



Тендеры и лиды
Информация
У digital-специалистов есть ощущение, что все уже знают о ChatGPT и активно применяют ее в своих задачах, ну или хотя бы пытались это делать. Это не так: по данным исследования anketolog.ru, из 2432 опрошенных россиян 43 % вообще не слышали о этой нейросети, а 53 % хотели бы ей воспользоваться. Опрос проводился с 26 апреля по 7 мая 2023 года: на тот момент нейросеть уже прославилась за счет первого релиза и выхода обновленной версии на базе языковой модели GPT-4.
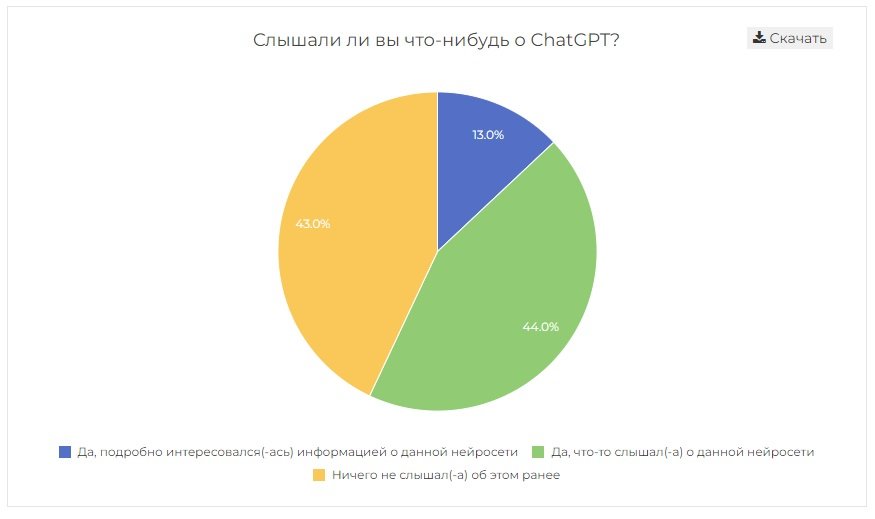
Диаграмма взята с сайта anketolog.ru
Думаем, что наша аудитория в большей степени знакома с ChatGPT, чем люди из исследования выше — в основном, нас читают digital-специалисты. Но мало кто знает, как устроена ChatGPT и мало кто знаком с историей ее развития. Мы решили провести ликбез — понимание принципов работы нейросети на фундаментальном уровне поможет использовать ее более эффективно.
В этой статье мы объясняем, как работает ChatGPT, погружаемся в историю развития нейросети, а также прогнозируем, что будет в GPT-5. Если вы хотите научиться работать с нейросетью, у нас есть подробный гайд: «Обзор ChatGPT: что умеет и как эффективно пользоваться нейросетью».
Языковую модель GPT 4, на которой работает ChatGPT, можно интегрировать в свой онлайн-сервис через API. На базе языковой модели работают такие сервисы, как Copy.ai, Writesonic и Gerwin AI. Если у вас есть идея для монетизации ChatGPT, необязательно сразу делать дорогой сайт: можно создать Telegram-бота в качестве MVP. Вы можете создать задачу для разработчиков чат-ботов на Workspace. Workspace — это тендерная площадка № 1 в сфере digital: собирайте отклики и выберите лучшего исполнителя.
По сути, ChatGPT — это интерфейс в виде чат-бота, который служит «прокладкой» между пользователем и языковой моделью GPT. Платная версия продукта работает на языковой модели GPT-4, а бесплатная — на GPT-3.5. Для понимания принципа работы нейросети объясним, как устроены языковые модели семейства GPT.
Все версии GPT используют подход казуального моделирования. То есть, они просто подбирают слово за словом, исходя из анализа предыдущих слов. Например, тем же самым занимаются более свежие версии T9, которые умеют предлагать следующее слово, отталкиваясь от введенного текста. Система T9 обязана такой возможностью простецкой языковой модели, которая является ее частью.
Пример работы функции автозаполнения, которая угадывает следующее слово на основе введенного текста
Нейросети семейства GPT работают на базе архитектуры глубоких нейронных сетей, которая называется «Трансформер». Эту архитектуру изобрели в 2017 году в Google Brain — исследовательской группе Google, которая занимается изучением и разработкой нейросетей. Создание архитектуры «Трансформер» стало переломным моментом в проектировании нейросетей и позволило создать настолько «умный» продукт, как ChatGPT.
В чем преимущество архитектуры «Трансформер»: нейросеть на ее базе состоит из отдельных слоев, которые работают параллельно, а также позволяют улавливать контекст и долгосрочные зависимости в запросе. В случае с языковыми моделями это означает, что нейросеть генерирует следующее слово на основе всех предыдущих слов из запроса и связей между ними. Менее продвинутая T9 предлагает следующее слово лишь на основе одного предыдущего слова — дело в более примитивной архитектуре.
Как и другие нейросети, GPT — это языковая модель, основанная на статистических паттернах, и она не обладает реальным пониманием или сознанием. Она просто предсказывает вероятные следующие слова на основе информации, на которой обучалась. Она прочитала тексты, выявила закономерности и построила на их основе алгоритмы для использования в последующей генерации.
Блочное устройство «Трансформера» позволило сильно масштабировать нейросети, скармливая им огромное количество данных, не вызывая при этом неадекватных требований к вычислительным мощностям. Поэтому после обновлений тексты GPT становятся все более похожими на человеческие. С ростом количества алгоритмов нейросети ее ответы все чаще становятся дельными советами.
Постараемся разобрать устройство языковой модели GPT так, чтобы всем было понятно.
GPT состоит из входного слоя, блоков трансформера и декодера. По сути это отдельные нейросети, которые входят в модели архитектуры «Трансформер».
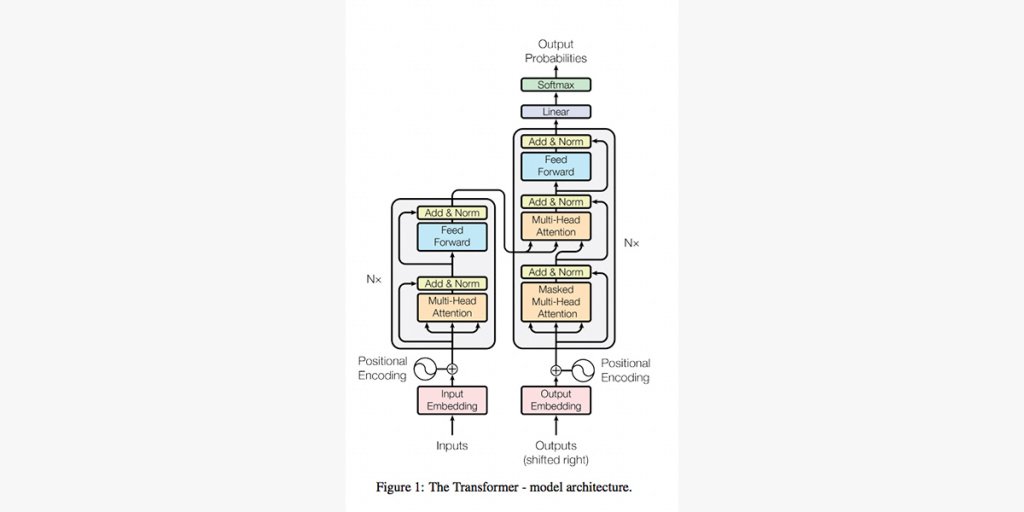
Схема одной из вариаций архитектуры «Трансформер»
Что происходит в GPT при вводе запроса:
Входной слой получает запрос, который мы хотим обработать или продолжить. На этом слое текст преобразуется в числовые векторы, называемые эмбеддингами. Близость векторов в векторном пространстве отражает синтаксическую структуру и семантическую схожесть слов. Например, в одном предложении слово «замок» может означать крепость, а в другом — штуку, в которую вставляют ключ. Эмбеддинги помогают GPT понять, какое значение слова более вероятно, и генерировать текст с учетом семантики слов в запросе. Также эмбеддинги помогают установить связи между отдельными словами и понять синтаксическую структуру предложений.
Эмбеддинги обрабатываются несколькими блоками трансформера. Каждый блок позволяет модели обрабатывать и улавливать различные аспекты текста, такие как семантику, синтаксис и контекст. Каждый блок состоит из механизма внимания и многослойного персептрона.
Механизм внимания позволяет модели фокусироваться на определенных словах в контексте и учитывать их влияние при обработке остальной части текста. Те эмбеддинги, которая нейросеть выделит как «важные», получат больший вес.
Далее многослойный персептрон преобразует данные с помощью линейных операций и нелинейных функций активации над эмбеддингами. За счет этого GPT выявляет сложные зависимости между эмбеддингами, чтобы с большей вероятностью сгенерировать связный и качественный текст.
После того, как запрос прошел вычисления несколькими блоками, GPT использует декодер, чтобы генерировать продолжение текста на основе эмбеддингов, а также их весов и параметров после вычислений. Декодер вычисляет вероятности возможных следующих слов и выводит наиболее вероятные.
Разберем, как эволюционировала языковая модель GPT и в какой момент на ее основе появился сервис ChatGPT.
 Читайте также:
18 нейросетей для генерации контента в 2023 году
Читайте также:
18 нейросетей для генерации контента в 2023 году
Через год после того, как Google Brain обнародовали архитектуру «Трансформер», OpenAI выпустили статью «Improving Language Understanding by Generative Pre-Training» и первую версию своей языковой модели — GPT-1. Первая версия модели не была в публичном доступе — это была внутренняя разработка OpenAI. GPT-1 стала примером инновационного подхода OpenAI к машинному обучению — методу генеративного предварительного обучения.
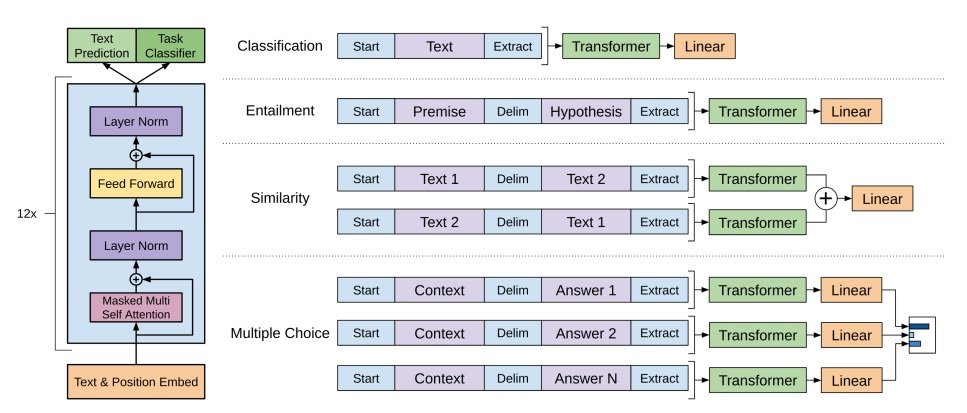
Архитектура GPT-1
Архитектура GPT (Generative Pre-trained Transformer) отличалась от «гугловской» архитектуры «Трансформер» в нескольких ключевых аспектах:
GPT-1 использовала несколько блоков за счет технологии multi-head attention. Это позволило языковой модели обращать внимание на различные аспекты текста одновременно, что поспособствовало лучшему пониманию контекста и связей между словами.
В сравнении с «Трансформером», в GPT-1 использовались эмбеддинги с более высокой размерностью. Например, если размерность эмбеддинга равна 300, каждое слово представлено вектором в
Самое главное. GPT-1 использовал метод генеративного предварительного обучения (generative pre-training). Это означает, что модель сначала обучалась на большом количестве неразмеченных данных, а затем дообучалась на конкретных задачах с инструктором. Такой подход позволил GPT-1 обладать общим представлением языка и обобщать свои знания. Но самое главное, что обучать такую языковую модель стало очень просто — загружаешь в нее данные, а она сама разбирается. Потом подправить — и в релиз.
Характеристики GPT-1:
максимальный размер запроса — 512 токенов (токены можно примерно считать как морфемы в словах);
обучающая информация — 7 000 книг;
количество параметров — 120 миллионов;
12 слоев.
Версия GPT-2 вышла в феврале 2019 года — это была первая публичная версия языковой модели. GPT-2 была результатом масштабирования языковой модели GPT-1. Фундаментально ее архитектура не изменилась — разве что увеличили количество слоев до 48 и загрузили в нее 40 Гб данных, за счет чего ее количество параметров увеличилось в 10 раз. Благодаря этому нейросеть сама научилась отвечать на вопросы, генерировать достаточно сложные эссе и переводить тексты с языка на язык с переменным успехом.
Характеристики GPT-2:
максимальный размер запроса — 1 024 токена;
обучающая информация — 8 миллионов веб-страниц или 40 Гб данных;
количество параметров — 1,5 миллиарда;
48 слоев.
 Читайте также:
Workspace Robot: что умеет наш чат-бот в Telegram
Читайте также:
Workspace Robot: что умеет наш чат-бот в Telegram
Бета-версия GPT-3 вышла в июне 2020 года. В нее загрузили еще больше данных, за счет чего количество параметров нейросети снова увеличилось в 10 раз в сравнении с предыдущей версией. С апгрейдом у нейросети появилось еще больше навыков. Она стала еще лучше работать с текстом, научившись выдавать более сложные ответы в разной стилистике, а также писать программный код и проводить несложные математические вычисления.
Характеристики GPT-3:
максимальный размер запроса — 2 048 токенов;
обучающая информация — 570 Гб данных;
объем нейросети — 800 гигабайт;
количество параметров — 175 миллиардов;
96 слоев.
Что удивительно, эта версия языковой модели все еще не снискала всемирной популярности, хотя по возможностям была близка к версии ChatGPT. Все дело в отсутствии интерфейса в виде чат-бота. GPT-3 была опубликована публично, но к ней приходилось обращаться через API, а еще она была платной. Зато эта версия языковой модели доступна в вариациях с различным количеством параметров: например, у облегченной версии Ada их всего 350 миллионов.
Революция наступила, когда появилась языковая модель InstructGPT, она же GPT-3.5, которая и стала основой ChatGPT. Ключевое отличие InstructGPT от GPT-3 в том, что ее более глубоко дообучали люди, оценивая качество ответов. Еще ее максимальное количество токенов увеличилось до 4 096.
За счет дообучения нейросеть стала более подготовленной к использованию простыми людьми, которые не являются промпт-инженерами, а просто пишут незамысловатые запросы. Ее мощности остались примерно теми же, что и в версии GPT-3. При этом, открытый публичный доступ, удобный интерфейс и невероятные доселе возможности сделали ChatGPT всемирно известной.
Тонкости промпт-инжиниринга в ChatGPT
 Читайте также:
Чат-боты в ВК для бизнеса от «А» до «Я»
Читайте также:
Чат-боты в ВК для бизнеса от «А» до «Я»
GPT-4 — версия языковой модели, которую выпустили 14 марта 2023 года. Эта версия стала мультимодальной, поскольку научилась работать не только с текстом, но и с изображениями. Количество параметров этой версии неизвестно, эксперты оценивают его примерно в 500 миллиардов. Новая версия нейросети стала генерировать еще более качественные ответы, но из-за того, что прирост мощности не был кратным, невероятного скачка в функциональности не произошло. На мой субъективный взгляд, нейросеть все еще не способна заменить коммерческого автора.
Эта версия языковой модели доступна в 2 видах: в платной подписке ChatGPT Plus, а также в чат-боте браузера Bing от Microsoft. О том, как пользоваться обновленной версией ChatGPT в Bing, мы рассказали в статье «Обзор ChatGPT: что умеет и как эффективно пользоваться нейросетью». Новая модель нейросети появилась у Microsoft, потому что компания Билла Гейтса проинвестировала в OpenAI более 10 миллиардов долларов.
23 марта 2023 года OpenAI добавила поддержку плагинов, которые дополнительно расширяют функционал сервиса.
Сервисы, которые стали доступны в виде плагинов на момент релиза новой функции в ChatGPT. Сейчас их еще больше
Наша система сама подберет вам исполнителей на услуги, связанные с разработкой сайта или приложения, поисковой оптимизацией, контекстной рекламой, маркетингом, SMM и PR.
Заполнить заявку
13517 тендеров
проведено за восемь лет работы нашего сайта.
Сэм Альтман, гендир OpenAI, заявил, что настоящее время компания не занимается обучением GPT-5. Его речь состоялась 13 апреля 2023 года на конференции «The Future of Business with AI». По словам Сэма, в данный момент компания занимается профилактикой угроз, которые могут произойти в связи с релизом более мощной версии нейросети. Ожидается, что GPT-5 станет сильным искусственным интеллектом — более умным, чем человек. Изначально релиз новой версии планировался на начало 2024 года. Сейчас эта дата неизвестна.

