Тендеры и лиды
Информация

100 000
Услуги
Июнь 2026
Если вы держите клиентские сайты на абонентке, вы знаете этот холодок: сообщение от клиента «у меня сайт не работает, вы вообще следите?». В этот момент вся ваша ценность как подрядчика обнуляется — потому что узнать о проблеме первым должны были вы, а не он.
Расскажем, как мы прошли через это, что переделали в процессах поддержки и как побочным эффектом получили аргумент, который снял вечный вопрос клиентов «а за что я плачу каждый месяц». Будет полезно студиям и фрилансерам, у которых на обслуживании больше десятка проектов.
Когда сайтов на поддержке пять, всё держится на памяти и утреннем обходе. Это работает. Но как только проектов становится двадцать-тридцать-пятьдесят, ручной контроль рассыпается — физически невозможно каждый день проверять по полсотни сайтов, причём не только «открывается / не открывается», а всё, что ломается незаметно:
- сайт отвечает, но форма заявки тихо перестала отправлять письма — клиент теряет лиды и не понимает почему;
- домен или SSL подходят к концу срока, и в один день сайт исчезает или пугает посетителей «небезопасным соединением»;
- сайт взломали — редиректы на чужой домен, спам-вставки, случайный noindex — и проект выпадает из поиска;
- CMS устарела — ядро или плагины WordPress / Битрикс не обновлялись, и это бомба замедленного действия.
Ни одно из этого не видно при беглом «зашёл — вроде живой». А каждый случай бьёт по клиенту деньгами и по нашей репутации подрядчика.
Чтобы было понятнее, немного контекста. Один из наших самых непростых проектов — большой интернет-магазин электроники на WordPress и WooCommerce. Многоязычный, с огромным каталогом и десятками плагинов, каждый из которых за что-то отвечает: оплата, доставка, фильтры, переводы, выгрузки. Сайт живой и сложный, а значит, по определению хрупкий: то один плагин после обновления конфликтует с другим, то отваливается какая-нибудь мелочь на одной из языковых версий. У такого магазина всегда что-нибудь «подрагивает» — это просто плата за объём и функциональность.
И клиент под стать сайту — внимательный и очень требовательный. Для него этот магазин не витрина, а вся выручка, поэтому на любой сбой он реагирует мгновенно и эмоционально. И, честно говоря, он прав: когда продажи идут через сайт, каждая минута простоя — это потерянные деньги. Беда была в другом: о проблемах он раз за разом узнавал быстрее нас — и сообщал нам об этом без особой деликатности.
Кульминация случилась в понедельник утром. Сообщение от клиента: магазин не открывается. Лезем в логи — лёг ещё в субботу вечером, после автоматического обновления одного из плагинов. Почти двое суток крупный магазин электроники простоял в выходные, на хорошем трафике: каталог не грузился, корзина не работала, заявки не уходили. А узнали мы об этом не из мониторинга, а из гневного сообщения человека, который платит нам ровно за то, чтобы такого не случалось.
Этот понедельник стал триггером. Стало ясно: дело не в конкретном плагине, а в том, что у нас нет системы, которая ловит проблемы раньше клиента — особенно на таких перегруженных проектах, где «что-то отваливается» — норма жизни.
Прежде чем прийти к финальному варианту, честно перебрали несколько подходов.
Ручные проверки по утрам. Развалились первыми — на двадцати сайтах это полчаса рутины, которую все начинают пропускать через неделю.
Напоминания в календаре про домены и SSL. Лучше, чем ничего, но всё держится на одном человеке. Ушёл в отпуск — и привет, просроченный домен у клиента.
Самописный скрипт на cron + curl. Пингует сайты, шлёт алерт при коде ответа не 200. Дал нам пару недель спокойствия, а потом вылезли нюансы: не ловил сломанные формы (страница-то отдаёт 200), заваливал ложными тревогами при любом сетевом моргании, логи никто не читал. Поддержка самого скрипта превратилась в отдельную работу.
Главный вывод: проверять надо не «жив ли сервер», а приносит ли сайт клиенту то, за что он платит. Это другой уровень контроля, и его ручками и одним curl не закрыть.
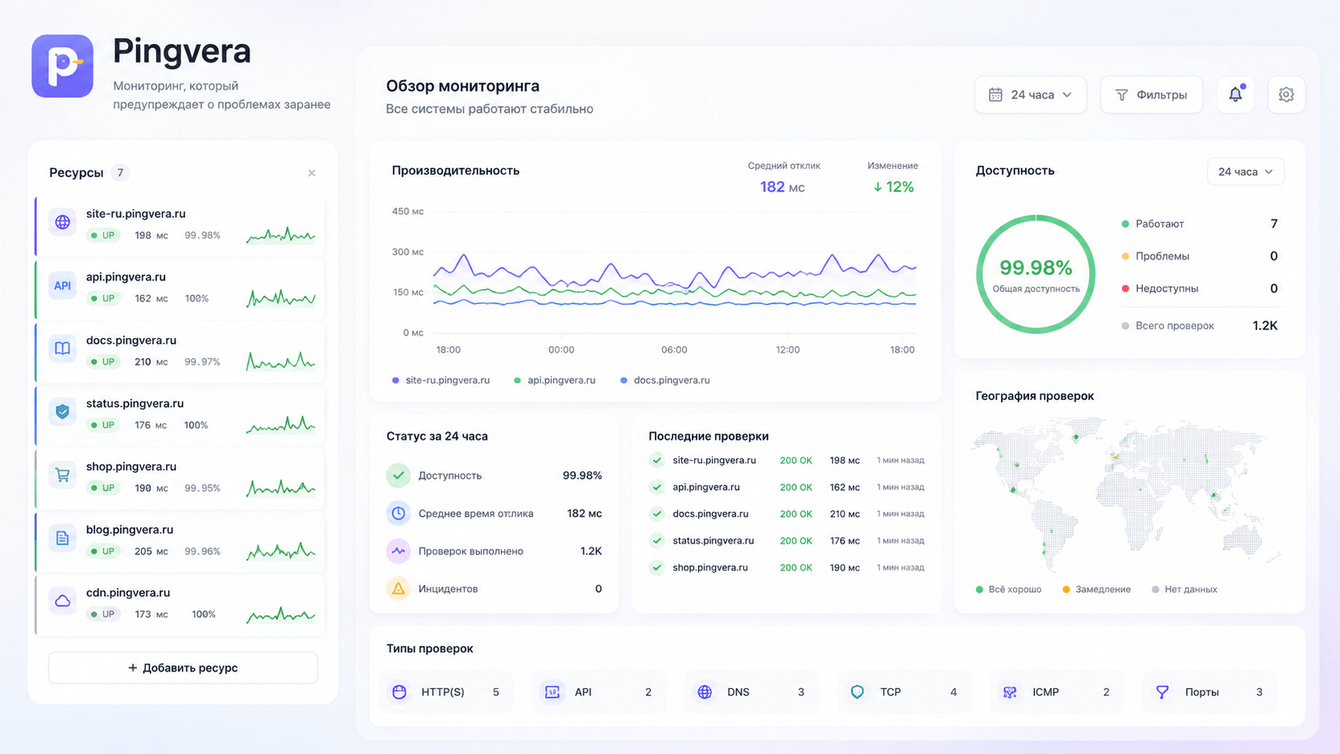
Опишем по типам — логика применима, даже если вы соберёте это другими инструментами.
Доступность по фазам запроса — DNS, TCP, TLS, HTTP — чтобы понимать не просто «лежит», а где именно. С подтверждением перед тревогой: алерт уходит после нескольких неудач подряд, а не от одного таймаута. Без этого доверие к уведомлениям умирает за неделю, и команда начинает их игнорировать.
Формы и заявки — синтетическая отправка формы (реальный POST) и проверка ответа: доходит ли заявка вообще. Плюс контроль ключевого текста на странице — не сломалась ли вёрстка формы после очередного обновления. Это самый недооценённый пункт: потеря лидов через молча сломанную форму бьёт по клиенту напрямую.
Домен и SSL — срок регистрации домена (включая .ru и .рф) и сертификата, с предупреждением заранее, а не в день, когда сайт уже исчез.
Взлом и SEO — подозрительные редиректы, спам-вставки, дефейс, случайный noindex, битые ссылки. То, из-за чего проект тихо выпадает из выдачи, а вы узнаёте об этом по графику трафика через месяц.
Диагностика CMS — версия ядра и плагинов WordPress и 1С-Битрикс, устаревшие компоненты, без проброса портов, только исходящими запросами.
Мы собрали всё это в одном месте — для этого сделали https://pingvera.ru и сами на нём работаем. Но повторимся: суть не в конкретном сервисе, а в принципе — контроль должен покрывать цепочку «сайт → форма → домен → поиск», а не один зелёный кружок «200 OK».
Первый и очевидный эффект — мы перестали узнавать о проблемах от клиентов. Алерт приходит раньше, чем человек откроет свой сайт и расстроится.
А вот неочевидный эффект, ради которого стоит читать этот кейс студиям. В конце первого же месяца мы отдали клиентам white-label отчёт — аптайм, список инцидентов, причины и сроки решения, под нашим логотипом и в наших цветах. И этот отчёт оказался лучшим ответом на вопрос, который рано или поздно задаёт каждый клиент на абонентке: «а за что я, собственно, плачу?».
Раньше абонентку приходилось защищать словами и обещаниями. Теперь клиент открывает отчёт и видит сам: вот что происходило с его сайтом, вот что мы отловили и починили — часто до того, как он вообще что-то заметил. Это перевело разговор из плоскости «дорого / непонятно за что» в плоскость «понятно, за что плачу, и это работает». По нашему опыту, именно прозрачность результата, а не уговоры, удерживает клиента на поддержке.
Тот минимум, который отличает системную студию от подрядчика в режиме «зашёл — вроде живой». Забирайте.
1. Сайт открывается — главная и ключевые внутренние страницы.
2. Скорость ответа не деградировала.
3. Форма заявки реально отправляет письмо / создаёт лид.
4. Контент на месте — нет пустых блоков и сломанной вёрстки.
5. Срок домена — предупреждение минимум за месяц.
6. Срок SSL-сертификата — предупреждение заранее.
7. Нет посторонних редиректов на чужие домены.
8. Нет спам-вставок и следов дефейса.
9. Не выставлен случайный noindex.
10. Нет массовых битых ссылок.
11. Версия CMS и плагинов актуальна (WordPress / Битрикс).
12. Ресурсы сервера в норме (если есть доступ): CPU, память, диск.
13. Алерты приходят туда, где их видят (Telegram / почта / MAX), и с подтверждением, чтобы не было ложных тревог.
14. Раз в месяц — отчёт клиенту. Не ради галочки, а как аргумент для продления договора.
На масштабе ручной контроль не масштабируется — нужна система, ловящая проблемы раньше клиента.
Проверять надо бизнес-функцию сайта (доступность, формы, домен, поиск), а не только код ответа сервера.
Мониторинг — это не только про «не упасть». Прозрачный отчёт о проделанной работе — рабочий инструмент удержания и обоснования абонентки.

Vera Pingvera
Россия Санкт-Петербург
А как у вас устроена поддержка клиентских сайтов на потоке — ручками, своими скриптами или сервисом? И что помогает удерживать клиентов на абонентке: отчёты, регулярные созвоны, что-то ещё? Поделитесь в комментариях — соберём опыт коллег.







