Тендеры и лиды
Информация
Вопрос о законности парсинга в 2026 году давно вышел за рамки чисто технической темы. Для бизнеса это уже не спор «можно или нельзя», а вполне практический вопрос: можно ли собирать данные с сайтов без риска получить претензию, блокировку или юридические проблемы.
Если отвечать коротко, сам по себе парсинг не запрещен. Автоматический сбор данных остается обычным рабочим инструментом, если речь идет об открытой информации, доступной любому пользователю, и если при этом не нарушаются чужие права, не затрагиваются персональные данные и не создается вред для сайта.
Главный вопрос: можно ли легально собирать данные с сайтов
Да, можно — если вы работаете с публичной информацией. В первую очередь речь идет о тех данных, которые изначально открыты для любого посетителя: цены, карточки товаров, описания услуг, перечни предложений, открытые характеристики, новости и другие общедоступные сведения.
С юридической точки зрения важен не сам факт использования парсера, а то, как именно ведет себя сборщик данных и что именно он собирает. Если программа просто автоматизирует доступ к открытой информации, не обходит защиту, не вытягивает закрытые разделы и не мешает работе сайта, это обычно рассматривается как технический способ получения информации, а не как нарушение.
Проще говоря, закон оценивает не слово «парсинг», а последствия: был ли взлом, был ли доступ к закрытым данным, пострадал ли сайт, затронуты ли личные сведения людей.
Почему тема законности парсинга стала особенно важной
Еще несколько лет назад вокруг парсинга было много путаницы. Владельцы сайтов часто считали, что сам факт автоматического сбора данных уже незаконен. Бизнес, наоборот, исходил из логики «если информация открыта, значит ее можно использовать». Сейчас подход становится более практическим.
Парсинг в 2026 году воспринимается не как что-то экзотическое, а как обычный инструмент автоматизации: для мониторинга цен, анализа ассортимента, отслеживания новостей, сравнения предложений, проверки наличия и построения аналитики. Поэтому и юридический разговор сместился в более понятную плоскость: что можно собирать, а что нельзя, и где проходит граница между легальной автоматизацией и нарушением.
Судебная практика 2026: на что теперь смотрят суды
Один из важных ориентиров — подход, при котором суды оценивают не саму программу-парсер, а фактическое поведение стороны. Если информация должна быть открытой и доступна всем, сам по себе автоматический сбор таких данных уже не выглядит чем-то незаконным.
Это важный сдвиг для рынка. Раньше спор часто строился вокруг слова «парсинг» как будто это изначально подозрительная технология. Сейчас в центре внимания другие вопросы: был ли причинен вред серверу, был ли обход защиты, собирались ли закрытые данные, использовались ли персональные сведения без правового основания.
Для бизнеса это хороший сигнал. Он означает, что автоматизация не рассматривается как проблема сама по себе. Проблемой становятся уже конкретные нарушения.
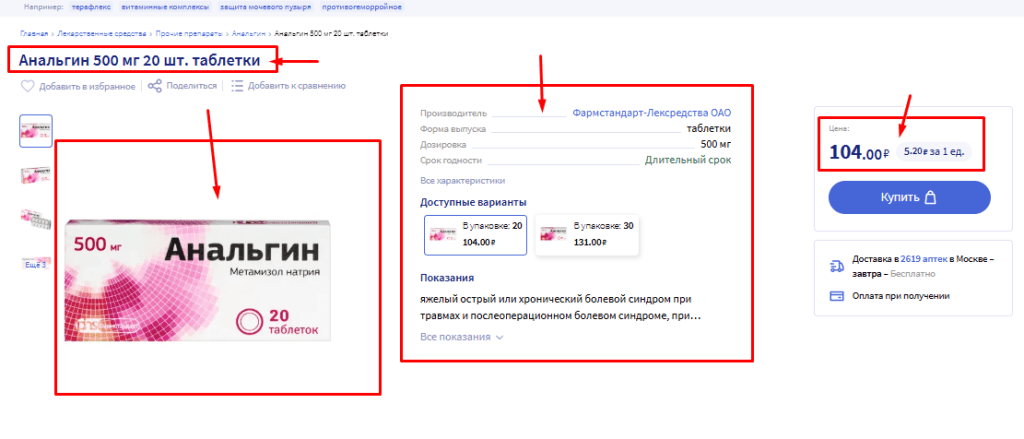
Пример открытых данных для парсинга
Где проходят главные красные линии
На практике все упирается в несколько ограничений. И именно они определяют, можно ли считать сбор данных безопасным с юридической точки зрения.
1. Нельзя лезть в закрытую часть сайта
Одно дело — собрать открытые карточки товаров. Другое — попытаться эмулировать чужой вход, обходить ограничения или забирать то, что не предназначено для свободного доступа.
Именно здесь заканчивается «сбор открытых данных» и начинается потенциальное нарушение.
2. Нельзя перегружать чужой сайт
Даже если информация публичная, это не дает права собирать ее так, чтобы сайт начал тормозить или падать. Слишком агрессивный скрипт, который делает большое количество запросов без пауз, может быть расценен как вредоносное поведение, даже если он собирает открытые данные.
Для бизнеса это важный момент. Законность парсинга зависит не только от содержания данных, но и от технического поведения программы.
3. Нельзя собирать и использовать персональные данные без оснований
Это самая чувствительная зона. ФИО, телефоны, адреса, фотографии, ссылки на профили и другие сведения, по которым можно определить конкретного человека, относятся к персональным данным.
Даже если человек сам указал телефон в объявлении, это еще не означает, что такие сведения можно спокойно складывать в свою базу и использовать для рассылок или массового обзвона. Именно здесь у бизнеса чаще всего возникают реальные юридические риски.
Персональные данные: где чаще всего ошибаются
На практике компании часто считают, что если информация уже опубликована в интернете, то ее можно использовать как угодно. Это опасная логика.
Публичность еще не равна свободному использованию. Если вы собираете не просто цены, характеристики товаров или перечень услуг, а формируете массив данных о конкретных людях, вы уже попадаете в другую правовую зону.
Для бизнеса безопаснее всего собирать обезличенные или технические данные: стоимость, наличие, вес, размер, описание категории, рейтинг товара, структуру предложения. Проблемы начинаются там, где система собирает «цифровой портрет» человека — пусть даже частично.
Robots.txt и технические правила: насколько это важно
Наша система сама подберет вам исполнителей на услуги, связанные с разработкой сайта или приложения, поисковой оптимизацией, контекстной рекламой, маркетингом, SMM и PR.
Заполнить заявку
13590 тендеров
проведено за восемь лет работы нашего сайта.
Файл robots.txt часто воспринимают как чисто техническую деталь, но на практике он тоже важен. Это файл, в котором владелец сайта показывает, какие разделы рекомендует не сканировать.
Нарушение robots.txt не всегда автоматически означает нарушение закона. Но игнорировать его — плохая идея и с технической, и с юридической точки зрения. Если сайт прямо указывает ограничения, лучше учитывать их при проектировании парсинга и не идти в лоб.
В целом безопасный подход выглядит так:
Авторское право: что можно брать, а что нельзя
Еще одна частая ошибка — смешивать сбор фактов и копирование контента. Цена, наличие, вес, размер, артикул, технический параметр — это одно. Полный текст описания, чужая статья, уникальный контент, фотографии — уже другое.
Для аналитики безопаснее всего собирать именно фактические и технические данные. Они нужны для сравнения, мониторинга, расчета, аналитики и контроля рынка. Но если бизнес копирует чужие тексты описаний или изображения и использует их как свои, это уже может привести к претензиям по авторскому праву.
Именно поэтому легальный парсинг обычно строится вокруг чисел, параметров, статусов и признаков, а не вокруг простого копирования чужого контента.
Когда API — более безопасный путь
Если у сайта есть официальное API, это почти всегда лучший вариант. API — это предусмотренный владельцем способ отдачи данных, и использование такого канала обычно выглядит наиболее чисто и с технической, и с юридической стороны.
Это не значит, что сбор открытых страниц всегда незаконен, если API нет. Но если официальный интерфейс существует и подходит под задачу, разумнее использовать именно его.
Для заказчика это обычно означает меньше споров, меньше технических рисков и более устойчивую интеграцию.
Что это значит для бизнеса на практике
Если упростить, законный парсинг в 2026 году держится на трех правилах.
Первое: собирать только открытые данные, которые доступны всем.
Второе: не трогать персональные данные без понятного правового основания.
Третье: не мешать работе чужого сайта слишком агрессивным сбором.
При таком подходе автоматизированный сбор данных остается нормальным и понятным инструментом для бизнеса. Его используют для мониторинга цен, анализа ассортимента, сравнения предложений, проверки конкурентов, отслеживания наличия, построения аналитики и обновления собственных систем.
Частые вопросы, которые задают наши заказчики
Могут ли быть реальные санкции за парсинг?
Да, если вы пытаетесь получить данные в закрытых разделов, обходите защиту, собираете персональные данные без оснований или создаете нагрузку на сайт. За сам факт работы с открытыми данными риск обычно отсутствует.
Нужно ли всегда спрашивать разрешение владельца сайта?
Не обязательно, если речь идет об открытой информации и вы не нарушаете технические или правовые границы. Но в спорных случаях лучше заранее оценивать риски.
Можно ли собирать цены и характеристики товаров?
Обычно да. Это один из самых безопасных сценариев для бизнеса, особенно если вы работаете именно с открытыми карточками и техническими параметрами.
Можно ли собирать телефоны и контакты?
Вот здесь уже нужна очень осторожная оценка. Такая информация часто относится к персональным данным, а значит, риски сразу становятся выше.
Если сайт прислал претензию, это уже нарушение?
Не всегда. Иногда вопрос решается технически: снизить частоту запросов, убрать спорный блок, временно остановить сбор. Но игнорировать такие сигналы точно не стоит.
Вывод
Парсинг в 2026 году остается легальным бизнес-инструментом, если он используется разумно. Сам по себе автоматический сбор данных не запрещен. Риски начинаются не из-за слова «парсинг», а из-за конкретных действий: обхода защиты, работы с персональными данными, перегрузки сайта и копирования чужого контента.
Для бизнеса рабочая логика выглядит просто: открытые данные собирать можно, закрытые — нельзя, персональные — только с очень осторожной правовой оценкой, а техническая реализация должна быть аккуратной и безопасной.
Именно такой подход сегодня позволяет использовать парсинг не как серую зону, а как обычный инструмент аналитики, мониторинга и автоматизации.