




Тендеры и лиды
Информация
За последние два года мы перестали замечать, сколько контента в интернете создают нейросети. Google фиксирует миллионы новых страниц каждый день, и значительная часть из них — продукт генеративных моделей. Создавать тексты стало быстрее и дешевле, но есть проблема, о которой пока говорят только исследователи.
Сегодня я хочу рассказать, почему неизбежен model collapse (коллапс ИИ-моделей), как это скажется на онлайн-контенте и что делать авторам и редакторам, чтобы не стать частью проблемы.
Исследователи Оксфорда и Кембриджа не так давно опубликовали в журнале Nature работу, которая впервые описала феномен коллапса ИИ-моделей очень подробно. Согласно научному определению, это деградация генеративных моделей при обучении на синтетических данных — то есть на текстах, изображениях или аудио, созданных другими нейросетями. Дело в том, что любая языковая модель постепенно теряет связь с реальным распределением данных, начинает выдавать однотипные ответы и чаще ошибается даже в тех областях, где раньше справлялась хорошо.
Проще говоря: если нейросеть постоянно "ест" собственные или чужие ИИ-тексты, она начинает "забывать" реальный мир. Можно провести аналогию с ксерокопией: если делать копию не оригинального документа, а его копии, изображение получится более размытым и блеклым. Другой пример — игра в сломанный телефон. Как мы знаем, к концу игровой цепочки исходная фраза меняется если и не до узнаваемости, то больше, чем на 30-40%. С нейросетями происходит то же самое, но в масштабах всего интернета.
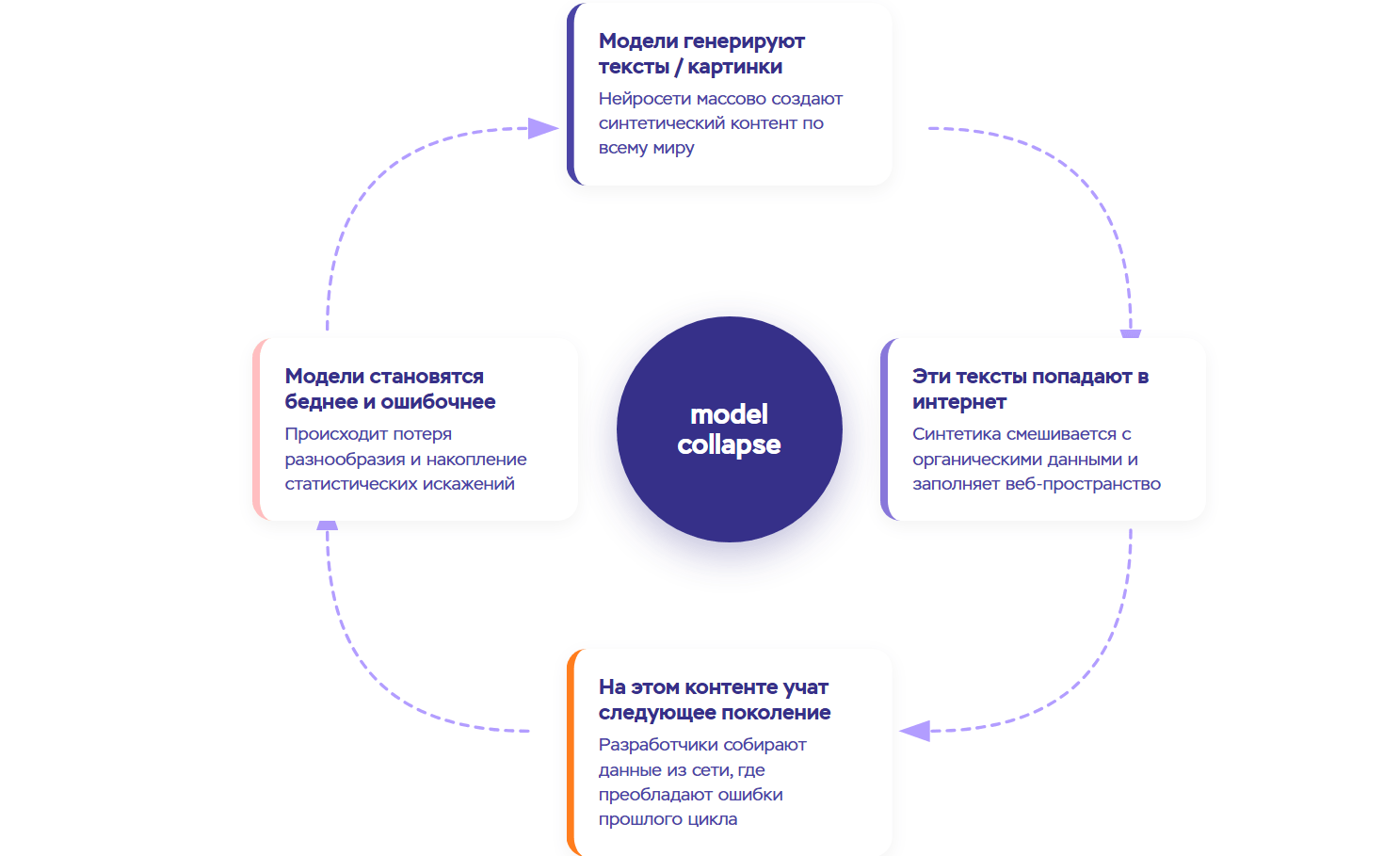
Каждый цикл обучения ИИ на текстах, сгенерированных предыдущими поколениями, ведет к упрощениям, однообразным формулировкам и ошибкам. Со временем всё это накапливается. При этом есть несколько характерных признаков — “симптомов” коллапса:
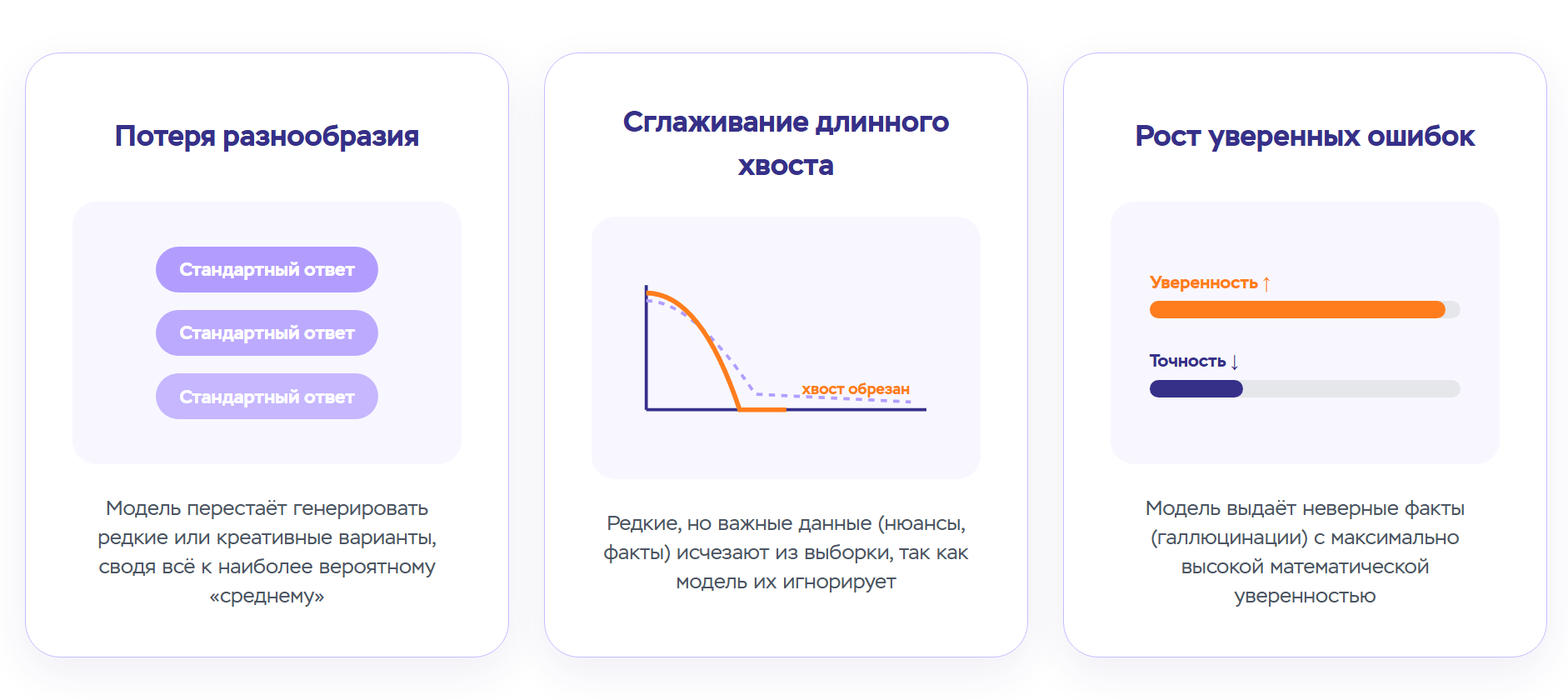
1. Потеря разнообразия. Модель перестает генерировать необычные, нестандартные ответы. Она выдает шаблонные фразы, повторяет одни и те же конструкции, избегает редких слов и специфических терминов.
2. Сглаживание "длинного хвоста". В статистике "длинным хвостом" называют редкие, но важные события — например, упоминания малоизвестных фактов, специализированную лексику, локальные культурные особенности. Модель, обученная на синтетических данных, постепенно забывает эти детали. Остаются только самые частые, усредненные паттерны. Можно сказать, что редкие знания исчезают первыми.
3. Рост уверенных, но неверных ответов. Модель начинает ошибаться чаще, но при этом звучит убедительно. Она может с апломбом утверждать что-то неправильное, потому что ее представление о мире исказилось. Это особенно опасно, когда пользователи доверяют ИИ и не проверяют факты.
Помимо ИИ-коллапса, исследователи недавно ввели еще один термин — расстройство "самопоедания" модели (model autophagy disorder). Это когда нейросети снова и снова потребляют собственные и чужие ИИ-выводы. В итоге каждое новое поколение языковых моделей неизбежно теряет либо качество (точность), либо разнообразие (полноту охвата), если не добавлять свежих и реальных данных. ИИ-каннибализм описывает по сути ту же проблему, что и коллапс, но более образно: модели "поедают" контент друг друга, постепенно деградируя.
Для узких и формализованных задач — например, распознавания цифр или классификации объектов на фото — ИИ-коллапс сейчас менее опасен. Там есть четкие правила, ограниченное пространство возможных вариантов. Но язык — это открытая система. Текст может быть написан бесконечным количеством способов, и каждая формулировка несет свой оттенок смысла.
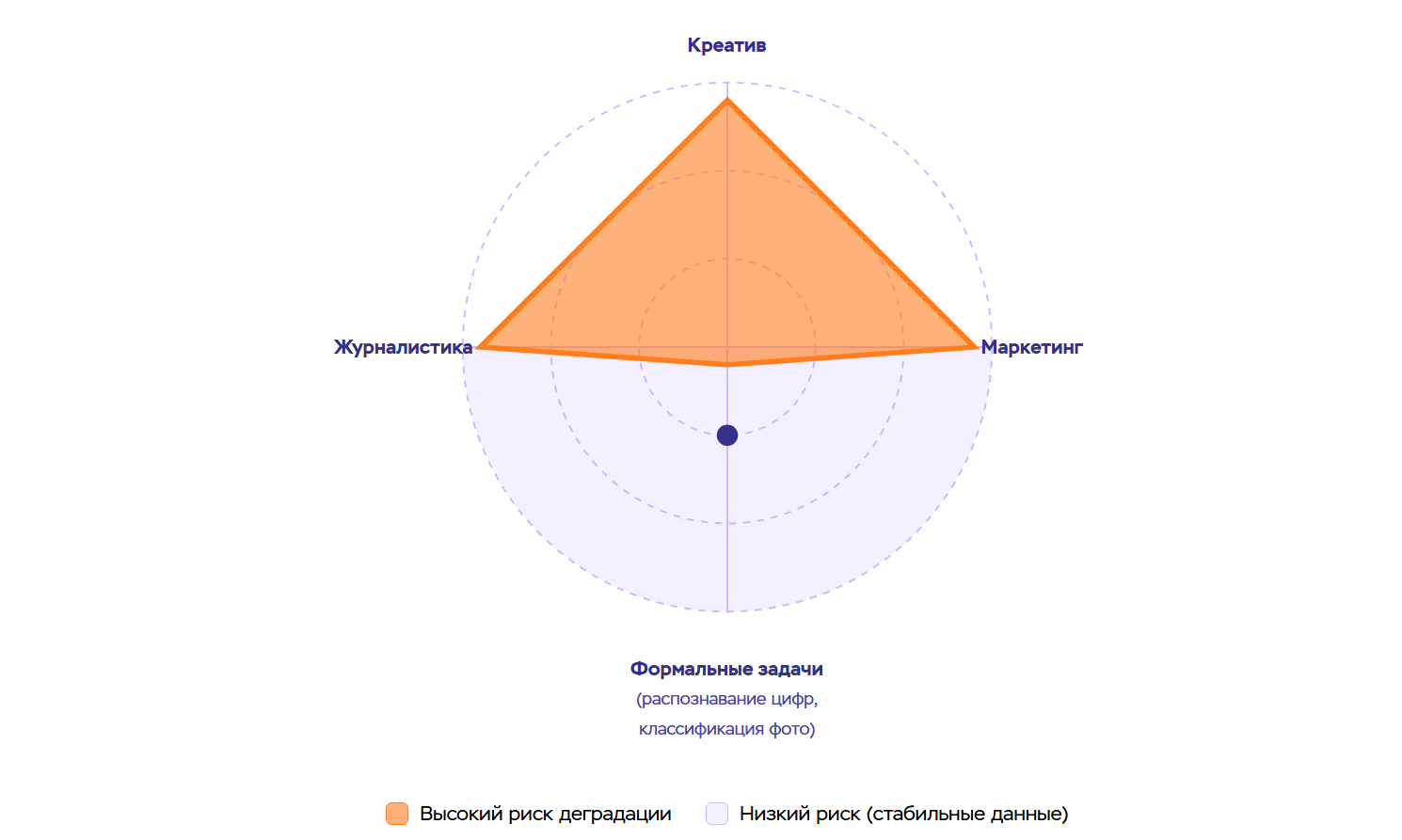
Креатив, маркетинг, журналистика — это области, где важна не только фактическая корректность, но и стиль, тон, культурный контекст. Именно здесь model collapse наносит максимальный урон, потому что убивает разнообразие и живость языка.
Давайте представим, что будет через несколько лет, если ничего не изменится.
Сценарий "интернет из клонов"
Итак, коммерческие сайты, личные блоги м медиа наполняются сгенерированным контентом. Копирайтеры используют нейросети для статей, компании автоматизируют создание товарных карточек, новостные агрегаторы публикуют ИИ-пересказы. Каждый текст — это перефразированная версия другого сгенерированного текста. В результате из контента исчезает голос бренда, личный опыт, нишевая экспертиза.
Для онлайн-пользователя это будет выглядеть как выбор без выбора. Заходишь в интернет поискать обзоры московских диджитал-агентств — а весь топ выдачи забит одинаковыми статьями. Одни и те же компании и преимущества. Это не плагиат в классическом смысле, поскольку слова везде разные, как и их порядок. Но это точно не приращение смыслов, чего ждет читатель.
Усиление информационного шума
Когда все пишут одинаково, найти действительно полезную информацию становится сложнее. Множатся поверхностные тексты, которые выглядят компетентно, но не несут реальной ценности. Алгоритмы поиска и сами ИИ-сервисы начинают учиться на этом шуме. Google и другие поисковики пытаются бороться с низкокачественным контентом, повышая в ранжировании проверенные источники — университеты, официальные организации, признанных экспертов. Но масштаб проблемы растет быстрее, чем возможности фильтрации.
Удар по доверию к поиску и ИИ
Пользователи начинают получать всё более однообразные ответы. Запросили информацию о редком медицинском заболевании — получили общие фразы, потому что специализированные данные потерялись в том самом длинном хвосте. Спросили про малоизвестный город — модель выдала стандартное описание, потому что забыла локальные детали.
В такой ситуации доверие неизбежно падает. Сначала только к ИИ, потом к авторам и брендам, которые его используют, потом и вовсе — к интернету. Парадокс: технология, призванная упростить наш доступ к общемировым знаниям, делает его всё сложнее.
Исчезновение "человеческого"
Реальные кейсы, эмпатия, неожиданная точка зрения, юмор — всё это сложно извлечь из статистики. Модель может воспроизвести структуру хорошей статьи, но не может вложить в нее живой опыт автора, который провел десятки интервью или сам прошел через проблему, о которой пишет. Когда интернет наполняется ИИ-текстами, уменьшается доля контента, который может вдохновить, удивить или дать по-настоящему полезный совет, основанный на практике.
Для нас всех сейчас очевидно, что именно копирайтинг — это та сфера, которая сейчас переживает жесткую трансформацию из-за ИИ. И model collapse может стать катализатором этих изменений.
Обесценивание массового копирайтинга
Тексты, написанные по шаблону с помощью ИИ, перестают выделяться. Если все используют ChatGPT для контента, материалы начинают звучать одинаково. Клиенты перестают читать подобное, потому что уже видели эти формулировки десятки раз. Контент становится фоновым шумом, а не инструментом привлечения внимания.
Когда мы приходим на большой рынок, каждый продавец выкрикивает нам одно и то же. Мы перестаем разбирать слова довольно быстро. Так и с текстами: если все копирайтеры используют одни и те же ИИ-инструменты и подходы, их работа теряет ценность.
Растущая конкуренция за внимание
Чтобы прорваться через океан однотипного ИИ-контента, копирайтерам приходится вкладывать больше усилий. Нужны уникальные истории, авторский стиль, глубокая экспертиза. Креативность и оригинальность снова становятся главными конкурентными преимуществами. Это хорошая новость для профессионалов, которые умеют не просто генерировать слова, а создавать смыслы. Но плохая — для тех, кто раньше выигрывать за счет своей скорости и объемов текста.

Риск профессиональной деградации
Если копирайтер работает только как "оператор промптов" — создает задачу для нейросети и сразу публикует либо поверхностно редактирует ИИшный текст — он рискует сам стать частью проблемы. Такой подход не требует глубоких знаний, творческого мышления или умения анализировать. А значит, со временем автор может потерять навыки, которые делают его ценным. Более того, если всё, что копирайтер делает, это перефразирует ИИ-контент, он участвует в создании синтетического шума, который как раз и отравляет “данные” для обучения будущих моделей.
Для бизнеса последствия model collapse еще серьезнее, чем для отдельных специалистов.
Падение трафика
ИИ-ответы в поиске забирают клики. Google и “Яндекс” всё чаще показывают сгенерированные ответы прямо в выдаче. Пользователь получает информацию, не переходя на сайт. Когда эти ответы начинают деградировать из-за коллапса, страдают и пользователи (получают неполную или неточную информацию), и сайты (теряют трафик).
Компании, которые вкладывались в SEO, видят снижение отдачи. Органический трафик падает не только из-за конкуренции, но и из-за того, что сами алгоритмы начинают работать хуже, обучаясь на “грязных” данных.
Наша система сама подберет вам исполнителей на услуги, связанные с разработкой сайта или приложения, поисковой оптимизацией, контекстной рекламой, маркетингом, SMM и PR.
Заполнить заявку
13507 тендеров
проведено за восемь лет работы нашего сайта.
“Безголосые” компании
Когда все бренды пишут одинаковыми "ИИ-голосами", становится труднее выстроить свое позиционирование. Ваша компания продает программное обеспечение? Конкурент тоже. Вы оба используете ChatGPT для написания статей в блог. Результат: тексты на ваших сайтах похожи как близнецы. Читатель не видит разницы, а значит, не может сформировать предпочтение. Он вас даже не запоминает.
Как ни крути, бренд — это не только логотип и слоган. Это голос, стиль, подход к коммуникации. Если всё это генерирует одна и та же модель по одним и тем же принципам, уникальность теряется. Как в таких условиях отстроиться от конкурентов и заявить о себе на рынке?
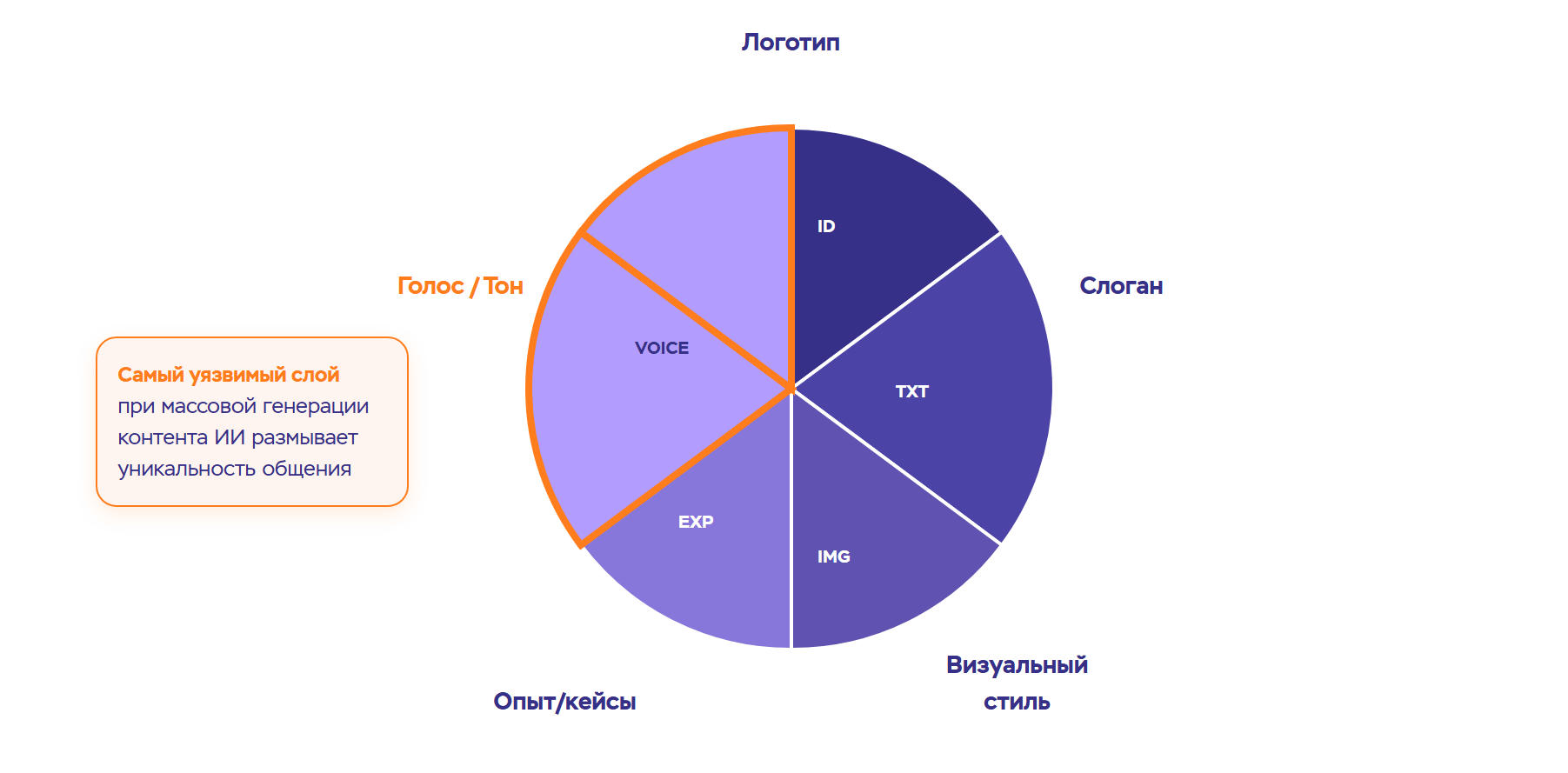
Важность доверия и экспертизы
В ответ на коллапс поисковые и ИИ-системы будут вынуждены искать способы выделять настоящий экспертный контент. Это значит, что текст, созданный проверенными специалистами на основе реального опыта, будет цениться выше.
Для брендов это сигнал инвестировать в настоящую экспертизу, а не в массовое производство текстов. Один хорошо проработанный кейс или глубокая аналитическая статья стоят больше, чем десятки поверхностных публикаций.
Что делать, если вы не хотите быть частью проблемы и хотите защитить свой контент от деградации?
Ставка на человеческий опыт
Реальный экспертный контент — это главная защита. Пишите на основе личной практики, собственных данных, интервью с реальными людьми. Кейсы, лонгриды, исследования, истории успеха — такой контент невозможно воспроизвести простым перефразированием или генерацией. Например, вместо общей статьи "как настроить контекстную рекламу" напишите разбор вашего проекта — с цифрами, ошибками, инсайтами, которые вы получили в процессе. Это уникально, потому что основано на конкретном опыте.
ВАЖНО: Ведите заметки по своей теме и используйте как основу для контента именно эту базу, а не общий "шум" из интернета. Можно создать, к примеру, документ с типичными проблемами ваших клиентов и решениями, которые вы предложили. Когда пишете статью, опирайтесь на этот файл, — получится уникальный и полезный контент.

Принцип "чистой тренировки"
Создавайте и публикуйте тексты, которые могут служить качественными исходными данными для будущих моделей. Не переработка чужого ИИ-контента, а оригинальный материал с проверенными фактами и четкой логикой. Если интернет наполнится высококачественным контентом, будущие модели будут лучше, а значит, и ваши собственные инструменты (поиск, аналитика, помощники) станут эффективнее.
Отдельно хочется остановится на авторском стиле. Тренируйте голос бренда или свой личный тон. У вас может быть особая манера объяснять сложное простым языком, использовать определенные метафоры, задавать вопросы читателю, шутить. ИИ сложнее воспроизводить подобные нюансы, а значит, ваш текст выделится на фоне генераций.

Микс: как разумно сочетать ИИ и человека
ИИ — это инструмент, а не замена автору. Используйте его для черновиков, генерации идей, структурирования мыслей. При этом, чтобы не превращать нейросеть в генератор шаблонов, соблюдайте простые правила в работе:
1. Продвинутый промптинг. Простая инструкция всегда дает примитивный ИИ-результат. Если же задать роль, добавить контекст, указать ограничения и привести примеры желаемого стиля, ответ нейросети будет лучше. Хороший промпт — это мини-бриф для ИИ. Чем детальнее вы опишете задачу, тем меньше вероятность получить шаблонный текст.
2. "Обогащение" ИИ-текстов. Контент всегда должен проходить через человеческий фильтр. В содержательном смысле — это добавление малоизвестных фактов, цитат, живых деталей, визуальных примеров или свежих инсайтов рынка. Это превращает любой безликий ИИ-текст в полезный материал. Не менее важны проверка логики и стиля у любого сгенерированного контента, а также вычитка на недочеты в грамматике.
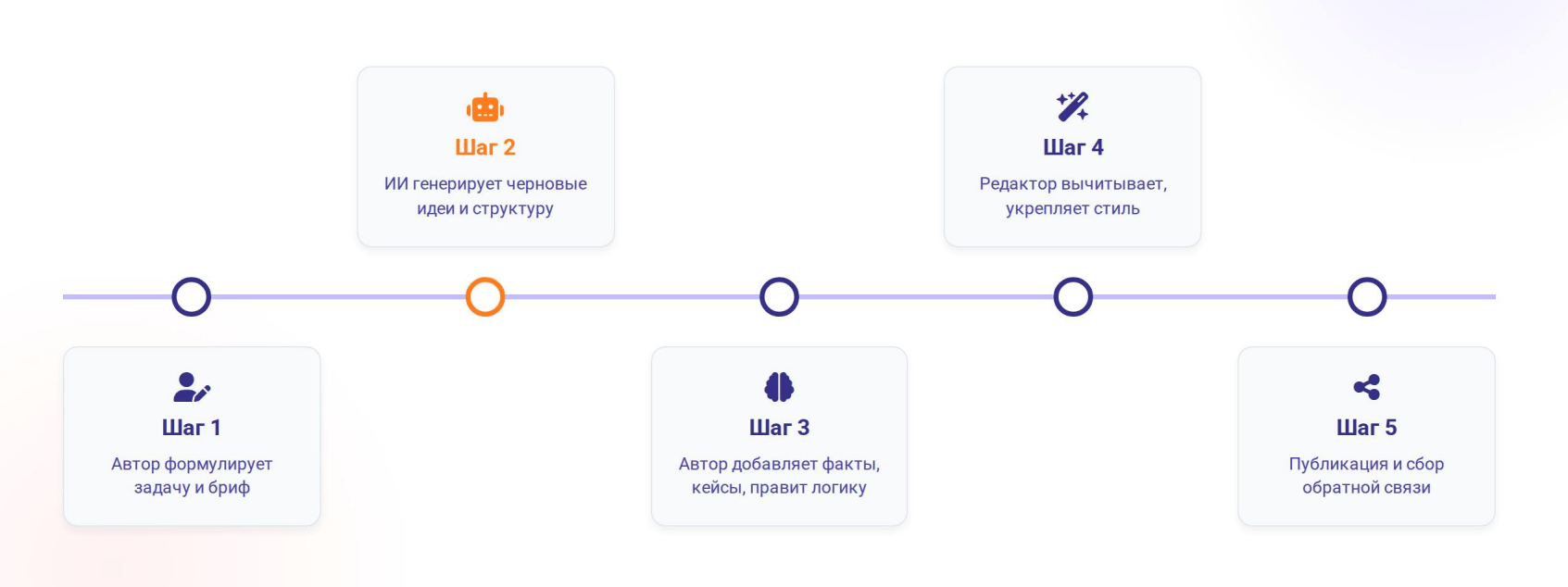
Такой подход позволяет сохранить скорость, которую дает ИИ, но избежать однообразия и ошибок, которые он неизбежно вносит.
Само собой, проблема model collapse волнует не только контент-маркетологов, но и разработчиков ИИ. И они не сидят без дела, а предлагают варианты решений:
Ограничение доли синтетических данных
Один из очевидных подходов в такой ситуации — строго контролировать, сколько синтетических данных используется при обучении. Например, устанавливать максимальную долю ИИ-контента в обучающей выборке (скажем, не больше 30%). Остальное — только проверенные человеческие данные.
К сожалению, это требует тщательной фильтрации и маркировки данных. Нужны инструменты, которые могут отличить человеческий текст от сгенерированного. Пока такие инструменты несовершенны, но над ними активно работают.
Подходы вроде "semi-synthetic data" и токен-редактирования
Вместо полной замены человеческих данных на синтетические, исследователи экспериментируют и с гибридными подходами. Например, можно использовать ИИ для улучшения человеческих данных — исправить опечатки, дополнить недостающие детали, перефразировать для разнообразия. Но основа остается реальной.
В этом ключе на сцену выходит токен-редактирование. Можно сказать, это способ аккуратно "чинить" текст, не обучая модель заново и не переписывая весь ответ. Мы меняем распределение вероятностей (усиливаем или ослабляем отдельные токены), запрещаем часть токенов или подменяем уже сгенерированные токены на другие. В результате модель изменяет отдельные слова или фразы в тексте, а не генерирует весь текст с нуля. Это позволяет сохранить структуру и смысл оригинала, избегая полного коллапса.
Новые метрики и тесты
Чтобы вовремя заметить признаки коллапса, нужны специальные метрики. Исследователи разрабатывают тесты, которые отслеживают:
Такие метрики помогают понять, что модель начинает деградировать, и вовремя скорректировать процесс обучения.
Даже если вы не разрабатываете собственные ИИ-модели, я советую хотя бы время от времени следить за новыми открытыми в сфере model collapse. Потому что многие инструменты, которые вы используете (чат-боты, аналитика, генерация контента), зависят от качества моделей. Если модели деградируют, ваши инструменты будут работать хуже. Кроме того, понимание проблемы помогает принимать осознанные решения: стоит ли полагаться на ИИ-контент, нужно ли инвестировать в создание собственной базы качественных данных, какие риски учитывать при планировании контент-стратегии.
Model collapse — это не только техническая проблема для разработчиков нейросетей. Это вызов для всех, кто создает контент в интернете. Если мы позволим интернету наполниться синтетическими текстами, будущие ИИ-модели будут учиться на этом шуме и деградировать. Качество контента упадет, доверие к информации снизится, а поиск и ИИ-сервисы станут менее полезными. Мы окажемся в замкнутом круге, где каждое новое поколение моделей хуже предыдущего.
Но есть и хорошая новость: ценность копирайтера и контент-маркетолога будет расти там, где нужен живой опыт, оригинальные идеи и ответственность за смысл, а не просто скорость генерации. Профессионалы, которые умеют создавать уникальный контент на основе реальных знаний, станут еще более востребованными.




