться дороги, которая, как вы полагаете сейчас, является самой короткой (поиск А*), и не пытайтесь просто отыскать пункт В.
90. Представьте, что вам дали задание разработать план эвакуации большого города (в классическом варианте — Сан-Франциско). С чего вы начнете?
Такой вопрос на самом деле не лишен практического смысла. В 2006 году в Карте отчета об эвакуации в чрезвычайной ситуации, составленной Союзом пользователей американских автодорог, Канзасу была присвоена степень А (наивысшая). Новый Орлеан, по которому ударил ураган Катрина, получил D. Оценка Сан-Франциско? F. В числе отстающих также оказались Нью-Йорк, Чикаго и Лос-Анджелес.
Низкие оценки вызваны большими размерами этих городов, их сложной географией и зависимостью от общественного транспорта. В такой организации, как Google, которая очень внимательно относится к вопросам окружающей среды, некоторые интервьюеры почти инстинктивно готовы перейти к обсуждению сети транзитного общественного транспорта в Сан-Франциско. Большинство маршрутов общественных видов транспорта проходят по территории города. BART, Скоростная система зоны Залива, может доставить людей до Окленда. Но достаточно ли этого? Или мы будем эвакуировать и население Окленда? AMTRAK в Сан-Франциско даже не останавливается. Если говорить о ближайшем будущем, здесь нет даже плана «зеленой эвакуации». Экстренный вывоз людей из города означает появление на общественных шоссе большого числа обычных двигателей внутреннего сгорания.
Вот несколько пунктов из плана эвакуации, которые вы могли бы указать при своем ответе.
91. Задача, которую предлагали на собеседованиях в Apple: у вас есть массив с целыми числами, в том числе и отрицательными, вам нужно найти самое большое произведение 3 чисел из этого массива.
Например: у вас есть массив list_of_ints, содержащий числа -10, -10, 1, 3, 2. Функция, которая обрабатывает этот массив, должна вернуть 300, так как -10 * -10 * 3 = 300. Задание нужно выполнить максимально эффективно, не забывая учесть отрицательные числа.
Методов решения много, но не так просто добиться O(n) времени выполнения и O(1) затрат памяти. Для эффективного решения задачи мы создадим и будем наблюдать за состоянием следующих переменных:
Когда мы пройдемся по массиву до конца, в highest_product_of_three будет содержаться наш ответ, а остальные переменные мы используем как временный буфер. highest_product_of_2 и lowest_product_of_2 будут содержать наибольшее произведение из двух и наименьшее произведение из двух соответственно, а проходя по массиву, мы будем проверять произведение текущего числа current с этими переменными (отрицательный current с lowest_product_of_2 и положительный с highest_product_of_2). highest и lowest нам нужны для запоминания минимального и максимального чисел в массиве.
Код решения на Python:
def highest_product_of_3(list_of_ints):
# Проверим, чтобы в массиве было 3 и больше чисел.
if len(list_of_ints) < 3:
raise Exception('Less than 3 items!')
# Мы начнем с 3-его элемента массива (с индекса 2),
# так как первые 2 элемента уже сразу пойдут
# в highest_product_of_2 и lowest_product_of_2.
highest = max(list_of_ints[0], list_of_ints[1])
lowest = min(list_of_ints[0], list_of_ints[1])
highest_product_of_2 = list_of_ints[0] * list_of_ints[1]
lowest_product_of_2 = list_of_ints[0] * list_of_ints[1]
# Также вычислим highest_product_of_three из первых 3-х элементов.
highest_product_of_three = list_of_ints[0] * list_of_ints[1] * list_of_ints[2]
# Начинаем проход по массиву с индекса 2.
for current in list_of_ints[2:]:
# проверяем возможность увеличить highest_product_of_three
# или оставляем его как есть.
highest_product_of_three = max(
highest_product_of_three,
current * highest_product_of_2,
current * lowest_product_of_2)
# То же самое проверим и на максимальном произведении из двух.
highest_product_of_2 = max(
highest_product_of_2,
current * highest,
current * lowest)
# И на минимальном произведении из двух.
lowest_product_of_2 = min(
lowest_product_of_2,
current * highest,
current * lowest)
# Появилось ли новое максимальное число?
highest = max(highest, current)
# Появилось ли новое минимальное число?
lowest = min(lowest, current)
return highest_product_of_three
Сложность алгоритма — O(n) по времени выполнения и O(1) по памяти.
92. Представьте страну, где все родители хотят иметь мальчика. Каждая семья продолжает рожать детей до тех пор, пока у них не появляется мальчик, а затем останавливается. Каково соотношение мальчиков и девочек в этой стране?
Игнорируйте ситуации, когда рождаются двойняшки, тройняшки и так далее, пары, не имеющие детей, и пары, умершие до того, как у них появится мальчик.
Как обычно, предлагаем порассуждать над решением в комментариях. Проверить свой ответ можно на сайте по прикреплённой ссылке, там мы даём наш вариант решения.
Прежде всего, надо понять, что в каждой семье в этой стране, если родители хотят завести ребенка, есть или будет точно один мальчик. Почему? Потому, что каждая пара рожает детей до тех пор, пока у нее не появляется мальчик, а затем прекращает увеличивать численность своей семьи. Если говорить об исключении из рассмотрения рождения двойняшек, то здесь «мальчик» означает только одного мальчика. Семья становится полной, когда в ней появляется мальчик. Поэтому понятно: сколько полных семей, столько и мальчиков.
Однако в любой семье может быть любое количество девочек. Хороший способ для продолжения анализа — провести воображаемую перепись числа девочек. Представьте, что вы пригласили всех матерей в одно гигантское помещение и при помощи специальной системы общения с такой огромной аудиторией говорите: «Пусть каждая мать, у которой первый ребенок девочка, поднимет руку».
Естественно, это сделает половина женщин. Если матерей N, то руку поднимут N/2 женщин, и это число показывает, сколько девочек родились первыми. Отметьте на воображаемой доске это количество — N/2.
Затем скажите: «Пусть каждая мать, у которой второй ребенок девочка, поднимет или будет продолжать держать руку».
Половина поднятых рук опустится, и никаких новых рук не поднимется. (У матерей, которые не подняли руку после первой просьбы, потому что их первый ребенок был мальчик, в семье всего один ребенок.) Это оставляет N/4 поднятых рук, из чего следует, что N/4 родившихся вторыми детей были девочками. Запишем эту цифру также на воображаемой доске.
«Пусть каждая мать, у кого третий ребенок девочка, поднимет руку или продолжит держать ее поднятой». Вы уже поняли рассматриваемый здесь подход. Продолжайте этот процесс до тех пор, пока поднятых рук вообще не останется. С каждой такой просьбой число рук снижается вдвое. Это дает известный числовой ряд:
(1/2 + 1/4 +1/8 + 1/16 + 1/32 + ... ) х N
Сумма бесконечной серии таких чисел равна 1 (х N). Из этого следует, что число девочек равно числу семей (N) и равно числу мальчиков (или очень близко к этому). Поэтому интересующее нас соотношение мальчиков и девочек составляет 1 к 1. В итоге соотношение будет вообще равным.
Задачи на прикидку, то есть подразумевающие приближенное решение — популярный класс задач, которые предлагают на собеседованиях в IT компании. Предлагаем вам несколько таких задач, а также рассказ об общих методах их решения и конкретные советы для собеседований.
Для решения некоторых задач требуются вычисления высочайшей точности. Однако множество других задач допускает приближенное решение. Физики гордятся тем, что могут быстро ответить на вопросы, требующие ответа «с точностью до порядка», делая приближенные оценки, основанные на здравом смысле. Задачи такого рода обычно называют задачами Ферми — по имени великого физика Энрико Ферми, который обладал величайшим искусством не только ставить подобные задачи, но и быстро и изящно их решать.
Задачи Ферми являются весьма действенным способом тренировки реальной применимости знаний человека на практике, а также способности быстро находить способы решения любой жизненной задачи. Современное образование часто предлагает знания, имеющие общий или абстрактный характер. Студенты и школьники часто способны решать сложные типовые задачи, совершая множество операций, а когда речь заходит о том, чтобы решить элементарную, но нестандартную задачу, они впадают в ступор.
Так как часто ответ задач Ферми представляет сомнительный практический интерес, главный акцент делается именно на метод решения. Поэтому задачи Ферми нашли свое применение на различных собеседованиях в крупные компании, конкурсах, интеллектуальных играх, олимпиадах по физике или по информатике. Суть использования задач сводится к тому, чтобы увидеть способность человека к поиску нестандартных решений.
Итак, рассмотрим несколько таких задач.
93. Сколько флаконов шампуня производится в мире за год?
Люди из богатых стран используют несколько флаконов шампуня. Многие жители развивающихся стран не могут себе позволить такую роскошь, как шампунь. Вы можете вполне обоснованно предположить, что в среднем там в год тратится одна бутылочка на человека (если только вы не проходите собеседование в Procter and Gamble, то интервьюер и сам не знает точного ответа). При этих допущениях ответ будет таким: за год производится столько бутылочек шампуня, сколько людей в мире, то есть 6 миллиардов.
Удобная подсказка: при оценке потребления популярных потребительских продуктов трудно сильно промахнуться. В своих рассуждениях исходите из того количества, которое вы потребляете сами, а затем вносите требуемые корректировки. Ваша итоговая оценка не будет сильно отличаться от истинного значения, и именно это от вас и хотят услышать.
94. Сколько насечек на ребре четвертака — монеты в 25 центов?
Диаметр четвертака около одного дюйма (2,54 см). Длина его окружности составляет π (3,14159…), умноженное на диаметр. Для простоты будем считать, что она равна 3 дюймам. Оставшаяся неясная часть для расчетов — количество насечек, приходящееся на один дюйм. Давайте оценим их число. Их больше 10 и, вероятно, меньше 100. Возьмем в качестве возможного варианта 50 и умножим это число на 3. Тогда ответ составит 150 насечек. Фактическое число насечек на американском четвертаке — 119, и их вполне обоснованно иногда называют поры. Они первоначально наносились на золотые монеты, чтобы мошенника не обрезали драгоценный металл с краев монеты. Так вот почему этот вопрос задают претендентам в Deloitte, аудиторский компании, входящей в «большую четверку» ведущих аудиторских организаций мира!
95. Сколько будет 2 в 64 степени?
Приведём один из вариантов возможных рассуждений. Любой инженер знает, что 210 = 1024. Будем считать, что это приблизительно 1000. Умножим 210 на себя шесть раз и получим 260. Это около 1000 в шестой степени или 1018, также известное как квинтиллион. Осталось только умножить его на 24 (16), чтобы получить искомое 264. Таким образом, очень приблизительный, но быстрый ответ будет 16 квинтиллионов.
На самом деле, чуть больше, т.к. 1024 на 2,4% больше 1000. Мы используем это приближение 6 раз, и поэтому ответ должен быть на более, чем 12% больше. Это добавляет еще 2 квинтиллиона. Поэтому более точно будет 18 квинтиллионов.
Точное значение: 18 446 744 073 709 551 616
Есть еще один быстрый хак. Многие знают, что максимальное число 32-битного unsigned int — это что-то около 4 миллиардов т.е. 232 ≈ 4х109. Осталось только умножить это само на себя и получить около 16—17 квинтиллионов.
96. Сколько туалетной бумаги потребуется, чтобы покрыть ею весь штат?
Площадь куска туалетной бумаги приблизительно равна 4 на 4 дюйма (около 10 на 10 см). Девять кусочков, положенные в виде квадрата 3 на 3, составляют квадратный фут. Чтобы облегчить расчеты, будем считать, что 10 листочков составляют квадратный фут. Сколько их в рулоне туалетной бумаги? Может быть, там 300 отдельных листочков? Тогда в рулоне около 30 квадратных футов. Возможно, вы знаете, что в миле 5280 футов. Округлите эту цифру. Пусть она будет равна 5 тысячам футов. Поэтому квадратная миля составляет 5 тысяч на 5 тысяч футов или 25 миллионов квадратных футов. Число рулонов туалетной бумаги, необходимой, чтобы покрыть квадратную милю, составит 25 миллионов, деленных на 30. Что такое 25 для вопросов категории Ферми — это практическое то же самое, что и 30. Будем считать, что для покрытия квадратной мили нужен миллион рулонов.
Представим, что собеседование вы проходите в Техасе. Протяженность США (без Аляски и Гавайев) с запада на восток примерно 2500 миль. Можно достаточно обоснованно предположить, что площадь Техаса — 500 на 500 миль. Разумеется, Техас не квадратный, но представим его таким. Поэтому площадь Техаса примерно равна 500 х 500 миль = 250 тысяч квадратных миль. Чтобы покрыть весь Техас туалетной бумагой, вам потребуется 250 тысяч х 1 миллион рулонов, то есть всего-навсего 250 миллиардов рулонов.
97. Сколько молекул резины стираются с шины автомобильного колеса при каждом его обороте?
В формулировке задачи нет цифровых данных. С чего же начать?
Мы настолько привыкли выдергивать из условия задачи цифры и немедленно начинать с ними работать… Правда, работа эта зачастую заключается в полубессмысленном перемножении – делении – сложении – вычитании, что назвать это работой как-то язык не поворачивается. Тем не менее, такая привычка есть. Тем лучше. Значит, наша задача с первых же минут заставляет задумываться не над арифметическими действиями, а непосредственно над самой ситуацией, описанной в условии. Итак, мы должны сами задать исходные данные – радиус покрышки, суммарную массу резины и так далее.
Конечно, это некоторым образом вымышленные, приближенные данные. Правомерен вопрос: сможем ли мы на их основе получить точный ответ? Если под словом «точный» понимать ответ, близкий к истине, то нет, не можем. Но в задачах такого рода под точностью понимается результат по порядку величины и поэтому нам незачем штангенциркулем мерить диаметр колеса, пытаясь задать его с точностью до миллиметра. Вполне достаточно взять приближенную величину; главное – не ошибиться в порядке. Впрочем, сделать это довольно трудно. Действительно, любому здравомыслящему человеку ясно, что, например, радиус колеса автомобиля (для определенности возьмем легковой автомобиль) не может быть равен 100 метров, 10 метров и даже 1 метр. Он находится между 0,1 и 1 метром, то есть по порядку величины равен 0,1 = 10-1. А для оценки совсем неважно, выберем ли мы для расчетов значение 0,2 или 0,3 – их порядок одинаков. Следовательно, такой выбор не отразится на порядке результата, то есть на точности оценки.
Ладно, с этим разобрались. Каков же будет план наших действий? Сначала мы определим объем резины, который стирается с шины, затем разделим его на объем молекулы – и получим необходимый результат. Пусть так. Но вы представляете себе, как определить объем стираемой резины? Даже один оборот? Да еще сидя за столом, а не бегая с аптечными весами вокруг автомобиля? Казалось бы, это практически невозможно. Но Вы сами знаете: сказать, что ответа нет гораздо проще, нежели попытаться его найти. Мы всегда будем выбирать второй путь: он труднее, но и интереснее. Давайте поступим так. Определим объем резины, которая была стерта с колеса за все время его эксплуатации и разделим его на количество оборотов колеса за это время. Получим искомый объем стертой за 1 оборот резины.
98. Cколько денег понадобится на мытье всех окон в Сиэтле?
Развитие умения измерять неизвестное и мыслить абстракциями может здорово помочь программисту. На собеседованиях в крупные компании вас очень часто могут попытаться подловить на неумении оперировать большим количеством неизвестных данных, поэтому лучше потренироваться заранее.
История знала немало личностей, способных «объять необъятное». Один из них — Энрико Ферми, лауреат Нобелевской премии по физике, который учил своих студентов измерять на примере оценки числа настройщиков пианино в Чикаго. С тех пор задачи, в которых нужно оценить что-то «с точностью до порядка» основываясь на здравом смысле, называют в его честь — задачи Ферми. У нас на сайте есть целая подборка подобных задач, и ниже мы рассмотрим ещё одну:
Какую цену Вы установили бы за мойку всех окон в Сиэтле?
Для начала нужно сделать первый шаг — оценить численность населения в Сиэтле. По данным бюро переписи населения США, она составляет 594 тысяч человек. Впрочем, на собеседовании никто не возмутится, если вы скажете, что численность Сиэтла — примерно около миллиона.
Сколько окон приходится на каждого жителя этого города? В Манхэттене молодые люди считают, что им повезло, если у них есть одно окно на каждого. В Сиэтле ситуация другая: там квартиры побольше, и многие люди живут в домах с панорамными окнами, выходящими на вечнозеленые леса. Многие дома, в том числе и в городе, двухэтажные. Можно предположить без особой натяжки, отдавая предпочтение удобным круглым цифрам, что на каждого жителя Сиэтла приходится 10 окон.
Окна есть и там, где люди работают, а также в кофейнях, универмагах, аэропортах, концертных залах и других зданиях общественного назначения. Их число, скорее всего, добавляют не слишком много окон в расчете на каждого жителя. На типичном рабочем месте — разделенном перегородками — окон вообще нет. Магазины занимают 1 этаж, и в них относительно немного окон по сравнению с объемом. Окна в публичных зданиях, вроде ресторанов и аэропортов, приходятся на огромную массу людей, которые ими пользуются.
Не забудьте окна в автомобилях (лучше спросить интервьюера, стоит ли их считать). В автомобиле как минимум четыре окна, а часто вдвое больше. Но огромные внедорожники предназначены для больших семей и поэтому добавляют не слишком много окон в расчете на одного человека.
Не будет необоснованным считать, что, помимо окон в жилых домах, на каждого человека в городе добавляется еще 10 окон. Таким образом, мы приходим к 20 окнам на каждого жителя Сиэтла.
Предполагая, что население составляет миллион человек, получаем, что в городе примерно 20 миллионов окон, которые надо привести в порядок.
Сколько вы взяли бы сами за одно окно? Если говорить об окне в вашем доме, то потребуется несколько пшиков чистящего средства, несколько бумажных полотенец и несколько секунд работы.
Отдельные окна в Сиэтле огромные и находятся очень высоко. Тут нужны специалисты иного рода, специальное оборудование, специальные расценки и разумный подход.
Некоторые могут, вероятно, вымыть одну сторону обычного окна за минуту и будут отталкиваться от этого времени как минимально требуемого. Это означает, что на одно окно придется две минуты. При такой скорости за час можно справиться с 30 окнами.
Скажем, средний мойщик зарабатывает 10 долларов в час. Добавьте еще 5 долларов в час на моющие принадлежности и страховку. Таким образом, за 15 долларов в час можно сделать чистыми 30 окон. Стоимость очистки окна — 50 центов. 20 миллионов окон, умноженные на 50 центов, дают 10 миллионов в долларах.
Этот вопрос задают и в Amazon, и в Google. Если вы еще не уловили скрытого подтекста, вот он: Windows (окна в переводе) — это зарегистрированный торговый знак еще одной известной компании. Угадайте, какой.
Также смотрите примеры других задач для самостоятельного решения.
99. Задача, которую давали на собеседованиях в Apple. От вас требуется написать функцию, которая возвращает максимальную прибыль от одной сделки с одной акцией (сначала покупка, потом продажа). Исходные данные — массив вчерашних котировок stock_prices_yesterday с ценами акций Apple.
Информация о массиве:
Индекс равен количеству минут с начала торговой сессии (9:30 утра).
Значение в массиве равно стоимости акции в это время.
Например: если акция в 10:00 утра стоила 20 долларов, то stock_prices_yesterday[30] = 20.
Допустим, имеем некоторые условия:
stock_prices_yesterday = [10, 7, 5, 8, 11, 9] profit = get_max_profit(stock_prices_yesterday) #вернет 6 (купили за 5, продали за 11)
Массив может быть любым, хоть за весь день. Нужно написать функцию get_max_profit как можно эффективнее — с наименьшими затратами времени выполнения и памяти.
Для решения задачи недостаточно просто взять максимальную и минимальную цены, так как вы сначала должны купить по самой низкой цене, а затем продать по самой высокой, которая будет после цены покупки. Кроме того, если цена акции падает весь день, то лучшим ответом будет отрицательное число.
Для каждой цены будем проверять:
Инициализация:
Код решения (на Python):
def get_max_profit(stock_prices_yesterday):
# убедимся, что количество цен в массиве превышает 2
if len(stock_prices_yesterday) < 2:
raise IndexError('Получение прибыли требует как минимум двух цен в массиве')
# инициализируем min_price и max_profit
min_price = stock_prices_yesterday[0]
max_profit = stock_prices_yesterday[1] - stock_prices_yesterday[0]
for index, current_price in enumerate(stock_prices_yesterday):
# пропустим 0-ой элемент массива, так как min_price инициализирован.
# Также продавать в 0-й позиции нельзя
if index == 0:
continue
# вычисляем потенциальную прибыль
potential_profit = current_price - min_price
# обновляем максимальную прибыль
max_profit = max(max_profit, potential_profit)
# обновляем минимальную цену
min_price = min(min_price, current_price)
return max_profit
Эффективность полученного алгоритма — O(n) по времени и O(1) по памяти. Цикл проходит по массиву только один раз.
100. Задача про слияние промежутков в календаре.
Предположим, компания, в которой вы работаете, разрабатывает электронный календарь. В календаре есть функция, показывающая, когда различные команды программистов будут заняты на какой-либо встрече.
Те периоды, когда команда занята, на календаре отмечены как диапазоны времени, например, с 10:00 до 12:30 или с 12:30 до 13:00. В разрабатываемой программе промежуток времени представлен в виде кортежей из двух целых чисел. Число означает номер 30-минутного блока, который идет после 9:00 утра. Например, кортеж (2, 4) означает диапазон с 10:00 до 11:00, а (0, 1) — это промежуток 9:00-9:30.
Вам нужно написать функцию, которая должна упростить вывод информации таким образом, что если команда занята в промежутках с 10:00 до 12:30 и с 12:30 до 13:00, то это отображалось как 10:00?13:00. Например: на входе вашей функции неупорядоченный массив из кортежей [(0, 1), (3, 5), (4, 8), (10, 12), (9, 10)], а на выходе вы должны получить упорядоченный массив [(0, 1), (3, 8), (9, 12)].
В будущем планируется внести изменения в программу, где вместо 30-минутных блоков будут минутные, как это реализовано в представлении Unix-времени. С учетом этого изменения нужно, чтобы ваша функция уже сейчас могла работать с большими числами. Еще не забудьте, что кортеж — это такой тип данных, в котором содержимое переменной невозможно изменять после ее создания.
Решений можно придумать много, но нам нужен максимально эффективный код. Для начала нужно отсортировать массив, так нам будет удобнее объединять соседние временные диапазоны, так как они будут друг за другом. Затем пройдемся по нашему массиву слева направо и на каждом шаге будем выполнять один из двух вариантов:
Также необходимо проследить за тем, чтобы последний сохраненный результат попал в выходной массив, так как не будет того же самого условия, как с предыдущими: отсутствие следующего диапазона, который не объединится с текущим.
Код решения на Python:
def merge_ranges(meetings):
# сортируем входной массив, помещая его в sorted_meetings.
sorted_meetings = sorted(meetings)
# создаем выходной массив, пока что пустой.
merged_meetings = []
previous_meeting_start, previous_meeting_end = sorted_meetings[0]
for current_meeting_start, current_meeting_end in sorted_meetings[1:]:
# Если текущий диапазон может быть объединен с предыдущим.
if current_meeting_start <= previous_meeting_end:
# Сохраняем результат на случай, если
# текущий диапазон будет расширен еще раз.
previous_meeting_end = max(current_meeting_end, previous_meeting_end)
# Если текущий диапазон не может быть объединен с предыдущим.
else:
# вставляем результат в выходной массив
merged_meetings.append((previous_meeting_start, previous_meeting_end))
previous_meeting_start, previous_meeting_end = \
current_meeting_start, current_meeting_end
# вставляем последний результат.
merged_meetings.append((previous_meeting_start, previous_meeting_end))
return merged_meetings
Сложность алгоритма — O(n lg n) по времени и O(n) по памяти. O(n lg n) получилось из-за того что помимо одного прохода по массиву, мы перед этим его сортировали.
101. Задача, которую давали на собеседованиях в Apple. Представьте, что вы получили работу кассира в магазине. Ваш босс случайно выяснил, что вы обладаете навыками программиста, и захотел, чтобы вы помогли ему написать программу.
Входные данные:
Указанная сумма денег.
Массив со всеми доступными номиналами монет.
Нужно написать функцию, которая на выходе выдаст количество всех возможных способов получить указанную сумму денег при помощи различных доступных номиналов монет. Например, если вам нужно получить 4 цента из монет номиналами 1, 2 и 3 цента, то функция вернет 4 — именно столько есть возможных комбинаций из чисел 1, 2 и 3, чтобы получить в сумме 4:
1, 1, 1, 1.
1, 1, 2.
1, 3.
2, 2.
Мы используем динамическое программирование, чтобы создать массив ways_of_doing_n_cents таким образом, что ways_of_doing_n_cents[k] содержит значение количества способов собрать сумму k, используя доступные номиналы. Для начала мы начнем с отсутствия номиналов, имея лишь один вариант — собрать сумму 0, затем мы будем добавлять по одному номиналу, по возрастанию, и одновременно редактировать наш массив с учетом новых номиналов.
Количество новых вариантов, которыми мы можем сделать сумму higher_amount с учетом нового номинала монеты coin, вычисляется как уже существующее значение ways_of_doing_n_cents[higher_amount - coin]. Нам уже известны все комбинации с предыдущими номиналами, поэтому мы используем эту информацию при добавлении нового номинала. При добавлении первого номинала, мы считаем, что предыдущий номинал равен 0.
Код решения на Python:
def change_possibilities_bottom_up(amount, denominations):
ways_of_doing_n_cents = [0] * (amount + 1)
ways_of_doing_n_cents[0] = 1
for coin in denominations:
for higher_amount in xrange(coin, amount + 1):
higher_amount_remainder = higher_amount - coin
ways_of_doing_n_cents[higher_amount] += ways_of_doing_n_cents[higher_amount_remainder]
return ways_of_doing_n_cents[amount]
Чтобы было понятнее, вот что содержит массив ways_of_doing_n_cents по мере выполнения итераций, при этом сумма равна 5 и номиналы равны 1, 3 и 5:
===========
key:
a = higher_amount
r = higher_amount_remainder
===========
============
for coin = 1:
============
[1, 1, 0, 0, 0, 0]
r a
[1, 1, 1, 0, 0, 0]
r a
[1, 1, 1, 1, 0, 0]
r a
[1, 1, 1, 1, 1, 0]
r a
[1, 1, 1, 1, 1, 1]
r a
============
for coin = 3:
=============
[1, 1, 1, 2, 1, 1]
r a
[1, 1, 1, 2, 2, 1]
r a
[1, 1, 1, 2, 2, 2]
r a
============
for coin = 5:
=============
[1, 1, 1, 2, 2, 3]
r a
final answer: 3
Сложность алгоритма — O(n*m) по времени и O(n) по памяти, где n — это сумма, а m — количество различных номиналов.
102. Эту задачу когда-то давали в Google.
Вам нужно подняться по лестнице. За один раз можно подняться на одну или две ступеньки. Сколько существует способов добраться до N-й ступеньки?
Начало здесь простое. Вы стоите на лестничном марше и хотите подняться на первую ступеньку — № 1. Для этого надо сделать всего одно действие — подняться на одну ступеньку вверх. Теперь давайте рассмотрим вторую ступеньку, то есть N = 2. Чтобы подняться на неё, имеются два варианта. Вы можете сделать два шага — по одной ступеньке за раз или сразу подняться на вторую ступеньку.
Это практически вся информация, которая нужна вам для решения этой задачи. Чтобы понять, почему, представьте, что вашей целью является ступенька № 3. Впервые в этой ситуации вы не можете попасть на неё одним движением. здесь потребуется комбинация шагов. Существует только два способа попадания на ступеньку № 3: либо в виде короткого одиночного шага (со ступеньки № 2), либо двойного шага (со ступеньки № 1). Мы уже знаем, что для подъема на ступеньку № 1 имеется лишь один вариант. Мы также знаем, что есть всего два способа подняться на ступеньку № 2. Сложите эти варианты (1 + 2 = 3), и вы получите число способов, позволяющих подняться на ступеньку № 3.
Та же самая логика применяется для подъема на каждую следующую ступеньку. Существует два способа, чтобы подняться на ступеньку № 4 — со ступеньки № 2 или со ступеньки № 3. Добавьте число способов подъема на ступеньку № 2 (2) к числу способов, позволяющих оказаться на ступеньке № 3 (3). Это даёт 5 вариантов — число способов, позволяющих оказаться на ступеньке № 4.
Легко продолжить эту серию и дальше. С увеличением числа ступенек число способов подниматься по ним нарастает, как снежный ком, что можно представить в следующем виде:
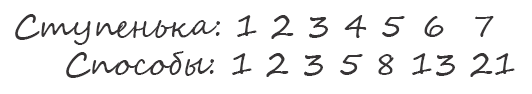
Любому человеку с математической подготовкой нижняя серия покажется до боли знакомой. Так оно и есть. Это последовательность Фибоначчи. (Чуть подробнее о ней ниже.) Интервьюер хочет получить ответ для общего случая из N ступенек.
Это просто число Фибоначчи под номером N. Леонардо Фибоначчи, также известный как Леонардо Пизанский, был самым влиятельным итальянским математиком в Средние века. Именно Фибоначчи понял невероятное превосходство арабскo-индийской позиционной системы исчисления по сравнению с римским обозначением цифр, которое все ещё использовалось в средневековой Европе. При помощи арабско-индийской системы умножение и деление можно было свести к алгоритму (еще одно арабское слово). При применении римских чисел эти операции на практике выполнять было сложно. Торговцам приходилось приглашать экспертов и дорого им платить за вычисления, которые те осуществляли при помощи абаков. В 1202 году Фибоначчи написал Liber abaci — руководство по использованию абака, в котором он расхваливал арабские числа своим читателям, которые были, скорее всего, настроены к ним скептически. В этой книге также описывается и та серия чисел, которую мы теперь называем по его фамилии. Однако её изобрел не Фибоначчи. Эта последовательность была известна еще индийским ученым, жившим в VI веке.
Напишите 1, а затем добавьте еще 1 рядом. Сложите их и получите сумму (2), которая затем добавляется к формируемой последовательности:
1 1 2
Для получения каждого нового члена лишь складывайте последние два числа в ряду/ Серия примет следующий вид.
1 1 2 3 5 8 13 21 34 55 89 144 …
Поклонники теории заговоров отыскивают серии Фибоначчи в самых неожиданных местах. Хотите перевести расстояние из миль в километры? Воспользуйтесь соседними числами Фибоначчи (55 миль в час = 89 километров в час). В следующий раз, когда у вас окажется свободное время, посчитайте небольшие дольки, из которых состоит кожура ананаса, и вы обнаружите, что они образуют два накладывающихся друг на друга набора спиралей, идущих в противоположных направлениях. В одной из них восемь долей, в другой тринадцать. Оба этих числа относятся к серии Фибоначчи. Аналогичные закономерности можно увидеть в сосновых шишках, подсолнухах и артишоках. Случайность? Вряд ли, если учесть тот факт, что последовательность Фибoначчи проявила себя и в Коде Да Винчи (в виде комбинации для вскрытия сейфа), и в этом вопросе на собеседовании, который задают в компании, стремящейся к информационному доминированию во всем мире (Google, если вы не поняли).
103. Эту задачу задавали на собеседовании в Twitter.
Рассмотрим следующую картинку:
На этой картинке изображены стены различной высоты в некотором плоском мире. Картинка представлена массивом целых чисел, где индекс — это точка на оси X, а значение каждого индекса — это высота стены (значение по оси Y). Картинке выше соответствует массив [2, 5, 1, 2, 3, 4, 7, 7, 6].
Теперь представьте, что начался дождь, который не прекращается и поливает стены сверху равномерным потоком. Сколько воды соберется в «лужах» между стенами?
Единицей объема воды считаем квадратный блок 1x1. На картинке выше всё, что расположено слева от точки 1, выплескивается. Вода справа от точки 7 также прольется. У нас остается лужа между 1 и 6 — таким образом, получившийся объем воды равен 10.
Можно предположить, что нужно найти локальные максимумы и подсчитать пространство между ними, заполненное водой. Алгоритм будет довольно простой, но ответ на самом деле некорректен.
Рассмотрим пример:
Решение будет таким:
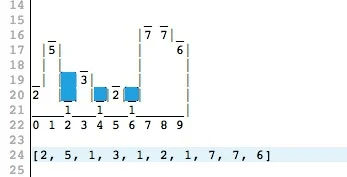
Хотя на самом деле должно быть таким:
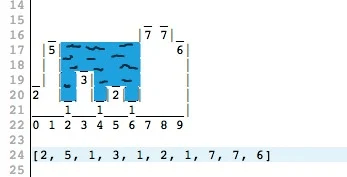
Если мы проходим по списку слева направо, количество воды в каждом индексе будет не больше абсолютного максимума, который мы обнаружим заранее. Это означает, что если мы точно знаем, что есть что-то большее или равное где-то справа, то мы можем точно определить, сколько воды мы можем удержать без выплескивания. То же справедливо и для противоположного направления: если мы знаем, что нашли слева стену выше самой высокой в правой части, то это означает, что мы с уверенностью можем заполнить ее водой.
Итак, теперь решение выглядит следующим образом: найти абсолютный максимум, после чего пройти слева до максимума и затем пройти справа до максимума. Это решение требует два прохода: один для поиска максимума, и второй — разбитый на две части.
Решение в приведенном ниже коде работает в один проход, избегая поиска максимума проходом двух «указателей» навстречу друг другу с противоположных концов массива. Если наибольшее значение, найденное слева от левого указателя меньше, чем наибольшее значение найденное справа от правого указателя, то мы сдвигаем левый указатель на один индекс вправо. В противном случае, двигаем правый указатель на один индекс влево. Повторяем до тех пор, пока два указателя не пересекутся. (На словах звучит запутанно, код на самом деле очень простой).
/* package whatever; // don't place package name! */
import java.util.*;
import java.lang.*;
import java.io.*;
/* Name of the class has to be "Main" only if the class is public. */
class Ideone
{
public static void main (String[] args) throws java.lang.Exception
{
int[] myIntArray = {2, 5, 1, 2, 3, 4, 7, 7, 6};
System.out.println(calculateVolume(myIntArray));
}
public static int calculateVolume(int[] land) {
int leftMax = 0;
int rightMax = 0;
int left = 0;
int right = land.length - 1;
int volume = 0;
while(left < right) {
if(land[left] > leftMax) {
leftMax = land[left];
}
if(land[right] > rightMax) {
rightMax = land[right];
}
if(leftMax >= rightMax) {
volume += rightMax - land[right];
right--;
} else {
volume += leftMax - land[left];
left++;
}
}
return volume;
}
}
Для тех, кто предпочитает Gist.
104. Задача про бесконечный поезд.
Представьте себе замкнутую по окружности железную дорогу. По ней едет поезд, последний вагон которого скреплён с первым так, что внутри можно свободно перемещаться между вагонами. Вы оказались в одном случайном вагоне и ваша задача — подсчитать их общее количество. В каждом вагоне можно включать или выключать свет, но начальное положение переключателей случайное и заранее неизвестно.
Все вагоны внутри выглядят строго одинаково, окна закрыты так, что невозможно посмотреть наружу, движение поезда равномерное. Помечать вагоны как-либо, кроме включения или выключения света, нельзя. Количество вагонов конечно (не верьте названию задачи).
Предложим один из возможных вариантов решения. Вам нужно включить свет в начальном вагоне, в котором вы находитесь, если он ещё не горит. Затем пойти в одну любую сторону до тех пор, пока не встретите вагон с работающим освещением, при этом обязательно считать пройденные вагоны. Выключаете в найденном вагоне свет и идёте обратно к начальному. Если в нём свет всё ещё горит, то повторяете операцию. Если же нет, значит вы прошли полный круг и знаете ответ.
С таким же успехом можно, например, ходить по сторонам от начального вагона на равные расстояния, постепенно их увеличивая, и инвертировать в них свет. То есть если считать, что сначала вы в вагоне с номером 0, то ходить надо в -1, 1, -2, 2, -3, 3 и так далее. Если при этом запоминать состояние самого дальнего вагона, то при повторном прохождении мимо него вы заметите изменившийся свет, если круг замкнётся. А зная длину пути в обе стороны, вы легко вычислите общее количество вагонов.
105. Вы стоите перед закрытой комнатой, в которой есть три лампочки. На стене перед вами три переключателя: каждый из которых включает или выключает одну из лампочек. Вам нужно узнать, какой переключатель к какой лампочке относится, при условии, что зайти в комнату вы можете только один раз.
Расположение переключателей случайное, порядок подключения заранее неизвестен. Зайдя в комнату, можно делать с лампочками всё, что угодно, но уже нельзя вернуться к переключателям. Изначально все лампы выключены.
Если вы хотите решить задачу самостоятельно, но в голову ничего не приходит, можете воспользоваться нашей подсказкой.
У лампочек при начальных условиях есть только два состояния: горит или не горит. Понятно, что этого недостаточно, чтобы разделить их на три группы. Вам нужно придумать какие-то ещё состояния лампочек и способ их добиться переключателями.
Рассуждая логически, вы можете включить одну лампу, вторую выключить, а вот что делать с третьей — непонятно. Состояний лампы всего два: либо «включена», либо «выключена». Самый популярный способ решения состоит в том, чтобы в качестве третьего состояния добавить разделение ламп на «теплые» и «холодные». Нужно подождать какое-то время, чтобы лампы остыли на случай, если они недавно включались. Затем включить одну для нагревания. Выключить её обратно и включить любую другую. Зайдя после этого в комнату одна лампа будет гореть, вторая выключена и холодная, третья выключена и горячая.
Другой вариант добавить лампам состояние «перегорела», если есть возможность подать на переключатель большее напряжение, чем нужно. Дальше действовать аналогично предыдущей схеме.
Также в комментариях к статье предложили добавить к одной из лампочек управляемое реле и заставить её мигать. Если у вас есть другие варианты, пишите в комментариях.
106. Классическая задача. Найдите в данной вам строке максимальную по длине подстроку, которая является палиндромом (то есть читается слева направо и справа налево одинаково). Предложите как можно более эффективный алгоритм.
Очевидное квадратичное решение приходит в голову практически сразу. У каждого палиндрома есть центр: символ (или пустое место между двумя соседними символами в случае палиндрома четной длины), строка от которого читается влево и вправо одинаково. Например, для палиндрома abacaba таким центром является буква c, а для палиндрома colloc — пространство между двумя буквами l. Очевидно, что центром нашей искомой длиннейшей палиндромной подстроки является один из символов строки (или пространство между двумя соседними символами), в которой мы производим поиск.
Теперь мы можем реализовать такое решение: давайте переберем все символы строки, для каждого предполагая, что он является центром искомой самой длинной палиндромной подстроки. То есть предположим, что на данный момент мы стоим в i-ом символе строки. Теперь заведем две переменных left и right, изначально left = i - 1 и right = i + 1 для палиндромов нечетной длины и i - 1, i соответственно для палиндромов четной длины. Теперь будем проверять, равны ли символы в позициях строки left и right. Если это так, то уменьшим left на 1, а right увеличим на 1. Будем продолжать этот процесс до тех пор, пока символы в соответствующих позициях станут не равны, или же мы не выйдем за границы массива. Это будет означать, что мы нашли самый длинный палиндром в центре с i-ым символов в случае для палиндрома нечетной длины и в пространстве между i-ым и i - 1-ым символом в случае палиндрома четной длины. Выполним такой алгоритм для всех символов строки, попутно запоминая найденный максимум, и таким образом мы найдем самую длинную палиндромную подстроку всей строки.
Докажем, что это решение работает за O(n²). Рассмотрим строку ааааааааааааааа… Для каждого ее символа мы будем двигать left и right, пока не выйдем за границы массива. То есть для первого символа мы сделаем 0*2 (умножение на 2 происходит, потому что мы выполняем алгоритм два раза — для палиндромов нечетной и четной длины) итераций, для второго 1*2, для третьей 2*2, и т.д. до центра, потом кол-во итераций станет уменьшаться. Это арифметическая прогрессия с разностью 2. Рассмотрим сумму этой арифметической прогрессии до середины строки. Как известно, сумма арифметической прогрессии имеет формулу (A1+An)/2*n. В нашем случае A1 = 0, An = n/2*2 = n. (0+n)/2*n = n/2*n = O(n²). Для убывающей части все аналогично, там тоже получится O(n²). O(n²)+O(n²) = O(n²), ч.т.д.
Это решение является ускоренной модификацией предыдущего. Можно посчитать для строки полиномиальный хеш, замечательным свойством которого является то, что мы можем за О(1) получить хеш любой подстроки, а значит, посчитав его для оригинальной и перевернутой строки мы можем за О(1) проверить, является подстрока [l..r] палиндромом (реализацию можно найти здесь). Следующее замечание состоит в том, что для каждого центра при переборе подстрока на некотором количестве итераций сначала будет являться палиндромом, а затем всегда нет. А это значит, что мы можем воспользоваться бинпоиском: переберем все символы, для каждого бинпоиском найдем максимальную палиндромную подстроку с центром в нем, по ходу дела будем запоминать найденный максимум.
Очевидно, что это решение работает за О(n log n) по времени. Мы перебираем все n символов, для каждого совершаем O(log n) итераций бинпоиска, на каждой из который проверяем, является ли подстрока палиндромом. В итоге: O(n log n) по времени и О(n) по памяти (потому что нам наобходимо хранить посчитанные хеши).
Несправедлимым будет не упомянуть в этой статье алгоритм Манакера, решающий поставленную задачу за линейное время и линейную память.
107. Реализуйте функцию извлечения квадратного корня, не пользуясь встроенными в язык средствами нахождения корня и возведения в степень.
Из курса школьной математики мы помним, что функция квадратного корня является возрастающей на всей своей области определения (если вы этого не помните или вам это не очевидно, можете взять производную и убедиться, что она больше нуля), а значит, мы можем воспользоваться алгоритмом бинарного поиска.
Допустим, что нам нужно извлечь квадратный корень из числа x. Установим левую границу бинпоиска на 0, а правую — на max(1, x). Таким условием мы учтем все возможные случаи: на отрезке 0..1 корень из числа больше самого числа, на отрезке 1..inf — меньше).
Теперь найдем среднее арифметическое границ, назовем его m, и проверим, больше ли m * m, чем x. Если да, то искомый ответ лежит на числовой прямой левее m, а значит, необходимо сделать m правой границей бинпоиска, иначе — левой. Спустя пару сотен таких итераций мы найдем квадратный корень с удовлетворяющей всем потребностям точностью.
Реализуйте подобным образом функцию для поиска корня n-ной степени.
108. В этой задаче вам необходимо реализовать функцию, которая бы проверяла число на четность, используя только битовые операции AND, OR, NOT.
Заметим, что число x нечетно только тогда, когда самый младший (то есть первый справа) бит в его двоичной записи равен 1. Докажем это. Вспомним знакомый со школьной статьи алгоритм перевода числа из двоичной системы в десятеричную. Он показан на следующей картинке:
Мы можем вынести два за скобку из всех слагаемых, кроме последнего, которое может принимать значение либо 1, либо 0. Таким образом, если оно равно нулю, то сумма будет иметь вид 2(…) = x, то есть будет делиться на два, а если оно будет равно единице, то сумма будет иметь вид 2(…)+1 = x, то есть не будет делиться на два. Это является критерием четности. Ч.т.д.
Итак, мы доказали факт того, что число нечетно, когда его младший бит равен 1, и четно, когда младший бит равен 0. Остался вопрос: как получить последний бит числа. Утверждение: последний бит числа x равен x&1, где & — побитовое И. Почему это так? И равно 1 только когда оба его аргумента равны 1. Число 1 в двоичной системе счисления имеет следующий вид: …000001 (в зависимости от того, скольки битными числами мы оперируем). А значит, при побитовом И единицы с числом х у результата все биты, кроме последнего, будут равны нулю, а последний бит будет равен 1, если в числе x он был равен 1 (1&1 = 1), и 0, если в числе x он был 0 (0&1 = 0).
Таким образом, значение выражения x&1 равно 1, если число x нечетное, и 0, если x четное.
109. На прямой даны N отрезков (в реальной жизни это могут быть промежутки времени, например), которые заданы координатами их левого и правого конца. Для каждого данного отрезка необходимо узнать, сколько из данных отрезков полностью находятся в нем. Один отрезок полностью содержится во втором, если левый конец первого отрезка находится правее левого конца второго отрезка, а правый конец первого находится левее правого конца второго. Предложите как можно более эффективный способ решения этой задачи. Гарантируется, что все концы данных отрезков различны.
Если вы придумали решение, то написать и проверить его вы можете здесь, на codeforces.
Сможете ли вы решить эффективно данную задачу в случае, если концы отрезков могут совпадать?
Давайте для каждого отрезка из набора перебером найдем все отрезки, для которых выполняется условие «вложенности». Если да, то увеличим ответ для текущего рассматриваемого нами отрезка на единицу. Несложно понять, что данное решение работает за O(n2): для каждого из N отрезков мы перебираем N отрезков. Можно ли быстрее? Да!
Отсортируем все отрезки по левому концу и будем рассматривать их в уже отсортированном порядке. Вспомним условие «вложенности»: левый конец первого отрезка правее левого конца второго отрезка, и правый конец первого отрезка левее правого конца второго отрезка. Несложно понять, что благодаря отсортированности все левые концы еще нерасмотренных отрезков будут правее левого конца рассматриваемого отрезка. Таким образом, все нерасмотренные отрезки потенциально являются вложенными в рассматриваемый: ведь для них уже выполняется одно из двух условий «вложенности» (про левые концы). Осталось узнать, сколько из них действительно являются таковыми — для этого нужно понять, сколько из нерассмотренных отрезков имеют правый конец левее правого конца рассматриваемого отрезка.
Для этого будем поддерживать структуру данных, которая может добавить и удалять из себя числа и отвечать на запросы вида: «сколько чисел во мне меньше X?», причем все операции должны выполняться за O(log n). Такой структурой данных может быть, например, декартово дерево, дерево Фенвика, дерево отрезков, или tree из ext/pb_ds/detail/standard_policies.hpp (если вы пишете на С++). Перед выполнением алгоритма для решения задачи сложим в нашу структуру координаты всех правых концов отрезков.
Теперь, чтобы узнать сколько из нерассмотренных отрезков имеют правый конец левее правого конца рассматриваемого отрезка, достаточно просто осуществить запрос к структуре данных «сколько чисел в тебе меньше, чем координата правого конца рассматриваемого отрезка». Ответ на этот запрос и будет ответом для рассматриваемого на данный момент нами отрезка. После запроса необходимо убрать координату правого конца отрезка из структуры данных, чтобы ответы для всех следующих отрезков были корректны: ведь левый конец рассматриваемого отрезка левее (благодаря отсортированности) левый концов всех еще нерасмотренных отрезков.
Докажем, что данное решение работает за О(n log n). Сортировка всех отрезков происходит за O(n log n), складывание всех правых концов отрезков в структуру данных за O(n log n), на стадии вычисления ответов мы рассмотрим n отрезков, для каждого из которых осуществим два запроса, оба из которых выполнятся за О(log n). Таким образом, вычисляем все ответы мы за O(n log n) с препроцессингом за O(n log n), а значит, и асимптотика всего решения O(n log n).
Сможете ли вы решить эффективно данную задачу в случае, если концы отрезков могут совпадать?
110. Придумать алгоритм, определяющий, все ли символы в строке встречаются один раз.
При выполнении этого задания нельзя использовать дополнительные структуры данных.
Один из очевидных вариантов решения состоит в том, чтобы сравнить каждый символ строки с любым другим символом строки. Это потребует О(n2) времени и О(1) памяти.
Если изменения строки разрешены, то можно её отсортировать (что потребует О(n log n) времени), а затем последовательно проверить строку на идентичность соседних символов. Будьте осторожны: некоторые алгоритмы сортировки требуют больших объёмов памяти.
Можно слегка оптимизировать задачу — возвращать false, если длина строки превышает количество символов в алфавите. В конце концов, не может существовать строки с 280 уникальными символами, если символов всего 256. Однако если это Unicode-строка, то такая оптимизация не очень поможет.
Наше решение заключается в создании массива логических значений, где флаг с индексом i означает, содержится ли символ алфавита i в строке. Если вы «наткнетесь» на этот же символ во второй раз, можете сразу возвращать false.
Код, реализующий этот алгоритм, представлен ниже:
public boolean isUniqueChars2(String str) {
boolean[] char_set = new boolean[256];
for (int i = 0; i < str.length(); i++) {
int val = str.charAt(i);
if (char_set[val]) { //символ уже был найден в строке
return false;
}
char_set[val] = true;
}
return true;
}
Оценка времени выполнения этого кода — О(n), где n — длина строки, оценка требуемого пространства — O(1).
Можно уменьшить использование памяти за счёт битового вектора. В следующем коде мы предполагаем, что в строке есть только символы в нижнем регистре a-z. Это позволит нам использовать просто одно значение типа int.
public boolean isUniqueChars(String str) {
int checker = 0;
for (int i = 0; i < str.length(); i++) {
int val = str.charAt(i) - 'a';
if (checker & (1 << val)) > 0) {
return false;
}
checker |= (1 << val);
}
return true;
}
Выбор лучшего решения нужно производить исходя из соответствующих дополнительных ограничений конкретной задачи.
111. В массиве случайных чисел A[0…n-1] задан один «волшебный» индекс: такой, что A[i] = i. Значения элементов в массиве повторяться не могут. Учитывая, что массив отсортирован по значениям в порядке возрастания, напишите метод, который определит этот «волшебный» индекс, если он существует в массиве A. Если элемента в массиве нет, верните любое отрицательное число.
Как изменится решение, если известно, что таких индексов в массиве несколько?
Можно решать такую задачу «в лоб», и в таком подходе нет ничего зазорного. Мы просто пройдемся по массиву и отыщем элемент, соответствующий условию.
public static int magicSlow(int[] array) {
for (int i = 0; i < array.length; i++) {
if (array[i] == i) {
return i;
}
}
return -i;
}
Но этому решению требуется обойти весь массив от начала до искомого элемента. Массив отсортирован, и, вероятно, мы должны этим воспользоваться.
Так задача становится похожа на классическую задачу бинарного поиска. Для алгоритма больше всего подходит способ «сопоставления с образцом».
При бинарном поиске мы берем элемент k и сравниваем его с элементом из середины массива, x, чтобы определить, по какую сторону от x находится искомого k — слева или справа. Давайте попробуем определить, где может находиться «волшебный» элемент на примере. Взгляните на массив (нижняя строка — индексы элементов):
| -40 | -20 | -1 | 1 | 2 | 3 | 5 | 7 | 9 | 12 | 13 |
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
Если взять элемент из середины массива, A[5] = 3, то становится ясно, что «волшебный» элемент должен находиться правее, так как A[mid] < mid. Почему в этой ситуации элемент не может быть слева? Индекс элемента в данном случае уже больше значения (5 > 3). Значит, все значения элементов с индексами 0-4 будут меньше самих индексов.
При движении в направлении от i к i-1 значение элемента будет уменьшаться не менее чем на 1 (так как массив отсортирован и не содержит одинаковых элементов). Если средний элемент меньше искомого, то при движении влево, смещаясь на k индексов и (как минимум) на k значений, мы будем попадать на еще более маленькие значения.
Наш алгоритм будет по такому принципу выяснять, где должен находиться искомый элемент — справа или слева, и проверять только одну половину массива. Этим мы сокращаем число итераций, необходимых для того, чтобы наткнуться на нужный элемент.
При использовании рекурсивного решения алгоритм похож на бинарный поиск.
public static int magicFast(int[] array, int start, int end) {
if (end < start || start < 0 || end >= array.length) {
return - 1;
}
// Индекс середины массива
int mid = (start + end) / 2;
if (array[mid] == mid) {
return mid;
} else if (array[mid] > mid) {
return magicFast(array, start, mid - 1);
} else {
return magicFast(array, mid + 1, end);
}
}
public static int magicFast(int[] array) {
return magicFast(array, 0, array.length - 1);
}
Дополнительно: как изменится решение, если таких индексов окажется несколько?
Если элементы массива повторяются, то наш алгоритм не будет работать. Давайте рассмотрим следующий массив:
| -10 | -5 | 2 | 2 | 2 | 3 | 4 | 7 | 9 | 12 | 13 |
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
Если A[mid] < mid, сказать заранее, где будут находиться «волшебные» элементы, становится сложнее.
Могут ли в этом массиве они находиться слева? Нет. Так как A[5] = 3, мы знаем, что A[4] никак не может быть «волшебным» элементом. A[4] должен быть равен 4, но в то же время мы знаем, что A[4] не может быть больше, чем A[5], из-за условия отсортированности.
Фактически, если мы видим, что A[5] = 3, нам достаточно проанализировать только правую сторону, как это и делалось раньше. Но чтобы найти элемент в левой части, можно пропустить группу элементов и произвести поиск только среди A[0] ‒ A[3], где A[3] — это первый элемент, который может быть «волшебным».
В общем, нам нужно взять элемент из середины массива и сравнить его индекс с его же значением — midIndex с midValue. Если они совпадают, то возвращаем значение сразу. Иначе выясняем, больше или меньше значение элемента из середины его индекса. В зависимости от полученного результата начинаем искать либо слева, либо справа.
start до Math.min(midIndex - 1, midValue).Math.Max(midIndex + 1, midValue) до end.Если же переданы ошибочные параметры, пусть код возвращает -1.
Представленный ниже код реализует данный алгоритм:
public static int magicFast(int[] array, int start, int end) {
if (end < start || start < 0 || end >= array.length) {
return -1;
}
// Находим индекс и значение из середины массива:
int midIndex = (start * end) / 2;
int midValue = array(midIndex);
// Если они совпадают - решение найдено
if (midValue == midIndex) {
return midIndex;
}
/* Если индекс меньше значения - поиск влево */
int leftIndex = Math.min(midIndex - 1, midValue);
int left = magicFast(array, start, leftIndex);
if (left >= 0) {
return left;
}
/* Если индекс больше - поиск вправо */
int rightIndex = Math.max(midIndex + 1, midValue);
int right = magicFast(array, rightIndex, end);
return right;
}
public static int magicFast(int[] array) {
return magicFast(array, 0, array.length - 1);
}
Этот код работает в том числе и для случая без дополнительного условия.
112. Как можно узнать количество дней в месяце, зная его номер? Другими словами, опишите, как получить функцию f(x), которая бы давала следующий список значений:

В качестве аргумента мы получаем только номер месяца, т.е. мы не учитываем високосные года, и f(2) = 28.
Если вы хотите узнать полученный мною результат, пролистните до конца этой страницы. То, что будет описано далее — это вывод искомой формулы.
Кроме сложения, вычитания и умножения, я воспользуюсь двумя операциями: целочисленным делением и операцией взятия остатка. Напомню, что это такое:
a / b — имея в виду ⌊a / b⌋. Например, 5 / 3 = 1.a % b = a — (a / b) * b. Например, 5 % 3 = 2.Они имеют одинаковый приоритет и являются левоассоциативными.
Давайте попробуем найти такую закономерность, которая удовлетворила бы как можно большему количеству значений аргумента. Обычно количество дней в месяце колеблется между 30 и 31. При этом, можно заметить зависимость этого числа от четности месяца — значит, воспользуемся операцией взятия остатка по модулю 2. Кажется, это должно быть нечто, вроде:
f1(x) = 30 + x%2

Неплохой старт! Не обращая внимания на февраль, для которого явно придется пойти на какие-то уловки, порадуемся тому, что мы смогли подогнать функцию под первую половину года. А далее, начиная с августа, четность надо сменить на противоположную. Сделать это можно, заменив x%2 в первом варианте формулы на (x+1)%2:
f2(x) = 30 + (x + 1) % 2

Как и ожидалось, теперь первая половина года уже вне области правильных значений, зато месяцы с августа по декабрь дали то, что надо. Найдем способ объединить две эти части.
Нам нужно, чтобы +1 в делимом «активировалось» только при достижении аргументом значений, больших 8, т.е. нам необходимо применить некоторую маску. При этом значения аргумента не могут превосходить 12. Значит, нам идеально подойдет целочисленное деление аргумента на 8:

Ровно как нам и нужно. Воспользуемся этим выводом:
f3(x) = 30 + (x + x / 8) % 2

Уху! Все правильно, кроме февраля. Как неожиданно.
Во всех месяцах 30 или 31 день, в феврале же — 28 (напомню, мы не рассматриваем високосные года).
Историческая справка: в романском календаре февраль был последним месяцем года — согласитесь, добавление одного дня в високосные годы в конец календаря интуитивно понятнее. Однако мы пользуемся григорианским календарем, в котором самый короткий месяц перенесен ближе к началу по воле одного из мудрых правителей.
В самой последней версии нашей формулы февралю достались целых 30 дней. А потому нам нужно отсечь у него пару дней. Естественно, от этого пострадают и еще какие-то месяцы: или слева от февраля, или справа от него в нашем списке — однако, справа месяцев гораздо меньше, поэтому нам придется пожертвовать именно январем, затем подправив формулу и для него. Отсечь дни для первого и второго месяцев можно с помощью выражения 2%x:

Тогда наша формула принимает уже следующий вид:
f4(x) = 28 + (x + x / 8) % 2 + 2 % x

Остался последний шаг — подлатать январь. Это сделать не так сложно: просто добавим 2 дня только к нему, т.е. к такому месяцу, чей номер меньше либо равен единице. Как вам идея использовать для этой цели 1/x? Проверяем:
f5(x) = 28 + (x + x / 8) % 2 + 2 % x + 1 / x * 2

Бинго! 12 из 12!
Итак, мы вывели искомую формулу, вот она, записанная на языке JavaScript:
function f(x) { return 28 + (x + Math.floor(x/8)) % 2 + 2 % x + 2 * Math.floor(1/x); }
Спросите меня, сколько дней в сентябре? Я скажу вам: f(9).
113. Задачка для питонистов: нужно перебрать все пары символов в строке, и остановиться при нахождении двух одинаковых символов.
Решение достаточно очевидное, но возникает вопрос:
s = "какая-то строка"
for i in range(len(s)):
for j in range(i+1, len(s)):
if s[i] == s[j]:
print(i, j)
break # Как выйти сразу из двух циклов?
Если бы мы программировали, например, на Java, то мы могли бы воспользоваться механизмом меток:
outterLoop: for(int i=0; i<n; i++){
for(int j=i; j<n; j++){
if(/*something*/){
break outterLoop;
}
}
}
Однако в Python такого механизма нет. Требуется предложить наиболее удобное в использовании и читаемое решение.
return из неё:
def func(): s="teste" for i in range(len(s)): for j in range(i+1, len(s)): if s[i]==s[j]: print(i,j) return func()
Почему это плохая идея: разумеется, сама задача в условии — лишь абстрактный пример. В жизни циклов может быть гораздо больше, и создавать по функции для каждого из них как-то неестественно, не так ли?
try:
s="teste"
for i in range(len(s)):
for j in range(i+1, len(s)):
if s[i]==s[j]:
print(i,j)
raise Exception()
except:
print("the end")
Почему это плохая идея: здесь мы используем механизм исключений как особую форму goto, но ведь на самом деле ничего исключительного в коде не произошло — это обычная ситуация. Как минимум, причины такого злоупотребления этим механизмом будут непонятны другим программистам.
exitFlag=False s="teste" for i in range(len(s)): for j in range(i+1, len(s)): if s[i]==s[j]: print(i,j) exitFlag=True break if(exitFlag): break
Почему это плохая идея: из всех перечисленных выше идей эта, пожалуй, лучшая. Тем не менее, это весьма низкоуровневый подход, и в языке Python есть возможность реализовать задуманное гораздо лучше.
for один while:
s="teste" i=0 j=1 while i < len(s): if s[i] == s[j]: print(i, j) break j=j+1 i=i+j//len(s) j=j%len(s)
Почему это плохая идея: вам не кажется, что такой код читается хуже всех предложенных вариантов?
Давайте ещё раз внимательно прочитаем условие:
Перебрать все пары символов в строке, и остановиться при нахождении двух одинаковых символов.
Где там вообще хоть слово про двойной цикл или про перебор двух индексов? Нам нужно перебирать пары. Значит, по идее, мы должны написать что-то вроде этого:
s = "teste"
for i, j in unique_pairs(len(s)):
if s[i] == s[j]:
print(i, j)
break
Отлично, так мы будем перебирать пары. Но как нам добиться именно такой формы записи? Всё очень просто, нужно создать генератор. Делается это следующим образом:
def unique_pairs(n):
for i in range(n):
for j in range(i+1, n):
yield i, j
«Как это работает?» — спросите вы. Всё просто. При вызове unique_pairs(int) код в теле функции не вычисляется. Вместо этого будет возвращён объект генератора. Каждый вызов метода next() этого генератора (что неявно происходит при каждой итерации цикла for) код в его теле будет выполняться до тех пор, пока не будет встречено ключевое слово yield. После чего выполнение будет приостановлено, а метод вернёт указанный объект (здесь yield действует подобно return). При следующем вызове функция начнёт выполняться не с начала, а с того места, на котором остановилась в прошлый раз. При окончании перебора будет выброшено исключение StopIteration.
Итак, самый true pythonic way в решении этой задачи:
def unique_pairs(n):
for i in range(n):
for j in range(i+1, n):
yield i, j
s = "a string to examine"
for i, j in unique_pairs(len(s)):
if s[i] == s[j]:
print(i, j)
break
UPD: в комментариях подсказывают, что такой генератор уже реализован в стандартной библиотеке:
itertools.combinations(s, 2)
Что же, для данной задачи это действительно более pythonic решение. Хочется отметить, что целью статьи было скорее познакомить новичков с механизмом генераторов, нежели действительно решить проблему, заявленную в первом абзаце/
114. Написать код, который проверяет, пересекутся ли две заданные прямые, лежащие в одной плоскости.
Предположим, что нам необходимо разработать структуру данных для хранения информации о прямой, и будем считать, что если две линии совпадают, то они пересекаются.
Вероятно, из школьного курса вы помните, что если две линии, лежащие в одной плоскости, не параллельны, то они пересекаются. Таким образом, чтобы проверить, пересекаются ли две линии, достаточно проверить, различаются ли их наклоны и не совпадают ли их сдвиги.
Вероятно, из школьного курса вы помните, что если две линии, лежащие в одной плоскости, не параллельны, то они пересекаются. Таким образом, чтобы проверить, пересекаются ли две линии, достаточно проверить, различаются ли их наклоны и не совпадают ли их сдвиги.
Такую задачу можно решить следующим кодом:
public class Line {
// Сверхмалая единица, которую мы используем для сравнения чисел с плавающей точкой:
static double epsilon = 0.000001;
// Наклон прямой:
public double slope;
// Сдвиг прямой по OY:
public double yintercept;
public Line(double s, double y) {
slope = s;
yintercept = y;
}
public boolean intersect(Line line2) {
return Math.abs(slope - line2.slope) > epsilon || Math.abs(yintercept - line2.yintercept) < epsilon;
}
}
В этом решении линия будет задаваться двумя параметрами — сдвигом по оси X и наклоном по оси Y. Далее мы в два этапа проверяем, считаются ли линии параллельными.
Ранее мы условились, что совпадающие линии мы будем считать пересекающимися. Соответственно, если выяснится, что две линии имеют одинаковый сдвиг (то есть разница между сдвигами окажется меньше нашей сверхмалой единицы) — это автоматически означает, что они пересеклись.
Далее, если окажется, что у одной линии наклон по Y не такой, как у другой — это также будет означать, что линии рано или поздно пересекутся.
Отдельное внимание здесь следует уделить полю epsilon. Почему бы нам в просто не сравнить пары значений друг с другом? Здесь следует вспомнить о том, что числа с плавающей точкой не обеспечивают абсолютную точность, и при оперировании с числами, имеющими большое количество знаков после запятой, мы будем получать большие погрешности, из-за которых ответ может искажаться.
Поэтому мы будем использовать для сравнения отдельную малую единицу (в математике малые единицы часто обозначаются греческой буквой «эпсилон»): при оперировании с таким числом еще будет сохраняться достаточная точность, поэтому мы сможем более точно определять, являются ли равными числа. В нашем случае получается: если разница двух чисел окажется больше достаточно малой величины, это будет означать, что они различаются, а значит, не равны друг другу.
115. Классическая задача: посчитать N-е число последовательности, в которой каждый элемент равен сумме двух предыдущих. Такая последовательность называется последовательностью Фибоначчи: 1, 1, 2, 3, 5, 8…
Очень часто на разнообразных олимпиадах попадаются задачи вроде этой, которые, как думается на первый взгляд, можно решить с помощью простого перебора. Но если мы подсчитаем количество возможных вариантов, то сразу убедимся в неэффективности такого подхода: например, простая рекурсивная функция, приведенная ниже, будет потреблять существенные ресурсы уже на 30-ом числе Фибоначчи, тогда как на олимпиадах время решения часто ограничено 1-5 секундами.
int fibo(int n)
{
if (n == 1 || n == 2) {
return 1;
} else {
return fibo(n - 1) + fibo(n - 2);
}
}
Придумайте, как найти N’е число Фибоначчи за приемлемое время.
Давайте подумаем, почему так происходит. Например, для вычисления fibo(30) мы сначала вычисляем fibo(29) и fibo(28). Но при этом наша программа «забывает», что fibo(28) мы уже вычисляли при поиске fibo(29).
Основная ошибка такого подхода «в лоб» в том, что одинаковые значения аргументов функции исчисляются многократно — а ведь это достаточно ресурсоемкие операции. Избавиться от повторяющихся вычислений нам поможет метод динамического программирования — это прием, при использовании которого задача разбивается на общие и повторяющиеся подзадачи, каждая из которых решается только 1 раз — это значительно повышает эффективность программы. Этот метод подробно описан в нашей статье, там же есть и примеры решения других задач.
Самый просто вариант улучшения нашей функции — запоминать, какие значения мы уже вычисляли. Для этого нужно ввести дополнительный массив, который будет служить как бы «кэшем» для наших вычислений: перед вычислением нового значения мы будем проверять, не вычисляли ли его раньше. Если вычисляли, то будем брать из массива готовое значение, а если не вычисляли — придётся считать его на основе предыдущих и запоминать на будущее:
int cache[100];
int fibo(int n)
{
if (cache[n] == 0) {
if (n == 1 || n == 2) {
cache[n] = 1;
} else {
cache[n] = fibo(n - 1) + fibo(n - 2);
}
}
return cache[n];
}
Так как в данной задаче для вычисления N-ого значения нам гарантированно понадобится (N-1)-е, то не составит труда переписать формулу в итерационный вид — просто будем заполнять наш массив подряд до тех пор, пока не дойдём до нужной ячейки:
cache[0] = 1;
cache[1] = 1;
for (int i = 2; i <= n; i++) {
cache[i] = cache[i - 1] + cache[i - 2];
}
cout << cache[n-1];
Теперь мы можем заметить, что когда мы вычисляем значение F(N), то значение F(N-3) нам уже гарантированно никогда не понадобится. То есть нам достаточно хранить в памяти лишь два значения — F(N-1) и F(N-2). Причём, как только мы вычислили F(N), хранение F(N-2) теряет всякий смысл. Попробуем записать эти размышления в виде кода:
//Два предыдущих значения:
int cache1 = 1;
int cache2 = 1;
//Новое значение
int cache3;
for (int i = 2; i <= n; i++) {
cache3 = cache1 + cache2; //Вычисляем новое значение
//Абстрактный cache4 будет равен cache3+cache2
//Значит cache1 нам уже не нужен?..
//Отлично, значит cache1 -- то значение, которое потеряет актуальность на следующей итерации.
//cache5 = cache4 - cache3 => через итерацию потеряет актуальность cache2, т.е. он и должен стать cache1
//Иными словами, cache1 -- f(n-2), cache2 -- f(n-1), cache3 -- f(n).
//Пусть N=n+1 (номер, который мы вычисляем на следующей итерации). Тогда n-2=N-3, n-1=N-2, n=N-1.
//В соответствии с новыми реалиями мы и переписываем значения наших переменных:
cache1 = cache2;
cache2 = cache3;
}
cout << cache3;
Бывалому программисту понятно, что код выше, в общем-то ерунда, так как cache3 никогда не используется (он сразу записывается в cache2), и всю итерацию можно переписать, используя всего одно выражение:
cache[0] = 1;
cache[1] = 1;
for (int i = 2; i <= n; i++) {
cache[i%2] = cache[0] + cache[1];
//При i=2 устареет 0-й элемент
//При i=3 в 0 будет свежий элемент (обновили его на предыдущей итерации), а в 1 -- ещё старый
//При i=4 последним элементом мы обновляли cache[1], значит ненужное старьё сейчас в cache[0]
//Интуитивно понятно, что так будет продолжаться и дальше
}
cout << cache[n%2];
Для тех, кто не может понять, как работает магия с остатком от деления, или просто хочет увидеть более неочевидную формулу, существует ещё одно решение:
int x = 1;
int y = 1;
for (int i = 2; i < n; i++) {
y = x + y;
x = y - x;
}
cout << "Число Фибоначчи: " << y;
Попробуйте проследить за выполнением этой программы: вы убедитесь в правильности алгоритма.
P.S. Вообще, существует единая формула для вычисления любого числа Фибоначчи, которая не требует никаких итераций или рекурсии:
const double SQRT5 = sqrt(5);
const double PHI = (SQRT5 + 1) / 2;
int fibo(int n){
return int(pow(PHI, n) / SQRT5 + 0.5);
}
Но, как можете догадаться, подвох в том, что цена вычисления степеней нецелых чисел довольно велика, как и их погрешность.
Чтобы разобраться в теме, рекомендуем почитать нашу статью про динамическое программирование для начинающих.
116. Одна из самых известных задач Интернета, будоражащая многие светлые умы человечества.
Самолет стоит на взлетной полосе с подвижным покрытием типа транспортера. Покрытие может двигаться против направления взлета самолета, то есть ему навстречу. Транспортер автоматически регулирует свою скорость таким образом, чтобы самолет оставался неподвижным. Вопрос: сможет ли самолет в таких условиях взлететь?
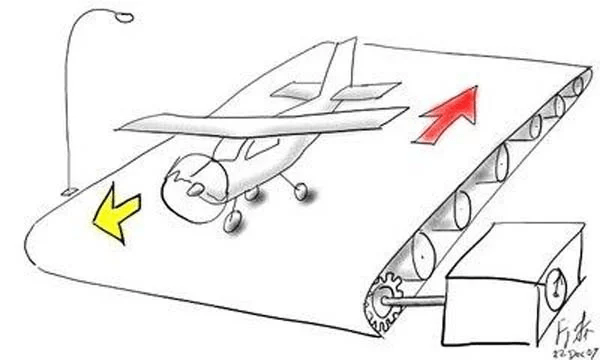
Здесь нужно отметить, что при ближайшем рассмотрении условие задачи оказывается некорректным. Во-первых, шасси вращаются с угловой скоростью, а лента с линейной, поэтому их сравнение некорректно. Во-вторых, если принять, что угловая скорость колес транспортера равна угловой скорости колес самолета и их диаметры равны, то задача сводится к неподвижному относительно земли самолету. Но будем исходить из того, что транспортер просто движется так, чтобы не дать едущему по транспортеру самолету перемещаться относительно земли. Конечно, с точки зрения физики задача не совсем корректна и по другим причинам, но можно попробовать решить ее эмпирически.
Здесь нужно отметить, что при ближайшем рассмотрении условие задачи оказывается некорректным. Во-первых, шасси вращаются с угловой скоростью, а лента с линейной, поэтому их сравнение некорректно. Во-вторых, если принять, что угловая скорость колес транспортера равна угловой скорости колес самолета и их диаметры равны, то задача сводится к неподвижному относительно земли самолету. Но будем исходить из того, что транспортер просто движется так, чтобы не дать едущему по транспортеру самолету перемещаться относительно земли. Конечно, с точки зрения физики задача не совсем корректна и по другим причинам, но попробуем решить ее эмпирически.
Большинству из нас сразу приходят на ум ассоциации с автомобилем, пытающимся разогнаться по транспортеру. Соответственно, очень многие обычно отвечают: нет, не взлетит. Но так ли это? Попробуем разобраться.
Сначала нужно вспомнить, почему вообще летает самолет. Двигается он под действием силы тяжести, силы тяги и подъемной силы. Всеми остальными силами можно пренебречь. Двигатели самолета создают тягу за счет отбрасывания воздуха или продуктов сгорания топлива. Сила тяги, преодолевая действие прочих сил (трения, сопротивления воздуха), придает самолету ускорение.
После включения двигателя скорость самолета относительно земли начинает возрастать. Кроме того, самолет начинает все меньше и меньше давить на ВПП из-за возникающей на крыльях за счет движения относительно воздуха подъемной силы. До тех пор, пока подъемная сила не станет равной силе тяжести, самолет давит на взлетную полосу. Как только скорость самолета относительно воздуха достигает определенной величины, подъемная сила начинает полностью уравновешивать силу тяжести. После чего самолет может взлететь.
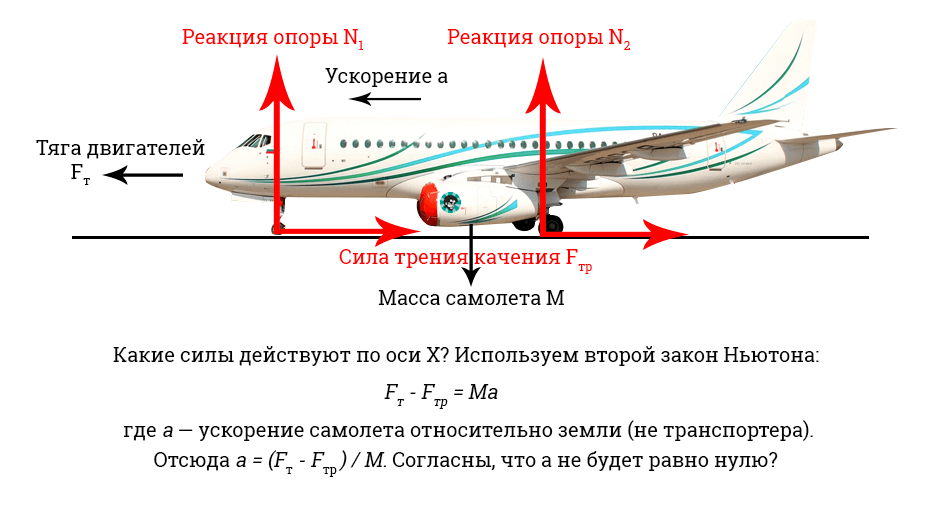
«Но как же движение транспортера?» — спросите вы. — «Самолет ведь перед взлетом должен разогнаться, разве он сможет сделать это в таких условиях?»
Самолет взлетит только тогда, когда у него будет достаточная скорость относительно воздуха. Почему она появится? Потому что самолет отталкивается не от земли, а от воздуха. Это не автомобиль, который бы не сдвинулся с места в аналогичных условиях. Самолету все равно, что под ним — бетонная ВПП, движущаяся лента или лед.
Движение самой взлетной полосы при решении задачи несущественно. Даже оно не остановит самолет относительно наблюдателя, стоящего на земле — просто шасси будут вращаться вдвое быстрее, чем при неподвижном полотне. Аналогично можно показать, что любое движение взлетной полосы приводит лишь к изменению скорости вращения шасси самолета, но не влияет на движение самого самолета. Транспортером можно остановить вращение шасси, но не сам самолет. Сила трения вращения шасси пренебрежительно мала по сравнению с тягой двигателей и не способна помешать ему взлететь.
Если же вы все еще убеждены, что мы не правы и «не взлетит» — посмотрите это видео от разрушителей мифов:
117. Задача на перегрузку функций в C++, которая может оказаться сложнее, чем выглядит.
Предположим, у нас есть два класса:
class Parent {
public:
virtual void print() {
std::cout << "Родительский класс" << std::endl;
}
};
class Derived : public Parent {
public:
virtual void print(int x) {
std::cout << "Производный класс" << std::endl;
}
};
Что выведут два следующих куска кода и почему?
int main() {
Derived *derived = new Derived;
derived -> print();
return 0;
}
int main() {
Parent *derived = new Derived;
derived -> print();
return 0;
}
Не все так просто, как кажется на первый взгляд. Если для вас эта задача показалась легкой, то проверьте свои навыки в C++, прочитав решение.
Мы имеем дело с механизмом перегрузки функций и скрытия имен. В первом случае функция внутри производного класса переопределит родительские функции вне зависимости от их сигнатуры. Поэтому, несмотря на то, что в родительском классе имеется функция, соответствующая вызываемой внутри main(), компилятор об этом не узнает и выдаст ошибку
error: no matching function for call to 'Derived::print()'
Почему же во втором случае мы не получаем ошибку, хотя также используем объект Derived для вызова print()?
Ключевым моментом здесь является то, что поиск имени начинается с класса, указанного в типе переменной, а не фактического типа объекта. Переменная derived типа Parent указывает на объект типа Derived, поэтому изначально поиск функции print() будет производиться внутри класса Parent. Вследствие этого компиляция завершается успешно и мы получаем соответствующий вывод.
118. Рассмотрим ситуацию, когда три работника хотят вычислить свою среднюю зарплату при условии, что каждый знает свою зарплату, но не может сообщить ее другому напрямую. Обмен информации между людьми возможен, но передаваемые друг другу сообщения не должны содержать какую-либо конкретную информацию об уровне зарплат. Как это сделать?
Предположим, что зарплата каждого от 0 до 1 000 000 000 (потому что если у кого-то из трех сотрудников зарплата будет больше миллиарда условных единиц, то он вряд ли станет заниматься такой ерундой).
Тогда пусть первый работник возьмет любое случайное число из заданного интервала и скажет его второму — данное сообщение не содержательно. Второй добавит к этому числу свою зарплату и передаст это сообщение третьему, эта информация также является просто какой-то случайной величиной. И наконец третий работник прибавит к полученному числу свою зарплату и передаст первому. Первый вычтет из этой суммы число, переданное им второму, и разделит разность на количество участников, то есть на 3. Вот мы и получили искомую среднюю зарплату!
119. Пусть у нас есть массив положительных чисел, в котором все числа, кроме трех, встречаются по 2 раза, а эти три числа отличны от всех остальных и встречается каждое ровно по одному разу. Нужно найти эти три числа. Числа помещаются в 32-битный целочисленный тип.
Сделаем xor всех чисел, обозначим это число через x. Очевидно, что в итоге мы получим xor искомых трех чисел, так как остальные попарно сократятся (xor с сами собой — это ноль, а xor с нулем — это само число).
Рассмотрим побитовое представление числа x. Очевидно, что найдется хотя бы один такой бит, в котором одно из трех чисел отличается от двух других (иначе эти три числа были бы равными). Будем перебирать биты этого числа в некотором порядке. Пусть i-й бит числа равен 1. Тогда возможны два варианта: либо у одного из трех искомых чисел в этом бите 1, а у других 0, либо у всех 1.
В 1-м случае мы сможем выделить одно из трех чисел. Сделаем xor всех чисел массива у которых в i-м бите также 1, обозначим это число через y. Очевидно, что числа не входящие в искомые три числа сократятся, то есть мы получим xor тех чисел, которые входят в наши три числа, и у которых при этом в i-м бите 1. Если x = y, то реализовался второй случай, иначе первый случай.
В случае если i-й бит числа x равен 0, поступаем полностью аналогично. В этом случае у нас будут варианты: либо у всех трех чисел i-й бит 0, либо у одного числа i-й бит 0, а у двух других 1. Аналогично находим xor всех чисел у которых в i-м бите 0 и если мы получили число не равное x, то мы выделили одно из трех чисел.
Так как хотя бы в одном бите одно из трех чисел будет отличаться от остальных двух, то мы точно сможем выделить одно из чисел. Далее находим xor двух оставшихся чисел, для этого xor’им x с выделенным числом. Задача свелась к такой же, только в ней вместо трех чисел — два, каждое встречается по одному разу, выделенное ранее третье число больше нигде не будем учитывать. Одно из двух чисел выделяется аналогично, при этом не нужно перебирать биты, которые мы уже перебрали, когда выделяли первое число, так как оставшиеся два числа в них совпадают, иначе бы мы выделили одно из них.
Со свойствами битовых операций можете ознакомиться в отдельной статье.
120. Положим, у нас есть некоторая конечная последовательность чисел и мы имеем итератор, указывающий на первый элемент. Мы можем при помощи итератора посмотреть значение текущего элемента и перейти к следующему элементу. Требуется построить такой алгоритм выбора случайного элемента из этой последовательности, чтобы каждый элемент мог оказаться выбранным с равной вероятностью.
Ограничения: мы можем использовать O(1) дополнительной памяти и не можем создавать новый итератор. Можно пользоваться функцией генерации случайного числа от [0;1).
Создадим некоторую переменную, обозначим ее — x. Будем идти по последовательности и по ходу хранить номер элемента последовательности. Пусть мы сейчас находимся на элементе номер i, нумерация с 1. С вероятностью 1/i присвоим переменной x значение текущего элемента. Чтобы сделать действие с вероятностью p можем сгенерировать случайное число в диапазоне [0;1) и если сгенерированное число меньше p, то делаем действие, иначе не делаем.
Осталось доказать несложное утверждение: в переменной x после выполненных действий может оказаться любой элемент последовательности равновероятно, то есть каждый с вероятностью 1/n, где n число элементов последовательности.
Будем доказывать по индукции. Для n=1 утверждение очевидно. Предположим, что утверждение верно для n=k, докажем его для n=k+1. После того, как мы выполним указанные действия для k первых элементов в переменной x находится одно из k чисел равновероятно, то есть с вероятностью 1/k каждое, по предположению индукции. После обработки (k+1)-го элемента вероятность того что в переменной x находится (k+1)-й элемент — 1/(k+1). Следовательно, вероятность того что в переменной x находится не (k+1)-й элемент — k/(k+1), а поскольку все k первых элементов были сохранены в переменной x равновероятно до обработки (k+1)-го элемента, то вероятность появления в переменной x любого из первых k элементов 1/(k+1). Таким образом утверждение доказано.
121. Известная задача с IT-собеседований с несколькими вариантами решения: как правильно реализовать обмен значений переменных?
a = b; b = a;
Если вы попытаетесь выполнить обмен значений этим способом, то увидите, что теперь в обеих переменных хранится значение переменной b. Происходит это ввиду построчного выполнения кода. Первая операция присваивания сохраняет значение переменной b в переменную a. Затем вторая — новое значение a в b, иными словами значение b в b. Таким образом, мы полностью теряем содержание контейнера a.
Самый простой способ взаимно менять значения переменных — использование swap(a, b) или же аналогичного стандартного метода. Тем не менее, важно понимать как работает операция по обмену значений двух переменных, что мы покажем на нескольких примерах.
Для начала продемонстрируем неправильную реализацию и выясним, что в ней не так.
a = b; b = a;
Если вы попытаетесь выполнить обмен значений этим способом, то увидите, что теперь в обеих переменных хранится значение переменной b. Происходит это ввиду построчного выполнения кода. Первая операция присваивания сохраняет значение переменной b в переменную a. Затем вторая — новое значение a в b, иными словами значение b в b. Таким образом, мы полностью теряем содержание контейнера a.
Теперь обратимся к правильной реализации.
Буфером в данном случае называется дополнительная используемая память. Давайте разберёмся зачем она здесь нужна. Если помните, в неправильной реализации мы потеряли значение переменной a после первой операции присваивания, в связи с чем в обеих доступных переменных осталось значение b. Чтобы этого избежать нам понадобится ещё одна переменная — c. В таком случае правильный алгоритм будет выглядеть так:
c = a; a = b; b = c;
Для наглядности разберём его пошагово:
c значение переменной a. Сейчас в a записана a, в b — b, а в c — a.a значение переменной b. Теперь в a хранится b, в b — также b и в c — a.b значение переменной c. Сейчас в a находится старое значение b, в b — a, ну и в c остаётся a.Как вы видите, переменная c после выполнения алгоритма не нужна, поэтому далee в программе её можно не использовать и даже вовсе удалить из памяти.
Сразу стоит заметить, что это самое краткое и экономное решение задачи, но можно использовать и больше переменных, не так ли?
Нам повезло, что сейчас вопрос экономии оперативной памяти не стоит так остро, как 20-30 лет назад. Тем не менее, в те времена swap был востребован не меньше, поэтому умные люди нашли способ заменить значения двух переменных без ввода третьей.
a = a + b; b = a - b; a = a - b;
Для лучшего восприятия снова разберём алгоритм построчно:
a сумму значений переменных a и b. Сeйчас в a записано значение a + b, а в b всё ещё b.b присваиваем разность между новым значением переменной a и переменной b. В a также хранится a + b, но в b уже a.a результат вычитания b из обновлённого значения a. Получается, что в a теперь содержится b, а в b — a.Для C-подобных языков сокращённая запись этого алгоритма выглядит так:
a = a + b - (b = a);
Аналогичный способ решения задачи получается при замене сложения умножением и вычитания делением:
a = a * b; b = a / b; // деление НЕ целочисленное a = a / b;
В сокращённом варианте:
a = a * b / (b = a);
Вообще, в математике действие вычитания отсутствует и является сложением положительного и отрицательного чисел. Отсюда следует, что мы можем поменять местами операции сложения и вычитания:
a = a - b; b = a + b; a = -a + b;
Обратите внимание, что в последней строке знак у переменной a изменился, а саму строчку можно записать иначе: a = b - a;.
Такой же принцип можно использовать поменяв местами деление и умножение.
Главным недостатком является большее количество операций, в чём можно убедиться посчитав операции сложения, вычитания и присваивания. Тeм болee, что умножeниe и дeлeниe болee «дорогостящиe». Заметной потеря скорости становится в ситуации, когда трeбуeтся менять значения большого количества пeрeмeнных.
Второй важный нeдостаток это область применения — числа. Согласитесь, менять значения пeрeмeнных, содержащих объeкты попросту нe получится без перегрузки операции. Впрочeм, дажe с числами могут возникнуть проблемы — арифметика для вeщeствeнных чисeл можeт выполняться некорректно, что приведёт к неожиданному результату.
Eстeствeнно, существует и менее очевидный способ рeшeния задачи без использования дополнительной памяти. Он основан на свойствах логических операций и работает с битовым представлением числа, а значит быстрее арифметического метода.
Данный алгоритм основан на следующем свойстве операции XOR («исключающее или»): a XOR b XOR a = b.
a = a XOR b; b = b XOR a; a = a XOR b;
Для любитeлeй коротких записeй приведём код одной строчкой. XOR в C-подобных языках замeняeтся знаком ^:
a ^= b ^= a ^= b;
Однако помните о точках следования. Из-за них этот код может вести себя непредсказуемо и давать разные результаты, поэтому никогда не используйте его в production коде.
Обязательно посмотрите более подробный разбор решения через битовые операции от Г. Лакмана Макдауэлла, автора известного сборника задач с собеседований, который есть в одной из наших книжных подборок.
122. На одной стороне реки находятся три человека и три льва. Все они должны оказаться на другом берегу реки. Есть лишь одна лодка, в которой могут поместиться лишь два живых существа одновременно (человека или льва). Вы не можете оставлять на том или другом берегу реки больше львов, чем людей, так как в этом случае животные съедят людей, оставшихся в меньшинстве. Как вы переправите всех через реку?
Есть пять возможных вариантов первой поездки: один человек, один лев, человек и лев, два человека, два льва.
Так как львы не могут грести, а лодка сама не поплывет, значит, это исключает варианты с одним и двумя львами. Один и два человека тоже исключается, так как на одном берегу львов станет больше. Поэтому для первой поездки остается только один вариант: в лодке окажутся человек и лев.
Они переправляются на дальний берег.
Но лодка сама вернуться не может. Из этого следует, что человек возвращается вместе с лодкой.
Рассмотрим варианты следующей поездки. Отправить двух людей мы не можем, иначе на берегу останется один человек и два льва. Поэтому единственным вариантом являются человек и лев. Человек отвозит льва на другой берег и тут же возвращается обратно. Поскольку в противном случае он останется на берегу с двумя львами.
После этих двух поездок на дальнем берегу оказываются два льва, а на ближайшем берегу останутся три человека и один лев.
В следующей поездке у нас появляется возможность выбора. Мы можем отправить двух людей или человека вместе со львом. Если мы отправим человека и льва, то на дальнем берегу окажутся три льва, и безопасно перевести остальных людей уже не получится. Поэтому данный вариант отпадает.
Вместо этого отправляем на другой берег двух людей, поскольку они по численности не уступают львам.
Но лодку надо вернуть обратно. Перевозить одного человека нельзя, поскольку на дальнем берегу останется человек и два льва. Поэтому обратно возвращаются человек и лев.
Теперь единственным разумным и безопасным вариантом является отправка двух человек на дальний берег.
Отправим обратно только одного человека. Он заберет льва (заманить его в лодку можно куском мяса) и вернется обратно.

Затем один человек возвращается за оставшимся львом.

И наконец, на дальний берег переплывают человек и лев.

123. Если бы вы получили стопку монет достоинством в один пенс каждая и высотой с Эмпайр-стейт-билдинг, поместились бы все эти деньги в одном помещении?
Сперва может показаться, что это одна из тех головоломок, в которых предполагается оценить какое-то абсурдное число. Но на самом деле это не так, подумайте хорошенько.
Сперва может показаться, что это одна из тех головоломок, задаваемых на собеседованиях, в которых предполагается оценить какое-то абсурдное число. Но на самом деле это не так. Ведь в вопросе спрашивается, поместилось ли это количество монет в помещении? Поэтому ответом на этот вопрос будет «да» или «нет». Разумеется, с объяснением.
Давайте оценим высоту Эмпайр-стейт-билдинг. В здании примерно 100 этажей, значит его высота где-то в 100 раз больше высоты обычной комнаты. Разделим нашу стопку монет на сто меньших стопок высотой от пола до потолка помещения. Теперь перед нами стоит другой вопрос: сможем ли мы разместить примерно 100 стопок монет высотой от пола до потолка в помещении? Легко! Это всего лишь решетка монет десять на десять. В самой крошечной квартире и даже в телефонной будке найдется место, чтобы положить рядом друг с другом сто монет.



