


Тендеры и лиды
Информация
Транскрибация аудио и видео в текст — автоматическое преобразование речи в текст нейросетями. Объём ежемесячно транскрибируемого в России аудио вырос с 2,7 млн минут в 2023 году до 9,5 млн в 2025 — в 3,5 раза. Гайд ниже: технологии распознавания, обзор 8 сервисов с тарифами и точностью, как выбрать под задачу.
Транскрибация — это процесс автоматического преобразования устной речи в текст. Раньше это делали стенографисты вручную: расшифровка часа качественной аудиозаписи занимала 5–6 часов. С 2022 года, когда OpenAI опубликовала модель Whisper с открытым исходным кодом, индустрия пережила технологический скачок — час аудио стал расшифровываться за 2 минуты с точностью до 97%.
Резкий рост рынка вызван тремя факторами. Первый — массовое распространение видеоконтента: к 2026 году на YouTube ежеминутно загружается более 500 часов видео, и значительная часть авторов нуждается в субтитрах и текстовых конспектах. Второй — переход бизнеса в гибридный формат: совещания через Zoom, Google Meet, Telemost, Yandex Telemost производят гигантский объём записей, которые нужно структурировать. Третий — развитие моделей машинного обучения с поддержкой русского языка: SaluteSpeech от Сбера, Yandex SpeechKit, локально дообученные версии Whisper резко повысили точность распознавания русской речи.
В практическом измерении автоматическая транскрибация экономит до 80% времени по сравнению с ручным набором. Современные системы достигают точности 92–98% на качественных записях — это уже не «ИИ-эксперимент», а рабочий инструмент для бизнеса, медиа и науки.
«Whisper приближается к точности человека на чистом аудио. Реальная ценность модели — в работе со сложными условиями: фоновым шумом, разными акцентами, переходами между языками. Это первая открытая модель распознавания речи такого уровня, доступная любому разработчику».
— Команда исследователей OpenAI, разработчики модели Whisper
Транскрибация перестала быть нишевым инструментом. Сегодня её используют профессионалы из совершенно разных областей:
Команда toolfox.ru постоянно тестирует решения для этих задач — в каталоге собраны более 30 сервисов транскрибации разной специализации, от универсальных российских до международных платформ для подкастеров.
Технологическая база транскрибации в 2026 году делится на три ключевых семейства моделей. Понимание архитектуры важно при выборе сервиса — точность, поддерживаемые языки и устойчивость к шуму прямо зависят от используемой модели.
Whisper от OpenAI — самая распространённая основа для современных сервисов. Модель обучена на 680 000 часов многоязычного аудио, поддерживает 99 языков, доступна с открытым кодом по лицензии MIT. По заявлениям разработчиков, Whisper на чистом русском аудио показывает точность 95–97%, а на сложных записях со шумом и акцентами — 88–92%.
Ключевое преимущество Whisper — открытая лицензия. Любой сервис может локально дообучить модель под свою специфику: добавить медицинскую терминологию, юридический сленг, технические понятия. Многие российские сервисы как раз используют локально дообученные версии Whisper в качестве движка.
SaluteSpeech — собственная модель распознавания речи от Сбера, лежащая в основе сервиса GigaChat от Сбера. Модель оптимизирована под русский язык с учётом региональных акцентов, разговорных конструкций, типичных ошибок речи. Заявленная точность распознавания русской речи — 95–98% на чистом аудио. Главное преимущество — обработка данных на российских серверах с соответствием ФЗ-152.
GigaChat бесплатно расшифровывает голосовые сообщения и аудиофайлы через интерфейс мессенджеров и API, расставляет знаки препинания, работает с файлами до 20 МБ. SaluteSpeech используется и как отдельное корпоративное API SmartSpeech для энтерпрайз-клиентов с большими объёмами обработки.
Часть сервисов разрабатывает свои собственные нейросетевые архитектуры — это касается Yandex SpeechKit, AssemblyAI, Sonix, RealSpeaker. Преимущество — полный контроль над качеством под целевую аудиторию и интеграция с другими продуктами компании. Обратная сторона — закрытость технологии: пользователь не может локально дообучить модель под свою специфику.
В нашем тестовом обзоре 30+ сервисов из каталога мы видим: 60% сервисов используют Whisper или его форки, 25% — собственные модели, 15% — гибридные решения (Whisper + локальные доработки + ChatGPT для постобработки текста).
Универсального «лучшего» сервиса не существует — каждый оптимален под определённые задачи. Перед выбором стоит проверить семь параметров.
Точность распознавания на русском языке. Это критерий №1. Норма для качественного сервиса в 2026 — 92%+ на чистом аудио. Разница между 92% и 97% означает 5% слов, которые придётся править вручную. На часе записи это около 50 правок против 25 — двукратная разница в редактуре.
Скорость обработки. Современные облачные сервисы транскрибируют час аудио за 2–15 минут. Локальные модели на CPU работают медленнее (час за 30–60 минут), на GPU — за 3–10 минут. Для срочных задач (расшифровка прямого эфира) принципиальна минутная задержка, для архивной работы — несущественна.
Диаризация — разделение по спикерам. Критична для интервью, совещаний, фокус-групп. Качественная диаризация распознаёт 4–8 разных голосов в записи и присваивает им метки. Без диаризации текст превращается в монолитную стенограмму, требующую ручного разбиения.
Поддерживаемые форматы и интеграции. Стандартный набор: MP3, WAV, OGG для аудио, MP4, AVI, MKV для видео. Продвинутые сервисы поддерживают потоковую транскрибацию из YouTube, Google Drive, Яндекс.Диск, Telegram. Для разработчиков критично наличие API.
Экспорт результатов. Минимум — TXT и DOCX. Для видеомейкеров обязательны субтитры SRT, VTT. Для бизнеса — структурированные протоколы со списком задач и ответственных.
Безопасность данных и соответствие законам. Для России — обработка на серверах в РФ по ФЗ-152, для медицинских и юридических данных — дополнительные сертификаты. Международные сервисы (Otter, Descript) хранят данные в США и не подходят для чувствительных корпоративных задач.
Цена и тарифная модель. Базовые варианты: бесплатно с лимитами (3 часа в месяц), подписка фиксированной цены (490–2900 ₽/мес), pay-as-you-go (30–60 ₽ за час), enterprise по контракту. Для разовых задач выгоднее PAYG, для регулярной работы — подписка.
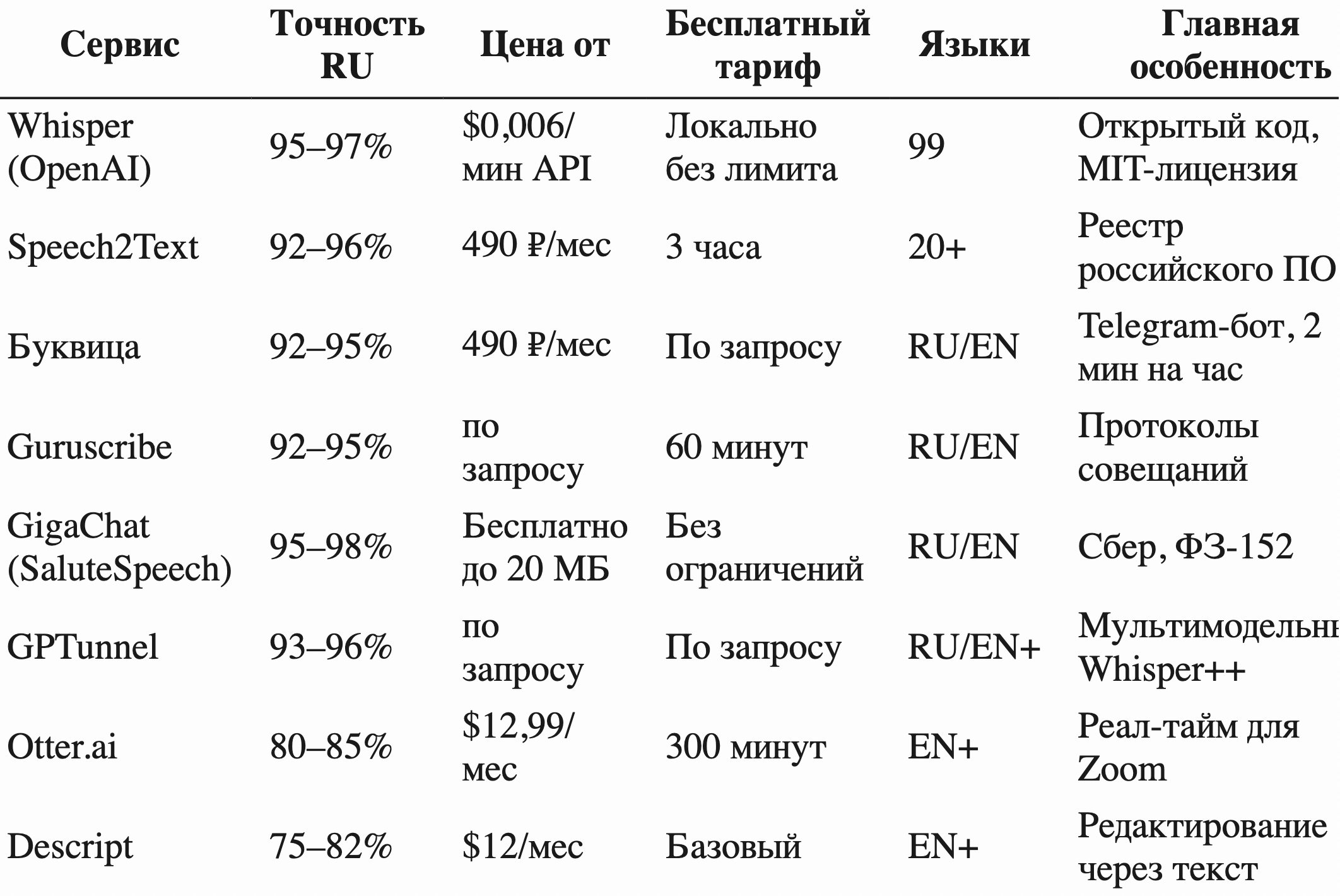
В каталоге toolfox.ru собраны более 30 сервисов распознавания речи. Ниже — детальный разбор 8 ключевых решений с тарифами, технологической базой и сферами применения.
Whisper от OpenAI — флагманская открытая модель распознавания речи, выпущенная в 2022 году. Обучена на 680 000 часов многоязычного аудио, поддерживает 99 языков с автоматическим определением языка, лицензия MIT.
Whisper доступен в двух режимах. Локальный запуск — бесплатный, требует GPU NVIDIA с 6+ ГБ VRAM. Доступны 5 размеров модели от tiny (39 МБ) до large (1,5 ГБ) с разной точностью и скоростью. API через OpenAI — $0,006 за минуту аудио ($0,36 за час, около 30 ₽), без необходимости содержать инфраструктуру.
Ключевые преимущества — открытость кода и широкое сообщество. На базе Whisper построены десятки коммерческих сервисов с локальной дообученной моделью под русский язык. Подходит разработчикам, исследователям, командам с собственной инфраструктурой и большими объёмами обработки.
Speech2Text — отечественный сервис автоматической транскрибации, зарегистрированный в Реестре российского ПО (запись №27300 от 21.03.2025). Разработка ООО «Современные речевые технологии».
Ключевые особенности: автоматическое деление на спикеров с возможностью переименования, поддержка более 20 языков, генерация субтитров SRT для видео, экспорт в DOCX. Час аудио обрабатывается за 10 минут. При регистрации даётся 3 бесплатных часа транскрибации.
Сервис подходит для журналистов, исследователей, юристов и всех, кому важна работа на русских серверах с соответствием ФЗ-152. Тарифы — от 490 ₽/мес. Поддерживает MP3, WAV, OGG, MP4, AVI, WMA и другие форматы.
Буквица — российский сервис транскрибации в формате Telegram-бота. Главное преимущество — нулевой порог входа: запуск через Telegram без регистрации на отдельном сайте.
Сервис работает с YouTube-ссылками, файлами с Google Drive и Яндекс.Диска, видео из Instagram, прямой загрузкой в Telegram. После обработки выдаёт ссылку на Google Документ с правами редактирования — удобно для совместной работы. Скорость — около 2 минут на час материала, что один из самых быстрых показателей рынка.
Тарифы прозрачные: Базовый — 30 часов транскрибации в месяц за 490 ₽, Про — безлимитная генерация за 1 290 ₽/мес. Годовая подписка со скидкой 50% — 2 890 ₽ за Базовый и 7 690 ₽ за Про. Подходит маркетологам, продуктовым командам, тем кто живёт в Telegram.
Guruscribe — отечественная платформа транскрибации с акцентом на корпоративные сценарии. Главная фишка — автоматическая генерация структурированных протоколов совещаний с выделением ключевых решений, задач и ответственных.
Поддерживает диаризацию, расстановку временных меток, экспорт в TXT, DOCX, SRT. Час аудио — около 27 секунд обработки на базовых записях. Доступны бесплатный тариф (60 минут), стандартный для индивидуальных пользователей и бизнес-тариф для команд с приоритетной обработкой и API.
Подходит руководителям, секретарям, проектным менеджерам, всем кто проводит много совещаний и нуждается в их быстрой структуризации.
GigaChat с SaluteSpeech — собственная разработка Сбера на базе SaluteSpeech. Главные преимущества — бесплатное распознавание голосовых сообщений и аудиофайлов до 20 МБ, обработка на российских серверах в соответствии с ФЗ-152, автоматическая расстановка пунктуации.
GigaChat распознаёт речь через мессенджер-интерфейс или API. Точность на русском — 95–98%, особенно сильна работа с разговорной речью, региональными акцентами, телефонным качеством записи. Подходит для частного использования, малого бизнеса, для тех кому критично нахождение данных в РФ.
Ограничение бесплатного тарифа — 20 МБ на файл (примерно 30–40 минут аудио в среднем качестве). Для больших объёмов нужен корпоративный API SaluteSpeech.
GPTunnel — российская платформа агрегатор нейросетей, в составе которой есть транскрибация на базе Whisper-архитектуры с локальными доработками под русскую речь. Доработки включают распознавание сленга, технических терминов и региональных акцентов.
Главное преимущество — мультимодельность: транскрибация совмещается с другими ИИ-функциями (генерация текста, перевод, саммаризация) в едином интерфейсе. Получив транскрибацию, пользователь сразу может попросить ChatGPT или Claude сделать резюме, выделить ключевые темы, перевести на другой язык.
Подходит контент-мейкерам, маркетологам, исследователям — тем кому нужна не просто транскрибация, а готовый текстовый материал.
Otter.ai — международный сервис для бизнес-встреч с интеграцией в Zoom, Google Meet, Microsoft Teams. Главная особенность — реал-тайм-транскрибация: текст появляется на экране параллельно с разговором.
Поддерживает диаризацию (до 4 голосов в бесплатном тарифе, до 8 в платных), автоматическую генерацию саммари по итогам встречи, выделение задач. Точность на английском — 92–95%, на русском — 80–85% (что существенно ниже российских специализированных сервисов).
Тарифы: Free (300 минут/мес), Pro $12,99/мес, Business $20/мес. Подходит для англоязычных встреч и международных команд. Для русских записей лучше выбирать российский сервис из списка выше.
Descript — международная платформа для подкастеров и видеомейкеров с уникальным подходом: редактирование аудио и видео через текст. Удалив слово или абзац в транскрипции, пользователь автоматически удаляет соответствующий фрагмент в аудио или видео.
Точность на английском — 93–95%, на русском поддержка ограничена. Тарифы — от $12/мес. Подходит создателям подкастов, видеоблогерам, командам контент-производства, которым нужна не только транскрибация, но и быстрое редактирование медиа без видеоредактора.
Полный набор инструментов с подробными тарифами и техническими параметрами доступен в каталоге сервисов транскрибации аудио в текст.
В 2026 году базовый бесплатный функционал доступен почти у всех сервисов, но границы возможностей различаются кардинально.
Наша система сама подберет вам исполнителей на услуги, связанные с разработкой сайта или приложения, поисковой оптимизацией, контекстной рекламой, маркетингом, SMM и PR.
Заполнить заявку
13514 тендеров
проведено за восемь лет работы нашего сайта.
Реально работающие бесплатные опции:
Где бесплатное не работает:
Для большинства профессиональных задач имеет смысл платный тариф 490–1 290 ₽/мес. При расходе свыше 50 часов транскрибации в месяц выгоднее становится локальный Whisper на собственном GPU.
Закон № 152-ФЗ «О персональных данных» обязывает обрабатывать персональные данные граждан России на серверах, находящихся на территории РФ. Для транскрибации это означает: записи голосов сотрудников, клиентов, пациентов, истцов считаются персональными данными и требуют российской инфраструктуры.
Из 8 рассмотренных сервисов 5 российских (Speech2Text, Буквица, Guruscribe, GigaChat, GPTunnel) хранят данные на российских серверах с подтверждённым соответствием ФЗ-152. Whisper можно запустить локально (что автоматически решает вопрос). Otter и Descript хранят данные в США — для российских корпоративных клиентов с чувствительными записями это блокирующий фактор.
Дополнительные требования по отраслям:
Для типового бизнеса (маркетинг, продакт, контент) достаточно стандартного набора требований 152-ФЗ — все российские сервисы из списка подходят.
Ниже — конкретные сценарии применения по отраслям с примерами реальных задач.
Медиа и журналистика. Расшифровка интервью занимает у журналиста 60% времени работы над материалом. Автоматическая транскрибация сокращает это до 5–10%. Один час разговора с экспертом превращается в текст за 2–10 минут, остаётся только редактура и структурирование. Особенно полезна диаризация для бесед с несколькими собеседниками — каждая реплика автоматически помечается.
Маркетинг и контент. Анализ видеоконтента конкурентов (часовое выступление эксперта на YouTube → текст за 5 минут → ключевые тезисы для своей статьи), создание текстовых версий собственных видео для SEO и индексации поисковиками, расшифровка кастомер-интервью для создания УТП.
Образование и наука. Преподаватели публикуют конспекты лекций для дистанционных студентов, исследователи обрабатывают фокус-группы и качественные интервью, аспиранты транскрибируют записи опросов. Это резко ускоряет научные исследования: фаза «сбор данных» сокращается с месяцев до недель.
Бизнес и корпоративный сектор. Транскрибация совещаний с автоматической генерацией протокола (Guruscribe лидер этой ниши), документирование переговоров с клиентами для контроля качества, расшифровка product-discovery-интервью с пользователями. Многие компании внедряют автоматическую транскрибацию всех важных встреч — это создаёт корпоративную базу знаний.
Юриспруденция. Расшифровка судебных заседаний, документирование показаний, работа с записями переговоров с клиентами. Для протокольной точности часто используют гибридный подход: автоматическая транскрибация + ручная сверка человеком.
Здравоохранение. Документирование консультаций с пациентами, транскрибация медицинских комиссий, обработка обучающих лекций для медиков. Жёсткие требования к 152-ФЗ ограничивают выбор: подходят локальный Whisper и российские сертифицированные сервисы.
«Спрос на транскрибацию русской речи в 2025-2026 годах вырос лавинообразно. Главный технологический вызов — не просто распознать слова, а понять контекст, расставить смысловые акценты, выделить ключевые тезисы. Сегодня лучшие российские сервисы делают это автоматически».
— Эксперт по локализации речевых технологий (адаптировано из материалов индустриальных конференций)
Точность даже самого продвинутого сервиса зависит от исходного материала. Ниже семь правил, которые помогут получить максимум при минимальных доработках текста.
Правило 1. Качественная запись. Используйте петличный или конденсаторный микрофон вместо встроенного в ноутбук. Разница в точности — 5–10 процентных пунктов. На записи из встроенного микрофона ноутбука Whisper даёт 88–90%, на записи с петличного — 95–97%.
Правило 2. Минимизация фонового шума. Закройте окна, выключите кондиционер и вентиляторы, отойдите от шумных мест. Современные модели справляются с лёгким шумом, но при шумах более 40 дБ точность падает на 10–15%.
Правило 3. Чёткая речь без перебиваний. Если возможно, попросите собеседников говорить по очереди. Когда два голоса перекрываются, диаризация падает с 90% до 60% — два спикера сливаются в одного.
Правило 4. Правильный формат файла. Лучше — WAV без сжатия или MP3 320 кбит/с. Сжатые форматы (MP3 64 кбит/с, OGG низкого качества) снижают точность на 3–8%.
Правило 5. Один язык на запись. Большинство сервисов плохо работают со смешением языков (русский + английский в одной фразе). Если интервью на двух языках — лучше разбить на сегменты и транскрибировать каждый отдельно.
Правило 6. Пользовательские словари. Многие сервисы (Speech2Text, Guruscribe, Whisper API) позволяют задать словарь специальных терминов: имена, бренды, технические понятия. Это решает 80% проблем с уникальной лексикой.
Правило 7. Финальная человеческая проверка. Даже 98% точность означает 1 ошибку каждые 50 слов. На двухчасовом интервью — около 200 правок. Закладывайте время на редактуру.
Получить текст — половина задачи. Дальше его нужно структурировать и использовать. Базовый workflow.
Шаг 1. Удаление слов-паразитов и оговорок. «Эээ», «нуу», «как бы», «вот это», повторы фраз — всё это засоряет текст. У большинства сервисов есть встроенная функция фильтрации. Если нет — массовый поиск-замена в редакторе.
Шаг 2. Структурирование. Разделите текст на смысловые блоки с заголовками. Для интервью — по темам обсуждения, для совещаний — по обсуждаемым вопросам и решениям, для лекций — по разделам учебной программы.
Шаг 3. Редакторская правка. Устная речь и письменная имеют разные нормы. То что хорошо звучит, плохо читается. Перестройте предложения для удобочитаемости, разбейте длинные на короткие, замените разговорные конструкции литературными там где это уместно.
Шаг 4. Использование по назначению. Превращение в статью для блога, скрипт для видео, ТЗ для копирайтера, отчёт для команды. Транскрибация — сырьё, но качественное сырьё, из которого можно делать любой формат.
Шаг 5. Архивирование. Сохраните оригинальную транскрипцию отдельно от отредактированной версии. Через год может понадобиться вернуться к точному цитированию.
Технологии распознавания речи продолжают стремительно развиваться. Из обзора публичных дорожных карт OpenAI, Сбера, Yandex и независимых исследователей видны пять ключевых направлений на ближайшие 2–3 года.
Точность приближается к человеческой на сложном аудио. Сейчас разрыв между автоматической транскрибацией и человеком составляет 2–5% на чистых записях и 10–15% на сложных. К 2027–2028 годам этот разрыв сократится до десятых процента — нейросети будут лучше человека на стандартных записях.
Распознавание эмоций и интонаций. Помимо слов сервисы начнут отмечать эмоциональную окраску: ирония, сарказм, гнев, радость. Это критично для анализа переговоров, продаж, психологических консультаций — текст без интонации часто теряет смысл.
Многоязычная транскрибация в реал-тайме. Бизнес-встречи на двух-трёх языках одновременно с переводом и транскрибацией каждого спикера на его родной язык. Технологии уже близки — Yandex Translator и Google Translate показывают рабочие демо.
Интеграция с большими языковыми моделями. Сразу после транскрибации — автоматическое саммари, выделение задач и ответственных, генерация текстов на основе сказанного. Это уже работает в GPTunnel, GigaChat, Otter — будет стандартом везде.
Локальные модели на устройствах. Транскрибация без интернета прямо на смартфоне или ноутбуке. Apple Whisper, Google AICore уже частично реализуют это. К 2027 году ожидается полный сдвиг на локальную обработку для конфиденциальных задач.
«В 2026 году транскрибация перестаёт быть отдельным инструментом и становится частью большего ИИ-стека: запись → расшифровка → саммари → выделение задач → распределение по команде. Сервисы, которые предоставляют только распознавание речи без следующих шагов, постепенно проигрывают».
— Отраслевой обзор индустрии, на основе материалов Habr Bothub и аналитических публикаций 2026 года
Для большинства задач — Speech2Text, Буквица, Guruscribe и GigaChat с SaluteSpeech. У всех точность на русском 92–98% при разной специализации. Speech2Text удобен журналистам и юристам, Буквица — пользователям Telegram, Guruscribe — для протоколов совещаний, GigaChat — для бесплатной обработки голосовых сообщений до 20 МБ.
Бесплатно — через GigaChat (до 20 МБ файл) или локальный Whisper. От 8 ₽ за минуту через RealSpeaker. От 27 ₽ за час через Whisper API OpenAI. Подписка 490 ₽/мес у Speech2Text и Буквицы покрывает до 30 часов в месяц. Корпоративные пакеты — от 1 290 ₽/мес за безлимит.
Да. Несколько способов: 1) встроенные субтитры YouTube (но они часто неточные); 2) Буквица принимает YouTube-ссылки и расшифровывает за 2 минуты; 3) скачать аудиодорожку через сторонние сервисы и пропустить через бесплатный Whisper; 4) GigaChat обработает 20 МБ — это около 30 минут аудио из видео.
Для российских клиентов выбирать сервисы с обработкой на серверах в РФ и явным соответствием 152-ФЗ: GigaChat, Speech2Text, Буквица, Guruscribe, GPTunnel. Для максимальной конфиденциальности — локальный Whisper на собственном GPU без интернета. Otter и Descript хранят данные в США и не подходят для чувствительных записей.
Обычная транскрибация выдаёт сплошной текст без разделения по говорящим. Диаризация автоматически определяет, кто из участников разговора что сказал, и помечает реплики метками вроде «Спикер 1», «Спикер 2». Метки потом можно переименовать в реальные имена. Без диаризации работа с интервью или записями совещаний сильно усложняется.
Это 1 ошибка каждые 20 слов. На часовом интервью с темпом речи 120 слов в минуту — около 360 ошибок на текст. Это требует редакторской правки, но в 5–10 раз быстрее чем ручной набор. Для большинства задач этого достаточно. Для протокольной точности (судебные записи, медицинские документы) применяют гибридный подход: автоматическая транскрибация + ручная сверка.
Whisper и AssemblyAI поддерживают многоязычные записи: автоматически переключаются между языками внутри одной аудиодорожки. Качество ниже, чем на однородном языке: точность падает с 95% до 85–90%. Для критичных задач рекомендуется разбить запись на сегменты и транскрибировать каждый отдельно с указанием правильного языка.
Транскрибация в 2026 году — рабочий инструмент, который кардинально меняет производительность работы с аудио и видео. Час интервью или совещания, на расшифровку которого раньше уходил рабочий день, теперь превращается в текст за 2–10 минут. Главное при выборе сервиса — соответствие задаче: для русских записей и работы по 152-ФЗ подходят отечественные решения (Speech2Text, Буквица, Guruscribe, GigaChat), для разработчиков и больших объёмов — локальный Whisper, для англоязычных бизнес-встреч — Otter, для подкастеров — Descript. Полный сравнительный обзор всех 30+ сервисов с актуальными тарифами и специализацией под задачи доступен в каталоге toolfox.ru — там же можно протестировать бесплатные тарифы каждого решения перед выбором платного.




