
Тендеры и лиды
Информация


Основные тезисы:
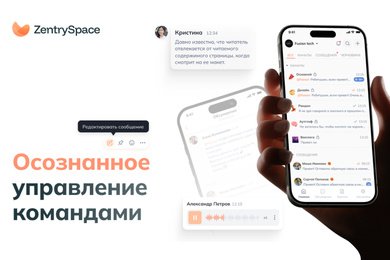
Схема извлечения векторных вложений из любого типа контента
А теперь разберем тему более подробно.
Веб-сайт представляет собой массив неструктурированных и полуструктурированных данных. Обычная страничка сайта изначально представляла собой чисто визуальную презентацию какого-то контента, без разделения на значимые и легко определяемые зоны. Такой документ может быть понятен человеку, но не машине: она не знает, где здесь что, на что обращать внимание, а что имеет случайный характер.
Несколько упростила оптимизацию контента для поисковых систем интеграция микроразметки. С помощью метаданных Schema.org можно указать поисковому роботу, какого типа страница представлена, например – какой товар, сколько стоит, сколько их в наличии, кто продавец, где тут изображение этого товара и т.п. Даже полуструктурированные данные такого рода сильно упрощают машиночитаемость контента и снимают необходимость писать уникальные описания, добавлять ненужный в принципе контент и т.п.
Для того, чтобы понять смысл страницы, поисковые системы изначально использовали опору на ключевые слова, выявляемые с помощью алгоритмов, основанных на частотности термина в основном контенте документа (как пример – TF-IDF и BM25), метатегах и текстах ссылок. Такие модели представляют собой очень разреженные двухмерные матрицы. Рассмотрим этот вопрос подробнее.
Разреженные двумерные матрицы представляют собой структуры данных, в которых большинство элементов имеют нулевые значения. В контексте SEO и обработки естественного языка такие матрицы играют фундаментальную роль, особенно при работе с моделью TF-IDF (Term Frequency-Inverse Document Frequency). Когда мы анализируем тексты для SEO, мы сталкиваемся с тем, что любой отдельный документ содержит лишь малую часть всех возможных слов языка. Если представить корпус документов как матрицу, где строки — это документы, а столбцы — уникальные слова (термины), то получится классическая разреженная матрица, заполненная преимущественно нулями.
Рассмотрим пример. Предположим, у нас есть коллекция из 1000 страниц сайта, и мы анализируем 50,000 уникальных слов. Матрица TF-IDF будет иметь размер 1000×50,000, но каждая страница, вероятно, содержит лишь несколько сотен, а то и десятков уникальных слов. Это означает, что более 99% элементов матрицы будут нулевыми — классический случай разреженной матрицы.
Таким способом можно определить самые весомые ключевые слова, характеризующих содержание страницы, обнаружить лексически похожие документы, выявить тематические кластеры на сайте и проанализировать страницы конкурентов. Например, SEO-специалист может сравнить матрицу TF-IDF своей страницы с матрицами конкурентов, чтобы выявить термины, которые отсутствуют или недостаточно представлены на его странице.
Для примера: представим, что у нас есть три страницы:
После токенизации и подсчета TF-IDF, получим разреженную матрицу, где, например, слово "SEO" будет иметь высокие значения для страниц 1 и 2, но нулевое значение для страницы 3. А слово "контент-маркетинг" получит высокие значения для страниц 1 и 3.
Именно эта разреженность позволяет алгоритмам поисковых систем эффективно индексировать миллиарды документов и находить релевантные результаты за миллисекунды, а SEO-специалистам — анализировать и оптимизировать контент для лучшего ранжирования. Однако такой подход не способен работать с реальным смыслом и его легко обмануть простейшими средствами текстового и ссылочного спама. Всё, что могут частотные алгоритмы – отобрать документы, где встречаются заданные ключевые слова, и определить, насколько важен заданный ключевик для конкретного документа.
Если простейшие частотные алгоритмы учитывали только двумерные матрицы («есть токен» - «нет токена») и не могли работать со смыслом, то начиная с алгоритма word2vec и его модификаций у поисковых систем появилась возможность более точно понимать смысл документа. Word2vec преобразует слова в векторы фиксированной размерности (обычно от 100 до 300 измерений), где каждый элемент вектора содержит некоторое ненулевое значение. Большинство элементов в этих векторах значимы и несут семантическую информацию о слове. Что это значит на практике?
Обученная модель Word2vec преобразует слова в векторы фиксированной размерности (обычно от 100 до 300 измерений), где каждый элемент вектора содержит некоторое ненулевое значение. В качестве измерений выступают какие-то семантические связи, характеризующие слово в многомерном пространстве смысла.
Рассмотрим гипотетический пример того, как модель word2vec может представлять слова «Дональд Трамп» и «осина» в многомерном семантическом пространстве, где значение "1" означает полное совпадение, а "-1" - противоположность. Предположим, у нас есть векторы размерности 300, но оценим только 10 измерений для наглядности.
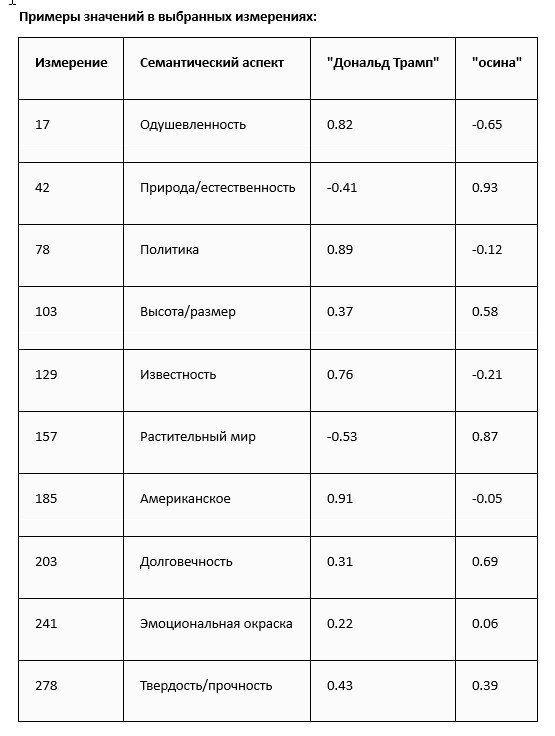
Что всё это значит? – Косинусное расстояние между этими векторами будет большим, так как слова относятся к совершенно разным семантическим областям.
В реальной модели word2vec эти значения были бы распределены по всем 300 измерениям, и конкретные измерения не имеют заранее заданной семантической интерпретации – эта семантика неявно возникает в процессе обучения на корпусе текстов. Представленный пример выглядит как игра "Что общего между Дональдом Трампом и осиной", но факт: алгоритм сумел найти некоторые точки соприкосновения даже в этом странном случае.
Наша система сама подберет вам исполнителей на услуги, связанные с разработкой сайта или приложения, поисковой оптимизацией, контекстной рекламой, маркетингом, SMM и PR.
Заполнить заявку
13359 тендеров
проведено за восемь лет работы нашего сайта.
Несмотря на все возможности, использование моделей word2vec всё ещё не позволяет говорить о полноценной работе со смыслом: речь идёт только о статистике совместно используемых n-грамм (слов и словосочетаний). Word2vec не учитывает контекст. Векторные вложения этой модели позволяют эффективно работать с определением тематики, более точно просчитывать релевантность, и на базе их – контекстуальную релевантность. Но не более того: модель не сможет оценить, отвечает ли текст на вполне определенный вопрос пользователя, а опора на статистику совместного использования слов позволяет использовать методики текстового спама. На этом основаны такие инструменты текстового анализа, как GAR и «Акварель-Генератор».
Традиционно SEO опиралось на относительно простые векторные представления слов: двухмерные модели и многомерные уровня word2vec. Все они представляют слова как статические векторы фиксированной длины, где каждое слово имеет одно единственное векторное представление. Не учитывается контекст употребления слова в предложении. Инструментарий, основанный на таких моделях, используется для самого базового семантического анализа и подбора ключевых слов.

Небольшой фрагмент матрицы, извлеченной с веб-страницы контекстной моделью
Современные языковые модели с глубокими контекстными представлениями кардинально изменили SEO-ландшафт. Модели-трансформеры представляют слова как динамические векторы, зависящие от контекста, понимают многозначность терминов и намерения пользователей. Они способны учитывать смысловые нюансы и тематические связи, анализировать контент на уровне документа, а не только отдельных слов. Приведем примеры таких трансформеров:
И т.п.
Контекстные модели всё активнее используются поисковыми системами. А это означает следующее:
В отличие от двухмерных моделей и word2vec, современные контекстные модели-трансформеры позволяют SEO-специалистам выйти за рамки простого подбора ключевых слов и создавать стратегии, ориентированные на глубокое понимание потребностей пользователей и тематической релевантности контента. Это привело к переходу от «оптимизации для поисковых систем» к «оптимизации для пользователей», что полностью соответствует эволюции поисковых алгоритмов.
Для начала вам понадобится доступ к модели-трансформеру, способной извлекать векторные вложения. Сделать это можно одним из широкодоступных способов:
Извлеченные данные, вероятно, будут представлять собой таблицу (csv), где каждому URL будет соответствовать массив чисел, матрица, где каждая строка — это контекстно-зависимое представление соответствующего токена.
Для отдельного токена (слова или части слова) вложение — это вектор, обычно содержащий от нескольких сотен до тысячи значений (например, 768 или 1024 числа в моделях типа BERT или GPT). Когда мы обрабатываем последовательность токенов (предложение, абзац и т.д.), каждый токен получает свой вектор-вложение, что в совокупности образует матрицу:
Глазами смотреть на это не имеет никакого смысла, если вам не встроили в голову достаточно сложный калькулятор. Вам понадобится хороший калькулятор в виде Python и его библиотек. И конечно же, вы должны понимать, какую задачу хотите решить с помощью векторных вложений. Вот самые типичные:
И даже если брать «чёрные» и «серые» методы продвижения – в ближайшем будущем можно ожидать серьёзные изменения и здесь:
Алгоритмы поисковых систем были и будут закрытой информацией. Вы не сможете точно воспроизвести их своими средствами. Однако доступ к современным большим языковым моделям позволяет с достаточно высокой точностью эмулировать эти алгоритмы для аналитики в рамках SEO.
Разумеется, во многих нишах текстовая релевантность и качество контента не является определяющим: если вы ищете необходимый вам товар по хорошей цене и у надёжного продавца – вам нет дела до текстового описания этого товара, вам не нужны статьи о его свойствах, истории, рассказ о бренде и т.п. Однако в сложных нишах, где потенциальному покупателю нужно сначала получить все ответы на вопросы без проработки контента не обойтись. И конечно же, это критически важно для информационных ресурсов, где смысл текста важнее всего прочего.
Если вы всё ещё думаете, что SEO – это тексты, напичканные ключевыми словами из поисковых запросов, покупка ссылок, правка «облака тегов» и тщательный подсчёт частотностей, выявление мифических LSI-ключей – время обновить инструментарий и пересмотреть свою практику.



