Тендеры и лиды
Информация


Сеть-магазинов «ВОИН»
Одежда и обувь
Россия, Москва
Контекстная реклама в Яндексe
Январь 2024
Повысить эффективность рекламных кампаний и получить больше продаж при тех же затратах на рекламу.
Мы использовали инструменты системы сквозной аналитики StreamMyData, внутри которой разработали модели машинного обучения на основе нейросетей. Они позволяли прогнозировать вероятность совершения покупки пользователей в течение 7 дней — среднего срока принятия решения клиентов этого интернет-магазина.
После создания моделей машинного обучения мы провели A/B-тестирование эффективности рекламных кампаний в Яндекс.Директе: в В-сегменте использовались наши предиктивные модели на основе ML-аудиторий, а A-сегментом работали обычные автостратегии Яндекса.
Прежде мы работали с хитовым и сессионным стримингом, полученным из Google Analytics. Однако новый кейс показал, что действия пользователей, выгруженные из Яндекс.Метрики посредством Logs API, также могут быть использованы при создании будущих ML-моделей.
Сначала мы составили клиенту ТЗ на передачу UserID из CRM клиента и разметку дополнительных событий, которых было около 150: базовые ecommerce события (покупка, добавление товара в корзину, клик по карточке товара и т.д.), использование регулировщика цены, использование поиска, переход в раздел каталога и т.д.
Этап накопления данных занял 3-4 недели.
Собрав данные, мы перешли к написанию SQL-запросов, которые фиксировали определенное поведение пользователя на сайте: например, совершение покупки, стоимость покупки, срок возвращение на сайт после предыдущей покупки и т.д.
Эти типы поведения являются признаками, на которые в дальнейшем будет опираться предиктивная модель.
Для определения признаков мы написали три SQL-запроса на формирование:
- Сессионных признаков.
- Признаков на основе действий пользователей во время сессий.
- Целевого признака — факта совершения покупки в течение 7 дней.
Пример части SQL запроса на выгрузку признаков:
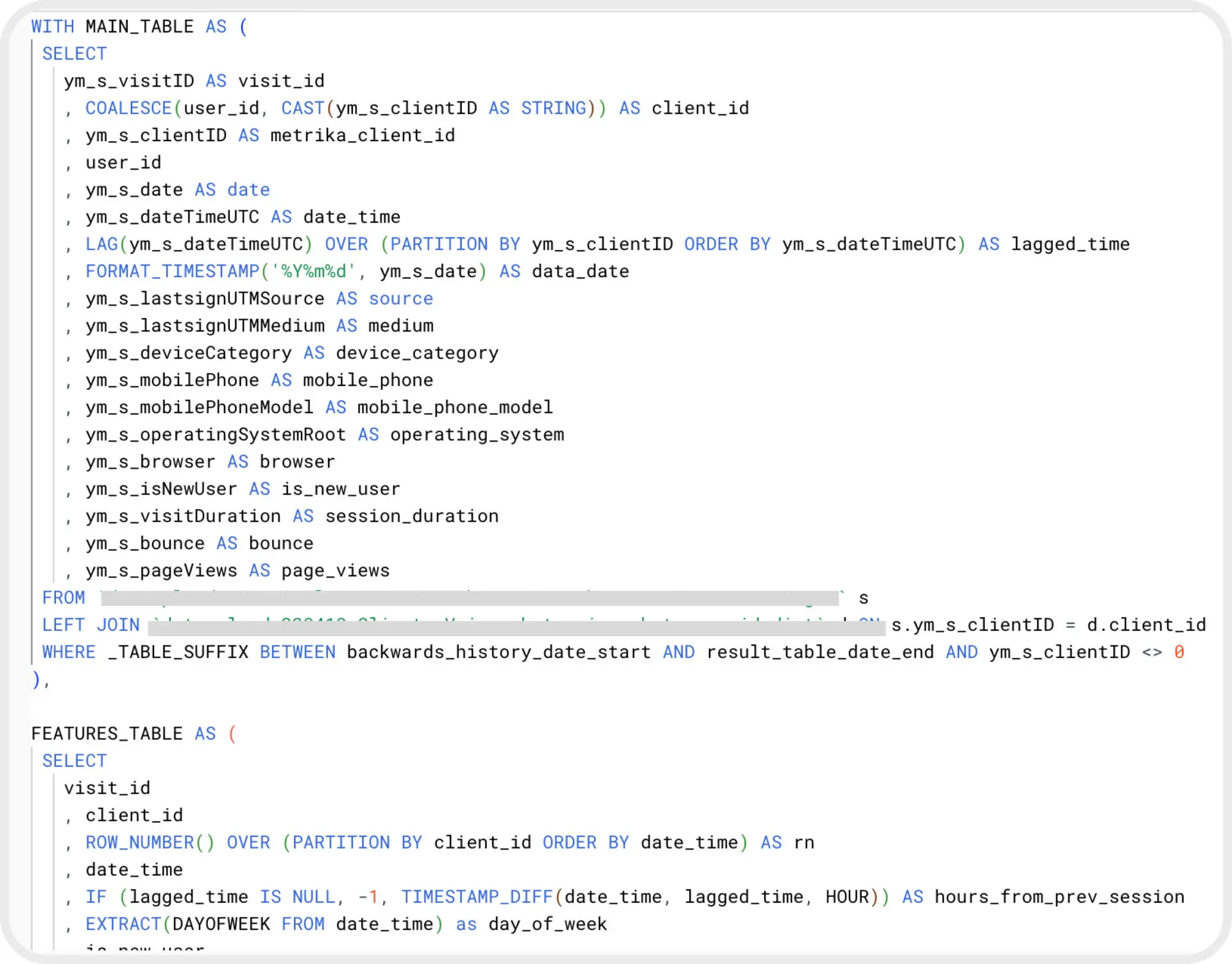
Нам удалось сформировать 707 признаков. Такое значительное число позволяет выявить больше закономерностей в действиях пользователей и лучше описать их поведение.
Это был самый долгий и трудоемкий этап. Его сложность состояла в том, что необходимо было потратить большое количество времени на продумывание архитектуры, перебор всевозможных гиперпараметров модели и ее обучение. Чем больше данных, тем дольше обучаются модели, и больше вычислительных ресурсов требуется.
Схема ниже демонстрирует, как сформированные признаки попадают в три разные обученные модели, а потом переходят в блок формирования итогового прогноза.
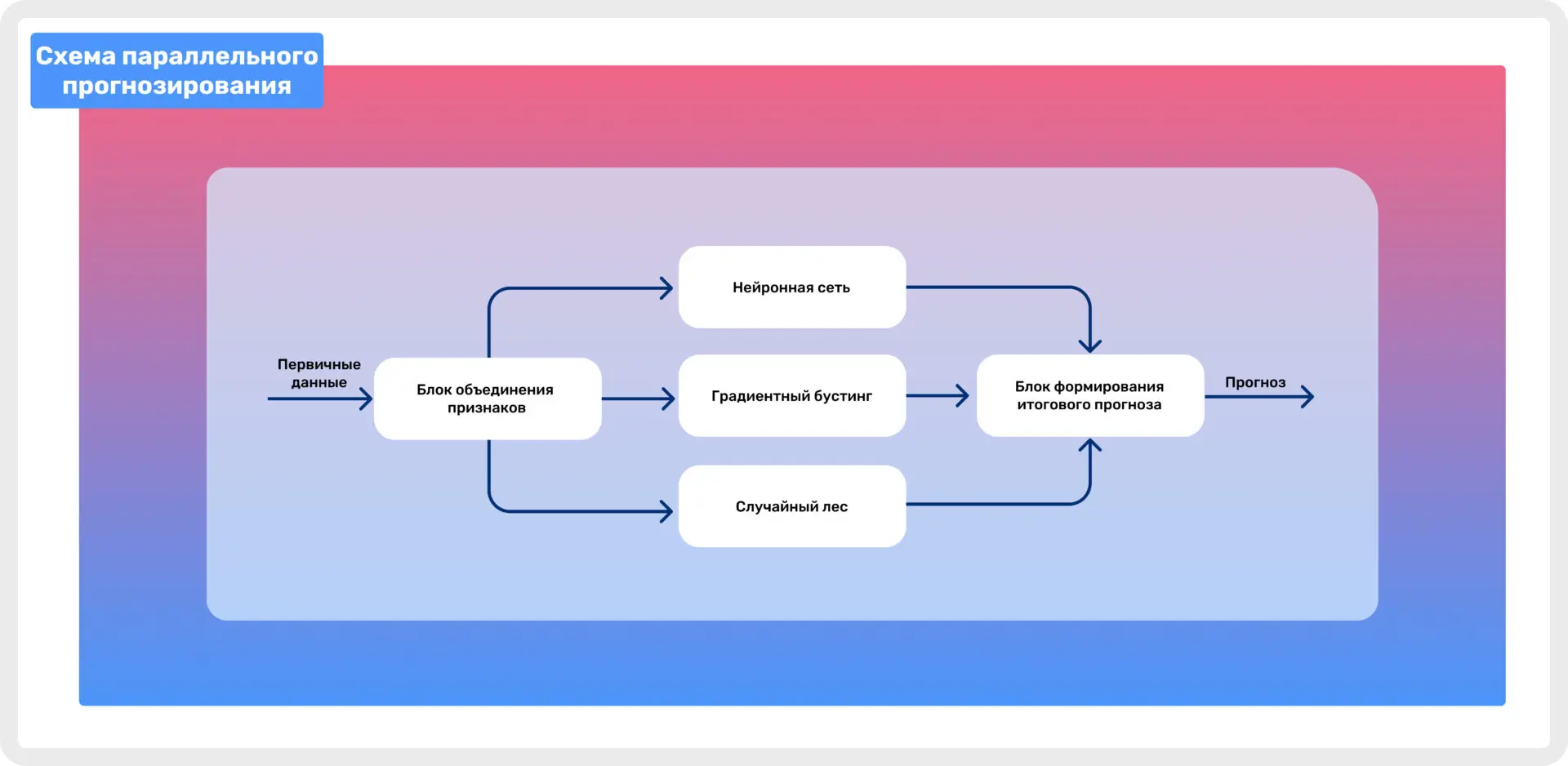
Схема параллельного прогнозирования
Финальный прогноз формируется на основе результатов предсказания всех трех моделей. Мы получаем усредненную вероятность совершения покупки пользователем в течение последующих 7 дней.
Исследование и применение нейронных сетей в нашей задаче заняло значительное время и усилия. Мы посвятили около года тщательному изучению и экспериментам с различными видами нейронных сетей, чтобы решить задачу прогнозирования поведения пользователей. Мы исследовали возможность применения сверточных, рекуррентных нейронных сетей, а также многослойного персептрона.
В нашей задаче, которая сводилась к бинарной классификации (предсказывая, совершит ли пользователь покупку), мы использовали числовые представления действий пользователей на сайте в виде векторов. Для этого мы прибегли к методам кодирования, таким как One-Hot Encoding, Ordinal Encoding или Embedding, чтобы преобразовать события в числовые значения и снизить размерность признаков.
Например, если пользователь выполнил три действия в сессии (просмотр каталога, клик на товар и покупку), мы можем закодировать их следующим образом:
Просмотр каталога - 1
Клик на товар - 2
Покупка - 3
Такой набор действий будет представлен в виде вектора [1, 2, 3], который мы затем передаем в нейронные сети после снижения размерности. Однако выбор оптимальной архитектуры сети и ее параметров представляет собой сложную задачу. Мы провели множество обучений, чтобы максимизировать точность и минимизировать ошибку сетей. В результате наших исследований мы обнаружили, что многослойный персептрон демонстрирует наилучшие результаты по сравнению со сверточными и рекуррентными нейронными сетями. Именно его мы и использовали в прогнозировании действий пользователей на проекте «ВОИН»
Многослойный персептрон является одним из наиболее распространенных типов нейронных сетей и часто используется для решения задач классификации. Такой вид нейронных сетей обычно имеет входной слой равный количеству входных параметров (признаков), несколько скрытых слоев и выходной слой.
Количество скрытых слоев может быть любым, так же, как и количество нейронов в каждом слое. Несмотря на это, разработка архитектуры нейронной сети является сложной задачей, поскольку большое количество слоев может привести к переобучению сети и наоборот, слишком маленькое количество скрытых слоев может привести к недообучению, когда сеть не способна выявлять определенные паттерны для достижения высокой точности.
Как правило, мы создаем пять сегментов пользователей на основе вероятности совершения покупки:
- Околонулевая вероятность покупки.
- Нулевая вероятность покупки.
- Средняя вероятность покупки.
- Высокая вероятность покупки.
- Очень высокая вероятность покупки.
В первых трех сегментах всегда будет больше людей, тогда как в последних двух сегментах пользователей в разы меньше.
Мы столкнулись с проблемой: Яндекс.Аудитории позволяли создавать сегменты объемом не менее 100 уникальных пользователей. Поэтому мы были вынуждены объединить сегменты и вместо пяти сделать три:
- Нулевой + околонулевой.
- Средний.
- Высокий + очень высокий.
На основе этих сегментов мы создали аудитории в Яндекс.Аудиториях, добавили их в рекламные кампании Яндекс.Директа и присвоили им определенные корректировки:
- Понижающий коэффициент для околонулевых сегментов, поскольку эти пользователи не будут совершать покупку, и нет смысла тратить деньги на их привлечение.
- Повышающие коэффициенты для остальных сегментов. Чем выше вероятность покупки, тем был выше коэффициент — это позволяло чаще выигрывать рекламные аукционы, демонстрировать рекламу и стимулировать клиентов совершить покупку.
Каждый день поступала новая информация о действиях посетителей сайта, и ML-сегменты необходимо было обновлять. Без регулярного обновления пользователь будет оставаться в самом конверсионном сегменте, даже после того, как совершит покупку, и ему уже не будет смысла показывать рекламу. Обновление также необходимо для дообучения ML-моделей, что повышает точность предсказаний.
Для автоматизации обновления данных мы
1. Написали необходимый код на Python.
2. Использовали open-source решение Apache Airflow в роли оркестратора наших процессов. Основной сущностью Airflow является DAG (Directed Acyclic Graph) — направленный ацикличный граф, вершинами которого являются задачи, которые мы зададим при создании самого DAG.
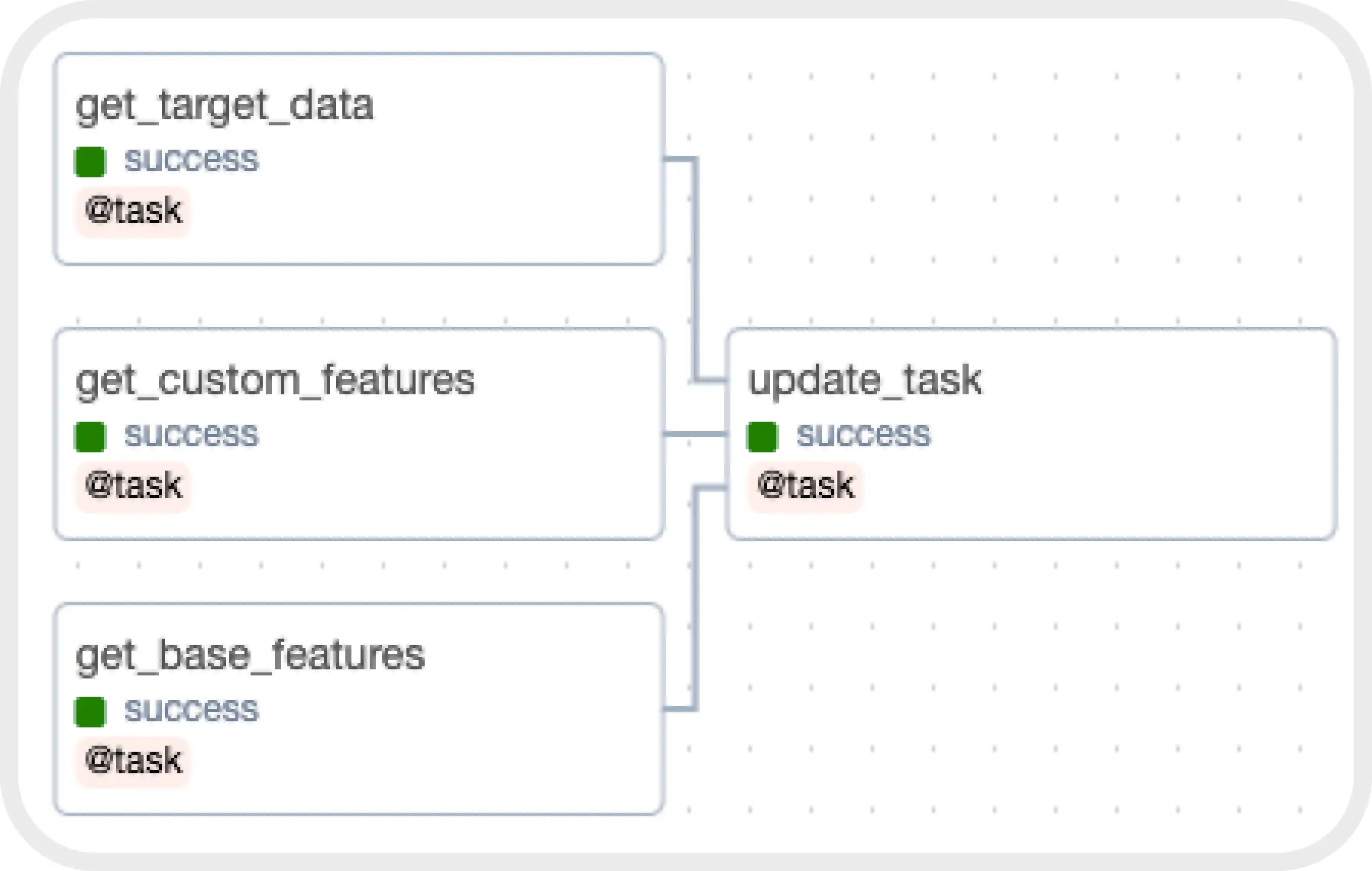
Структура DAG для дообучения ML моделей
3. Создали три отдельных DAG, которые дообучали наши ML-модели. Каждый DAG состоял из четырех отдельных задач (task), первые три из которых на ежедневной основе выгружали данные из Google BigQuery, после чего данные передавались в задачу на дообучение моделей.
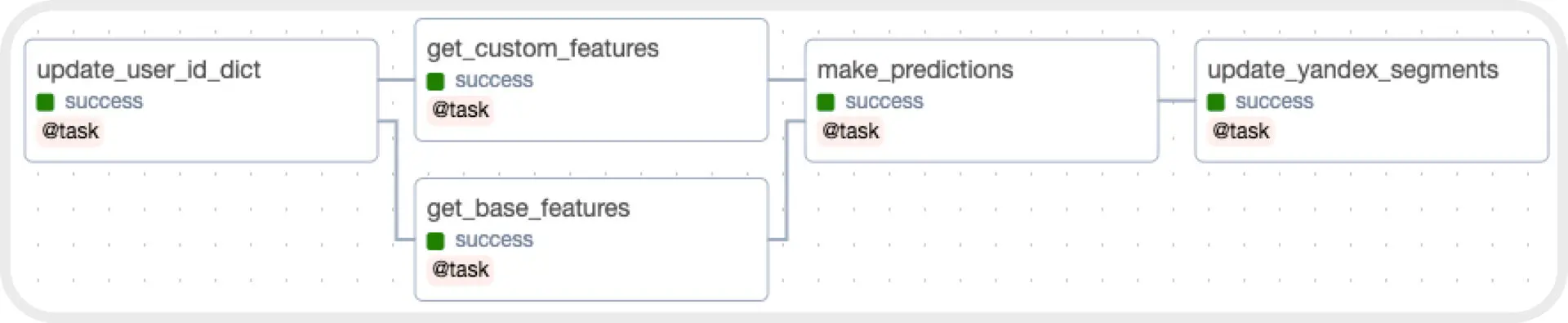
Структура DAG для обновления сегментов в Яндекс.Аудитории
4. Написали DAG, который будет автоматизировать процесс обновления сегментов на ежедневной основе ночью.
5. Обратились к Kubernetes — системе оркестрации, которая осуществляла контроль выделения ресурсов под каждую задачу: метчинг User_ID, выгрузку данных о действиях пользователей, формирование предсказаний, сегментирование пользователей.
После автоматизации всех процессов мы перешли к A/B-тестированию ML-сегментов в рекламных кампаниях Яндекс.Директа. В тесте участвовало две рекламные кампании (со смарт-баннерами и текстово-графические кампании), каждая из которых была поделена на две части:
1. Первая часть работала на автостратегиях Яндекса (сегмент А).
2. Вторая часть использовала наши ML-сегменты с повышающими или понижающими коэффициентами (сегмент В).
На каждую кампанию мы выделили одинаковый бюджет в неделю и запустили их одновременно. Мы тестировали кампании ровно один месяц с 11 декабря 2023 по 11 января 2024 года, — в это время не вмешивались в настройки объявлений, чтобы результаты были объективными.

Креативы для первой и второй кампании
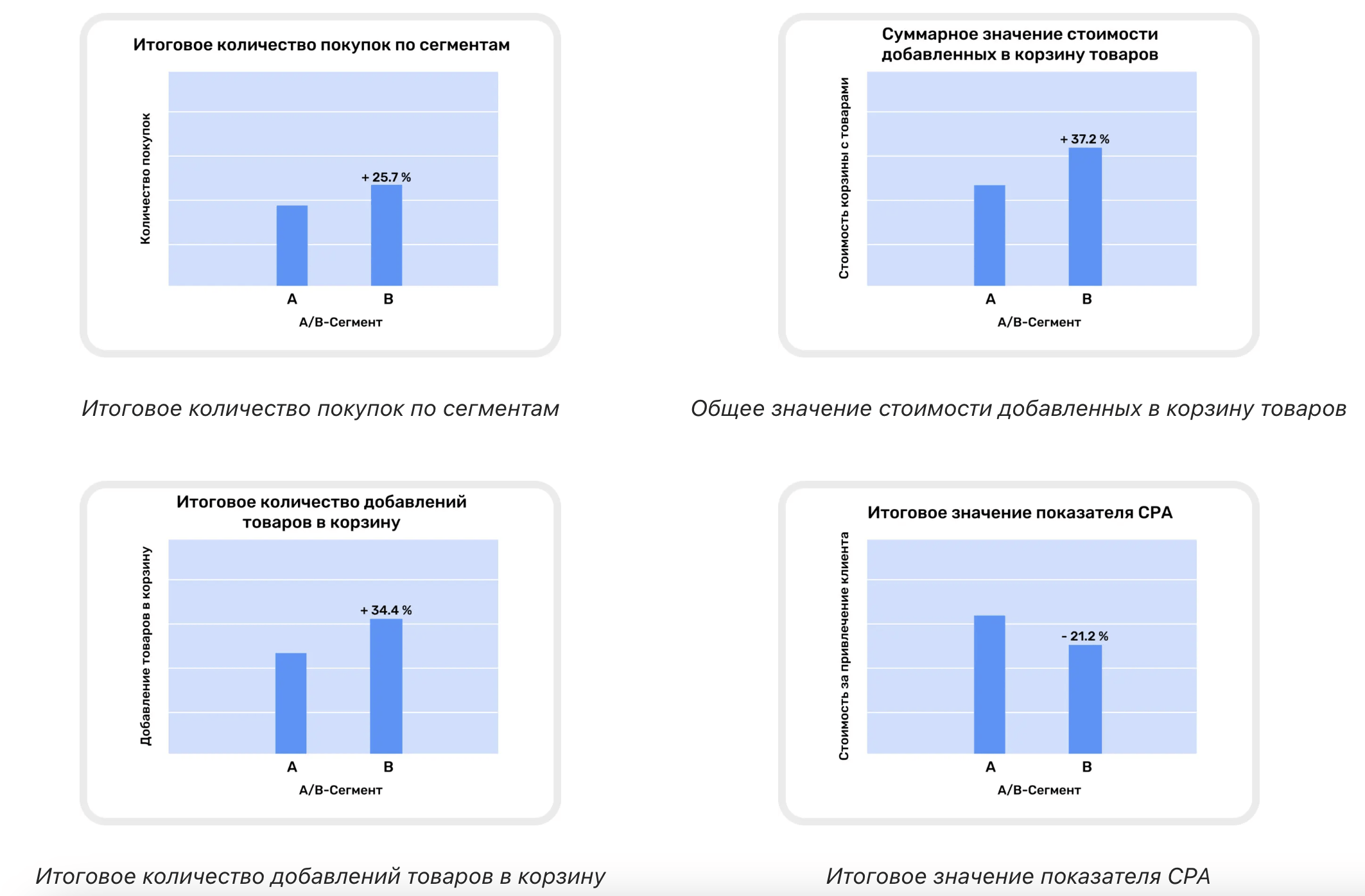
Результаты первой кампании
- Сегмент B значительно опередил A по эффективности: принес больше конверсий, добавлений товаров в корзину по более низкому CPA:
- Сегмент В принес на 25.7% больше покупок, чем сегмент А, что говорит о правильном выборе корректировок в отношении этой группы.
- Итоговое количество добавлений товаров в корзину на 34.4% больше, чем у сегмента A. Это значит, этот сегмент более активный и вовлеченный.
- Суммарное значение стоимости добавленных в корзину товаров у сегмента B на 37.2% больше, чем у сегмента A. Это говорит о большем размере среднего чека и заинтересованности пользователей в более дорогих товарах.
- Значение CPA у сегмента B на 21.2% ниже, чем у сегмента A, — мы тратили меньше бюджета на привлечение пользователей.
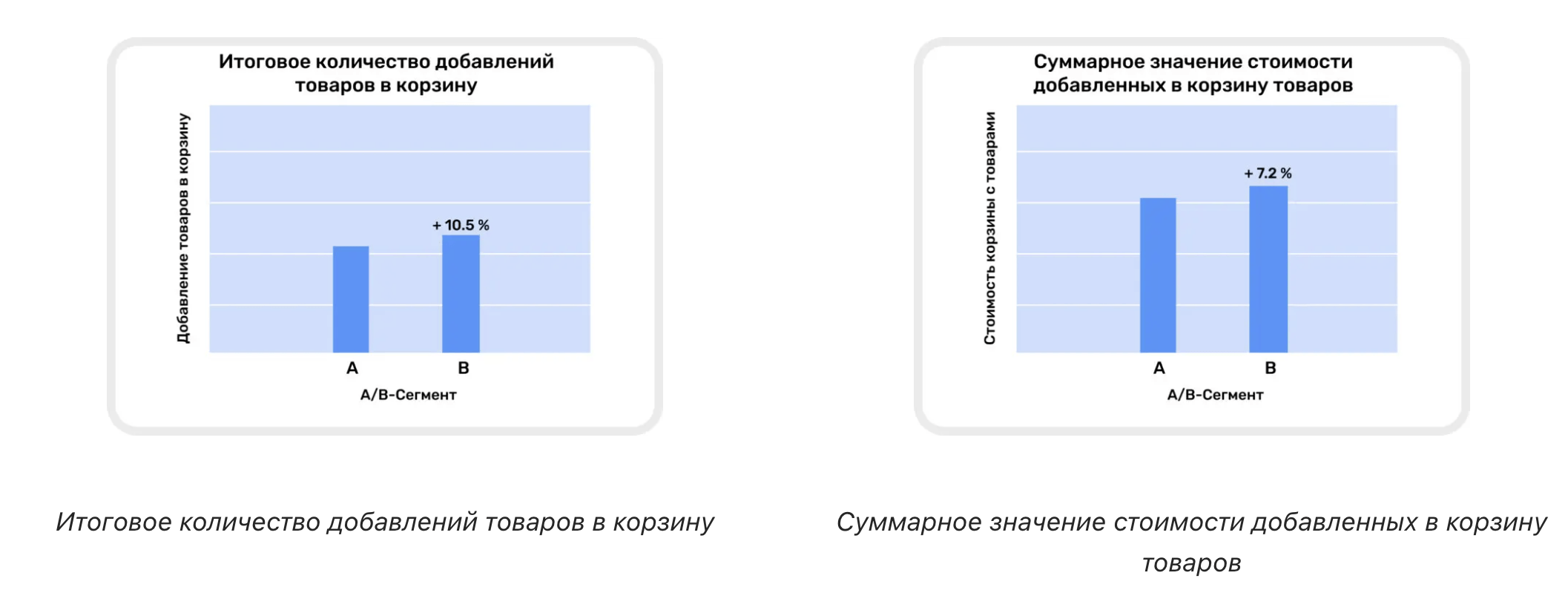
Результаты второй кампании
Во время второй рекламной кампании сегмент с ML-корректировками лучше показал себя с т.з. увеличения продаж и суммарной стоимости корзины:
- В сегменте B количество добавлений товара в корзину превышает аналогичный показатель в сегменте A на 10.5%.
- Суммарная стоимость корзины в сегменте B на 7.2% больше, чем в сегменте A, что указывает на чуть более высокий средний чек.

MediaNation Иван Барченков
Результаты A/B-тестирования подтверждают высокую эффективность обученных предиктивных ML-моделей в рекламных кампаниях Яндекс Директа. ML-модели корректно предсказывали совершение покупки пользователем в течение последующих 7 дней. А значит, мы можем использовать ML-модели уже в последующих полноценных запусках для клиента.

Юлия Гнатюк
Руководитель отдела электронной коммерции «ВОИН».
В период с октября 2023 г. по январь 2024 г. на базе нашего сайта осуществлялся тест сервиса предиктивной аналитики Stream My Data. Суть теста заключалась в том, чтобы усилить показатели контекстной рекламы в Яндекс Директ, реализовав сегментирование клиентов посредством сервиса.
Могу заключить, что тест прошёл успешно, так как кампании, которые использовались в тестировании, показали прирост в количестве конверсий равный 25%. Предоставленные результаты и выводы теста были также положительно оценены компанией подрядчиком по контекстной рекламе.
Перешли на постоянное сотрудничество с компанией ООО «Медианация», так как видим большой потенциал в данном сервисе.





















